


5.4 综合案例2-------爬取起点中文网小说信息
本节将利用Requests和Lxml第三方库,爬取起点中文小说信息,并存储到Excel文件中。
5.4.1 将数据存储到Excel文件中
使用Python的第三方库xlwt,可将数据写入Excel中,通过pip进行安装即可:
pip3 install xlwt
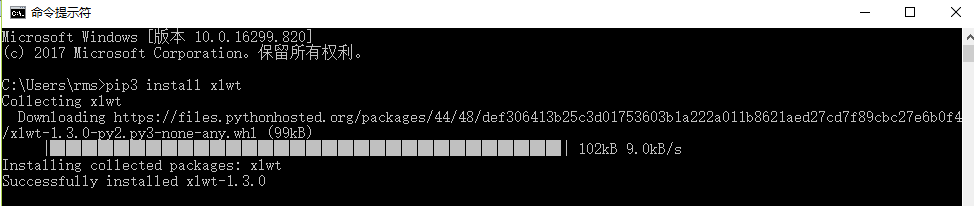
执行结果如下图所示。
通过下面的代码,便可将数据写入Excel中:
import xlwt #将数据写入Excel的库文件中 book = xlwt.Workbook(encoding='utf-8') #创建工作簿 sheet = book.add_sheet('Sheet1') #创建工作表 sheet.write(0,0,'python') #在相应单元格写入数据 sheet.write(1,1,'love') book.save('test.xls') #保存到文件中
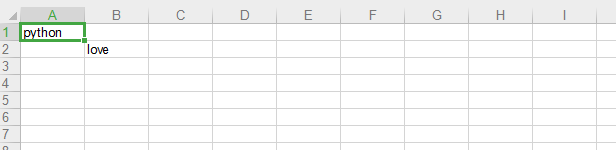
程序运行后,可在本地找到该Excel文件,结果如图所示。
代码说明如下:
⑴导入xlwt库。
⑵通过Workbook()方法创建一个工作簿。
⑶创建一个名字为Sheet1的工作表。
⑷写入数据,可以看出第一个和第二个参数为Excel表格的单元格位置,第三个为写入内容。
⑸保存到文件中。
5.4.2 爬虫思路分析
⑴爬取的内容为起点中文网的全部作品信息(http://a.qidian.com/),如下图所示。
⑵爬取起点中文网的全部作品信息的前100页,通过手动浏览,下面为第2页的网址:
https://www.qidian.com/all?orderId=&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=0&page=2
猜想这些字段是用来控制作品分类的,我们爬取的为全部作品,依次删掉一些参数检查,发现将网址改为https://www.qidian.com/all?page=2后,也可以访问相同的信息,通过多页检验,证明了修改的合理性,以此来构造前100页URL
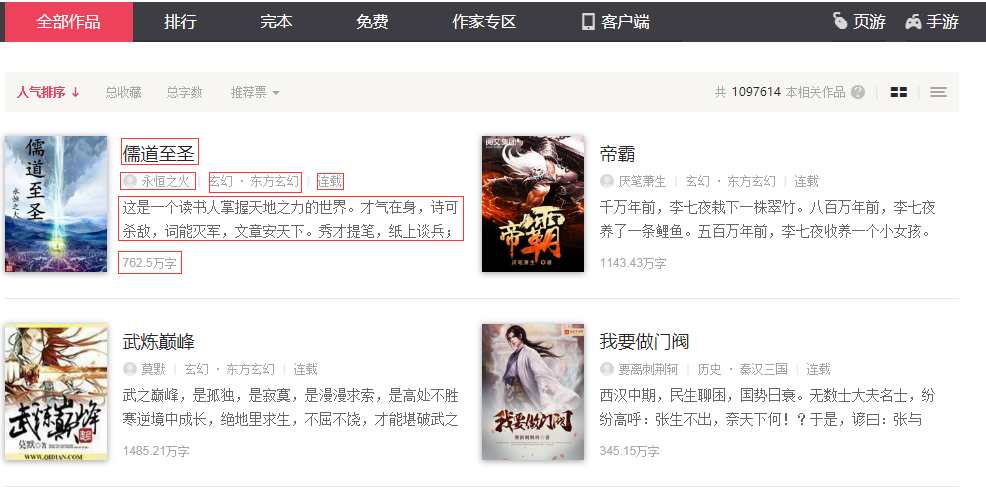
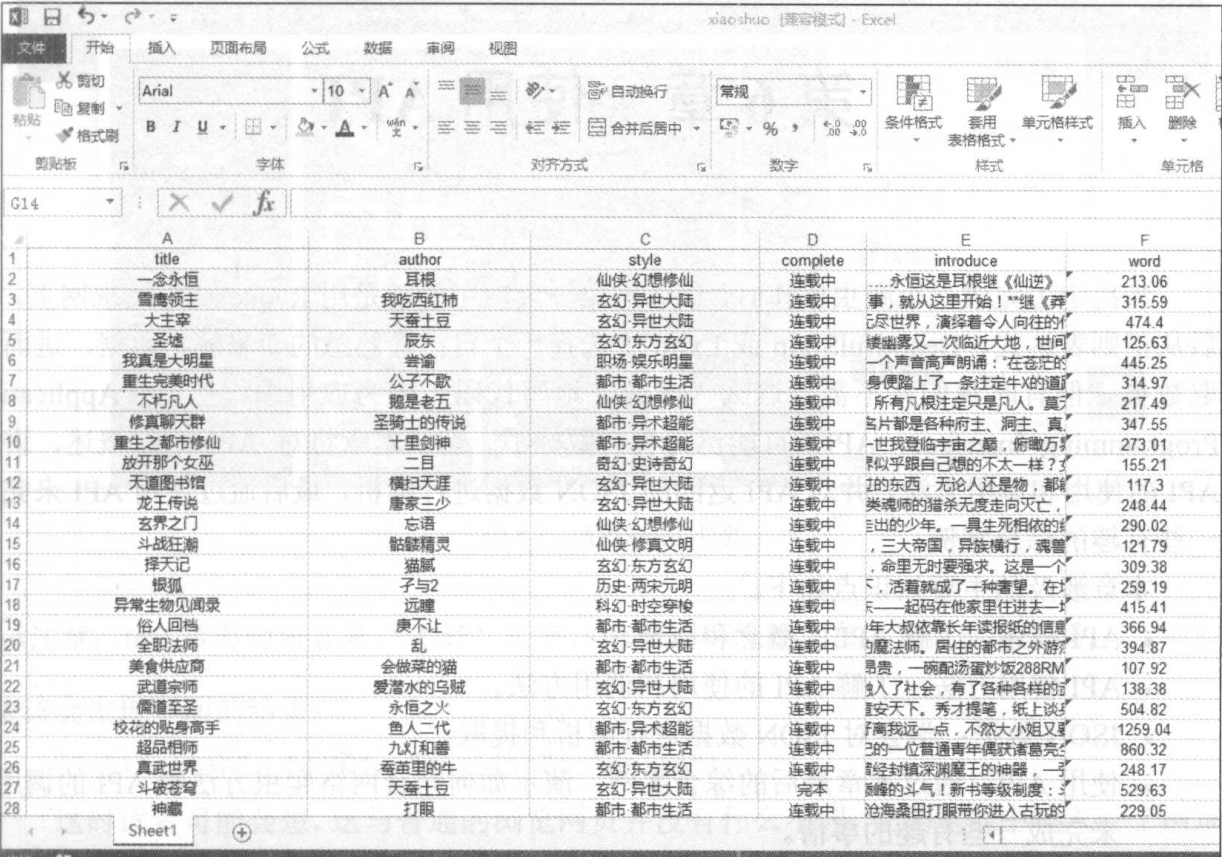
⑶需要爬取的信息有:小说名、作者ID、小说类型、完成情况、摘要和字数,如下图所示。
⑷运用xlwt库,把爬取的信息存储到本地的Excel表格中。
5.4.3 爬虫代码分析:
1 import xlwt 2 import requests 3 from lxml import etree 4 import time #导入相应的库文件 5 6 all_info_list = [] #初始化列表,存入爬虫数据 7 8 def get_info(url): #定义获取爬虫信息的函数 9 html = requests.get(url) 10 selector = etree.HTML(html.text) 11 infos = selector.xpath('//ul[@class="all-img-list cf"]/li') #定位大标签,以此循环 12 13 for info in infos: 14 title = info.xpath('div[2]/h4/a/text()')[0] 15 author = info.xpath('div[2]/p[1]/a[1]/text()')[0] 16 style_1 = info.xpath('div[2]/p[1]/a[2]/text()')[0] 17 style_2 = info.xpath('div[2]/p[1]/a[3]/text()')[0] 18 style = style_1+'·'+style_2 19 complete = info.xpath('div[2]/p[1]/span/text()')[0] 20 introduce = info.xpath('div[2]/p[2]/text()')[0].strip() 21 word = info.xpath('div[2]/p[3]/span/text()')[0].strip('万字') 22 info_list = [title,author,style,complete,introduce,word] 23 all_info_list.append(info_list) #把数据存入列表 24 time.sleep(1) #睡眠1秒 25 26 if __name__ == '__main__': #程序主入口 27 urls = ['https://www.qidian.com/all?page={}'.format(str(i)) for i in range(1,29655)] 28 for url in urls: 29 get_info(url) 30 header = ['title','author','style','complete','introduce','word'] #定义表头 31 32 book = xlwt.Workbook(encoding='utf-8') #创建工作簿 33 sheet = book.add_sheet('Sheet1') #创建工资表 34 for h in range(len(header)): 35 sheet.write(0, h, header[h]) #写入表头 36 i = 1 37 for list in all_info_list: 38 j = 0 39 for data in list: 40 sheet.write(i, j,data) 41 j += 1 42 i += 1 #写入爬虫数据 43 book.save('xiaoshuo.xls') #保存文件
代码分析:
⑴第1~4行导入程序所需要的库,xlwt用于写入数据到Excel文件中,requests库用于请求网页,lxml库用于解析提取数据,time库的sleep()方法可以让程序暂停。
⑵第6行定义了all_info_list列表,用于存储爬取的数据。
⑶第8~24行定义获取爬虫信息的函数,用于获取小说信息,并把小说信息以列表的形式存储到all_info_list列表中。
注意:列表中有列表,这样存储是为了方便写入Excel中。
⑷第26~43行为函数主入口,构造前100页URL,依次调用函数获取小说信息,最后把信息写入Excel文件中。
程序运行后,将会存入数据倒Excel表格中,如图所示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号