集合知识
常见集合
JAVA集合类主要由Collection和map派生
绿色代表接口。
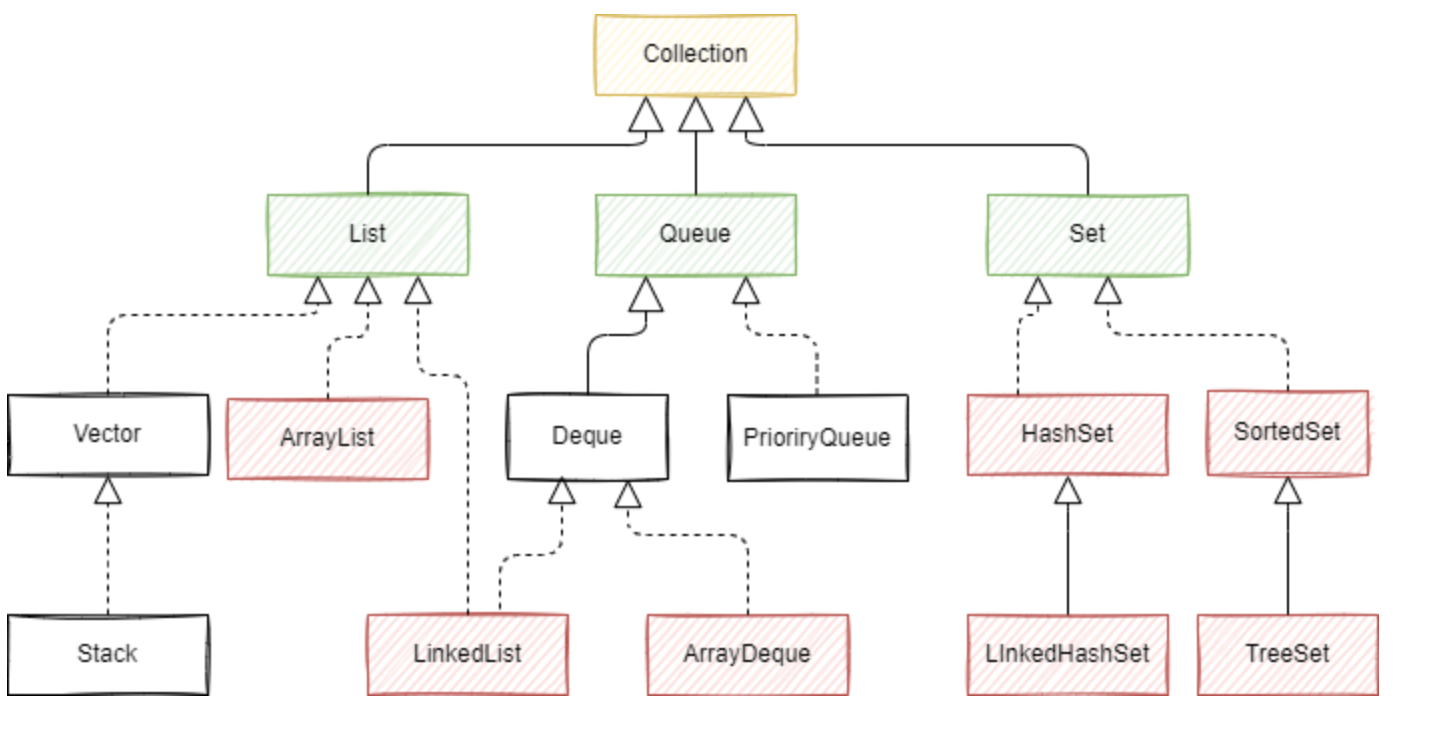
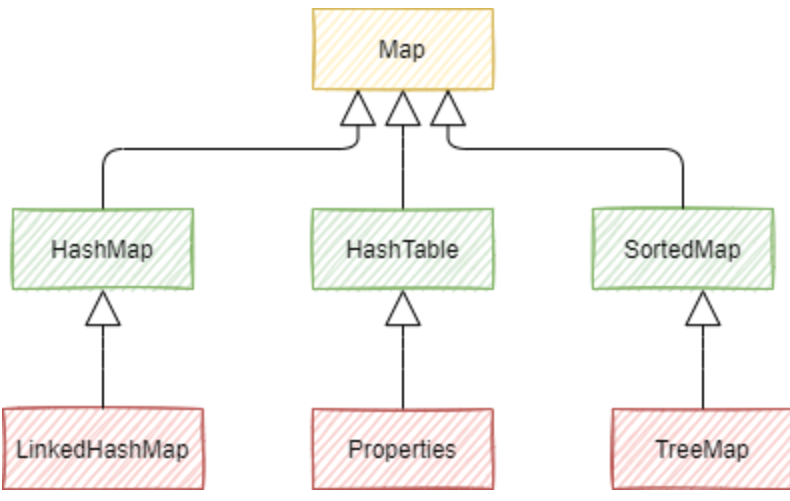
常规上分为四大类:
List代表有序可重复集合。Set代表无序不可重复集合,Queue是队列集合,Map代表的是key-value对集合。
关于它们的常见实现类由ArryayList,LinkedList,HashSet,TreeSet,HashMap等
List 、Set和Map 的区别
1.List以索引来存取元素,可以插入多个null,元素可重复
set不能存放重复元素,只允许有一个null。
Mao存储的是键值对映射。
2.底层不同,List有数组和链表2种形式,Set,Map基于哈希储存和红黑树2种方式实现。
3.Set基于Mao实现,Set的元素就是Map的键值
ArrayList 了解吗
ArryList的底层是动态数组,可使用ensureCapacity来增加实列的容量,ArrayList基础了AbstractList并且实现了List接口。
ArrayList 的扩容机制
讲解源码。先计算容器的大小,返回数组大小的容器中,如果数组为空则返回默认容量和添加后的容量的最大值,不为空则返回添加后的容量。在判断容量是否足够的函数中,如果容量够,则将其扩容为1.5倍

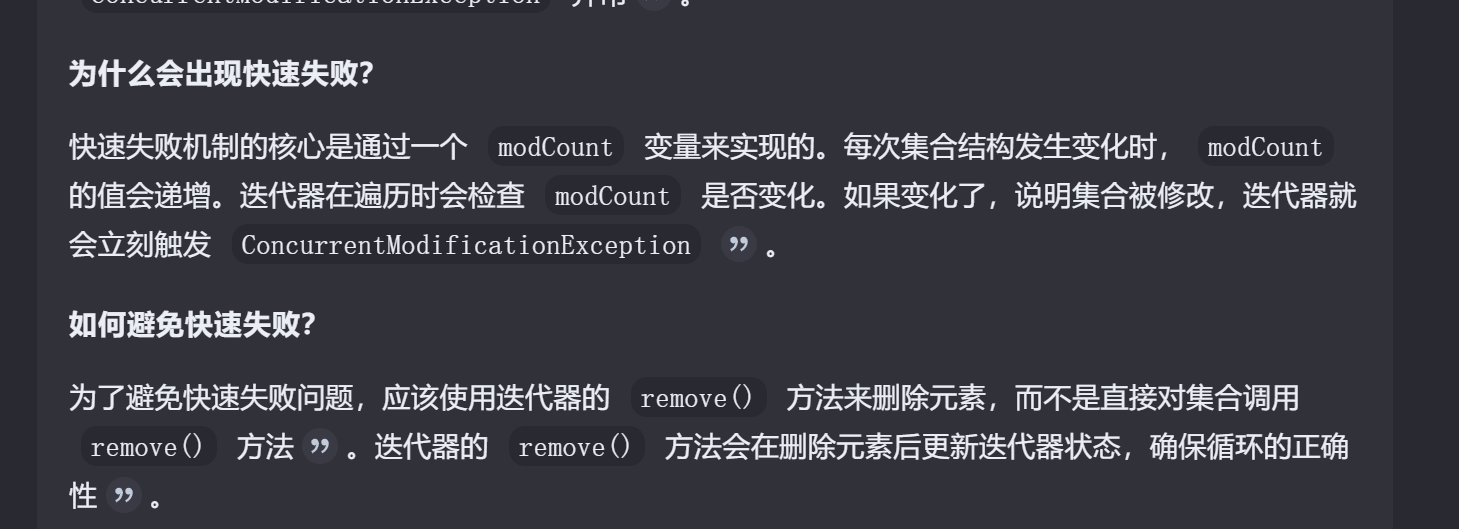
如何在遍历ArryList的时候移除一个元素
快速失败的定义和解决方案。foreach属于迭代器。要用remove维护它的状态,因为modCout变量如果变化,迭代器检测到变化就会抛出异常。
Arraylist 和 Vector 的区别
vector的扩容是2倍
vector虽然具有线程安全,但是其操作的效率很低。正因为其有线程安全才导致了效率低,其在每一次操作后都需要去同步线程。
Arraylist 与 LinkedList的区别
1.arrylist是动态数组,linklist是链表。
2.对于随机访问getset,arrylist速度优先,因为linklist要进行指针遍历。
3.对于添加元素,linklist的效率更高,因为其只需要修改指针,arrylist往往伴随着扩容的操作。
hashMap
hashmap基于数组,列表和红黑树(jdk1.8后加入),当链表长度超过8时变为红黑树,小于6时变为列表。
解决hash冲突的方法
1.开放地址法:当发生冲突后,去寻找一个不冲突的哈希地址pi,导致地址空间要求大
2.再哈希法.提供多个哈希函数,如果第一个函数发生了冲突,就去计算第二个,直到没有发生冲突为止。
3.链地址法:发生冲突去生成链表。
使用hash算法
1.取hashcode的值2.高位运算3.取模运算
为什么设置hashmap的容量
hashmap具有扩容机制,扩容是当超过某个临界条件就会扩容,并不是到满了后才进行扩容。如果没有指定容量,会不断从小开始扩容,每次扩容要重建立hash表,影响性能。
hashmap的扩容过程是怎么样的
1.8 当元素大于threshold进行扩容,用2倍的数组代替原数组,用尾插法。
1.7链表采用头插法,这种插入方式当扩容迁移的方式可能会引发循环链表,1.8的尾插法可以避免
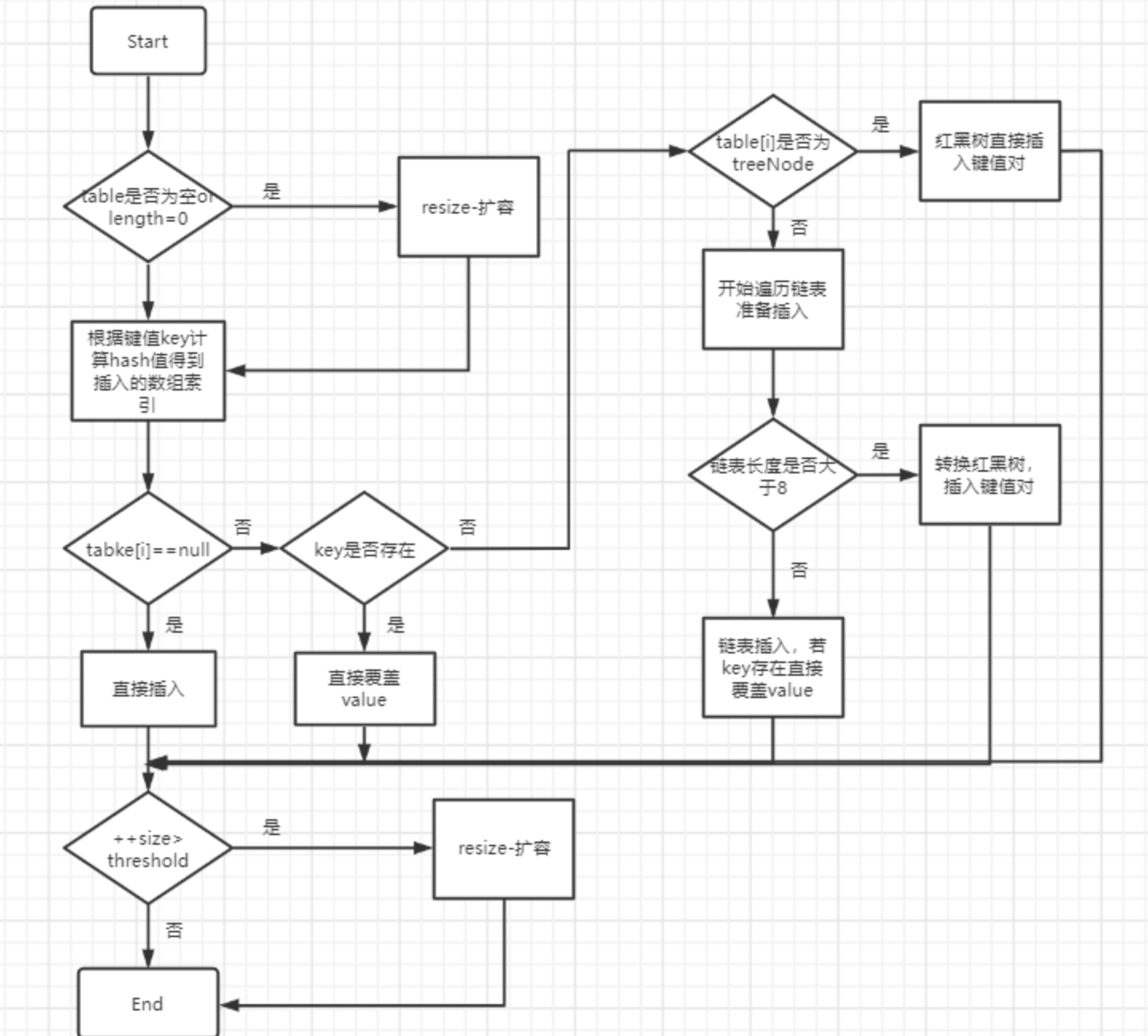
说说hashmapput方法的流程
1.table没有初始化就进行初始化流程。
2.用hash算法计算key的索引。
3.如果索引位置没元素则插入,有元素要分链表插入和黑红树插入
4.如果链表的阈值大于了8就要转为红黑树
5.添加成功后看是否需要扩容
红黑树特点
- 叶子节点都是黑色。根节点也是黑色的
- 红节点下必然是黑色
- 一个节点到叶子节点经过的黑节点数目是一样的
为什么超过一定的数目需要先用链表然后再转红黑树
当数量过大的时候,链表的查找为on,相对红黑树大于8个则可以构建红黑树,查找速度为ologn,可以加快查询速度。
为什么不直接用红黑树---小规模数据插入红黑树要通过左旋右旋变色等操作保证平衡,耗费性能。
hashmap的长度是2的n次方

HashMap默认加载因子是多少?为什么是 0.75

一般用什么作为HashMap的key?
一般选用Integer和String
1.因为String是不可变的,所以它创建hashcode就被缓存了,不需要重新计算。
2.获取对象的时候要用到 equals() 和 hashCode() 方法,而Integer、String这些类都已经重写了 hashCode() 以及 equals() 方法,不需要自己去重写这两个方法
HashMap为什么线程不安全?
1.7 是死循环
1.8会发生数据覆盖的情况
HashMap和HashTable的区别
1.hashmap可以接受null值
2.hashtable是线程安全的
3.因为是线程安全就伴随着多线程之间的同步,所以效率较慢,在单线程中效率慢。
4.hashtable直接使用了对象的hashcode,而hashmap重新计算hash值。因为hashmap会根据数组的大小进行一次取余确认在数组中的位置
LinkedHashMap底层原理
hashmap的迭代出的数据并不是原先加入的数据。ListedHashMap基础了hashmap和linkList的特性,具有顺序,以双向链表储存。线程不安全。map的特性就是键值对的储存,且键不可以重复
介绍treemap
treemap是一个可以比较元素大小的集合,对传入的key进行了排序,可以使用自然排序也可以自己设定排序规则。
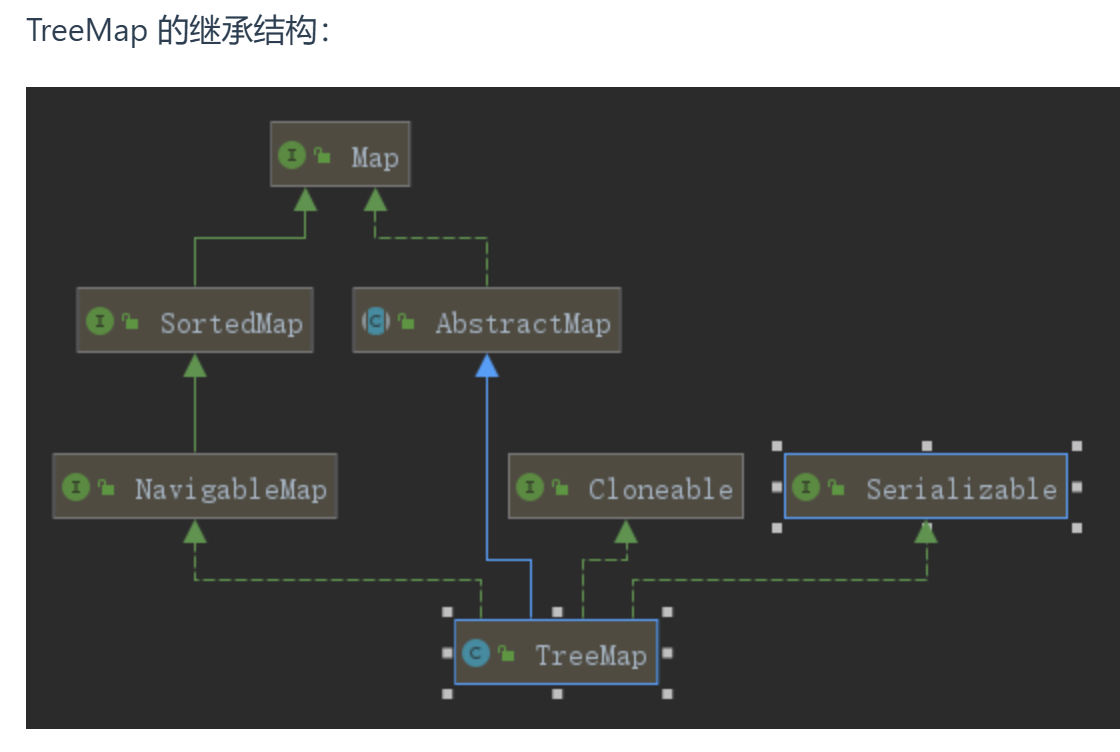
1.有序的key-value集合,使用了红黑树。
2.TreeMap继承了AbstractMap,实现了NavigableMap接口,支持一系列的导航方法,给定具体搜索目标,可以返回最接近的匹配项。如floorEntry()、ceilingEntry()分别返回小于等于、大于等于给定键关联的Map.Entry()对象,不存在则返回null。lowerKey()、floorKey、ceilingKey、higherKey()只返回关联的key
HashSet底层原理

HashSet、LinkedHashSet 和 TreeSet 的区别
treeset可以按照大小遍历,linkhashset可以根据加入的顺序遍历,HashSet 是 Set 接口的主要实现类 ,HashSet 的底层是 HashMap,线程不安全的,可以存储 null 值;
什么是fail fast?
集合中有modCount记录集合操作的次数,假如线程a在遍历某一个数组,另外一个线程修改了内容导致modCount变动,遍历的线程就会抛出ConcurrentModificationException,产生fast-fail
解决方法:1.上锁,2.使用CopyOnWriteArrayList来替换ArrayList。在对CopyOnWriteArrayList进行修改操作的时候,会拷贝一个新的数组,对新的数组进行操作,操作完成后再把引用移到新的数组
什么是fail safe
采用安全失败机制的集合容器,为了避免fail fast,遍历时不是直接在集合内容上访问,而是拷贝数据对拷贝数据修改后替换原数组。
缺点:迭代器不能获得在迭代过程中其他线程进行的修改。

介绍ArryDeque
实现了双端队列,内部使用循环数组实现,默认大小为16.
1.队列的好处是添加方便,但是查询删除效率低
2.不支持索引操作,这里指的是没有实现索引接口,没有索引定位的方法,添加的元素只允许在末尾和开头进行添加
链表没有索引的概念,不能通过o(1)的方式根据索引定位,但也是可以进行索引操作,只需要遍历到某个位置然后进行修改择校
linklist也是一个双向的链表,只从2端操作看,arrydeque效率更高,如果需要进行索引操作,linklist更优秀,2者都是线程不安全的。
哪些集合类是线程安全的,哪些是不安全的


迭代器 Iterator 是什么?
常用迭代器去遍历hashmap等

Iterator 和 ListIterator 有什么区别?

如何让一个集合不能被修改
unmodifiableMap/unmodifiableList/unmodifiableSet方法

地址不可变,但地址内部的内容是可以变的


 浙公网安备 33010602011771号
浙公网安备 33010602011771号