
爬虫_scrapy案例
打开一个cmd,输入
python -m pip install --upgrade pip
pip install wheel
pip install lxml
pip install twisted
pip install pywin32
pip install scrapy
然后输入
scrapy startproject 项目名
cd 项目名
scrapy genspider 爬虫名 域名
大致生成
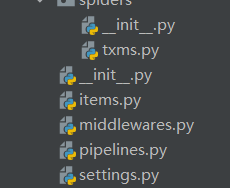
打开文件settings.py 找到机器人协议
ROBOTSTXT_OBEY:是否遵循机器人协议,默认是true,需要改为false
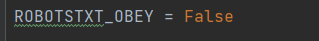
DOWNLOAD_DELAY:下载延迟时间,单位是秒

TEM_PIPELINES:项目管道,300为优先级,越低越爬取的优先度越高

DEFAULT_REQUEST_HEADERS:默认请求头

确认需要的数据 items.py
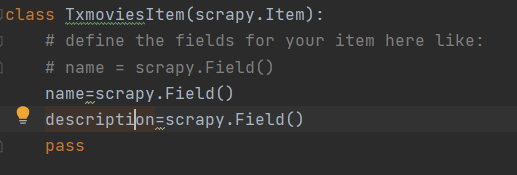
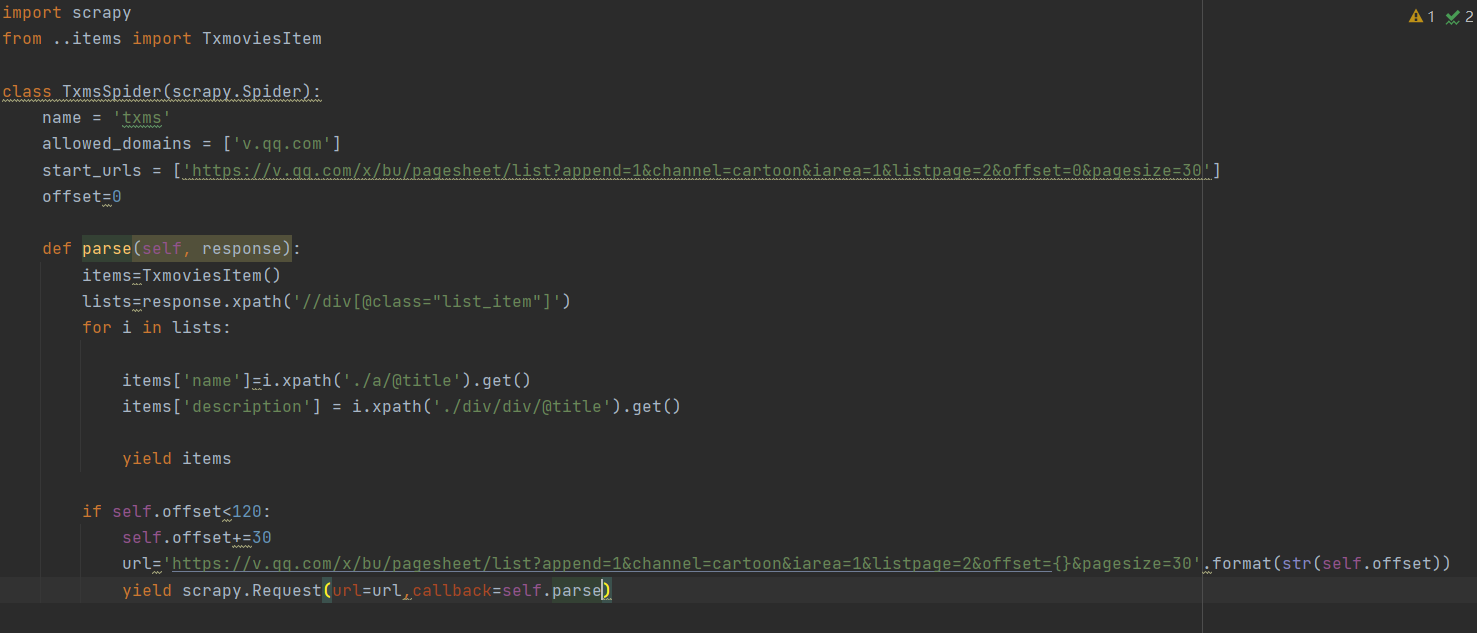
制作程序

 浙公网安备 33010602011771号
浙公网安备 33010602011771号