Python基础教程 - Tdcqma
1.1 普通字符串 |
1.21 错误与异常 |
1.41 XXXXXX |
1.61 XXXXXX |
1.81 XXXXXX |
1.101 XXXXXX |
1.2 转义字符串 |
1.22 装饰器 |
||||
1.3 字符串运算 |
1.23 高阶函数 |
||||
1.4 字符串函数 |
1.24 生成器 |
||||
1.5 字符编码 |
1.25 迭代器 |
||||
1.6 注释 |
1.26 序列化 |
||||
1.7 交互程序 |
1.27 Python反射 |
||||
1.8 格式化输出 |
1.28 Socket编程 |
||||
1.9 流程控制If-Else |
1.29 Paramiko |
||||
1.10 While循环 |
1.30 爬虫 | ||||
1.11 模块 |
|||||
1.12 列表 |
|||||
1.13 元组 |
|||||
1.14 字典 |
|||||
1.15 购物车实例 |
|||||
1.16 文件读写 |
|||||
1.17 目录操作 |
|||||
1.18 函数 |
|||||
1.19 类和对象 |
|||||
1.20 字符编码转换 |
一、Python基础
1.1 普通字符串
字符串主要用来存储和表示文本内容的,在python中表示字符串有单引号('),双引号(")和注释用的三引号(''')三种方式。
name = "harry"
print('my name is ',name)
输出:
my name is harry
print('飞机',"大厦",'''钢琴''',"""航海""")
输出:
飞机 大厦 钢琴 航海
但是有一种情况,就是原本被双引号扩起来的内容中需要用单引号进行标记,原本被单引号扩起来的内容中需要用双引号进行标记,否则使用相同的引号进行内部标记的时候python解释器会因无法判断引号的边界而报错。
print('hello "world"')
print("hello 'world'")
print('hello 'world'') # 报错
输出:
hello "world"
hello 'world'
1.2 转义字符串
python中包需要打印一些特殊的字符的时候,比如单引号、双引号、换行符的输出需要用\进行转义。例如
# \n 换行符
print('今天是个好日子\n明天也是!')
输出:
今天是个好日子
明天也是!
# \t 制表符
print('name:harry\tage:18')
输出:
name:harry age:18
# \r 回车
print('abc\r111')
输出:
111
# \\ 打印一个\字符
print('\\')
输出:
\
# \' 打印单引号
print('\'')
print("'")
输出:
'
'
# \" 打印双引号
print('"')
print("\"")
输出:
"
"
1.3 字符串运算
字符串可以通过➕或✖️来进行运算,加号就是拼接乘号就是字符串的倍数,效果如下
print('demo ' + 'hello')
输出:
demo hello
print('demo ' * 3)
输出:
demo demo demo
1.4 字符串函数
python中又一些函数可以来操作字符串,比如将字符串的小写字母全部转化为大写,或者计算出某个字母在字符串中出现的次数等等,以下为部分实际例子:
# 'abc'.capitalize() 将字符串的首字母大写
print('abc')
print('abc'.capitalize())
输出:
abc
Abc
# 'abcba'.count('a') 计算a在abcba中出现的次数
print('abcba'.count('a'))
输出:
2
# 得到a、b在字符串abcba中的最初出现的位置,第1位的位置是0,依此类推。
print('abcba'.find('a'))
print('abcba'.find('b'))
输出:
0
1
# 字符串分割
name = 'hellow.world'
a,b = name.split('.')
print('a:',a)
print('b:',b)
输出:
a: hellow
b: world
# 将字符串中的大写字母全部转换为小写字母
name = 'Hello World'
print(name.lower())
输出:
hello world
# 将字符串中的小写字母全部转换为大写字母
name = 'hello world'
print(name.upper())
输出;
HELLO WORLD
# 计算出一个字符串的长度是多少
name = 'hello world'
print('字符串长度:',len(name))
输出:
字符串长度: 11
# 判断字符串是否只有大小写字母+数字组成
info_1 = 'Harry19'
info_2 = 'Harry19?'
print(info_1.isalnum())
print(info_2.isalnum())
输出:
True
False
# 判断字符串是否只有大小写字母组成
info_3 = 'AaBb'
info_4 = 'AaBb_'
print(info_3.isalpha())
print(info_4.isalpha())
输出:
True
False
# 判断字符串是否只有数字组成
info_5 = '110'
info_6 = '110+110'
print(info_5.isdigit())
print(info_6.isdigit())
输出:
True
False
1.5 字符编码
计算机发展初期多为英语国家使用,而英文字母个数不像汉语的数量那么庞大,因此早期采用ASCII表来进行字符编码,但是随着全球经济发展使用计算机的非英语国家数量大大增加了,而非英语国家如,日语,汉语和韩语等字符没有办法参照ASCII表进行编码,因此各个国家开始在原始的ASCII表里插入本国的字符编码表,如中国前期的扩展出了用于编码汉字的GB2312表。当然ASCII表只有两百多位可以使用,而早期的汉字个数就已经在8k以上了,因此这里所谓的“插入本国字符编码”其实是在原有的ASCII表里占用剩余的一位,然后将本国的编码表指向ASCII表中的一位而已。GB2312之后又经历GB18030,可扩展的汉字个数扩展到了2万以上了。
与中国一样,其它很多非英语国家都逐渐扩展出来适合自己国家的字符编码表。而各种各样的编码表出现后带来的问题就是开发出的程序或其它应用在跨国展现的时候极其容易出现乱码。为了解决这个问题国际ISO的一个标准组织发布了一个统一标准,即:Unicode也叫做统一万国码。Unicode的好处是显而易见的,但是有一点也是不能忽略的,就是Unicode规定所有字符和符号最少由16位来表示,也就是2个字节(2**16=65536)。如此一来纯英文文本的存储原本只需要一个字节现在要占用2个字节了,带来的最大坏处就是极大的浪费了我们的磁盘空间。为了解决这个问题,人们在Unicode的基础上由开发出了一个存储空间可灵活扩展或缩小的编码形式,而这个编码也正是我们现在正在使用的UTF-8.
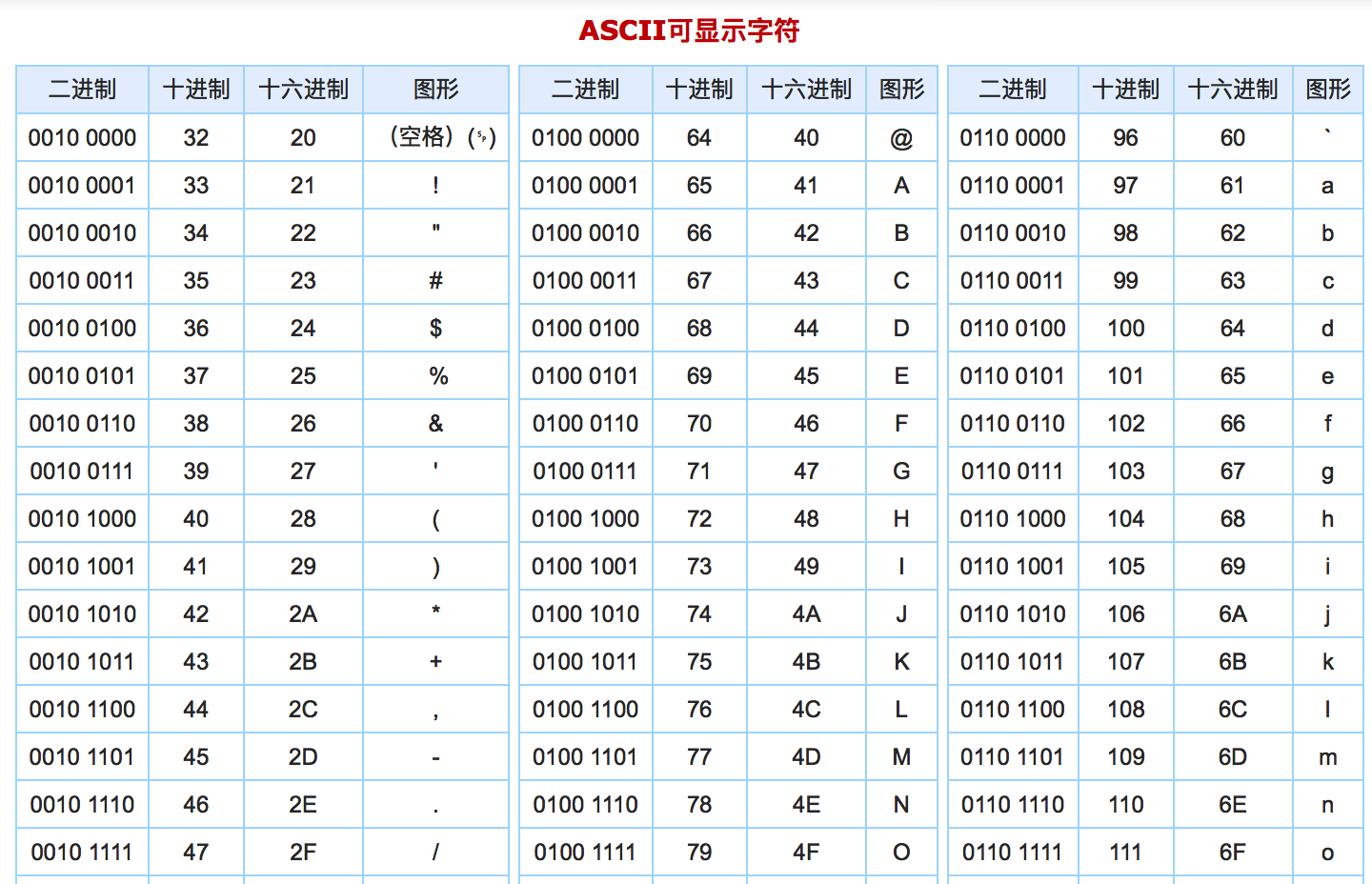
1.6 注释
python中的注释分为单行注释和多行注释,效果如下:
# 单行注释,当前行最前边的井号就是单行注释 # 多行注释使用三个引号来表示,可以是单引号也可以是三个双引号 ''' name = 'natasha' age = 19 print(name,age) ''' # 三个单引号或双引号除了做注释用还可以用于保存多行字符串,如下所示: info = ''' 外面下雨了 音乐响起了 菜场关门了 ''' print(info) 输出: 外面下雨了 音乐响起了 菜场关门了
1.7 交互程序
使用input()可以完成用户与程序间的交互,以下代码除了应用了交互外还使用+号进行字符串拼接:
name = input("please input your username:")
passwd = input('please input your password:')
age = input('please input your age:')
info = '''
---------- info of ''' + name + ''' ----------
UserName:''' + name + '''
Password:''' + passwd + '''
Age:''' + age
print(info)
输出:
please input your username:harry
please input your password:123456
please input your age:18
---------- info of harry ----------
UserName:harry
Password:123456
Age:18
1.8 格式化输出
以上交互程序中使用了字符串拼接,把通过input()接收来的字符串通过+号拼接起来看起来略显杂乱。而python的字符串格式化可以完美的解决这个问题。python格式化输出的其中一种方式就是百分号的形式%。所谓的格式化字符串就是指,在字符串中使用以%开头的字符在程序中改变字符的内容,常用的字符串有以下几种类型:
%c 单个字符 %d 十进制整数 %o 八进制整数 %s 字符串 %x 十六进制整数,其中字母小写 %X 十六进制整数,其中字母大写
仍然以1.7的代码为例,变更如下
name = input("please input your username:")
passwd = input('please input your password:')
age = int(input('please input your age:')) # input()接收的为字符串形式,通过int()函数将结果转为整数
info = '''
---------- info of %s ----------
Username:%s
Password:%s
Age:%d
''' % (name,name,passwd,age)
print(info)
输出:
please input your username:natasha
please input your password:1112223333abc
please input your age:10
---------- info of natasha ----------
Username:natasha
Password:1112223333abc
Age:10
另外一种格式化输出是使用.format()函数。而.format()函数在字符串标记有两种形式,即{变量}=变量,{下标}=变量的两种形式。使用时即在字符串中用{变量/下表}标记,然后字符串后跟.format(变量)来表示,语法如下:
》{变量}=变量
name = input("please input your username:")
passwd = input('please input your password:')
age = int(input('please input your age:'))
info = '''
---------- info of {_name}
Name: {_name}
Password: {_passwd}
Age: {_age}
'''.format(_name=name,
_passwd = passwd,
_age = age)
print(info)
输出:
please input your username:natasha
please input your password:888777
please input your age:28
---------- info of natasha
Name:natasha
Password:888777
Age:28
》{下标}=变量
name = input("please input your username:")
passwd = input('please input your password:')
age = int(input('please input your age:'))
info = '''
---------- info of {0} ----------
Name: {0}
Password:{1}
Age:{2}
'''.format(name,passwd,age)
print(info)
输出:
please input your username:akira
please input your password:222222
please input your age:78
---------- info of akira ----------
Name: akira
Password:222222
Age:78
1.9 流程控制If-Else
流程控制语句if-else为判断条件成立时执行什么,条件不成立时执行什么,在演示if-else代码前先看一段普通的输入用户名密码的代码:
import getpass # 导入getpass模块,输入密码时不可见
username = input("username:")
password = getpass.getpass("password") # 注意,getpass.getpass()在pycharm里使用会报错,可以直接在命令行执行。
print(username,password)
输出:
username:akira
password: # 密码输入了,但是并没有显示在控制台
akira 111111
通常情况下,输入用户名密码后需要判断内容是否正确,正确的话允许登录系统错误的话会返回一个报错信息。接下来用if-else来演示:
# 定义正确的用户名密码是什么
db_username = 'akira'
db_password = '111111'
username = input("请输入用户名:")
password = input("请输入密码:")
if db_username == username and db_password == password:
print('\n登录成功!\n欢迎{name}!'.format(name=username)) # \n为换行符
else:
print('\n登录失败!\n用户名{name}或密码{passwd}错误'.format(name=username,passwd=password))
正确输出:
请输入用户名:akira
请输入密码:111111
登录成功!
欢迎akira!
错误输出:
请输入用户名:akira
请输入密码:222222
登录失败!
用户名akira或密码222222错误
1.10 While循环
假定一个条件成立则一直执行符合条件的代码部分。以下实例在1.9流程控制If-Else的基础上演变而来,需求为用户第一次输入用户名密码时判断是否成功,如果第一次登录失败则之后的每一次都需要问一下用户是否仍要继续尝试登录,是则再次进行判断否则退出。
count = 0
while True:
# 定义正确的用户名密码是什么
db_username = 'akira'
db_password = '111111'
if count == 0 :
count += 1
username = input("请输入用户名:")
password = input("请输入密码:")
if db_username == username and db_password == password:
print('\n登录成功!\n欢迎{name}!\n'.format(name=username)) # \n为换行符
break
else:
print('\n登录失败!\n用户名{name}或密码{passwd}错误\n'.format(name=username, passwd=password))
elif count > 0 :
flag = input("按任意键退出,继续请按y:")
if flag == 'y':
username = input("请输入用户名:")
password = input("请输入密码:")
if db_username == username and db_password == password:
print('\n登录成功!\n欢迎{name}!\n'.format(name=username)) # \n为换行符
break
else:
print('\n登录失败!\n用户名{name}或密码{passwd}错误\n'.format(name=username, passwd=password))
else:
print('您已放弃登录,Bye!')
break
》错误输出:
请输入用户名:natasha
请输入密码:222222
登录失败!
用户名natasha或密码222222错误
按任意键退出,继续请按y:y
请输入用户名:sudo
请输入密码:333333
登录失败!
用户名sudo或密码333333错误
按任意键退出,继续请按y:n
您已放弃登录,Bye!
》正确输出:
请输入用户名:kkkkk
请输入密码:123456
登录失败!
用户名kkkkk或密码123456错误
按任意键退出,继续请按y:y
请输入用户名:akira
请输入密码:111111
登录成功!
欢迎akira!
1.11 模块
模块,在Python中可理解为一个Python文件。在创建了一个脚本文件后,模块中定义了某些函数、类和变量等。你在其他需要这些功能的文件中,导入该模块,就可重用这些函数和变量。以sys和os模块为例,代码如下
import sys # 导入sys模块 print(sys.path) # 打印环境变量 输出: ['/Users/***/PycharmProjects/python_basic/python教程/模块', '/Users/***/Documents/Python/21天学通python/源代码', '/Users/***/PycharmProjects/python_basic/python教程', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages']
sys.path为调用python的系统环境变量,python寻找模块则会在以上路径中寻找。我们所安装的第三方的库一般会安装在site-packages这个目录里。下面看一下os模块
import os #导入os模块
result_1 = os.system("dir") # os.system("dir")打印当前目录的所有文件
print(result_1)
输出:
C:\Users\***\PycharmProjects\PyDemo ��Ŀ¼
2017/07/10 19:49 <DIR> .
2017/07/10 19:49 <DIR> ..
2017/07/10 19:49 <DIR> .idea
2017/07/10 19:49 317 osDemo.py
2017/07/10 18:58 <DIR> __pycache__
1 ���ļ� 317 �ֽ�
4 ��Ŀ¼ 1,553,289,216 �����ֽ�
0
注意,os.system("dir")直接输出在控制台,同时result被赋值为0,也就是执行成功的返回值。使用os.popen().read()则可以直接将整个命令执行结果赋值给result_2
result_2 = os.popen("dir").read()
print(result_2)
输出:
2017/07/10 19:51 <DIR> .
2017/07/10 19:51 <DIR> ..
2017/07/10 19:50 <DIR> .idea
2017/07/10 19:51 317 osDemo.py
2017/07/10 18:58 <DIR> __pycache__
1 个文件 317 字节
4 个目录 1,553,018,880 可用字节
模块导入分为两种形式,即import module_name与from module_name import *两种方式,各自的调用方式均有不同;
模块路径:
-- module(文件夹)
-- main.py
-- module_A.py
module_A.py内容:
name = 'pentest123'
def say_hello():
print('module_A: say_hello')
def say_hi():
print('module_A: say_hi')
实例1: import module_name导入
import module_A print(module_A.name) # 通过模块名调用属性 module_A.say_hello() # 通过模块名调用方法 module_A.say_hi() # 通过模块名调用方法 输出: pentest123 module_A: say_hello module_A: say_hi
实例2: from module_name import * 导入
# from module_A import * 相当与把module_A里的所有内容都复制到当前py文件内一个效果,所以直接使用方法或属性。
from module_A import * say_hi() print(name) say_hello() 输出: module_A: say_hi pentest123 module_A: say_hello
实例3: 导入其他目录下的模块
目录结构及导入要求:
目录结构:
——模块
————import_package(包)
———————__init__.py
————module
———————imp_pac.py
要求:
在module目录下的imp_pac.py文件中导入“模块/import_package包”,其中待导入模块的__init__.py内容为:
print('from import_package')
def say_hello():
print('hello everyone!')
在导入其他目录下的模块前先来看几个获取python模块路径的方法:
import sys,os
print('查看Python搜索模块的路径有哪些:\n',sys.path)
输出:
查看Python搜索模块的路径有哪些:
[‘/Users/pentest/PycharmProjects/python_basic/python教程/模块/module’, ‘/Users/pentest/Documents/Python/21天学通python/源代码’, ‘/Users/pentest/PycharmProjects/python_basic/python教程’, ‘/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip’, ‘/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6’, ‘/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload’, ‘/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages’]
print('查看当前.py文件的当前路径:\n',os.path.abspath(__file__))
输出:
查看当前.py文件的当前路径:
/Users/pentest/PycharmProjects/python_basic/python教程/模块/module/imp_pac.py
print('查看当前.py文件的所在上级目录:\n',os.path.dirname(os.path.abspath(__file__)))
输出:
查看当前.py文件的所在上级目录:
/Users/pentest/PycharmProjects/python_basic/python教程/模块/module
# os.path.dirname()重复利用即可逐一回溯到更上级的目录
x1 = os.path.dirname(os.path.abspath(__file__))
print('x1目录名:',x1)
x2 = os.path.dirname(x1)
print('x2目录名:',x2)
x3 = os.path.dirname(x2)
print('x3目录名:',x3)
x4 = os.path.dirname(x3)
print('x4目录名:',x4)
print()
输出:
x1目录名: /Users/pentest/PycharmProjects/python_basic/python教程/模块/module
x2目录名: /Users/pentest/PycharmProjects/python_basic/python教程/模块
x3目录名: /Users/pentest/PycharmProjects/python_basic/python教程
x4目录名: /Users/pentest/PycharmProjects/python_basic
导入其他目录下的模块可以将被导入模块的上层目录添加到python搜索模块的路径列表中(也就是上例中的sys.path),而如何找到该包的路径名称就可以通过上述的os.path.dirname()来逐一查找,如下所示:
pt = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 找到被导入模块的上层路径
print('被导入模块的上层包为:',pt)
输出:
被导入模块的上层包为: /Users/pentest/PycharmProjects/python_basic/python教程/模块
sys.path.insert(0,pt) # 将该目录插入到python搜索模块的路径列表的第一个元素位置
print(sys.path) # 再次查看目录已被添加都列表首位
输出:
['/Users/pentest/PycharmProjects/python_basic/python教程/模块', '/Users/pentest/PycharmProjects/python_basic/python教程/模块/module', '/Users/pentest/Documents/Python/21天学通python/源代码', '/Users/pentest/PycharmProjects/python_basic/python教程', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages']
import import_package # 尝试导入该模块,发现并未报错。
输出:
from import_package
print('\n执行import_package包里的say_hello()方法:')
import_package.say_hello() # 尝试执行被导入模块里都方法
输出:
执行import_package包里的say_hello()方法:
hello everyone!
实例4:Time模块
>时间的几种表示方法:
-> 时间戳:从1970年1月1日0:00开始到当前时间为止的时间,单位为秒。 -> 格式化的时间字符串:完全按着自己所需要展现的格式去定义时间组合 -> 元组(struct_time)共九个元素,time.struct_time(tm_year=2017, tm_mon=8, tm_mday=1, tm_hour=18, tm_min=58, tm_sec=58, tm_wday=1, tm_yday=213, tm_isdst=0)
>代码部分:
import time
# 获取时间戳
print('当前时间戳:',time.time())
输出:
当前时间戳: 1501653135.0996149
# 由时间戳反转到年份,可以通过逐步转秒->分->时->天->年的方式,另一种方式是通过gmtime()或localtime()方法进行转换
t = time.time() # 计算得出从1970-01-01 00:00:00 到目前为止到秒数
min = t/60 # 计算分钟总数
hou = min/60 # 小时总数
day = hou/24 # 天总数
year = day/365 # 年总数
print('当前年:',int(year+1970)) # 年总数+1970后取整就是2017年
输出:
当前年: 2017
# gmtime()为空时输出当前时间
curt_time = time.gmtime()
print('time.gmtime()未指定时间戳:',curt_time)
输出:
time.gmtime()未指定时间戳: time.struct_time(tm_year=2017, tm_mon=8, tm_mday=2, tm_hour=5, tm_min=52, tm_sec=15, tm_wday=2, tm_yday=214, tm_isdst=0)
# gmtime()给出具体时间戳时计算对应的时间
zd_time = time.gmtime(1401639557)
print('time.gmtime()指定时间戳:',zd_time)
输出:
time.gmtime()指定时间戳: time.struct_time(tm_year=2014, tm_mon=6, tm_mday=1, tm_hour=16, tm_min=19, tm_sec=17, tm_wday=6, tm_yday=152, tm_isdst=0)
# 格式化的时间字符串
print('time.localtime()未指定时间戳:',time.localtime()) # localtime()括号内不添加秒数的时候是将当前时间格式化输出
输出:
time.localtime()未指定时间戳: time.struct_time(tm_year=2017, tm_mon=8, tm_mday=2, tm_hour=13, tm_min=52, tm_sec=15, tm_wday=2, tm_yday=214, tm_isdst=0)
print('time.localtime()指定时间戳:',time.localtime(1401639557)) # localtime()括号内指定具体秒数的时候可以转换成的对应的时间格式输出。
输出:
time.localtime()指定时间戳: time.struct_time(tm_year=2014, tm_mon=6, tm_mday=2, tm_hour=0, tm_min=19, tm_sec=17, tm_wday=0, tm_yday=153, tm_isdst=0)
# 通过time.localtime()单独获取时间元素,如年、月、日、时、分、秒等。
x = time.localtime()
print('年:',x.tm_year)
print('月:',x.tm_mon)
print('日:',x.tm_mday)
print('时:',x.tm_hour)
print('分:',x.tm_min)
print('秒:',x.tm_sec)
print('周:',x.tm_wday)
print('一年中的第几天:',x.tm_yday)
print('时区:',x.tm_isdst)
输出:
年: 2017
月: 8
日: 2
时: 13
分: 52
秒: 15
周: 2
一年中的第几天: 214
时区: 0
# 通过time.strftime()格式化输出时间,strptime(...)的用法如下所示:
%Y Year with century as a decimal number.
%m Month as a decimal number [01,12].
%d Day of the month as a decimal number [01,31].
%H Hour (24-hour clock) as a decimal number [00,23].
%M Minute as a decimal number [00,59].
%S Second as a decimal number [00,61].
%z Time zone offset from UTC.
%a Locale's abbreviated weekday name.
%A Locale's full weekday name.
%b Locale's abbreviated month name.
%B Locale's full month name.
%c Locale's appropriate date and time representation.
%I Hour (12-hour clock) as a decimal number [01,12].
%p Locale's equivalent of either AM or PM.
print('time.strftime时间格式化:',time.strftime("%Y-%m-%d %H:%M:%S"))
print('time.strftime参数:',time.strftime("%Y-%m-%d %H:%M %a %A %b %B %c %I %p"))
输出:
time.strftime时间格式化: 2017-08-02 13:52:15
time.strftime参数: 2017-08-02 13:52 Wed Wednesday Aug August Wed Aug 2 13:52:15 2017 01 PM
实例5: Random模块
import random
# 随机生成浮点数,范围为0-1之间的小数
x = random.random()
print('random.random():',x)
输出:
random.random(): 0.3629850178005113
# random.randint()随机生成指定范围之间的数字,首尾都可能会被取到
x = random.randint(5,10) # 取值范围5-10
print('random.randint(5,10):',x)
输出:
random.randint(5,10): 5
# random.randrange()随机生成指定范围之间的数字,首位可能回被取到但末尾绝对不取(顾头不顾尾)
x = random.randrange(5,10) # 取值范围:5-9
print('random.randrange(5,10):',x)
输出:
random.randrange(5,10): 6
# random.choice()随机选出括号内的元素,括号内需要是序列,例如字符串,列表等
x = random.choice('pentest')
print("random.choice('pentest'):",x)
输出:
random.choice('pentest'): e
li = [1,2,23,45,66]
x = random.choice(li)
print('random.choice([1,2,23,45,66]):',x)
输出:
random.choice([1,2,23,45,66]): 2
name = ("akira","natasha","jack","susan")
x = random.choice(name)
print('random.choice(("akira","natasha","jack","susan"))',x)
输出:
random.choice(("akira","natasha","jack","susan")) akira
# random.sample()随机选出序列中指定个数的元素。
x1 = random.sample('pentest',2)
x2 = random.sample('pentest',2)
print('random.sample()_1:',x1)
print('random.sample()_2',x2)
输出:
random.sample()_1: ['p', 'e']
random.sample()_2 ['s', 'n']
# random.uniform()随机取出给定范围内的浮点数
x = random.uniform(1,10)
print('random.uniform(1,10):',x)
输出:
random.uniform(1,10): 9.315535595496103
# random.shuffle()随机打算一个序列
items = [1,2,3,4,5,6,7,8,9,10]
print('[1,2,3,4,5,6,7,8,9,10]:',items)
random.shuffle(items)
print('random.shuffle([1,2,3,4,5,6,7,8,9,10]):',items)
输出:
[1,2,3,4,5,6,7,8,9,10]: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
random.shuffle([1,2,3,4,5,6,7,8,9,10]): [2, 9, 10, 7, 4, 1, 3, 8, 6, 5]
>制作一个6位随机数字+字母验证码
import random
checkcode = ''
for i in range(6): # 循环6次
current = random.randrange(0,6) # 每次循环取出一位随机值
if i == current: # 如果循环的次数等于该随机值,打印字母
tmp = chr(random.randint(65,90)) # chr()将十进制数字转换为ASCII表中对应的英文字母
else: # 否则打印0-9之间的随机数字
tmp = random.randint(0,9)
checkcode += str(tmp) # 将每一次获取的数字或字母添加到checkcode里即为随机验证码。
print(checkcode)
输出;
123382 / 7JH614 / 4YED09
实例6:OS模块
import os
# 获取当前被执行文件的所在路径
print(os.getcwd())
输出:
C:\Users\IH1407\PycharmProjects\PyDemo\module\osModule
# 更改路径,注意windows下路径D:\apk则应变更为D://apk
os.chdir("D://apk//dir1//dir2")
print(os.getcwd())
输出:
D:\apk\dir1\dir2
# 返回当前目录 .
print('当前目录:',os.curdir)
输出:
当前目录: .
# 返回当前目录的父目录 ..
print('当前目录的父目录:',os.pardir)
输出:
当前目录的父目录: ..
# 生成多层递归目录
os.chdir("D://apk")
os.makedirs('dir1/dir2/dir3')
输出:
文件夹:D:\apk\dir1\dir2\dir3
# 若最下层目录为空则删除并返回到上一层目录为空的话继续删除,若不为空则报错
os.removedirs('dir1/dir2/dir3')
# 生成单级目录,若目录存在则报错。
os.mkdir('testDir')
输出:
文件夹:D:\apk\testDir
# 删除单级目录,若目录不存在或目录不为空,则报错。
os.rmdir('testDir')
# 列出指定目录下的所有文件及子目录
print(os.listdir())
输出:
['111.apk', '222.txt']
# 删除一个文件,如果文件不存在则报错
print(os.listdir())
os.remove('222.txt')
print(os.listdir())
输出:
['111.apk', '222.txt']
['111.apk']
# 重命名一个文件
print(os.listdir())
os.rename('222.txt','111.txt')
print(os.listdir())
输出:
['111.apk', '222.txt']
['111.apk', '111.txt']
# 查看文件\目录信息
print(os.stat('111.txt'))
print(os.stat('111.apk'))
输出:
os.stat_result(st_mode=33206, st_ino=2814749767315451, st_dev=730660, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1501738210, st_mtime=1501738210, st_ctime=1501738210)
os.stat_result(st_mode=33206, st_ino=844424930348713, st_dev=730660, st_nlink=1, st_uid=0, st_gid=0, st_size=22208042, st_atime=1474528040, st_mtime=1476942255, st_ctime=1474528040)
# 输出操作系统的路径分隔符,windows是\,mac是/
print(os.sep)
输出:
\
# 运行系统shell命令,直接输出,下例为命令行调出计算器
print(os.system('calc'))
输出:
弹出计算机窗口
# 输出系统环境变量
print(os.environ)
输出:
environ({'ALLUSERSPROFILE': 'C:\\ProgramData', ... 'WINDIR': 'C:\\WINDOWS'})
# 将path分割成目录和文件名,并以元祖的形式返回
print('当前路径:',os.getcwd())
os.makedirs('dir1/dir2/dir3')
输出:
当前路径: D:\apk
print(os.path.split(os.getcwd()))
输出:
('D:\\', 'apk')
os.chdir('D:/apk/dir1/dir2/dir3/')
print(os.path.split(os.getcwd()))
输出:
('D:\\apk\\dir1\\dir2', 'dir3')
# 返回path的目录,其实就是os.path.split(path)的第一个元素
print(os.path.dirname(os.getcwd()))
# 返回path最后的文件名
print(os.path.basename(os.getcwd()))
输出:
D:\
apk
# 查看指定目录是否存在,如果存在返回True,否则返回False
print(os.getcwd())
print(os.path.exists('D:/apk/dir1/dir2/dir3'))
print(os.path.exists('D:/test'))
输出:
D:\apk
True
False
# 如果path是绝对路径返回True
print(os.path.isabs('dir3'))
print(os.path.isabs('D:/apk/dir1/dir2/dir3'))
输出:
False
True
# 如果文件存在返回True,否则返回False
print(os.listdir(os.getcwd()))
print(os.path.isfile('dir4.txt'))
print(os.path.isfile('111.txt'))
输出:
['111.apk', '111.txt', 'dir1']
False
True
# 如果指定path存在则返回True,否则返回False
print(os.path.isdir('D:/apk/dir1/dir2'))
print(os.path.isdir('D:/apk/dir1/dir'))
输出:
True
False
# 返回path所指向的文件或目录的最后存取时间,返回的时间格式为时间戳
print(os.path.getatime(os.getcwd()))
输出:
1501738703.7218287
#返回path所指向文件或目录的最后修改时间,返回的时间格式为时间戳
print(os.path.getmtime(os.getcwd()))
输出:
1501738703.7218287
实例7: SYS模块
>sys.exit()退出程序
import sys
# sys.exit(0)执行后后面的end将不会被打印了。
print('start')
sys.exit(0)
print('end')
'''
输出:
tdcqma:SYS $ ./sysModule.py
start
'''
>sys.argv获取参数(需要在终端进行实验)
import sys a = sys.argv print(a,type(a)) # 参数接收后保存在列表里 print(a[1:]) # 列表的第一位是脚本本身,从第二位开始才是接收来的参数,所以使用切片从下标为1的地方开始读 输出: tdcqma:SYS $ ./sysModule.py 1 2 3 4 5 (['./sysModule.py', '1', '2', '3', '4', '5'], <type 'list'>) ['1', '2', '3', '4', '5']
实例8: shutil模块(高级的文件、文件夹、压缩包处理模块)
>shutil.copy()模块复制文件
import shutil
import os
print('目录更改前:',os.getcwd()) # 查看当前目录:
# 变更目录:
os.chdir('/Users/mahaibin/Desktop')
print('目录更改后:',os.getcwd())
print()
# 创建文件1.txt'
os.system('echo pentest > 1.txt')
# 复制1.txt给2.txt(原本2.txt不存在)
shutil.copy('1.txt','2.txt')
# 因为os.listdir()为列表类型,可被for循环
for item in os.listdir():
print(item)
print('\n查看2.txt的内容:')
print(os.system('cat 2.txt'))
输出:
目录更改前: /Users/pentest/PycharmProjects/python_basic/python教程/模块/shutilModule
目录更改后: /Users/pentest/Desktop
.DS_Store
.localized
1.txt
2.txt
45个报警铃音WAV格式
查看2.txt的内容:
pentest
>shutil.copyfileobj()复制文件到另一个文件
import shutil
# f1与f2在当前目录,所以可以直接open打开
f1 = open('源文件',encoding='utf-8')
f2 = open('目标文件','w')
shutil.copyfileobj(f1,f2)
输出:
效果为f1的内容copy到f2的文件里去了。
实例9: hashlib模块,用于加密相关的操作提供了MD5、SHA224,SHA256、SHA512等算法。
将"hello python"字符串转换成16进制md5值。
import hashlib m = hashlib.md5() m.update(b"hello python") print(m.hexdigest()) 输出: e53024684c9be1dd3f6114ecc8bbdddc
一个md5对象每次update一个内容都会进行叠加,例如m1 = hello ,m1 = world , m1 = 123,那么最后一次m1.hexdigest()的md5值的对象其实是helloworld123,如:
m1 = hashlib.md5()
m1.update(b"hello")
print(m1.hexdigest())
m1.update(b"world")
print(m1.hexdigest())
m1.update(b"123")
print('m1-->',m1.hexdigest())
m2 = hashlib.md5()
m2.update(b"helloworld123")
print('m2-->',m2.hexdigest())
输出:
5d41402abc4b2a76b9719d911017c592
fc5e038d38a57032085441e7fe7010b0
m1--> cd1b8ecf103743a98958211a11e33b71
m2--> cd1b8ecf103743a98958211a11e33b71
将"hello python"字符串转换成16进制sha256值。
m3 = hashlib.sha256() m3.update(b"hello python") print(m3.hexdigest()) 输出: 373a23512f9531ad49ec6ad43ecdda58df01e59d9ec5812d601fd05cc53345d3
将包含中文的字符串转换成16进制md5值
m4 = hashlib.md5()
m4.update("战狼2真好看".encode(encoding="utf-8"))
print(m4.hexdigest())
输出:
ba284db74431c77acf84a309240a4a28
实例10: re模块(正则表达式)
常用正则表达式符号
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
'\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
(摘自alex金角大王的cnblog)
匹配特定字符开头
my_str = 'tianwanggaidihu1212'
res1 = re.match('^tian',my_str) # 在my_str中匹配是否由"tian"开头,如果匹配到有输出下标
print(res1)
res2 = re.match('^di',my_str) # 在my_str中匹配是否由"di"开头,如果没有匹配到返回None
print(res2)
输出:
<_sre.SRE_Match object; span=(0, 4), match='tian'>
None
匹配开头是任意字符,第二位是数字
my_str = "w2192olegequ123"
res1 = re.match("^.\d",my_str) # \d代表匹配一个数字
print(res1)
输出:
<_sre.SRE_Match object; span=(0, 2), match='w2'>
匹配开头是任意字符,后面跟着连续N位都是数字
import re
my_str = "h2310238feihong"
res1 = re.match("^.\d+",my_str)
print(res1)
输出:
<_sre.SRE_Match object; span=(0, 8), match='h2310238'>
匹配结尾是否是由连续N位数字结束
import re
my_str = "ChengfengPolang000"
res1 = re.search("\d+$",my_str)
print(res1)
输出:
<_sre.SRE_Match object; span=(15, 18), match='000'>
匹配*号前的字符0次或多次
import re
my_str = "zhiquuweiquuuuShan1q110"
res = re.findall("qu*",my_str) # u可以为0次匹配即q,或者多次qu、quu、quuu...
print(res)
输出:
['quu', 'quuuu', 'q']
匹配指定长度的数字,N{m}代表匹配N这个字符m次,注意看re.search与re.findall的区别
import re
my_str = "woaib23232eijingtia98989nan23sdfmen1"
res1 = re.search("\d{5}",my_str) # \d代表匹配数字,re.search只匹配最初符合条件的字符
print(res1)
res2 = re.findall("\d{5}",my_str) # re.findall匹配所有符合条件的字符
print(res2)
输出:
<_sre.SRE_Match object; span=(5, 10), match='23232'>
['23232', '98989']
匹配所有出现指定范围内的数字,[0-9]{a,b}代表出现a到b次0-9之间的任意数字
import re
my_str = "woaib23232eijingtia98989nan23sdfmen1"
res1 = re.findall("[0-9]{1,5}",my_str)
print(res1)
输出:
['23232', '98989', '23', '1']
匹配 |(或)左右两边的字符
import re
my_str = "woaib23232eijingtia98989nan23sdfmen1"
res1 = re.findall("woai|jingtia",my_str)
print(res1)
res2 = re.search("woai|jingtia",my_str)
print(res2)
print(res2.group())
输出:
['woai', 'jingtia']
<_sre.SRE_Match object; span=(0, 4), match='woai'>
woai
匹配分组,用()扩起来的可以看作一个单独的对象进行匹配
import re
my_str = "TESTTEST111TESTtest222"
res1 = re.findall("TEST{2}",my_str)
print(res1)
输出:
['TESTT']
res2 = re.findall("(TEST){2}",my_str)
print(res2)
输出:
['TEST']
res3 = re.search("TEST{2}",my_str)
print(res3)
输出:
<_sre.SRE_Match object; span=(0, 5), match='TESTT'>
res4 = re.search("(TEST){2}",my_str)
print(res4)
输出:
<_sre.SRE_Match object; span=(0, 8), match='TESTTEST'>
\A代表匹配开始字符,\Z代表匹配结束字符
import re
# re.search("\A[0-9].*[a-z]\Z",my_str)代表匹配开头是数字,中间是任意内容,末尾必须是小写字母的字符
my_str1 = "1232KHJKJlkda"
res1 = re.search("\A[0-9].*[a-z]\Z",my_str1)
print(res1)
输出:
<_sre.SRE_Match object; span=(0, 13), match='1232KHJKJlkda'>
# re.search("\A[0-9]+[a-z]\Z",mystr)代表只匹配数字+小写字母
my_str2 = "123abc"
my_str3 = "123a"
res2 = re.search("\A[0-9]+[a-z]\Z",my_str2)
res3 = re.search("\A[0-9]+[a-z]\Z",my_str3)
print(res2)
print(res3)
输出:
None
<_sre.SRE_Match object; span=(0, 4), match='123a'>
匹配除了数字之外的其他任意字符
import re
my_str = "2233-lkaP*098"
res = re.search("\D+",my_str) # \D代表除数字外的任意字符
print(res)
print(res.group())
输出:
<_sre.SRE_Match object; span=(4, 10), match='-lkaP*'>
-lkaP*
匹配[0-9a-zA-Z]字符,用\w来表达,匹配除了[0-9a-zA-Z]之外的字符用\W来表达。
import re
my_str = "##123abcCDE!!"
res1 = re.search("\w+",my_str) # 小写的w
print(res1)
print(res1.group())
输出:
<_sre.SRE_Match object; span=(2, 11), match='123abcCDE'>
123abcCDE
res2 = re.search("\W+",my_str) # 大写的W
print(res2)
print(res2.group())
输出:
<_sre.SRE_Match object; span=(0, 2), match='##'>
##
匹配空白字符
import re
my_str = "a b\nbc\t123 def\n((("
res1 = re.search("\s+",my_str)
print(res1)
输出:
<_sre.SRE_Match object; span=(1, 2), match=' '>
res2 = re.findall("\s+",my_str)
print(res2)
输出:
[' ', '\n', '\t', ' ', '\n']
1.12 列表
列表是一个数据集合,用[ ]扩起来且以“,”进行分割,列表里面可以包含任何数据类型,如对象、列表等等。
# 创建一个空列表
result = list()
print(result)
输出:
[]
# 创建含有两个元素的列表
result = [1,2]
print(result)
输出:
[1, 2]
# 创建包含不同类型元素的列表
result = ['a',False,2,1.342]
print(result)
输出:
['a', False, 2, 1.342]
# append()在列表末尾添加元素
result = [1,2,3,4,5]
print('原始result:',result)
result.append(6)
print('更新result:',result)
输出:
原始result: [1, 2, 3, 4, 5]
更新result: [1, 2, 3, 4, 5, 6]
# count()返回被选中元素在列表中出现的次数
result = ['a','b',1,False,'a','b','c','d']
num = result.count('a')
print(num)
输出:
2
# extend()可以连接两个列表里所有的元素
list_a = ['a','b','c']
list_b = [1,2,3]
list_a.extend(list_b)
print(list_a)
输出:
['a', 'b', 'c', 1, 2, 3]
# 查找被选中元素在列表中的位置,注意起始位置从0开始
result = ['ab','weiu','^&hl',121231,'hello',0.0001,True,[1,2,3]]
num = result.index('hello')
print(num)
输出:
4
# insert()函数在列表的指定位置上插入一个元素
list_a = ['a','b','c']
list_a.insert(0,'*')
print(list_a)
输出:
['*', 'a', 'b', 'c']
# pop()可将列表中的最后一个元素删除并且返回被删除的元素。
list_a = ['ab','weiu','^&hl',121231,'hello',0.0001,True,[1,2,3]]
print('删除前:',list_a)
result = list_a.pop()
print('删除元素:',result)
print('删除后:',list_a)
输出:
删除前: ['ab', 'weiu', '^&hl', 121231, 'hello', 0.0001, True, [1, 2, 3]]
删除元素: [1, 2, 3]
删除后: ['ab', 'weiu', '^&hl', 121231, 'hello', 0.0001, True]
# remove(元素),删除元素。注意括号内的不是下标而是元素的内容
list_a = ['ab','weiu','^&hl',121231,'hello',0.0001,True,[1,2,3]]
print('删除前:',list_a)
print('删除元素:',list_a[0])
list_a.remove('ab')
print('删除后:',list_a)
输出:
删除前: ['ab', 'weiu', '^&hl', 121231, 'hello', 0.0001, True, [1, 2, 3]]
删除元素: ab
删除后: ['weiu', '^&hl', 121231, 'hello', 0.0001, True, [1, 2, 3]]
# reverse()反转列表
list_c = [1,2,3,4,5,'a','b','c','d','e']
print('反转前:',list_c)
list_c.reverse()
print('反转后:',list_c)
输出:
反转前: [1, 2, 3, 4, 5, 'a', 'b', 'c', 'd', 'e']
反转后: ['e', 'd', 'c', 'b', 'a', 5, 4, 3, 2, 1]
# sort(),给列表排序,数据类型需一致,否则报错
list_a = [1,267,0,986,5,-12,8,97,223]
print('排序前:',list_a)
list_a.sort()
print('排序后:',list_a)
输出:
排序前: [1, 267, 0, 986, 5, -12, 8, 97, 223]
排序后: [-12, 0, 1, 5, 8, 97, 223, 267, 986]
list_b = ['r','g','v','e','j','s','k']
print('排序前:',list_b)
list_b.sort()
print('排序后:',list_b)
输出:
排序前: ['r', 'g', 'v', 'e', 'j', 's', 'k']
排序后: ['e', 'g', 'j', 'k', 'r', 's', 'v']
# 列表切片,list[a,b]代表从a的位置开始,截取到b-1下标位置的元素
list_a = ["zhangsan","harry","akira","natasha"]
result = list_a[0:2]
print(result)
输出:
['zhangsan', 'harry']
# 列表切片,负数表示从末尾开始取值,最后一个值的下标记为-1,从列表右侧向左侧第二个值的下标为-2,以此类推
list_a = ["zhangsan","harry","akira","natasha"]
result = list_a[-1]
print(result)
输出:
natasha
# 列表切片,特殊情况为负数切片的时候如果想获取到最后一个元素(最右侧的元素),原list[-a:-b]必须写成list[-a:]
list_a = ["zhangsan","harry","akira","natasha"]
result = list_a[-3:-1] # 只能获取到['harry', 'akira']
print(result)
result = list_a[-3:]
print(result)
输出:
['harry', 'akira']
['harry', 'akira', 'natasha']
# clear()用于清空列表的所有元素内容
list_b = [1,2,3,4,5]
print('clear前:',list_b)
list_b.clear()
print('clear后:',list_b)
输出:
clear前: [1, 2, 3, 4, 5]
clear后: []
1.13 元组
元组可以看成是一组特殊的列表,与列表不同之处在于元组一经创建就不能被改变了,即不能对元组里的数据进行删除、更改甚至添加。因此元组通常用于存放一组不允许被用户修改的数据。另外,列表使用[ ]扩起来,而元组则是使用( )扩起来。
# 创建空元组
result = tuple()
print(result)
输出:
()
# 创建只有一个元素的元组
result = ('h',)
print(result,'\n类型:',type(result))
输出:
('h',)
# 创建一个多元素的元组,并尝试修改
result = ('ab','weiu','^&hl',121231,'hello',0.0001,True,[1,2,3])
print('第一个元素:',result[0])
result[0] = 'cd'
print(result)
输出:
Traceback (most recent call last):
File "/Users/***/PycharmProjects/python_basic/python教程/元组/tupleDemo.py", line 19, in <module>
result[0] = 'cd'
TypeError: 'tuple' object does not support item assignment
1.14 字典
字典(dict)也是一种数据类型,是由大括号{ }括起来同时以“键:值”对的形式来表现的,字典不像列表有下标,字典里没有下标概念所以字典是无序的。而如果想要访问字典里的内容则需要通过“键”来访问“值”
# 创建一个空的字典
result = {}
print(result,type(result))
输出:
{} <class 'dict'>
# 创建一个空的字典
result = dict()
print(result,type(result))
输出:
{} <class 'dict'>
# 通过“键”来获取“值”
dicDem = {'harry':20,'akira':19,'daniel':22,'susan':17}
print('字典内容:',dicDem)
res = dicDem["harry"]
print('harry的值:',res)
输出:
字典内容: {'harry': 20, 'akira': 19, 'daniel': 22, 'susan': 17}
harry的值: 20
# 试图用下标来获取值,因为字典通过“键”来获取,所以通过下标获取值的时候会报错。
dicDem = {'harry':20,'akira':19,'daniel':22,'susan':17}
res = dicDem[1]
print(res)
输出报错:
Traceback (most recent call last):
File "C:/Users/IH1407/PycharmProjects/PyDemo/Dict/dictDemo.py", line 24, in <module>
res = dicDem[1]
KeyError: 1
# dic.clear(),清除字典内容
dic_1 = {'a':1,'b':2,'c':3}
print('清除前:',dic_1)
dic_1.clear()
print('清除后:',dic_1)
输出:
清除前: {'a': 1, 'b': 2, 'c': 3}
清除后: {}
# dic.copy(),复制字典给另一个字典
dic_1 = {'a':1,'b':2,'c':3}
dic_2 = dic_1.copy()
print('dic_2复制了dic_1的键-值:',dic_2,type(dic_2))
输出:
dic_2复制了dic_1的键-值: {'a': 1, 'b': 2, 'c': 3} <class 'dict'>
# dic.get('k',[指定值]),要求字典返回键"k"所对应的值,如果没有则返回中括号内的“指定值”
dic_1 = {'a':1,'b':2,'c':3}
res = dic_1.get('a',['无值'])
print(res)
res = dic_1.get('d',['无值'])
print(res)
输出:
1
['无值']
# 获得由键和值组成的迭代器
dicDem = {'harry':20,'akira':19,'daniel':22,'susan':17}
print('键值迭代器:',dicDem.items())
输出:
键值迭代器: dict_items([('harry', 20), ('akira', 19), ('daniel', 22), ('susan', 17)])
# 获取由键组成的迭代器
dicDem = {'harry':20,'akira':19,'daniel':22,'susan':17}
print('键迭代器:',dicDem.keys())
输出:
键迭代器: dict_keys(['harry', 'akira', 'daniel', 'susan'])
# 获取由值组成的迭代器
dicDem = {'harry':20,'akira':19,'daniel':22,'susan':17}
print('值迭代器:',dicDem.values())
输出:
值迭代器: dict_values([20, 19, 22, 17])
# 删除指定键值对
dicDem = {'harry':20,'akira':19,'daniel':22,'susan':17}
dicDem.pop('harry')
print('删除键值:',dicDem)
输出:
删除键值: {'akira': 19, 'daniel': 22, 'susan': 17}
# 合并两个字典,如果有相同的键值就覆盖掉相同的部分,如果没有相同的部分就创建新的键值。
dic_1 = {'a':1,'b':2,'c':3}
dic_2 = {'c':3,'d':4,'e':5,'f':6}
dic_1.update(dic_2) #因为dic_2与dic_1中的'c':3键值是重复的,所以覆盖。
print('两个字典合并后:',dic_1)
输出:
两个字典合并后: {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
# 从字典中删除任意键值,并返回删除的键值
dicDem = {'harry':20,'akira':19,'daniel':22,'susan':17}
res = dicDem.popitem()
print('删除的键值:',res)
print('删除后的字典:',dicDem)
输出:
删除的键值: ('susan', 17)
删除后的字典: {'harry': 20, 'akira': 19, 'daniel': 22}
#
dicDem = {'harry':20,'akira':19,'daniel':22,'susan':17}
res = dicDem.setdefault('harry',18)
print('harry(有):',res)
res = dicDem.setdefault('merry',18)
print('merry(无):',res)
输出:
harry(有): 20
merry(无): 18
1.15 购物车实例
需求:
1. 要求用户输入一个金额,然后打印商品列表
2. 用户对想要买的商品通过商品编号将商品加入购物车
3. 用户可多次添加商品到购物车,订单金额小于用户输入金额允许购买,否则提示余额不足。
salary = int(input('请输入您的金额:'))
goods = [['1','iphone',7200],['2','imac pc',12000],['3','benz car',600000],['4','big house',1500000]]
shopping_car = []
my_goods = []
fgx = '-'.center(40,'-')
count = 0
money = 0
flag = True
while flag:
print('\n商品列表:')
for i in goods:
print(i[0],'\t',i[1],'\t',i[2])
goods_num = input('\n请选择您要购买商品的序号以加入购物车:')
for i in goods:
if i[0] == goods_num:
shopping_car.append(i)
print('\n已加入购物车的商品:')
for j in shopping_car:
print('>>',j[1],'\t',j[2],'元')
money = money + int(shopping_car[count][2])
count += 1
conf = input('\n继续购买请按[C],去购物车支付请安[Y]: ')
if conf == 'c':
continue
elif conf == 'y':
conf_2 = input('您的商品订单总额为{price},确认付款请按[Y]: '.format(price=money))
if conf_2 == 'y':
if salary >= money:
salary = salary - money
print(fgx,'\n\n购买成功!当前余额:',salary)
break
else:
print('余额不足,请充值。')
break
输出1:
请输入您的金额:20000
商品列表:
1 iphone 7200
2 imac pc 12000
3 benz car 600000
4 big house 1500000
请选择您要购买商品的序号以加入购物车:1
已加入购物车的商品:
>> iphone 7200 元
继续购买请按[C],去购物车支付请安[Y]: c
商品列表:
1 iphone 7200
2 imac pc 12000
3 benz car 600000
4 big house 1500000
请选择您要购买商品的序号以加入购物车:2
已加入购物车的商品:
>> iphone 7200 元
>> imac pc 12000 元
继续购买请按[C],去购物车支付请安[Y]: y
您的商品订单总额为19200,确认付款请按[Y]: y
----------------------------------------
购买成功!当前余额: 800
输出2:
请输入您的金额:20000
商品列表:
1 iphone 7200
2 imac pc 12000
3 benz car 600000
4 big house 1500000
请选择您要购买商品的序号以加入购物车:1
已加入购物车的商品:
>> iphone 7200 元
继续购买请按[C],去购物车支付请安[Y]: c
商品列表:
1 iphone 7200
2 imac pc 12000
3 benz car 600000
4 big house 1500000
请选择您要购买商品的序号以加入购物车:2
已加入购物车的商品:
>> iphone 7200 元
>> imac pc 12000 元
继续购买请按[C],去购物车支付请安[Y]: c
商品列表:
1 iphone 7200
2 imac pc 12000
3 benz car 600000
4 big house 1500000
请选择您要购买商品的序号以加入购物车:3
已加入购物车的商品:
>> iphone 7200 元
>> imac pc 12000 元
>> benz car 600000 元
继续购买请按[C],去购物车支付请安[Y]: y
您的商品订单总额为619200,确认付款请按[Y]: y
余额不足,请充值。
1.16 文件读写
文件和文件处理是任何高级语言都不可缺少的一部分,Python语言提供了丰富的文件操作功能,包括文件读写操作、处理文件中的数据、fileinput操作文件及目录操作等等。
测试读写文件1:testfile.txt
中国是世界上文明发达最早的国家之一,有将近4000年的有文字可考的历史。 中国古代史经历了以下几个阶段:原始社会(170万年前-公元前2070年)、奴隶社会(公元前2070年-公元前476年)和封建社会。 其中封建社会可分为五个阶段:东周、秦、汉是封建社会形成和初步发展阶段。 三国、两晋、南北朝,是封建国家分裂和民族大融合的阶段。 隋唐五代时期是封建社会的繁荣阶段。辽、宋、夏、金、元,是民族融合进一步加强和封建经济继续发展的阶段。 明、清,是统一的多民族国家巩固和封建制度渐趋衰落阶段。
测试读写文件2:pythonFile.txt
AAUUAA BJBBBB CCCCAC DDDDDB EEAEEE
测试代码:
# open("filename","r/w/a/b",encoding="字符集"),read()表示读取文件全部内容到内存文件对象中。
f = open("testfile.txt",'r',encoding="utf-8")
print(f.read())
f.close()
输出:
中国是世界上文明发达最早的国家之一,有将近4000年的有文字可考的历史。
中国古代史经历了以下几个阶段:原始社会(170万年前-公元前2070年)、奴隶社会(公元前2070年-公元前476年)和封建社会。
其中封建社会可分为五个阶段:东周、秦、汉是封建社会形成和初步发展阶段。
三国、两晋、南北朝,是封建国家分裂和民族大融合的阶段。
隋唐五代时期是封建社会的繁荣阶段。辽、宋、夏、金、元,是民族融合进一步加强和封建经济继续发展的阶段。
明、清,是统一的多民族国家巩固和封建制度渐趋衰落阶段。
# read()括号内添加数字表示读取的字符个数。注意此字符既包括英文又包括汉字。
f = open("testfile.txt",'r',encoding="utf-8")
print(f.read(3))
f.close()
输出:
中国是
# readline()方法执行一次便打印其中一行,执行两次打印其中两行,以此类推。
f = open('testFile.txt','r',encoding='utf-8')
print(f.readline())
print(f.readline())
f.close()
输出:
中国是世界上文明发达最早的国家之一,有将近4000年的有文字可考的历史。
中国古代史经历了以下几个阶段:原始社会(170万年前-公元前2070年)、奴隶社会(公元前2070年-公元前476年)和封建社会。
# readlines()则将文件内容全部打印,并且以列表到形式保存每一行,即每一行都是列表到一个元素。
f = open('testFile.txt','r',encoding='utf-8')
print(f.readlines())
f.close()
输出:
['中国是世界上文明发达最早的国家之一,有将近4000年的有文字可考的历史。\n', '中国古代史经历了以下几个阶段:原始社会(170万年前-公元前2070年)、奴隶社会(公元前2070年-公元前476年)和封建社会。\n', '其中封建社会可分为五个阶段:东周、秦、汉是封建社会形成和初步发展阶段。\n', '三国、两晋、南北朝,是封建国家分裂和民族大融合的阶段。\n', '隋唐五代时期是封建社会的繁荣阶段。辽、宋、夏、金、元,是民族融合进一步加强和封建经济继续发展的阶段。\n', '明、清,是统一的多民族国家巩固和封建制度渐趋衰落阶段。']
# open('filename','w/a',encoding='utf-8'),wirte()函数是将内容写入到文件中。
# 模式选择'w',即赋予写权限,同时在写入到时候将原有内容全部清除后再写,使用该模式时请慎重选择。
f = open('testFile.txt','w',encoding='utf-8')
f.write('write test')
f.close()
f = open('testFile.txt','r',encoding='utf-8')
print(f.read())
f.close()
输出(写入到文件的内容):
write test
实例1: 使用while循环打印readline()
f = open('testFile.txt','r',encoding='utf-8')
print(f.readline())
while True:
line = f.readline()
print(line)
if not line:
break
f.close()
输出:
中国是世界上文明发达最早的国家之一,有将近4000年的有文字可考的历史。
中国古代史经历了以下几个阶段:原始社会(170万年前-公元前2070年)、奴隶社会(公元前2070年-公元前476年)和封建社会。
其中封建社会可分为五个阶段:东周、秦、汉是封建社会形成和初步发展阶段。
三国、两晋、南北朝,是封建国家分裂和民族大融合的阶段。
隋唐五代时期是封建社会的繁荣阶段。辽、宋、夏、金、元,是民族融合进一步加强和封建经济继续发展的阶段。
明、清,是统一的多民族国家巩固和封建制度渐趋衰落阶段。
实例2: 使用for循环打印readline()
f = open('testFile.txt','r',encoding='utf-8')
for line in f:
print(line)
f.close()
输出:
中国是世界上文明发达最早的国家之一,有将近4000年的有文字可考的历史。
中国古代史经历了以下几个阶段:原始社会(170万年前-公元前2070年)、奴隶社会(公元前2070年-公元前476年)和封建社会。
其中封建社会可分为五个阶段:东周、秦、汉是封建社会形成和初步发展阶段。
三国、两晋、南北朝,是封建国家分裂和民族大融合的阶段。
隋唐五代时期是封建社会的繁荣阶段。辽、宋、夏、金、元,是民族融合进一步加强和封建经济继续发展的阶段。
明、清,是统一的多民族国家巩固和封建制度渐趋衰落阶段。
实例3: 定义一个函数,只打印文件中偶数行的内容
def file_hdl(name):
f = open(name)
i = 0
print('打印偶数行内容:')
for line in f :
i += 1
if i % 2 == 0 :
print('第%s行:' % i,line)
else:
continue
f.close()
file_hdl('testFile.txt')
输出:
打印偶数行内容:
第2行: 中国古代史经历了以下几个阶段:原始社会(170万年前-公元前2070年)、奴隶社会(公元前2070年-公元前476年)和封建社会。
第4行: 三国、两晋、南北朝,是封建国家分裂和民族大融合的阶段。
第6行: 明、清,是统一的多民族国家巩固和封建制度渐趋衰落阶段。
实例4: 使用with语句来进行文件管理,同时定义函数只打印奇数行内容
def file_hdl(name):
with open(name) as f:
i = 0
for line in f:
i += 1
if i % 2 != 0:
print('第{line_row}行:{line_cont}'.format(line_row=i,line_cont=line))
f.close()
file_hdl('testFile.txt')
输出:
第1行:中国是世界上文明发达最早的国家之一,有将近4000年的有文字可考的历史。
第3行:其中封建社会可分为五个阶段:东周、秦、汉是封建社会形成和初步发展阶段。
第5行:隋唐五代时期是封建社会的繁荣阶段。辽、宋、夏、金、元,是民族融合进一步加强和封建经济继续发展的阶段。
实例5: 使用fileinput模块读取两个文件到列表中,然后依次识别文件名,并打印单一文件行数、总文件行数以及文件内容,line.strip()去掉空白行,同时找出包含'会'与'A'的行。
import fileinput
with fileinput.input(['testFile.txt','pythonFile.txt']) as lines:
for line in lines:
if fileinput.isfirstline():
print('\n>>>当前文件名称:{file_name}'.format(file_name=fileinput.filename()))
print(' 总第%d行\t当前文件的第%d行\t内容:%s' % (fileinput.lineno(),fileinput.filelineno(),line.strip()))
if line.count('会') != 0:
print(' >>第%d行有%d个\'会\'\n' %(fileinput.lineno(),line.count('会')))
if line.count('A') != 0:
print(' >>第%d行有%d个\'A\'\n' %(fileinput.lineno(),line.count('A')))
输出:
>>>当前文件名称:testFile.txt
总第1行 当前文件的第1行 内容:中国是世界上文明发达最早的国家之一,有将近4000年的有文字可考的历史。
总第2行 当前文件的第2行 内容:中国古代史经历了以下几个阶段:原始社会(170万年前-公元前2070年)、奴隶社会(公元前2070年-公元前476年)和封建社会。
>>第2行有3个'会'
总第3行 当前文件的第3行 内容:其中封建社会可分为五个阶段:东周、秦、汉是封建社会形成和初步发展阶段。
>>第3行有2个'会'
总第4行 当前文件的第4行 内容:三国、两晋、南北朝,是封建国家分裂和民族大融合的阶段。
总第5行 当前文件的第5行 内容:隋唐五代时期是封建社会的繁荣阶段。辽、宋、夏、金、元,是民族融合进一步加强和封建经济继续发展的阶段。
>>第5行有1个'会'
总第6行 当前文件的第6行 内容:明、清,是统一的多民族国家巩固和封建制度渐趋衰落阶段。
>>>当前文件名称:pythonFile.txt
总第7行 当前文件的第1行 内容:AAUUAA
>>第7行有4个'A'
总第8行 当前文件的第2行 内容:BJBBBB
总第9行 当前文件的第3行 内容:CCCCAC
>>第9行有1个'A'
总第10行 当前文件的第4行 内容:DDDDDB
总第11行 当前文件的第5行 内容:EEAEEE
>>第11行有1个'A'
1.17 目录操作
python的os模块提供了一些操作文件和目录的功能,可以很方便的重命名文件名、添加删除目录、复制目录文件等操作。
import os
# 当前目录路径: os.getcwd()
print('当前目录路径:',os.getcwd())
输出:
当前目录路径: /Users/pentest/PycharmProjects/python_basic/python教程/文件与文件系统/directory
# 列出当前执行文件所在目录的所有文件
print('获取当前目录所有文件:',os.listdir())
输出:
获取当前目录所有文件: ['direDemo.py', 'subDirec', '三国演义.mp4', '工资单.txt']
# 列出指定目录下的文件
print('列出指定目录内容:',os.listdir('/Users/pentest/learngit'))
输出:
列出指定目录内容: ['.DS_Store', 'hello python']
# 使用os.mkdir()创建目录,所创建的目录必须是不存在的,否则报错。
os.mkdir('/Users/pentest/learngit/python')
print('添加目录python后:',os.listdir('/Users/pentest/learngit'))
输出:
添加目录python后: ['.DS_Store', 'hello python', 'python']
# 删除目录,使用os.rmdir()删除的目录必须是空目录,必须是已存在的目录,否则都会报错
os.rmdir('/Users/pentest/learngit/python')
print('删除目录python后:',os.listdir('/Users/pentest/learngit/'))
输出:
删除目录python后: ['.DS_Store', 'hello python']
# 判断是否是目录
print(os.path.isdir('/Users/pentest'))
print(os.path.isdir('工资单.txt'))
输出:
True
False
# 判断是否是文件
print(os.path.isfile('/Users/pentest'))
print(os.path.isfile('工资单.txt'))
输出:
False
True
# 使用os.walk(path)可以遍历某目录下所有的文件和目录,但是os.walk()的返回对象只是一个可以迭代的生成器对象,如果想要打印每个元素可以通过for循环进行打印。打印结果保存在元组中,单引号扩起来的是目录,后边用[]扩起来的是每个元素内容。
result = os.walk('./') # 指定当前目录
print(result,type(result))
for i in result:
print(i)
输出:
<generator object walk at 0x102a144c0> <class 'generator'>
('./', ['subDirec'], ['direDemo.py', '三国演义.mp4', '工资单.txt'])
('./subDirec', [], ['wolegequ.html'])
实例1: 批量收集文件,并汇总各类信息到excel表格
用户需求:
1)接收用户输入一个路径,该路径中包含待收集文件,且文件名的组成方式为用户名 + 2位数字ID号 + .txt后缀
2)用户执行脚本后应自动生成后缀为.xls的excel文件,且表格中应包含目录文件的ID列,用户姓名列以及文件内容列。
3)待收集文件路径
$ pwd
/Users/pentest/learngit/userInfo/
4)待收集文件列表
$ ll
total 24
-rw-r--r-- 1 pentest staff 28 7 19 11:20 akira33.txt
-rw-r--r--@ 1 pentest staff 87 7 19 13:31 harry99.txt
-rw-r--r-- 1 pentest staff 40 7 19 11:20 natasha12.txt
代码实现:
import os
import fileinput
filenames = []
fname = 'userInfo_'
file_path = input('please input file path: ')
# for循环中变量a,b,files分别代表以下含义:
# a = ./userInfo 文件执行路径
# b = [] 空列表
#files = ['akira33.txt', 'natasha12.txt','harry99.txt'] files才是要操作的用户信息
# 将目录中所有文件名(不包括后缀)全部添加到filenames列表里。
for a,b,files in os.walk(file_path):
if files:
index = 0
filenames.append([file[:-4] for file in files])
i = 0
for files in filenames:
# 生成新文件用于保存用户信息,文件名组成方式:userInfo_ + 数字 + .xls
f = open(fname+str(i)+'.xls','w',encoding='utf-8')
# 在第一行中写入'UserId','UserName','Summary'到三个列
count = 0
for name in files:
if count == 0 :
f.write('UserId'+'\t'+'UserName'+'\t'+'Summary'+'\n')
# 以只读模式打开./userInfo/name.txt文件,如harry99.txt,natasha12.txt等
f_cont = open(file_path+name+'.txt','r',encoding='utf-8')
# 向新建文件里写入用户信息,包括:文件名后两位的ID号+第1位到倒数后两位之间的用户名+对应文件的内容
f.write(name[-2:]+'\t'+name[:-2]+'\t'+f_cont.read()+'\n')
count += 1
f.close()
i += 1
print('新文件生成成功!')
输出:
please input file path: /Users/pentest/learngit/userInfo/
新文件生成成功!

1.18 函数
Python函数类别有内建函数和自定义函数,其中内建函数就是以上实例中多次用到的方法,例如range(),input()及数据类型转换函数等等。但是很多时候开发者需要解决自己的实际问题的时候内建函数未必够用,这个时候就需要自己写函数了,这个就是所谓的自定义函数。而使用函数的好处就是可以调用函数来完成一些重复性的工作,且结构清晰易于维护。
声明函数
def <函数名> (参数列表):
<函数语句>
return 返回值
其中,参数列表与return返回值都不是必须的,当没有return语句或者return后没有返回值的时候均会返回None。
应用函数:
# 定义并调用函数,打印hello,python
def hello(): # 声明函数
print('hello,python')
hello() # 调用函数
输出:
hello,python
# 定义一个有参数列表的函数,调用时需给出符合函数计算的参数
def tpl_sum(arg):
result = 0
for item in arg:
result += item
return result
result2 = tpl_sum([1,2,3,4,5])
print(result2)
输出:
15
# 默认值参数,函数可以设定一个默认值参数,如果调用时不给出其他参数那么就会执行默认值参数,以下代码中需要给出参数有name和age,其中age设定了默认值18岁,如果用户在调用函数的时候没有给定具体age值,那么默认输出18。注意事项,含有默认值的参数需要放在参数列表的最后面,否则会报错。
def userInfo(name,age=18):
print('my name is %s,and i\'m %d !' % (name,age))
userInfo('harry',20)
userInfo('akira') #调用时没有给定具体age值则输出默认age值18。
输出:
my name is harry,and i'm 20 !
my name is akira,and i'm 18 !
# 参数传递(按照参数名匹配传递):一般情况下在调用python的函数时会依据函数的参数列表的顺序进行传参,但python提供了形为"关键字=关键字"的参数传递方式,如此以来就不必按着函数参数列表的顺序进行传参了。
def userInfo(name,age):
print('my name is %s,and i\'m %d !' % (name, age))
userInfo(age=20,name='daniel') # 传递参数时未按顺序给出参数。
输出:
my name is daniel,and i'm 20 !
实例1: 充分理解函数调用的可重用性,一致性以及可扩展性
以下代码中,函数test1、test2、test3均会调用logger()函数,起初logger函数完成的功能只是将"end action"写入到def_test1.txt文件中。但新的需求提出需要继续在logger函数中日志的前面添加时间模块,而新添加的时间模块均可以在调用logger函数的其他函数里有体现,也就是说修改了logger函数后就不需要再在其他几个函数里分别进行添加时间模块了。由此充分体现了函数调用的可重用性,一致性以及可扩展性。
import time
def logger():
time_format = '%Y-%m-%d %X' # %X代表小时:分钟:秒
time_current = time.strftime(time_format)
with open('def_test1.txt','a+',encoding='utf-8') as f:
f.write('%s : end action\n' % time_current)
f.close()
def test1():
print('in the test1')
logger()
def test2():
print('in the test2')
logger()
def test3():
print('in the test3')
logger()
test1()
test2()
test3()
输出(控制台):
in the test1
in the test2
in the test3
输出(def_test1.txt):
2017-07-21 15:55:29 : end action
2017-07-21 15:55:29 : end action
2017-07-21 15:55:29 : end action
实例2: 函数返回值的几种形式
>无return语句时返回None
>有return且值为唯一的时候,返回该唯一值
>有return且值为多个的时候,返回一个元组,元组里的元素为return返回的多个值。
def def_return1():
print('hello python1')
def def_return2():
print('hello python2')
return 0
def def_return3():
print('hello python3')
return 'world',123,['a','b','c'],{'name':'akira'}
d1 = def_return1()
d2 = def_return2()
d3 = def_return3()
print('d1:',d1)
print('d2:',d2)
print('d3:',d3)
输出:
hello python1
hello python2
hello python3
d1: None
d2: 0
d3: ('world', 123, ['a', 'b', 'c'], {'name': 'akira'})
1.19 类和对象
Python中具有相同属性或能力的模型在面向对象编程中以类进行定义和表示的,由类可以派生出(实例化)出同类的各个实例就是对象。
定义类:
# 使用class关键字进行定义,其中父类为可选项,如果不继承任何父类则括号都不需要写。
class <类名> (父类)
pass
# 定义一个不含父类的类
class MyClass:
pass
# 如果一个类表面上没有继承任何类但实际上它是继承了内建的object类,使用dir()函数来查看MyClass从object类那里继承来的属性和方法
print(dir(MyClass))
输出:
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
实例化:
类在定义后必须先实例化后才可以使用,类的实例化跟函数调用类似,只要使用类名加圆括号的形式就可以实例化一个类。类实例化以后会生成该类的一个实例,一个类可以实例化多个实例,实例和实例之间并不会相互影响,类实例化以后就可以直接使用了。
class MyClass: # 定义一个类
"MyClass help."
myclass = MyClass() # 实例化一个类
print('输出类说明:')
print(myclass.__doc__) # 输出类实例myclass的属性__doc__的值(类说明)
print('\n显示类帮助信息:')
print(help(myclass))
输出:
输出类说明:
MyClass help.
显示类帮助信息:
Help on MyClass in module __main__ object:
class MyClass(builtins.object) # 继承了object类
| MyClass help.
|
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
类的方法
类中的方法的定义和调用与函数定义和调用基本相同,其区别有:
>方法的第一个参数必须是self,而且不能省略。但是在通过实例调用方法的时候可以不用提供self参数。
>方法的调用需要实例来调用,并且以实例名.方法名(参数列表)形式调用
>整体进行一个单位的缩进,表示其属于类体中的内容
class MyClass:
def info(self):
print('>>>info method!')
def mycacl(self,x,y):
return x + y
mc = MyClass()
print('调用info方法:')
mc.info()
print('调用mycacl方法:')
result = mc.mycacl(3,4)
print(result)
输出:
调用info方法:
>>>info method!
调用mycacl方法:
7
构造方法
python的构造方法用__init__()方法来表示,用于类实例化时初始化相关数据,如果在这个方法中有相关参数,则实例化时就必须提供。
class UserInfo:
def __init__(self,name,age=18): #此方法为构造方法,参数中的age被设置成了默认参数
self.name = name
self.age = age
def user(self):
return 'name:{_name}\tage:{_age}'.format(_name=self.name,_age=self.age)
# 实例化的时候必须给name传参,age可传可不传,不传的时候使用默认age=18。
# 另外,调用方法的时候必须使用实例来调用。
dia = UserInfo('akira',22)
print('调用user-akira方法的结果:')
print(dia.user())
dib = UserInfo('susan')
print('调用user-susan方法的结果:')
print(dib.user())
输出:
调用user-akira方法的结果:
name:akira age:22
调用user-susan方法的结果:
name:susan age:18
构造函数中存在指定的参数时,实例化对象时必须给定相应的参数
class person :
def __init__(self,name): # 构造函数
self.name = name
def showName(self):
print(self.name)
p1 = person() # 因为构造函数要求name参数,而p1实例化时未给出所以报错
print(p1)
输出:
Traceback (most recent call last):
File "/Users/PycharmProjects/python_basic/python教程/类和对象/alex/xigou函数.py", line 14, in <module>
p1 = person()
TypeError: __init__() missing 1 required positional argument: 'name'
p2 = person('jack') # 实例化时给出了构造函数要求的name参数,所以不会报错
print(p2.showName())
输出:
jack
类中方法内部调用全局函数
类中的方法内部既可以调用本类中的其他方法,也可以调用全局函数来完成相关工作。调用全局函数和面向过程中的调用方式完全相同,而调用本类中的方法应使用self.方法名(参数列表)的形式完成。另外,调用本类中的方法时提供的参数列表中也仍不需包含self。
def coord_chng(x,y): # coord_chng(x,y)是全局函数
return (abs(x),abs(y))
class Ant:
def __init__(self,x=0,y=0): # __init__()为构造方法
self.x = x
self.y = y
self.disp_point() # 调用类中的其他方法,显示坐标位置
def move(self,x,y):
x,y = coord_chng(x,y) # 调用全局函数,注意看此时并没有实例进行调用,而是直接使用函数
self.edit_point(x,y) # 调用类中的其他方法
self.disp_point()
def edit_point(self,x,y):
self.x += x
self.y += y
def disp_point(self):
print("当前位置:(%s,%d)" % (self.x,self.y))
# 创建实例ant_a,调用构造方法,因构造方法中x、y均是默认参数,所以不传参也可以。
ant_a = Ant()
# 实例调用move方法,将2,4赋值给x,y。在move方法内再次调用全局函数coord_chng(x,y)进行取绝对值。
ant_a.move(2,4)
# 实例调用move方法,将-9,6赋值给x,y(经过上一步此时x,y为2,4),然后在调用coord_chng方法进行取绝对值,然后调用edit_point()方法对x,y均进行加等于操作,在调用dis_point()方法进行显示坐标。
ant_a.move(-9,6)
输出:
当前位置:(0,0)
当前位置:(2,4)
当前位置:(11,10)
类的属性
类的属性可以看作是数据,而类的方法就是用来操作类的属性(数据)的。在Python语言中类的属性分为实例属性与类属性两种,实例属性即同一个类中的不同实例,其值是不相关联的,定义时使用"self.属性名",调用时也适用它。类属性则是同一个类的所有实例都共有的,直接在类体中独立定义,引用时要使用"类名.类属性"形式来调用,只要时某个实例对其修改过,就会影响其他所有实例调用这个类属性的结果。
class Demo_Property:
class_name = "Demo_Property" # 创建类属性class_name
def __init__(self,x = 0): # 构造方法,用于给实例属性赋值
self.x = x
def class_info(self): # 类方法,用于显示类属性与实例属性
print('类属性值:',Demo_Property.class_name)
print('实例变量值:',self.x)
def chng(self,x): # 修改实例属性的方法
self.x = x
def chng_cn(self,name): # 修改类属性的方法
Demo_Property.class_name = name
dpa = Demo_Property() # 实例化对象dpa
dpb = Demo_Property() # 实例化对象dpb
print('初始化两个实例:')
dpa.class_info()
dpb.class_info()
输出:
初始化两个实例:
类属性值: Demo_Property
实例变量值: 0
类属性值: Demo_Property
实例变量值: 0
print('\n修改dpa实例变量:')
dpa.chng(3) # 修改实例dpa的属性
dpa.class_info()
dpb.class_info()
输出:
修改dpa实例变量:
类属性值: Demo_Property
实例变量值: 3
类属性值: Demo_Property
实例变量值: 0
print('\n修改dpb实例变量:')
dpb.chng(4)
dpa.class_info()
dpb.class_info()
输出:
修改dpb实例变量:
类属性值: Demo_Property
实例变量值: 3
类属性值: Demo_Property
实例变量值: 4
print('\n使用实例dpa对类的属性class_name进行修改')
dpa.chng_cn('dpa')
dpa.class_info()
dpb.class_info()
输出:
使用实例dpa对类的属性class_name进行修改
类属性值: dpa
实例变量值: 3
类属性值: dpa
实例变量值: 4
print('\n使用实例dpb对类的属性class_name进行修改')
dpb.chng_cn('dpb')
dpa.class_info()
dpb.class_info()
输出:
使用实例dpb对类的属性class_name进行修改
类属性值: dpb
实例变量值: 3
类属性值: dpb
实例变量值: 4
类的成员方法和静态方法
类的属性有类属性和实例属性之分,类的方法也有不同的种类,主要有:
>实例方法:前文案例中类中的方法均为实例方法,调用时需要实例化。
>类方法:定义时使用装饰器@classmethod进行装饰,必须有默认参数cls。调用时可直接由类名进行调用,调用前不需要实例化,当然也可以使用任何一个实例来进行调用。
>静态方法:定义时应使用@staticmethod进行修饰,没有默认参数。调用时可直接由类名进行调用,调用前不需要实例化,当然也可以使用任何一个实例来进行调用。
注意事项:在静态方法和类方法中不能使用实例属性,因为可能调用时类还没有实例化。
class DemoMthd:
@staticmethod # 静态方法装饰器
def static_mthd():
print('调用了静态方法!')
@classmethod # 类方法装饰器
def class_mthd(cls):
print('调用了类方法!')
print('\n通过类名来调用静态方法和类方法:')
DemoMthd.static_mthd() # 通过类名调用静态方法
DemoMthd.class_mthd() # 通过类名调用类方法
输出:
通过类名来调用静态方法和类方法:
调用了静态方法!
调用了类方法!
print('\n通过实例来调用静态方法和类方法:')
dm = DemoMthd() #实例化dm
dm.static_mthd() #通过实例调用静态方法
dm.class_mthd() #通过实例调用类方法
输出:
通过实例来调用静态方法和类方法:
调用了静态方法!
调用了类方法!
类的私有属性和私有方法
通常在Python中可以使用双下划线开头的方法或属性来达到私有函数或私有属性的目标,但事实上,这个所谓的"私有"更多的是一个强拼硬凑的惯用法。只是一种程序员约定俗称的规定,加了就表示私有变量,但是你如果要在外部调用的话,还是可以调用的。
调用方法:
私有变量:实例._类名__变量名
私有方法:实例._类名__方法名()
class person():
def __init__(self,name,salary):
self.name = name
self.__salary = salary #定义私有属性
def __showSalary(self): #定义私有方法
print('薪水:',self.__salary)
def showInfo(self): # 用于显示私有属性的方法,可被外部调用
print("name:%s salary:%s" % (self.name,self.__salary))
p = person('jack',10000)
p.showInfo() # 通过方法用于显示私有属性
输出:
name:jack salary:10000
print('name:',p.name)
输出:
name: jack
p.__showSalary() # 调用私有方法
输出:
Traceback (most recent call last):
File "/Users/PycharmProjects/python_basic/python教程/类和对象/alex/私有属性和方法.py", line 28, in <module>
p.__showSalary() # 调用私有方法
AttributeError: 'person' object has no attribute '__showSalary'
print('salary:',p.salary) # 调用私有属性,尝试不带两个下划线
输出:
File "/Users/PycharmProjects/python_basic/python教程/类和对象/alex/私有属性和方法.py", line 19, in <module>
name: jack
print('salary:',p.salary)
AttributeError: 'person' object has no attribute 'salary'
print('salary:',p.__salary) # 调用私有属性,尝试带两个下划线
输出:
Traceback (most recent call last):
File "/Users/PycharmProjects/python_basic/python教程/类和对象/alex/私有属性和方法.py", line 28, in <module>
print('salary:',p.__salary)
AttributeError: 'person' object has no attribute '__salary'
# 接下来,查看正确的调用私有属性和私有方法的方式:
print('调用私有属性:',p._person__salary) # 实例._类名__属性名
输出:
调用私有属性: 10000
print('调用私有方法:')
p._person__showSalary() # 实例._类名__方法名
输出:
调用私有方法:
薪水: 10000
类的继承
子类继承父类之后,就具有了父类的的属性和方法,但不能继承父类的私有属性和私有方法(属性名或方法名前缀为两个下划线的),子类中还可以重载来修改父类的方法,以实现与父类不同的行为表现或能力。
class Ant: # 定义父类
def __init__(self,x=0,y=0,color='black'): # 定义构造方法
self.x = x
self.y = y
self.color = color
def crawl(self,x,y): # 定义方法,爬行功能
self.x = x
self.y = y
print('爬行...')
self.info() # 打印位置信息
def info(self): # 打印位置方法
print('当前位置:(%d,%d)' % (self.x,self.y))
def attack(self): # 定义方法,攻击功能
print("用嘴咬!")
class FlyAnt(Ant): # 定义子类FlyAnt类,继承Ant类,此时FlyAny类拥有Ant的所有非私有方法和属性了。
def attack(self): # 重新修改父类Ant类的attack()方法:重载。
print("用尾针!")
def fly(self,x,y): # 定义特有方法fly(),属于新添加的方法
print('飞行...')
self.x = x
self.y = y
self.info()
flyant = FlyAnt(color='red')
flyant.crawl(3,5)
flyant.fly(10,14)
flyant.attack() # 因为attack()被重新修改了,所以方法由"用嘴咬"改为了"用尾针"。
输出:
爬行...
当前位置:(3,5)
飞行...
当前位置:(10,14)
用尾针!
多重继承
Python语言允许多重继承,即一个类可以继承多个类。多重继承的方式在类定义时的继承父类的括号中,以","分隔开要多重继承的父类即可。多重继承的时候,继承的顺序也是一个很重要的元素,如果继承的多个元素中有相同的方法名,但在类中使用时未指定父类名,则pyhon解释器将从左到右搜索,即调用先继承的类中的同名方法。
class PrntA:
namea = 'PrntA'
def set_value(self,a):
self.a = a
def set_namea(self,namea):
PrntA.namea = namea
def info(self): # 与PrntB有相同的info()方法
print('PrintA:%s,%s' % (PrntA.namea,self.a))
class PrntB:
nameb = 'PrntB'
def set_nameb(self,nameb):
PrntB.nameb = nameb
def info(self): # 与PrntA有相同的info()方法
print('PrntB:%s' % (PrntB.nameb))
class Sub(PrntA,PrntB): # 因PrntA与PrntB有相同的info方法,同时参数列表里PrntA排在PrntB的前边,如果要调用则优先调用PrntA的info方法。
pass
class Sub2(PrntB,PrntA):
pass
print('使用第一个子类:')
sub = Sub()
sub.set_value('aaaa')
sub.info() # 此处调用PrntA的info方法,打印PrintA:PrntA,aaaa
sub.set_nameb('BBBB')
sub.info() # 此处仍然调用PrntA的info方法,仍然打印PrintA:PrntA,aaaa
输出:
使用第一个子类:
PrintA:PrntA,aaaa
PrintA:PrntA,aaaa
print('使用第二个子类:')
sub2 = Sub2()
sub2.set_value('aaaa')
sub2.info() # 此处调用PrntB的info方法,因为上一步的"sub.set_nameb('BBBB')"已将nameb更改为了BBBB,所以打印打印PrntB:BBBB
sub2.set_nameb('BBBB')
sub2.info() # 此处仍然调用PrntB的info方法,因为上一步的sub2.set_nameb('BBBB')已将nameb再次更改为了BBBB,所以打印PrntB:BBBB
输出:
使用第二个子类:
PrntB:BBBB
PrntB:BBBB
class People: # 父类1
def __init__(self,name,age):
self.name = name
self.age = age
def eat(self):
print("%s is eatting..." % self.name)
def run(self):
print("%s is running..." % self.name)
def look(self):
print("%s is looking... in the People Class" % self.name)
class Human: # 父类2
def __init__(self,name,age):
self.name = name
self.age = age
def look(self):
print("%s is looking... in the Human Class" % self.name)
# 虽然Man类内部无任何属性和方法,但因其继承了父类People,自动拥有父类的所有属性和方法。
# Man是多继承,继承顺序是People,Human,当People与Human含有相同的方法look的时候,优先继承前边的类People中的look方法。
class Man(People,Human): # 子类1
pass
# 虽然Woman类内部无任何属性和方法,但因其继承了父类People,自动拥有父类的所有属性和方法。
# Woman是多继承,继承顺序是Human,People,当People与Human含有相同的方法look的时候,优先继承前边的类Human中的look方法。
class Woman(Human,People): # 子类2
pass
m1 = Man('jack',20)
m1.eat()
m1.run()
m1.look() # 因为Man类中的继承顺序是People,Human,所以优先继承People中的look()方法
print()
w1 = Woman('rose',19)
w1.eat()
w1.run()
w1.look() # 因为Woman类中的继承顺序是Human,People,所以优先继承Human中的look()方法
输出:
jack is eatting...
jack is running...
jack is looking... in the People Class
rose is eatting...
rose is running...
rose is looking... in the Human Class
m1 = Man() # 虽然实例化子类,但实例化时括号内的参数仍然要与父类的构造方法相匹配,否则报错
输出:
Traceback (most recent call last):
File "/Users/PycharmProjects/python_basic/python教程/类和对象/alex/jicheng.py", line 24, in <module>
m1 = Man()
TypeError: __init__() missing 2 required positional arguments: 'name' and 'age'
广度继承
class A class B(A) class C(A) class D(B,C)
继承关系如上所示,广度继承是即为最下层的classD继承后函数的执行优先顺序是B->C-A,如下图所示:
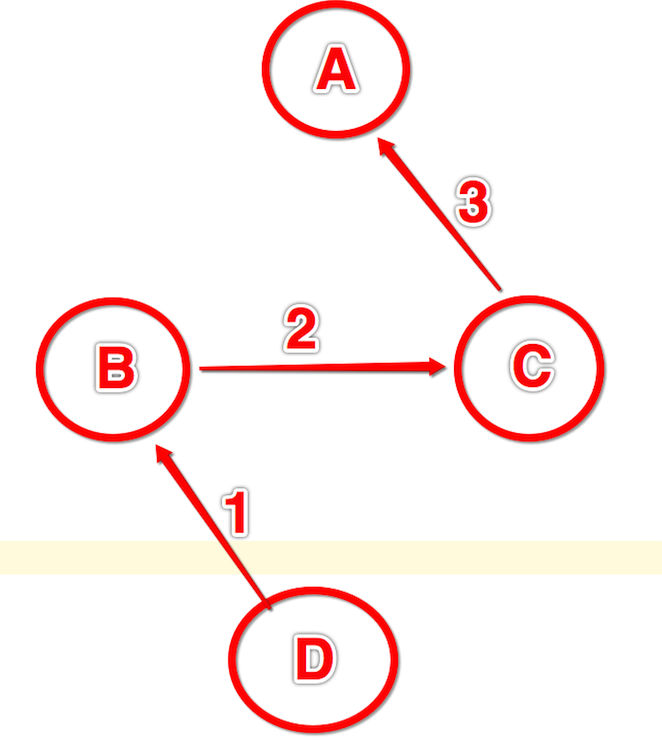
从以下四个场景来看广度继承的关系:
场景1: class D有自己的方法,执行自己的方法
class A :
def show(self):
print('form A...')
class B (A):
def show(self):
print('from B...')
class C (A):
def show(self):
print('from C...')
class D (B,C):
def show(self):
print('from D...')
d = D()
d.show()
输出:
from D...
场景2: class D没有自己的方法,执行class B的方法
class A :
def show(self):
print('form A...')
class B (A):
def show(self):
print('from B...')
class C (A):
def show(self):
print('from C...')
class D (B,C):
pass
d = D()
d.show()
输出:
from B...
场景3:class D没有自己的方法,class B也没有自己的方法,执行class C的方法
class A :
def show(self):
print('form A...')
class B (A):
pass
class C (A):
def show(self):
print('from C...')
class D (B,C):
pass
d = D()
d.show()
输出:
from C...
场景4:class D没有自己的方法,class B也没有自己的方法,class C也没有自己的方法,最后执行class A的方法
class A :
def show(self):
print('form A...')
class B (A):
pass
class C (A):
pass
class D (B,C):
pass
d = D()
d.show()
输出:
form A...
方法重载
子类继承了父类的属性和方法,但子类想要对继承来的父类方法进行修改就是方法重载,以实现与父类不同的表现行为与能力。
class Person: # 定义父类
def __init__(self,name,age):
self.name = name
self.age = age
def walks(self): # 父类的walks方法只实现了"走"的功能
print("%s is walking..." % self.name)
class OldMan(Person): # 继承父类Person,并没做任何修改
pass
class Children(Person):
def walks(self): # 子类Children继承了Person,并对walks方法进行修改添加了sing功能,叫做方法重载。
print("%s is walks and sings at the same time" % self.name)
om = OldMan('natasha',88)
om.walks() # 调用父类的walks方法
cd = Children('akira',17)
cd.walks() # 调用重载后的方法
输出:
natasha is walking...
akira is walks and sings at the same time
__doc__查看类的描述信息
__doc__ ,用于表达类的表述信息,使用类名.__doc__进行调用。
class Person:
'''
这个类是用来创建人的,创建时需要提供一个name参数。
'''
def __init__(self,name):
self.name = name
def showName(self,name):
print('name:',self.name)
print(Person.__doc__)
输出:
这个类是用来创建人的,创建时需要提供一个name参数。
__module__ & __class__确认类的出自及类名信息
__module__: 输出模块所在处
__class__: 输出类信息
目录结构:
-- 类和对象
---- lib(Package)
------ car.py
------ __init__.py
---- myTest.py
------------------------------
car.py
class Mycar:
def __init__(self,car_name):
self.name = car_name
------------------------------
myTest.py
from lib.car import Mycar
mc = Mycar('benz')
# 返回Mycar是从哪个模块导入的(确认类从哪里导入的)
print(mc.__module__)
# 输出这个类本身
print(mc.__class__)
执行myTest.py输出:
lib.car
<class 'lib.car.Mycar'>
__call__:通过对象()调用函数
构造方法的执行是由创建对象触发的,即:对象 = 类名();而对于__call__方法的执行则是由对象后加括号触发的,即对象()或类()()
对象通过提供__call__(slef, [,*args [,**kwargs]])方法可以模拟函数的行为,如果一个对象x提供了该方法,就可以像函数一样使用它,也就是说x(arg1, arg2...) 等同于调用x.__call__(self, arg1, arg2)。
class Person:
def __init__(self,name,age):
self.name = name
self.age = age
def info(self):
print('%s\'s age is %s' %(self.name,self.age))
def __call__(self, frend): # 定义__call__函数,要求输入一个frend参数
print('%s\'s friend is %s!' % (self.name,frend))
harry = Person('harry',20)
harry.info()
# 对象名调用__call__方法
harry('akira')
Person('natasha',22)('hanmeimei')
输出:
harry's age is 20
harry's friend is akira!
natasha's friend is hanmeimei!
__dict__:查看类或成员当中的所有成员,以字典的形式输出
class Person:
# 定义类属性
id = 101
address = 'china'
def __init__(self,name,age):
self.name = name
self.age = age
def info(self):
print('%s\'s age is %s' %(self.name,self.age))
def __call__(self, frend): # 定义__call__函数,要求输入一个frend参数
print('%s\'s friend is %s!' % (self.name,frend))
harry = Person('harry',20)
print(Person.__dict__) # 用类调用__init__,查看类中的所有成员,输出类属性,但是不会输出实例的属性
print()
print(harry.__dict__) # 用实例调用__init__,查看实例中的所有成员
输出:
{'__module__': '__main__', 'id': 101, 'address': 'china', '__init__': <function Person.__init__ at 0x10227a7b8>, 'info': <function Person.info at 0x10227a840>, '__call__': <function Person.__call__ at 0x10227a8c8>, '__dict__': <attribute '__dict__' of 'Person' objects>, '__weakref__': <attribute '__weakref__' of 'Person' objects>, '__doc__': None}
{'name': 'harry', 'age': 20}
__str__ : 如果一个类中定义了__str__方法,打印对象时默认输出__str__()方法的返回值
class PersonA():
def __init__(self,name):
self.name = name
class PersonB():
def __init__(self,name):
self.name = name
def __str__(self):
return 'Person : %s' % self.name
pa = PersonA('韩梅梅') # 类内部未使用__str__方法
print(pa)
pb = PersonB('李雪') # 类内部已使用__str__方法,调用时直接输出__str__的return值。
print(pb)
输出:
<__main__.PersonA object at 0x101a41cc0>
Person : 李雪
1.20 字符编码转换
当国内采用UTF-8字符编码写出的软件要在日本使用的时候,由于两国间的字符编码不同就会出现乱码的现象,Python中通过字符编码转换可解决这个问题。打个比方,众所周知的unicode(也叫万国编码),如果要想将原本使用GBK编码写出的软件转换成UTF-8编码的时候,就可以借助unicode作为中间人来进行转换。转换的大致思路如下图所示:
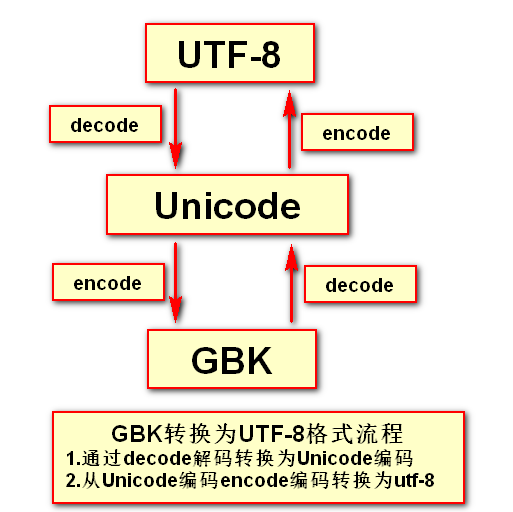
1.21 错误与异常
Python常见的基本错误有两类,一类是语法错误,另一个类是程序异常。语法错误:通常使用Pycharm等第三方IDE的时候如果出现语法错误在编程的时候会给出提醒,尽量在程序调试过程中就消除此类语法错误。程序异常:异常不是在编写代码时出现的错误,而是在程序运行时出现的错误,而如果对运行中的程序没有进行异常处理那么程序就会终止运行。
语法错误:
以下range()右侧的括号为全角括号,不符合代码规范因此报了语法错误。
for i in range(10):
print(i)
输出:
/excepDemo.py", line 15
for i in range(10):
^
SyntaxError: invalid character in identifier
异常错误:
python程序在程序运行中引发的错误称为异常,对异常的处理python与其他语言一样,也是通过try语句来完成,其语法规范如下所示:
try:
<语句(块)> # 可能产生异常的语句(块)
except <异常名1>: # 要处理的异常
<语句(块)> # 异常处理语句
except <异常名2>: # 要处理的异常
<语句(块)>: # 异常处理语句
else:
<语句(块)> # 未触发异常,则执行该语句(块)
finally:
<语句(块)> # 始终执行该语句,一般未来到达释放资源的目的
def testTry(index,flay=False):
userlst = ['jack','akira','harry']
if flay:
try:
astu = userlst[index]
except IndexError:
print('IndexError')
return 'Try Test Finished!'
else:
astu = userlst[index]
return "No try test !"
print('不越界,捕获异常:')
print(testTry(1,True))
输出:
不越界,捕获异常:
Try Test Finished!
print('\n不越界,不捕获异常:')
print(testTry(1,False))
输出:
不越界,不捕获异常:
No try test !
print('\n越界,捕获异常:')
print(testTry(4,True))
输出:
越界,捕获异常:
IndexError
Try Test Finished!
print('\n越界,未捕获异常:')
print(testTry(4,False))
输出:
越界,未捕获异常:
File "/Users/pentest/PycharmProjects/python_basic/python教程/错误、调试和测试/excepDemo.py", line 46, in testTry
No try test !
astu = userlst[index]
IndexError: list index out of range
finally语句执行
无论异常是否会发生,终究会执行finally里面的代码。以下演示运用finally语句来确保文件使用后能关闭该文件。
def testTryFinally(index):
stulist = ['John','Jenny','Tom']
af = open('my.txt','wt+')
try:
af.write(stulist[index])
except :
print('捕获异常:IndexError')
return 0
finally:
af.close()
print('文件已被关闭,finally已被执行!')
testTryFinally(1) # 无越界异常,执行finally关闭文件
输出:
文件已被关闭,finally已被执行!
print(testTryFinally(4)) # 有越界异常,捕获异常并执行finally关闭文件
输出:
捕获异常:IndexError
文件已被关闭,finally已被执行!
except语句用法
>except: # 捕获所有异常,不论是什么类型的错误统一抛出
>except <异常名>: # 捕获指定异常
>except (异常名1,异常名2): # 指定捕获异常1或异常2
# 以捕获所有异常为例
def testTryAll(index,i):
stulist = ['john','jenney','tom']
try:
print(len(stulist[index])/i)
except: # 捕获所有异常
print('Error!')
testTryAll(1,2) # 下标未越界,无异常产生
输出:
3.0
testTryAll(1,0) # 下标未越界,除数为0异常
输出:
Error!
testTryAll(4,0) # 下标已越界异常,除数为0异常
输出:
Error!
Raise手工抛出异常
程序员可以自定义异常类型,如对用户输入文本的长度有要求,则可以使用raise引发异常。使用raise引发异常十分简单,raise有以下几种使用方式:
>raise 异常名
>raise 异常名,附加数据
>raise 类名
# 以下代码演示了虽然程序中对代码进行了异常抛出,但是因为后续没有对该异常进行捕获,所以程序运行会被中断,导致后面的代码无法执行
def testRaise():
for i in range(5):
if i == 2:
raise NameError
print(i)
print('end...')
testRaise()
输出:
Traceback (most recent call last):
0
File "/Users/pentest/PycharmProjects/python_basic/python教程/错误、调试和测试/excepDemo.py", line 123, in <module>
1
testRaise()
File "/Users/pentest/PycharmProjects/python_basic/python教程/错误、调试和测试/excepDemo.py", line 119, in testRaise
raise NameError
NameError
# 综上所述,在对代码抛异常对同时进行捕获,那么程序运行则不会中断。
def testRaise():
for i in range(5):
try:
if i == 2:
raise NameError
except NameError:
print('Raise a NameError!')
print(i)
print('end...')
testRaise()
输出:
0
1
Raise a NameError!
2
3
4
end...
1.22 装饰器
定义:
本质是函数,用于装饰其他函数,说白了就是为其他函数添加附加功能。
原则:
1>不能修改被装饰的函数的源代码
2>不能修改被装饰的函数的调用方式
实例1: 统计程序运行时间的装饰器
import time
def timemer(func):
def warpper(*args,**kwargs):
start_time = time.time()
func(*args,**kwargs)
stop_time = time.time()
print('the func run time is %s' % (stop_time-start_time))
return warpper
@timemer
def test1():
time.sleep(3)
print('in the test1')
test1()
实例2: 在普通函数执行前添加开始与结束语句
def abc(fun): # 定义一个装饰器abc
def wrapper(*args,**kwargs): # 定义包装器函数
print('装饰器开始运行...')
fun(*args,**kwargs) # 调用被装饰函数
print('装饰器结束结束...')
return wrapper # 返回包装器函数
@abc #装饰函数语句
def demo_decoration(x): # 定义普通函数,被装饰器装饰
a = []
for i in range(x):
a.append(i)
print(a)
@abc # 装饰器语句
def hello(name): # 定义普通函数,被装饰器装饰
print('hello',name)
if __name__ == '__main__':
demo_decoration(5) # 调用被装饰器装饰的函数
print()
hello('John') # 调用被装饰器装饰的函数
输出:
装饰器开始运行...
[0, 1, 2, 3, 4]
运行结束...
装饰器开始运行...
hello John
运行结束...
输出(不加@abc装饰器的情况下):
[0, 1, 2, 3, 4]
hello John
1.23 高阶函数
高阶函数,满足以下两个条件中任意一个即可称之为高阶函数
a> 把一个函数名当作实参传给另外一个函数(在不修改被装饰函数源代码的情况下为其添加功能)
b> 返回值中包含函数名(不修改函数的调用方式)
a>证明:
import time
def bar():
time.sleep(3)
print('in the bar')
def test1(func):
start_time = time.time()
func()
stop_time = time.time()
print('the func run time is %s' % (stop_time - start_time))
test1(bar) # 传递参数时传递的是函数(bar是一个函数的内存地址)
输出:
in the bar
the func run time is 3.0024850368499756
b>证明:
import time
def bar(): # 被装饰的源代码
time.sleep(3)
print('in the bar')
def test2(func): # 装饰器
print(func)
print('我是装饰器!')
return func
bar = test2(bar) # 先把bar函数当作参数传递给装饰器test2(),输出结果为bar的内存地址,然后将内存地址重新赋值给bar
bar() # 此时的bar覆盖原始的bar,而bar()是集装饰器为一体的bar函数了,也就是说直接执行bar()就可以完成带装饰器的效果了。
输出:
<function bar at 0x100762e18>
我是装饰器!
in the bar
1.24 生成器
假如一个列表里有1000万个元素,如果我们只想读取列表里的前5个数据,那么程序依然会把包含1000万个元素的列表一下子都读到内存里,如此一来极大的浪费里内存空间,也浪费了硬盘空间。Python中的生成器机制可以生成一个[值的序列]用于迭代,并且这个值的序列不是一次生成的,而是使用一个再生成一个,可以使程序节约大量内存。生成器对象是通过使用yield关键字定义的函数对象,因此生成器也是一个函数。此外生成对象可以直接被for循环遍历,也可以手工进行遍历。
实例1:自定义一个递减数字序列的生成器,使用for循环遍历
def myYield(n): # 定义一个生成器
while n > 0:
print('开始生成...')
yield n # yield语句,用于返回给调用者表达式的值
print('完成一次...\n')
n -= 1
if __name__ == '__main__':
for i in myYield(4):
print('遍历得到的值:',i)
print()
输出:
开始生成...
遍历得到的值: 4
完成一次...
开始生成...
遍历得到的值: 3
完成一次...
开始生成...
遍历得到的值: 2
完成一次...
开始生成...
遍历得到的值: 1
完成一次...
实例2: 自定义一个递减数字序列的生成器,使用手工遍历,__next__()
def myYield(n): # 定义一个生成器
while n > 0:
print('开始生成...')
yield n # yield语句,用于返回给调用者表达式的值
print('完成一次...\n')
n -= 1
my_yield = myYield(3)
print('第一次调用__next__()方法:')
print(my_yield.__next__())
print()
print('第二次调用__next__()方法:') # 注意,第二次调用程序开始的位置为第一次结束位置的下一跳为起始位置。所以,第二次调用会先打印第一次调用尚未执行的"完成一次..."
print(my_yield.__next__())
输出:
第一次调用__next__()方法:
开始生成...
3
第二次调用__next__()方法:
完成一次...
开始生成...
2
实例3: ( i * i for i in range(10)) 使用括号扩起来然后赋值给scq,则scq就是一个生成器了,此时可以使用for循环进行遍历,也可以使用手工的方法进行输出。以下代码显示手工输出到一部分后继续使用for循环遍历输出。
scq = ( i * i for i in range(10))
print(scq,type(scq))
print()
print(scq.__next__()) # 手工输出生成器
print(scq.__next__()) # 手工输出生成器
print(scq.__next__()) # 手工输出生成器
print(scq.__next__()) # 手工输出生成器
print('for循环开始...') # 继续使用for循环输出生成器对象
for i in scq :
print(i)
输出:
<generator object <genexpr> at 0x102a14410> <class 'generator'>
0
1
4
9
for循环开始...
16
25
36
49
64
81
实例4: 生成器函数,以斐波那契数列为例,当使用print()打印时则为普通函数,当使用yield打印时则为生成器函数。
def fib1(max):
n,a,b = 0,0,1
while n < max:
print(b) # 使用print()打印b,是普通函数
a,b = b,a+b
n = n +1
return 'done'
def fib2(max):
n,a,b = 0,0,1
while n < max:
yield b # 使用yield()打印b,是生成器函数
a,b = b,a+b
n = n +1
return 'done'
print('fib1类型:',type(fib1(10)))
print('fib2类型:',type(fib2(10)))
f2 = fib2(10)
print(f2.__next__()) # f2是生成器,可以使用f2.__next__()进行打印
print(f2.__next__())
print(f2.__next__())
print(f2.__next__())
print(f2.__next__())
输出:
1
1
2
3
5
8
13
21
34
55
fib1类型: <class 'str'>
fib2类型: <class 'generator'>
1
1
2
3
5
1.25 迭代器
实例1:判断是否是可迭代对象与是否是迭代器
可迭代对象:
可直接作用于for循环的对象有以下两种,这些可直接用于for循环的对象统称为可迭代对象(Iterable对象)。
> list,tuple,dict,set,str等
> generator,包括生成器和含有yield的generator
迭代器:
可以被next()函数调用并不断返回下一个值的对象成为迭代器:Interator
# 如何判断一个对象是否是可迭代对象,可以使用isinstance()判断
from collections import Iterable # 从collections里面倒入Iterable(可迭代对象)
from collections import Iterator # 从collections里面倒入Iterator(迭代器)
print('列表是否是可迭代对象:',isinstance([],Iterable))
print('列表是否是迭代器:',isinstance([],Iterator))
print()
print('字符串是否是可迭代对象:',isinstance('abc',Iterable))
print('字符串是否是迭代器:',isinstance('abc',Iterator))
print()
print('数字是否是可迭代对象:',isinstance(123,Iterable))
print('数字是否是迭代器:',isinstance(123,Iterator))
print()
print('元组是否是可迭代对象:',isinstance(('1','2',3,'4',[]),Iterable))
print('元组是否是迭代器:',isinstance(('1','2',3,'4',[]),Iterator))
print()
print('字典是否是可迭代对象:',isinstance({'abc':123,'def':456},Iterable))
print('字典是否是迭代器:',isinstance({'abc':123,'def':456},Iterator))
print()
print('生成器是否是可迭代对象:',isinstance((x * x for x in range(5)),Iterable))
print('生成器是否是迭代器:',isinstance((x * x for x in range(5)),Iterator))
输出:
列表是否是可迭代对象: True
列表是否是迭代器: False
字符串是否是可迭代对象: True
字符串是否是迭代器: False
数字是否是可迭代对象: False
数字是否是迭代器: False
元组是否是可迭代对象: True
元组是否是迭代器: False
字典是否是可迭代对象: True
字典是否是迭代器: False
生成器是否是可迭代对象: True
生成器是否是迭代器: True
实例2: 将可迭代对象转换为迭代器
通过以上实例可以看出,是可迭代对象但未必是迭代器,那么如何将有些是可迭代对象但不是迭代器的对象转换为迭代器呢,通过iter()方法即可
l1 = [1,2,3,4,5]
print('转换前,是否是可迭代对象:',isinstance(l1,Iterable))
print('转换前,是否是迭代器:',isinstance(l1,Iterator))
print()
l2 = iter(l1)
print('转换后,是否是可迭代对象:',isinstance(l2,Iterable))
print('转换后,是否是迭代器:',isinstance(l2,Iterator))
输出:
转换前,是否是可迭代对象: True
转换前,是否是迭代器: False
转换后,是否是可迭代对象: True
转换后,是否是迭代器: True
1.26 序列化
序列化是将Python中的列表、元组、字典等基本数据类型转换为字符串的过程;而反序列化是指将字符串转换为python的列表、元组、字典等对象的过程,在Python中与序列化相关的两个模块:json和pickle。
实例1: 序列化,使用json.dumps()将字典数据类型进行序列化操作,(字典 -> 字符串)
dic = {'k1':'v1'} # 字典类型
print(dic,type(dic))
result = json.dumps(dic) # 序列化操作,由字典类型变成了字符串类型
print(result,type(result))
输出:
{'k1': 'v1'} <class 'dict'>
{"k1": "v1"} <class 'str'>
实例2: 反序列化,使用json.loads()将字符串类型转化为字典类型,(字符串->字典)
import json
# 将使用双引号进行装饰的字符串在进行反序列化时会报错。报错内容:json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
# s1 = "{'k1':'v1'}"
# 注意,在进行反序列化时诸如'{"k1":"v1"]'这种既不是列表又不是字典的数据类型无法进行反序列化,请保持数据类型的正确性后在进行反序列化。报错内容:json.decoder.JSONDecodeError: Expecting ',' delimiter: line 1 column 11 (char 10)
# 将使用单引号进行装饰的字符串在进行反序列化时不会报错。
s1 = '{"k1":"v1"}'
print(s1,type(s1))
dic = json.loads(s1) # 将字符串类型转换为字典类型
print(dic,type(dic))
输出:
{"k1":"v1"} <class 'str'>
{'k1': 'v1'} <class 'dict'>
实例3: 基于天气API获取JSON数据(http://wthrcdn.etouch.cn/weather_mini?city=上海)
import requests
import json
response = requests.get('http://wthrcdn.etouch.cn/weather_mini?city=上海')
response.encoding = 'utf-8'
print('获取到的天气API类型:',type(response.text)) # 查看获取到的天气API内容为字符串类型
print(response.text) # 通过response.text获取拿到的字符串内容
输出:
获取到的天气API类型: <class 'str'>
{"data":{"yesterday":{"date":"26日星期三","high":"高温 37℃","fx":"东风","low":"低温 29℃","fl":"微风","type":"阴"},"city":"上海","aqi":"99","forecast":[{"date":"27日星期四","high":"高温 37℃","fengli":"微风级","low":"低温 29℃","fengxiang":"东南风","type":"多云"},{"date":"28日星期五","high":"高温 37℃","fengli":"3-4级","low":"低温 29℃","fengxiang":"东南风","type":"阴"},{"date":"29日星期六","high":"高温 36℃","fengli":"3-4级","low":"低温 29℃","fengxiang":"东风","type":"小雨"},{"date":"30日星期天","high":"高温 35℃","fengli":"3-4级","low":"低温 28℃","fengxiang":"北风","type":"小雨"},{"date":"31日星期一","high":"高温 34℃","fengli":"微风级","low":"低温 28℃","fengxiang":"东北风","type":"中雨"}],"ganmao":"各项气象条件适宜,发生感冒机率较低。但请避免长期处于空调房间中,以防感冒。","wendu":"33"},"status":1000,"desc":"OK"}
# 以上通过request获取的是字符串类型,但是如果想更方便的被本地程序利用的化则需要再次将字符串类型反序列化成字典类型
dic = json.loads(response.text)
print('反序列化后得到的类型:',type(dic))
print(dic)
输出:
反序列化后得到的类型: <class 'dict'>
{'data': {'yesterday': {'date': '26日星期三', 'high': '高温 37℃', 'fx': '东风', 'low': '低温 29℃', 'fl': '微风', 'type': '阴'}, 'city': '上海', 'aqi': '99', 'forecast': [{'date': '27日星期四', 'high': '高温 37℃', 'fengli': '微风级', 'low': '低温 29℃', 'fengxiang': '东南风', 'type': '多云'}, {'date': '28日星期五', 'high': '高温 37℃', 'fengli': '3-4级', 'low': '低温 29℃', 'fengxiang': '东南风', 'type': '阴'}, {'date': '29日星期六', 'high': '高温 36℃', 'fengli': '3-4级', 'low': '低温 29℃', 'fengxiang': '东风', 'type': '小雨'}, {'date': '30日星期天', 'high': '高温 35℃', 'fengli': '3-4级', 'low': '低温 28℃', 'fengxiang': '北风', 'type': '小雨'}, {'date': '31日星期一', 'high': '高温 34℃', 'fengli': '微风级', 'low': '低温 28℃', 'fengxiang': '东北风', 'type': '中雨'}], 'ganmao': '各项气象条件适宜,发生感冒机率较低。但请避免长期处于空调房间中,以防感冒。', 'wendu': '33'}, 'status': 1000, 'desc': 'OK'}
实例4: 序列化,使用pickle.dumps()将列表数据类型进行序列化操作,(列表 -> 字符串)
import pickle li_1 = [11,22,33] result = pickle.dumps(li_1) print(result,type(result)) # 输出结果与json的输出结果不同,但python语言之间可以识别 输出: b'\x80\x03]q\x00(K\x0bK\x16K!e.' <class 'bytes'>
以上代码使用pickle.dumps()将python列表序列化成了字节类型,这种输出方式虽然人无法识但在python之间是可以识别。另外,如果想要反序列化成列表格式可以使用pickle.loads()方法:
li_2 = pickle.loads(result) print(li_2,type(li_2)) 输出: [11, 22, 33] <class 'list'>
实例5: json与pickle的序列化区别
数据类型区别: > json只能在简单数据类型(列表、字典、元组等)中进行序列化和反序列化 > pickle可以处理类的对象这种高级数据类型 跨语言区别: > json可以跨语言进行信息传递 > pickle只能在python语言之间进行信息传递
1.27 Python反射
Python反射包括四个方法:getattr、hasattr、setattr、delattr,分别用于获取成员、检查成员、设置成员、删除成员。
hasattr(obj,attr) : 这个方法用于检查obj是否有一个名为attr的值的属性,返回一个布尔值。 getattr(obj,attr) : 获取obj这个对象里的attr属性或方法,如果attr对应的是属性则直接返回属性,如果attr对应的是方法,则返回次方法的内存地址,需要加一个括号并且给齐所需参数才能调用对应的方法。 setattr(obj, attr, val): 调用这个方法将给obj的名为attr的值的属性赋值为val。例如如果attr为'bar',则相当于obj.bar = val。 delattr(obj,attr):调用这个方法将obj的名为attr的属性删除。
获取一个来自客户端的参数,进行反射案例演示
def talk(self):
print('%s is jiaoing...' % self.name)
class Dog(object):
def __init__(self,name):
self.name = name
def eat(self,food):
print('%s is eatting %s...' % (self.name,food))
d = Dog('Dahuang') # 先创建一个Dog类的对象。
choice = input('Please enter attribute or method and the program will check if it exists >>:').strip()
# [hasattr],判断d这个对象里面是否存在choice这个字符串的属性
if hasattr(d,choice):
try:
# [getattr]获取对象本来就有的方法, 存在函数(eat)走以下代码,返回值func为内存地址,需要加一个括号并且给齐所需参数才能调用对应的方法。
func = getattr(d,choice)
func('gouliang')
except TypeError:
# 获取对象本来就有的属性:如果终端输入的是"name"的时候走以下代码
print('name is %s' % getattr(d,choice))
else:
if choice == "talk":
# 如果用户输入的是"talk",则为对象创建talk方法
setattr(d,choice,talk)
d.talk(d)
print(d.__dict__)
else:
# 如果对象输入除了talk以外的字段,则为对象创建属性
setattr(d, choice, 22)
print(getattr(d, choice))
print('\n查看对象有那些属性:')
print(d.__dict__)
输出:
Please enter attribute or method and the program will check if it exists >>:name
name is Dahuang
Please enter attribute or method and the program will check if it exists >>:eat
Dahuang is eatting gouliang...
Please enter attribute or method and the program will check if it exists >>:talk
Dahuang is jiaoing...
{'name': 'Dahuang', 'talk': <function talk at 0x100562e18>}
Please enter attribute or method and the program will check if it exists >>:age
22
查看对象有那些属性:
{'name': 'Dahuang', 'age': 22}
class Person():
def __init__(self,name,age):
self.name = name
self.age = age
def run(self):
print('%s is running...' % self.name)
p1 = Person('akira',20)
print(hasattr(p1,'name'))
print(hasattr(p1,'height'))
输出:
True
False
p_name = getattr(p1,'name')
print(p_name)
输出:
akira
p_run = getattr(p1,'run')
print(p_run) # 打印的是方法的内存地址,调用具体值需要加括号
print(p_run())
输出:
<bound method Person.run of <__main__.Person object at 0x10225f2b0>>
akira is running...
print('setattr前:',getattr(p1,'age'))
setattr(p1,'age',30)
print('setattr后:',getattr(p1,'age'))
输出:
setattr前: 20
setattr后: 30
print(getattr(p1,'age'))
delattr(p1,'age')
print(getattr(p1,'age'))
输出:
报错AttributeError: 'Person' object has no attribute 'age'
1.28 Socket编程
网络概念:
TCP协议负责在两台计算机之间建立可靠连接,保证数据包按顺序到达。TCP协议会通过握手建立连接,然后,对每个IP包编号,确保对方按顺序收到,如果包丢掉了,就自动重发。 许多常用的更高级的协议都是建立在TCP协议基础上的,比如用于浏览器的HTTP协议、发送邮件的SMTP协议等。一个IP包除了包含要传输的数据外,还包含源IP地址和目标IP地址,源端口和目标端口。 端口的作用就是在两台计算机通信时,只发IP地址是不够的,因为同一台计算机上跑着多个网络程序。一个IP包来了之后,到底是交给浏览器还是QQ,就需要端口号来区分。每个网络程序都向操作系统申请唯一的端口号,这样,两个进程在两台计算机之间建立网络连接就需要各自的IP地址和各自的端口号。 一个进程也可能同时与多个计算机建立链接,因此它会申请很多端口。
socket编程
Socket是网络编程的一个抽象概念。通常我们用一个Socket表示“打开了一个网络链接”,而打开一个Socket需要知道目标计算机的IP地址和端口号,再指定协议类型即可。
客户端和服务端
大多数连接都是可靠的TCP连接。创建TCP连接时,主动发起连接的叫客户端,被动响应连接的叫服务器。
socket服务端建立连接流程图

Socket客户端建立连接流程

实例代码,本地搭建客户端与服务端模拟通信
服务端:
import socket
# ip地址为空表示本地地址
HOST = ''
# 设置端口
PORT = 10888
#初始化socket对象,AF_INET(IPV4),SOCK_STREAM(TCP协议)
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 绑定操作,使socket和服务器服务地址相关联
s.bind((HOST,PORT))
# 指定连接数,最小值为0 ,最多设置到5就可以了
s.listen(1)
#等待接入的链接,返回值是由一个socket连接和客户端的IP地址组成元组。
conn,addr = s.accept()
print('Client\'s address:',addr)
while True:
# recv 接收并返回远程连接发来的信息,1024为设定缓冲区大小。
data = conn.recv(1024)
if not data:
break
print('Receive Data:',data.decode('utf-8'))
conn.send(data) # 将接收到的数据再次发送出去
conn.close() # 关闭连接
客户端:
import socket
HOST = 'localhost'
PORT = 10888
# 初始化socket对象,使用IPv4,TCP协议
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 建立连接
s.connect((HOST,PORT))
data = '你好'
while data:
# 连接建立后向服务端发送data='你好'
s.sendall(data.encode('utf-8'))
# 接收socket服务器端发来的信息并保存于data中,data的缓存大小设置为512
data = s.recv(512)
# 将data进行解码后输出
print('Receive from server:',data.decode('utf-8'))
# 接收用户输入的内容然后在下一次循环中继续发送到服务端。
data = input('please input a info:\n')
# 关闭连接
s.close()
实例代码:运行服务端使之处于监听状态,在客户端发起请求
客户端:
Receive from server: 你好
please input a info:
hello world
Receive from server: hello world
please input a info:
hello python
Receive from server: hello python
please input a info:
服务端:
Client's address: ('127.0.0.1', 62285)
Receive Data: 你好
Receive Data: hello world
Receive Data: hello python
实例代码:socket实现简单SSH功能
服务端:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
# Author: Tdcqma
import socket
import os
server = socket.socket()
server.bind(('localhost',9761))
server.listen()
print('connection waitting...')
while True:
conn,addr = server.accept()
print('new connectiong:',addr)
while True:
print('等待新指令:')
data = conn.recv(1024)
if not data:
print('客户端已断开')
break
print('执行指令:',data)
cmd_res = os.popen(data.decode()).read()
print('before send',len(cmd_res),type(cmd_res))
if len(cmd_res) == 0:
cmd_res = 'cmd has no output...'
conn.send( str(len(cmd_res.encode())).encode('utf-8') )
conn.send(cmd_res.encode('utf-8'))
print('send done')
server.close()
客户端:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
# Author: Tdcqma
import socket
client = socket.socket()
client.connect(('localhost',9761))
while True:
cmd = input('>>:').strip()
if len(cmd) == 0: continue
client.send(cmd.encode('utf-8'))
cmd_res_size = client.recv(1024)
print('命令结果大小:',cmd_res_size.decode())
received_size = 0
received_data = b''
while received_size < int(cmd_res_size.decode()):
data = client.recv(1024)
received_size += len(data)
received_data += data
else:
print('cmd res receive done...',received_size)
print(received_data.decode())
client.close()
测试SSH连接:
客户端:
>>:ls -l
命令结果大小: 146
cmd res receive done... 146
total 16
-rw-r--r-- 1 pentest staff 666 Aug 28 15:47 sock_server_client.py
-rw-r--r-- 1 pentest staff 804 Aug 28 15:47 sock_server_ssh.py
>>:id
命令结果大小: 317
cmd res receive done... 317
uid=501(pentest) gid=20(staff) groups=20(staff),701(com.apple.sharepoint.group.1),12(everyone),61(localaccounts),79(_appserverusr),80(admin),81(_appserveradm),98(_lpadmin),33(_appstore),100(_lpoperator),204(_developer),395(com.apple.access_ftp),398(com.apple.access_screensharing-disabled),399(com.apple.access_ssh)
>>:df
命令结果大小: 424
cmd res receive done... 424
Filesystem 512-blocks Used Available Capacity iused ifree %iused Mounted on
/dev/disk1 487830528 258698920 228619608 54% 1172485 4293794794 0% /
devfs 367 367 0 100% 636 0 100% /dev
map -hosts 0 0 0 100% 0 0 100% /net
map auto_home 0 0 0 100% 0 0 100% /home
>>:
服务端:
connection waitting...
new connectiong: ('127.0.0.1', 50863)
等待新指令:
执行指令: b'ls -l'
before send 146 <class 'str'>
send done
等待新指令:
执行指令: b'id'
before send 317 <class 'str'>
send done
等待新指令:
执行指令: b'df'
before send 424 <class 'str'>
send done
等待新指令:
实例代码:socket实现简单FTP功能(测试环境为ubuntu,其中服务端与客户端均在同一台机器)
服务端:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
# Author: Tdcqma
import socket
import os
server = socket.socket()
server.bind(('localhost',9761))
server.listen()
print('connection waitting...')
while True:
conn,addr = server.accept()
print('new connectiong:',addr)
while True:
print('等待新指令:')
data = conn.recv(1024)
if not data:
print('客户端已断开')
break
cmd,filename = data.decode().split()
if os.path.isfile(filename):
f = open(filename,"rb")
file_size = os.stat(filename).st_size # get size of filename
conn.send( str(file_size).encode() ) # send server's file size
conn.recv(1024) # wait ack from client
for line in f:
conn.send(line)
f.close()
print('send done')
server.close()
客户端:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
# Author: Tdcqma
import socket
client = socket.socket()
client.connect(('localhost',9761))
while True:
cmd = input('>>:').strip()
if len(cmd) == 0: continue
if cmd.startswith("get"):
client.send(cmd.encode())
server_response = client.recv(1024)
print("server response:",server_response) # receive size of server's file
client.send(b"ready to recv file ") # send ack to server
file_total_size = int(server_response.decode())
received_size = 0
filename = cmd.split()[1] # get filename from "get filname"
f = open(filename + ".new","wb") # save file and named filename.new
while received_size < file_total_size:
data = client.recv(1024)
received_size += len(data)
f.write(data)
#print(file_total_size,received_size) # print received size and total size.
else:
print("file recv done!")
f.close()
client.close()
测试FTP文件发送
# 确认当前文件夹里的内容:
-rwxrwxr-x 1 pentester pentester 979 8月 28 19:49 ftp_socket_client.py*
-rwxrwxr-x 1 pentester pentester 867 8月 28 19:49 ftp_socket_server.py*
-rw-r--r-- 1 root root 226745856 8月 28 19:36 test.dd
# 服务端开启服务,并等待连接
pentester@pentest-machine:~/MyPythonObj/FTP$ ./ftp_socket_server.py
connection waitting...
new connectiong: ('127.0.0.1', 56498)
等待新指令:
send done
等待新指令:
# 客户端发起连接,并要求下载server端的test.dd保存到本地,并添加文件的后缀名.new
pentester@pentest-machine:~/MyPythonObj/FTP$ ./ftp_socket_client.py >>:get test.dd
server response: b'226745856'
file recv done!
# 查看已下载到文件
pentester@pentest-machine:~/MyPythonObj/FTP$ ls
ftp_socket_client.py ftp_socket_server.py test.dd test.dd.new
pentester@pentest-machine:~/MyPythonObj/FTP$ du -h test.dd.new
217M test.dd.new
用socketserver模块建立服务器
socketserver框架将处理请求分为了两个部分,分别对应请求处理类和服务器类。服务器类处理通信问题,请求处理类处理数据交换和传送。socketserver模块中使用的使用的服务器类主要有TCPServer、UDPServer、ThreadingTCPServer、ThreadingUDPServer、ForkingTCPServer,ForkingUDPServer其中有Threading的是多线程类,有Forking的是多进程类。要创建不同类型的服务器程序只需要继承其中之一或直接实例化,然后调用服务器类方法serve_forever()即可。 这些服务器的构造方法参数主要有: > server_address # 由IP地址和端口组成的元组 >RequestHandlerClass # 处理器类,共服务器类调用处理数据 socketserver模块中使用的处理器类主要有StreamRequestHandler(基于TCP协议的)和DatagramRequestHandler(基于UDP协议的),只要继承其中之一,就可以自定义一个处理器类。通过覆盖一下三个方法,实现自定义: > setup() 为请求准备请求处理器(请求处理的初始化工作) > handler() 完成具体的请求处理工作(解析请求、处理数据、发出响应) > finish() 清理请求处理器相关数据
代码部分(服务端)
import socketserver
class MyTCPHandler(socketserver.BaseRequestHandler):
def handle(self):
while True:
try:
self.data = self.request.recv(1024).strip()
if not self.data:
server.shutdown()
break
print("{} wrote:".format(self.client_address[0]))
print(self.data)
self.request.send(self.data.upper())
except ConnectionResetError as e:
print('err:',e)
break
if __name__ == "__main__":
HOST,PORT = 'localhost',9999
server = socketserver.ThreadingTCPServer((HOST,PORT),MyTCPHandler)
server.serve_forever()
代码部分(客户端)
import socket
client = socket.socket()
client.connect(('localhost',9999))
while True:
msg = input(">>:").strip()
if len(msg) == 0 : continue
client.send(msg.encode('utf-8'))
data = client.recv(1024)
print("recv:",data.decode())
client.close()
代码测试:
socketServer_client1: >>:from client_1 recv: FROM CLIENT_1 >>: socketServer_client2: recv: FROM CLIENT_2 >>: socketServer_server: 127.0.0.1 wrote: b'from client_1' 127.0.0.1 wrote: b'from client_2'
1.29 Paramiko
paramiko是一个基于SSH用于连接远程服务器并执行相关操作的一个模块,其中SSHClient可以实现SSH的功能,SFTPClinet可以实现SCP的功能。
实例代码:paramiko实现简单SSH功能
#! /usr/bin/env python
# -*- coding:utf-8 -*-
# Author: Tdcqma
import paramiko
# 接收用户输入的命令
com = input('please input your command:').strip()
# 创建SSH连接对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器,其中hostname为被连接服务器hostname或ip,port为ssh端口,username与password为远程连接的用户名密码。
ssh.connect(hostname='192.192.168.168',port=22,username='root',password='123456')
# 执行命令,返回值中包括标准输入、标准输出以及标准错误。
stdin,stdout,stderr = ssh.exec_command(com)
# 获取命令执行结果
res,err = stdout.read(),stderr.read()
result = res if res else err
# 由于result是bytes类型,转化为utf-8类型后即可恢复原是命令行格式
#print(result,type(result))
# 使用utf-8进行编码,格式化输出
print('命令执行结果:'.center(50,'-'))
print(result.decode('utf-8'))
# 关闭ssh连接
ssh.close()
输出:
/myPython/paramikoTest$ python3 ssh.py
please input your command:uname -a
---------------------命令执行结果:----------------------
Linux jumpserver 2.6.32-573.26.1.el6.x86_64 #1 SMP Wed May 4 00:57:44 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
实例代码:paramiko调用SFTPClient方法,实现scp功能
import paramiko
# 绑定连接和登录信息
transport = paramiko.Transport(('192.192.168.168',22))
transport.connect(username='root',password='123456')
# paramiko调用SFTPClient方法,实现Linux的scp功能
sftp = paramiko.SFTPClient.from_transport(transport)
# 上传文件到服务器,其中putfile_test为本地文件,/tmp/putfile为远程服务器的路径及保存文件名
sftp.put('putfile_test','/tmp/putfile.txt')
# 下载服务器文件到本地,其中/tmp/remote_file.txt为远程服务器上/tmp路径下的文件,保存到本地当前目录,保存到文件名为local_file.txt
sftp.get('/tmp/remote_file.txt','local_file.txt')
# 关闭连接
transport.close()
实例代码:paramiko基于公钥认证实现SSH连接
#! /usr/bin/env python
# -*- coding:utf-8 -*-
# Author: Tdcqma
'''
主意:在做基于公钥认证时需要现在本地生成公钥秘钥对,linux下可以使用ssh-keygen生成,windows下可以通过xshell生成。然后将公钥内容复制粘贴到要访问服务器指定用户的家目录下.ssh/authorized_keys里,而paramiko.RSAKey.from_private_key_file()里则是指本地生成的私钥,切勿弄混。
'''
import paramiko
private_key = paramiko.RSAKey.from_private_key_file("/home/pentest/.ssh/id_rsa")
# 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器,此处仅制定hostname、port、username及pkey即可,不需要密码了。
ssh.connect(hostname='192.192.168.168', port=22, username='root', pkey=private_key)
# 执行命令
stdin, stdout, stderr = ssh.exec_command('ifconfig')
# 获取命令结果
result = stdout.read()
# 打印输出命令执行结果
print(result.decode())
# 关闭连接
ssh.close()
输出:
python3 ssh_rsa.py
docker0 Link encap:Ethernet HWaddr 06:D1:E4:E6:41:EE
inet addr:172.17.42.1 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::44cc:ddff:fe91:722c/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1408 errors:0 dropped:0 overruns:0 frame:0
TX packets:1235 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:3662398 (3.4 MiB) TX bytes:285595 (278.9 KiB)
...
1.30 爬虫
爬虫简介...
Requests模块:发送get请求
response = requests.get('https://www.sogou.com/web?query=python')
print(response.text)
Requests模块:发送post请求,尝试登录操作,post登录请求数据需要借用浏览器查看元素(网络),例如查看登录数据的内容
form_data = {
'phone':'13311111111',
'password':'111111',
'oneMonth':'1'
}
response = requests.post(
url = 'http://dig.chouti.com/login',
data = form_data
)
print(response.text)
《持续更新中》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号