学习sql笔记
SQL 学习
学习地址:https://liaoxuefeng.com/books/sql/introduction/index.html
我是根据学习地址的练习题顺序来进行学习
基本语法
select 列名,列名1 form 表明 where 判断条件
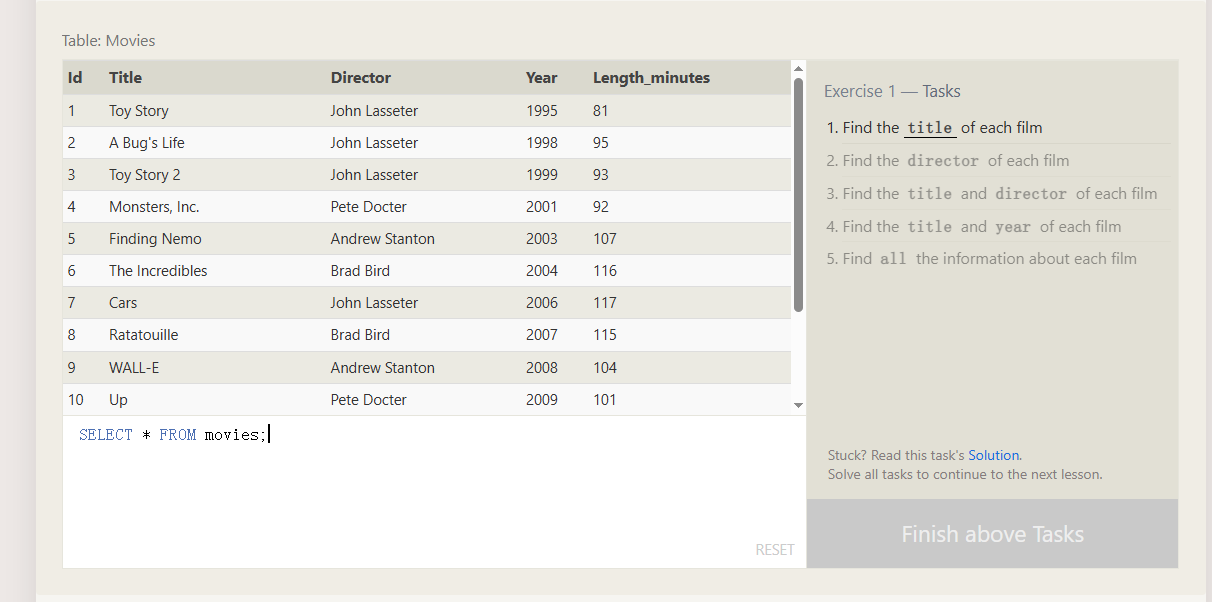
SQL带判断查询 第一部分
这一步又能认识到咱们,开始提到的,where 判断 还会有两个标识符 OR(代表或者 就是包含一项就行) AND(就是并且的意思需要都满足条件)
列:
SELECT title, year FROM movies WHERE year < 2000 OR year > 2010;
ORDER BY 通过....排序 ASC 升序 DESC 降序 LIMIT 多少条 就相当于请求接口获得第一页的数据
想获取的第二页的怎么实现
在LIMIT 后面加上 OFFSET 偏移量 5 获取第二页的第五个
列:
SELECT * FROM movies ORDER BY year ASC LIMIT 5 OFFSET 5
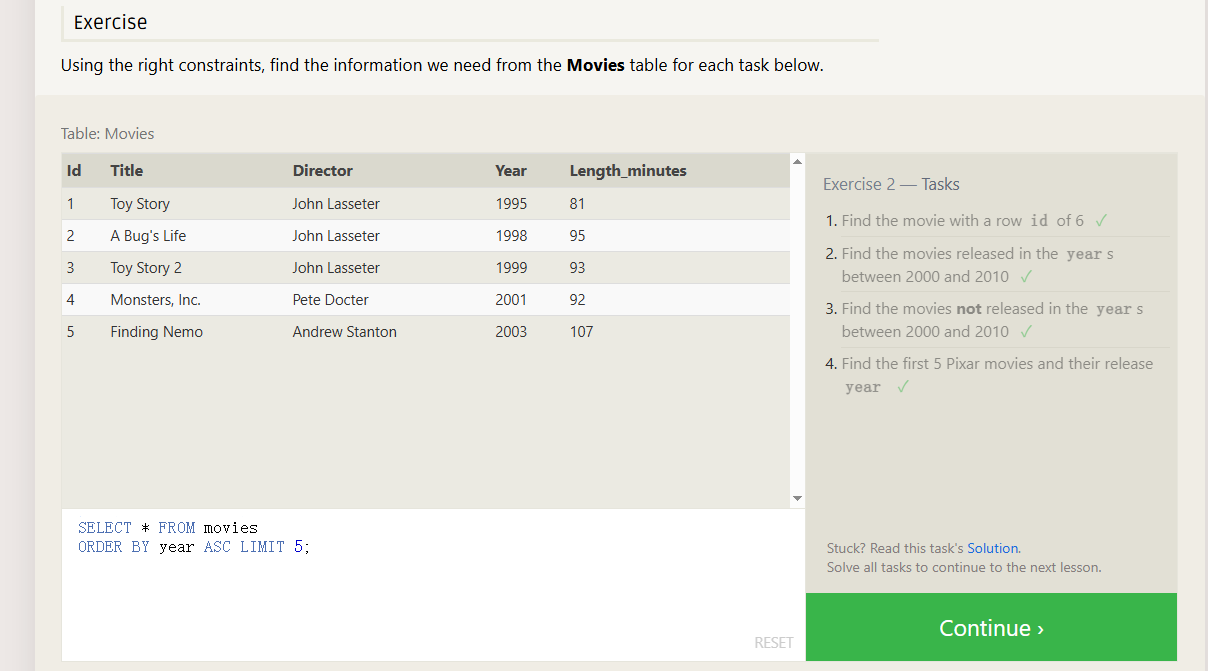
SQL查询第二部分
LIKE 进行模糊查询 % 百分号 相当于通配符 IN查询的时候不能解析通配符 因为IN是精准查询 还有 = 也是相当于精准查询
%在前 = 以...结尾%在后 = 以...开头%前后都有 = 包含
in 和 = 都是精准匹配 他们的区别
in能一次匹配多个接过 IN(1,2,3,4,5,6,7)
= 一次只能匹配一个结果
他们在使用的时候 需要执行一个列名
列:
name = 'sun'
name IN('s', 'u' , 'm')
name LIKE('%sun%')
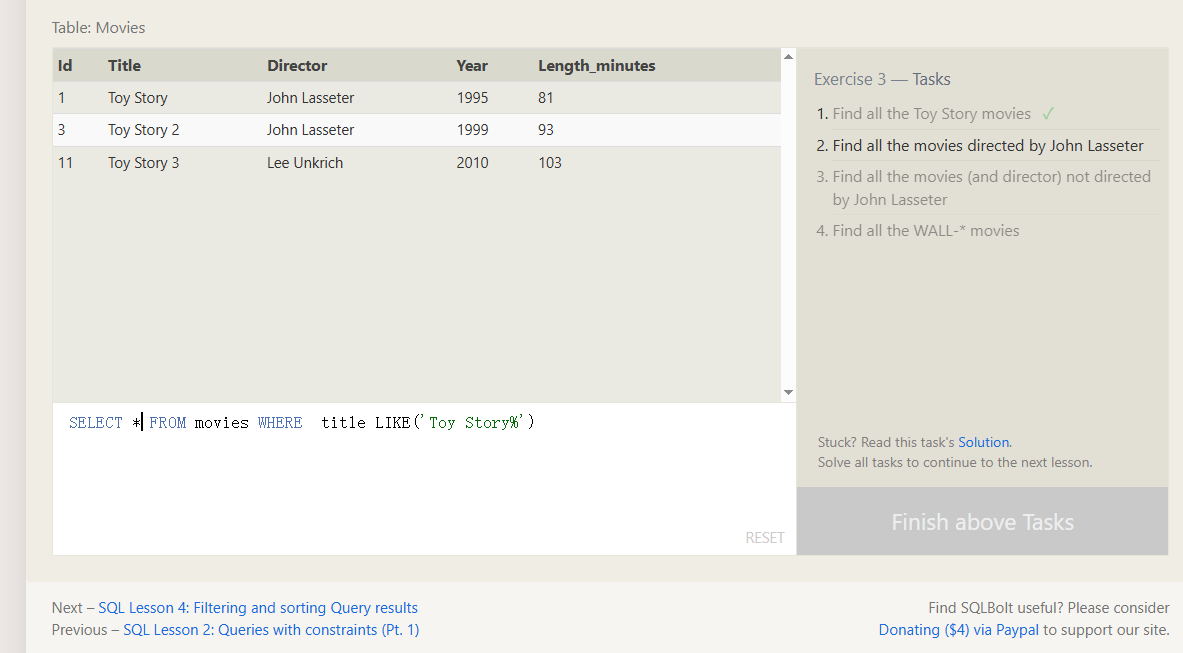
SQL筛选和排序结果
ASC 升序 DESC 降序
ASC 为什么会按照 A-Z 进行字符排序 根本原因:字符编码 计算机中所有的字符(包括字母、数字、符号)都有对应的数字编码。 ASCII 编码表(部分): text A → 65 B → 66 C → 67 ... Z → 90 a → 97 b → 98 c → 99 ... z → 122 0 → 48 1 → 49 ... 9 → 57 ORDER BY ASC 的工作原理 当你说 ORDER BY director ASC 时,数据库实际上是: 取出每个名字的字符编码 按编码的数字大小升序排列 由于字母编码是连续的,自然就按字母顺序了
列:
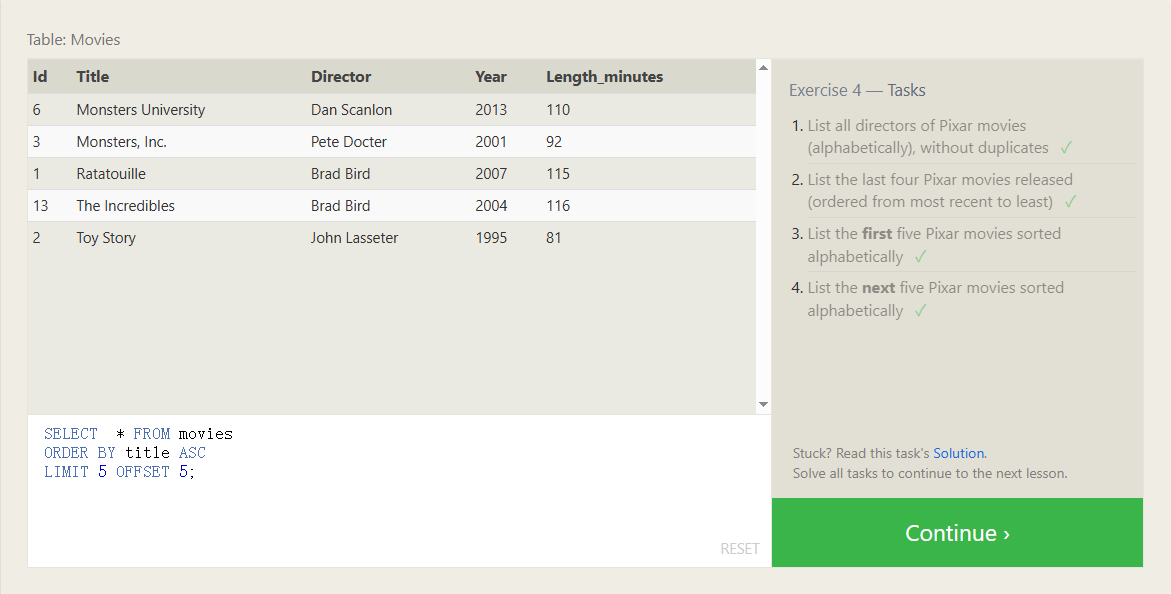
SQL 使用JOIN进行多表查询
FORM 表名后面增加 INNER JOIN 内部连接 接其他表名
找到表名之后 使用 ON 设计连接条件 简单来说就是使用什么 相等的唯一值 来把两个表的数据拼接在一个表里面
ON 是 SQL 标准中专门为 JOIN 操作设计的连接条件关键字,它的作用是: 指定两个表如何连接 定义匹配规则 确保连接的相关性
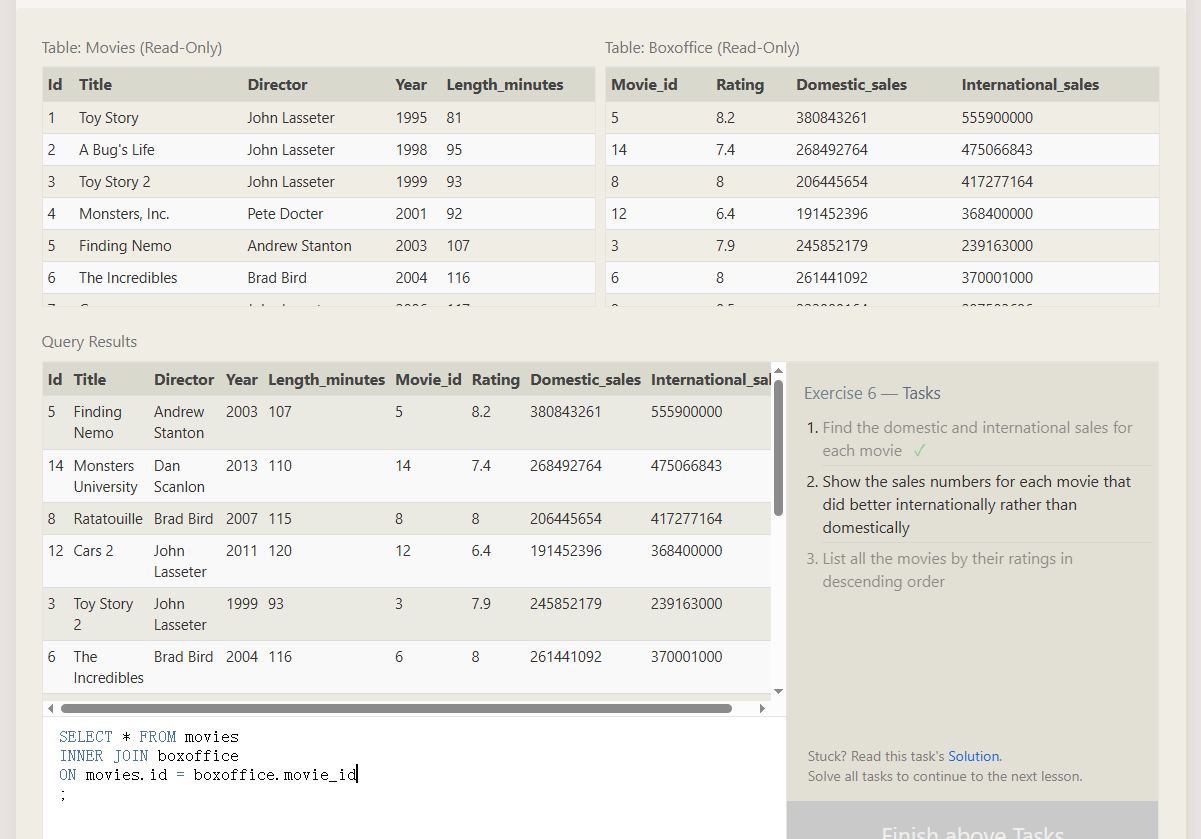
WHERE 判断条件继续往后面添加
如下图:
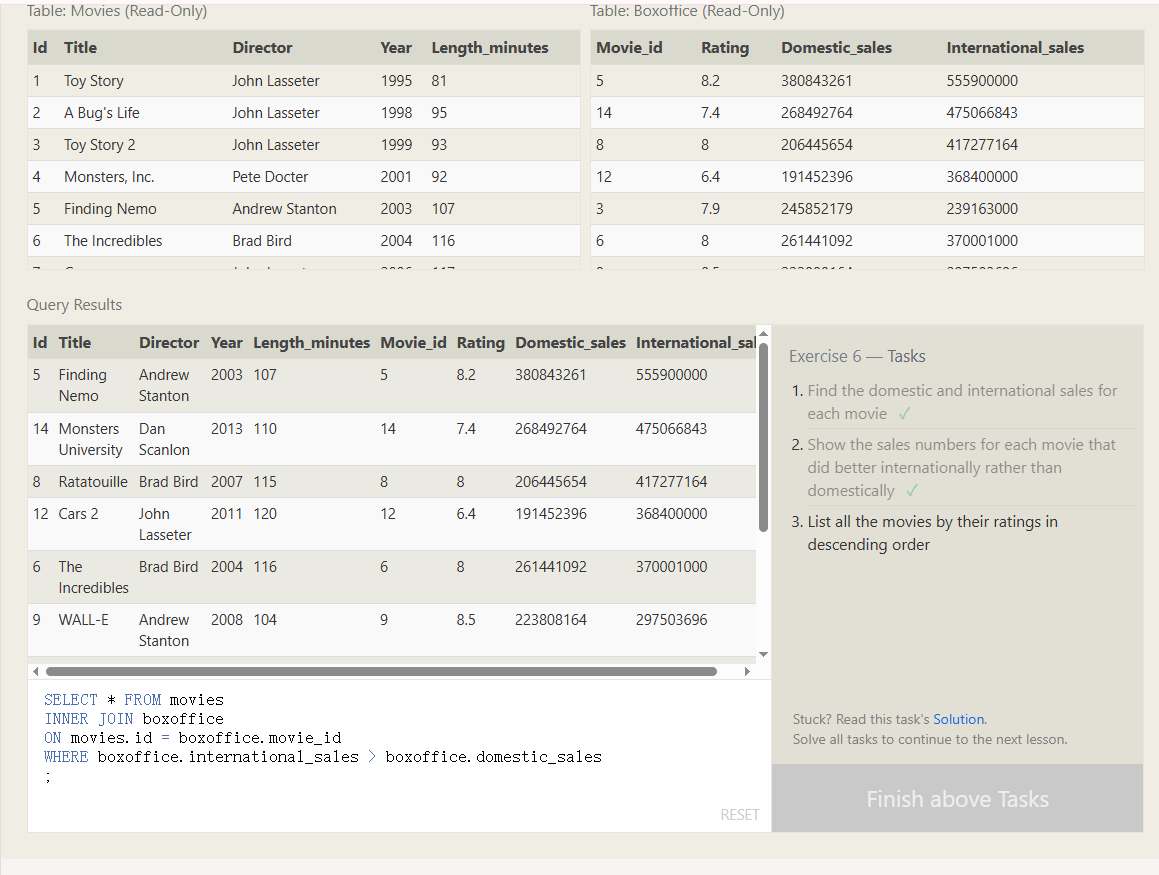
SQL外链接
LEFT JOIN 的主要作用是:保留左表的所有记录,同时匹配右表中的相关记录 JOIN 类型 结果特点 中文记忆口诀 LEFT JOIN 左表全留,右表可空 "左全右空" INNER JOIN 只显示两边都有的记录 "内连匹配,缺一不可" RIGHT JOIN 右表全留,左表可空 "右全左空"
左表是"主角",保证所有记录都出现
右表是"配角",有匹配就显示,无匹配就 NULL
常用于:主从表查询、数据完整性检查、统计分析
这是一个sql FROM 后面 跟的就是 左表(主角) left join 后面跟的就是 右表(配角)
SELECT DISTINCT building_name, role
FROM buildings
LEFT JOIN employees
ON building_name = building;
例:
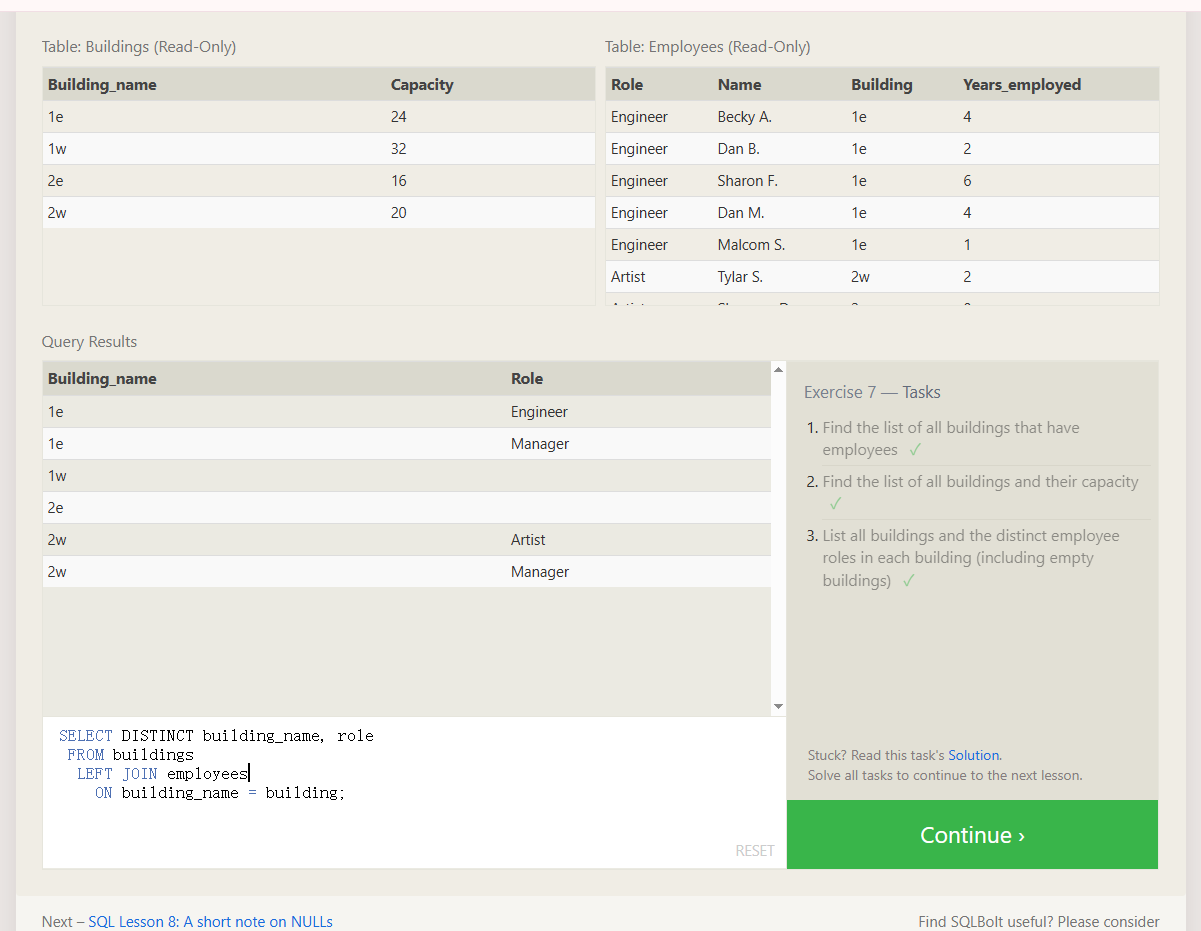
疑:为什么 我的主表上面只有4条数据 查出来会有多少

带表达式的执行 别名
就下面这个例子 咱们已经把两列相加了 并且也做了除法 但是咱们查询出来的表名是咱们表达式
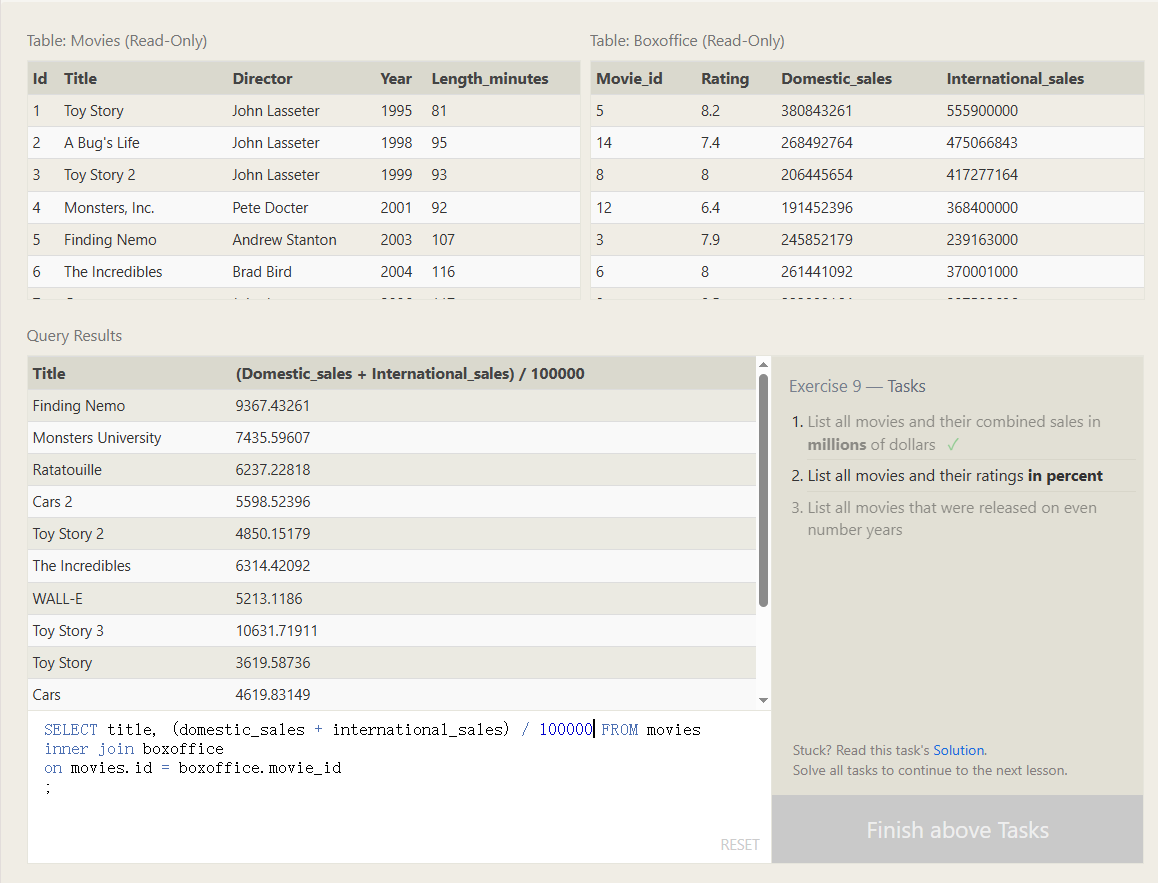
SELECT title, (domestic_sales + international_sales) / 100000 AS Money FROM movies
inner join boxoffice
on movies.id = boxoffice.movie_id
;
可以在后面加上as 可以给计算出来的新列命名
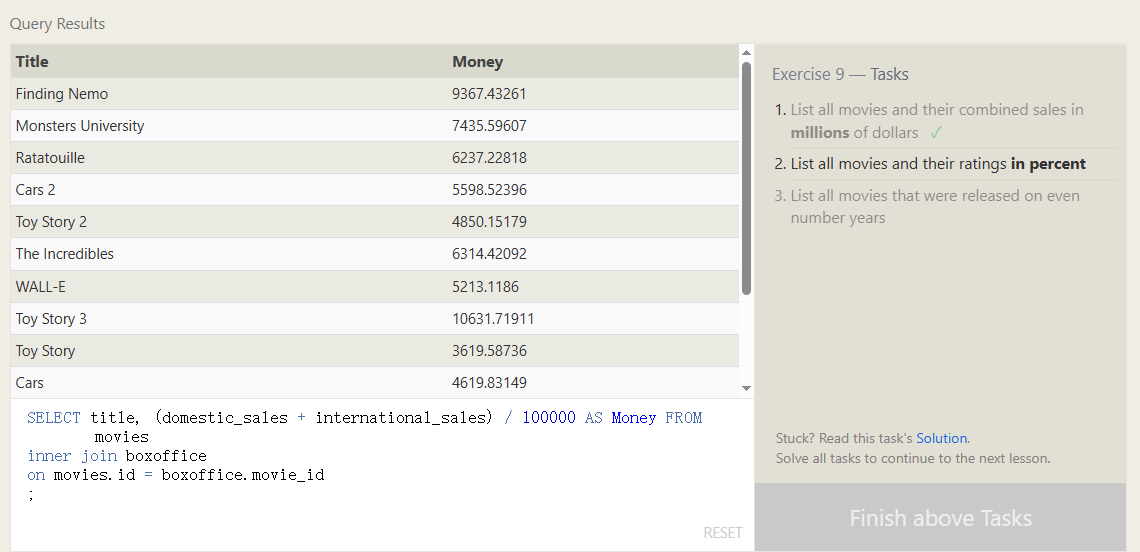
这个题还是有点迷惑性的 咱们应该什么时候去用WHERE 什么时候应该用带表达式的别名
-
WHERE:决定"哪些行"要显示
-
SELECT表达式:决定"这些行显示什么内容"
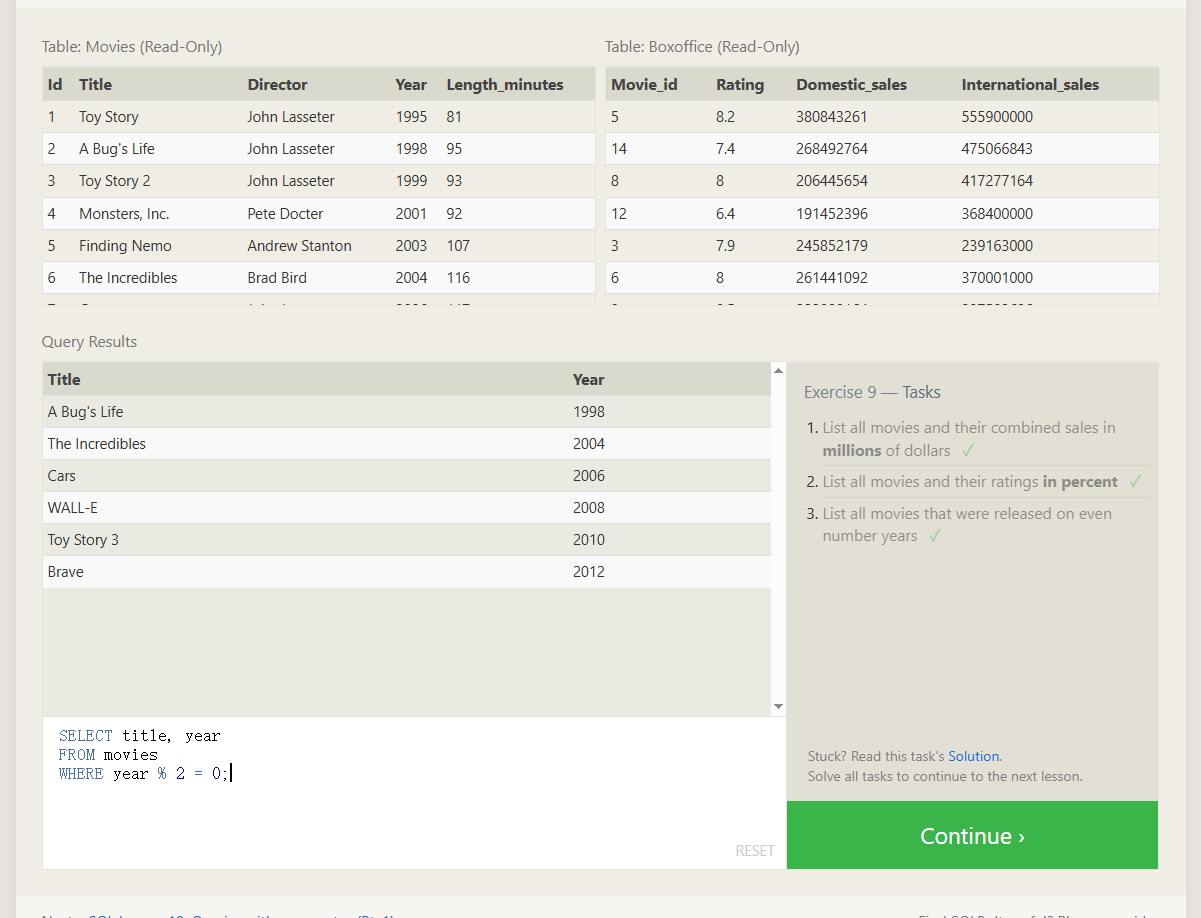
带聚合函数的查询
以下是一些我们将在示例中用到的常用聚合函数: 功能 描述 COUNT( * ),COUNT(列) 如果未指定列名,则此函数用于统计组中的行数。否则,此函数用于统计组中指定列中非空值的行数。
COUNT 就像是 SQL 中的"计数器",帮你快速统计各种数据量! MIN(列) 查找组中所有行指定列中的最小数值。 MAX(列) 查找组中所有行指定列中的最大数值。 AVG(列) 查找组中所有行的指定列的平均数值。 SUM(列) 计算组中指定列中各行数值的总和。
分组聚合函数
除了对所有行进行聚合之外,您还可以将聚合函数应用于组内的各个数据组(例如,喜剧片与动作片的票房收入)。
这样,结果的数量将与GROUP BY子句定义的唯一组的数量相同。
例下图:
对分组后的筛选
HAVING 子句的作用是 对分组(GROUP BY)后的结果进行筛选,就像 WHERE 子句用于在分组前筛选单个行一样。
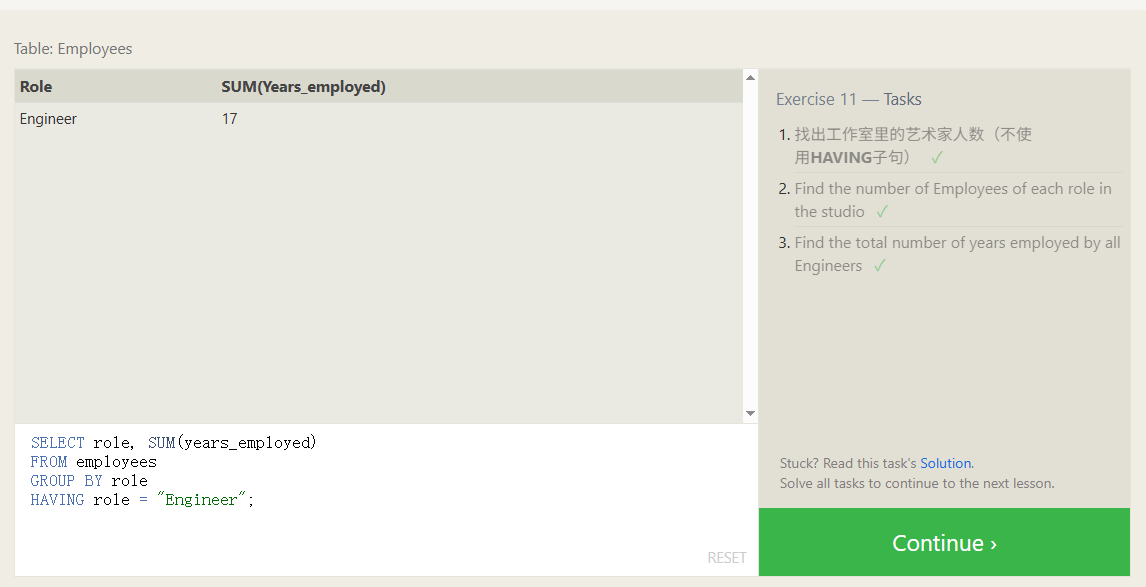
SELECT role, SUM(years_employed)
FROM employees
GROUP BY role
HAVING role = "Engineer";
学习进度:https://sqlbolt.com/lesson/select_queries_with_aggregates_pt_2
本文来自博客园,作者:樱桃树下的约定,转载请注明原文链接:https://www.cnblogs.com/tcyweb/p/19221867

 浙公网安备 33010602011771号
浙公网安备 33010602011771号