


5.2 Xpath语法
Xpath是一门在XML文档中查找信息的语言,对HTML文档也有很好的支持。本节将介绍Xpath的常用语法,讲解Xpath语法在爬虫中的使用技巧,最后通过案例对正则表达式、BeautifulSoup和Lxml进行性能对比。
5.2.1 节点关系
1、父节点
每个元素及属性都有一个父节点,在下面的例子中,user元素是name、sex、id及goal元素的父节点:
<user> <name>xiao ming</name> <sex>J K .Rowling</sex> <id>34</id> <goal>89</goal> </user>
2、子节点
元素节点可有0个、一个或多个子节点,在下面的例子中,name、sex、id及goal元素都是user元素的子节点:
<user> <name>xiao ming</name> <sex>J K. Rowling</sex> <id>34</id> <goal>89</goal> </user>
3、同胞节点
同胞节点拥有相同的父节点,在下面的例子中,name、sex、id及goal元素都是同胞节点:
<user> <name>xiao ming</name> <sex>J K. Rowling</sex> <id>34</id> <goal>89</goal> </user>
4、先辈节点
先辈节点指某节点的父、父的父节点等,在下面的例子中,name元素的先辈是user元素和user_database元素:
<user_database> <user> <name>xiao ming</name> <sex>J K. Rowling</sex> <id>34</id> <goal>89</goal> </user> </user_database>
5、后代节点
后代节点指某个节点的子节点,子节点的子节点等,在下面的例子,user_database的后代是user、name、sex、id及goal元素:
<user_database> <user> <name>xiao ming</name> <sex>J K. Rowling</sex> <id>34</id> <goal>89</goal> </user> </user_database>
5.2.2 节点选择
Xpath使用路径表达式在XML文档中选取节点。节点是通过沿着路径或者step来选取的,如表所示。
节点选择
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
通过前面的例子进行举例,如下图所示。
| 路径表达式 | 结果 |
| user_database | 选取元素user_database的所有子节点 |
| /user_database | 选取根元素user_database.注释:假如路径起始于正斜杠(/),则此路径始终代表到某元素的绝对路径 |
| user_database/user | 选取属于user_database的子元素的所有user元素 |
| //user | 选取所有user子元素,而不管它们在文档中的位置 |
| user_database//user | 选择属于user_database元素的后代的所有user元素,而不管它们位于user_database之下的什么位置 |
| //@attribute | 选取名为attribute的所有属性 |
Xpath语法中的谓语用来查找某个特定的节点或者包含某个指定值的节点,谓语被嵌在方括号中。常见的谓语如表所示。
| 路径表达式 | 结果 |
| /user_database/user[1] | 选取属于user_database子元素的第一个user元素 |
| //li[@attribute] | 选取所有拥有名为attribute属性的li元素 |
| //li[@attribute='red'] |
选取所有li元素,且这些元素拥有值为red的attribute属性 |
Xpath中也可以使用通配符来选取位置的元素,常用的就是“*”通配符,它可以匹配任何元素节点。
5.2.3 使用技巧
在爬虫实战中,Xpath路径可以通过Chrome复制得到,如图所示。
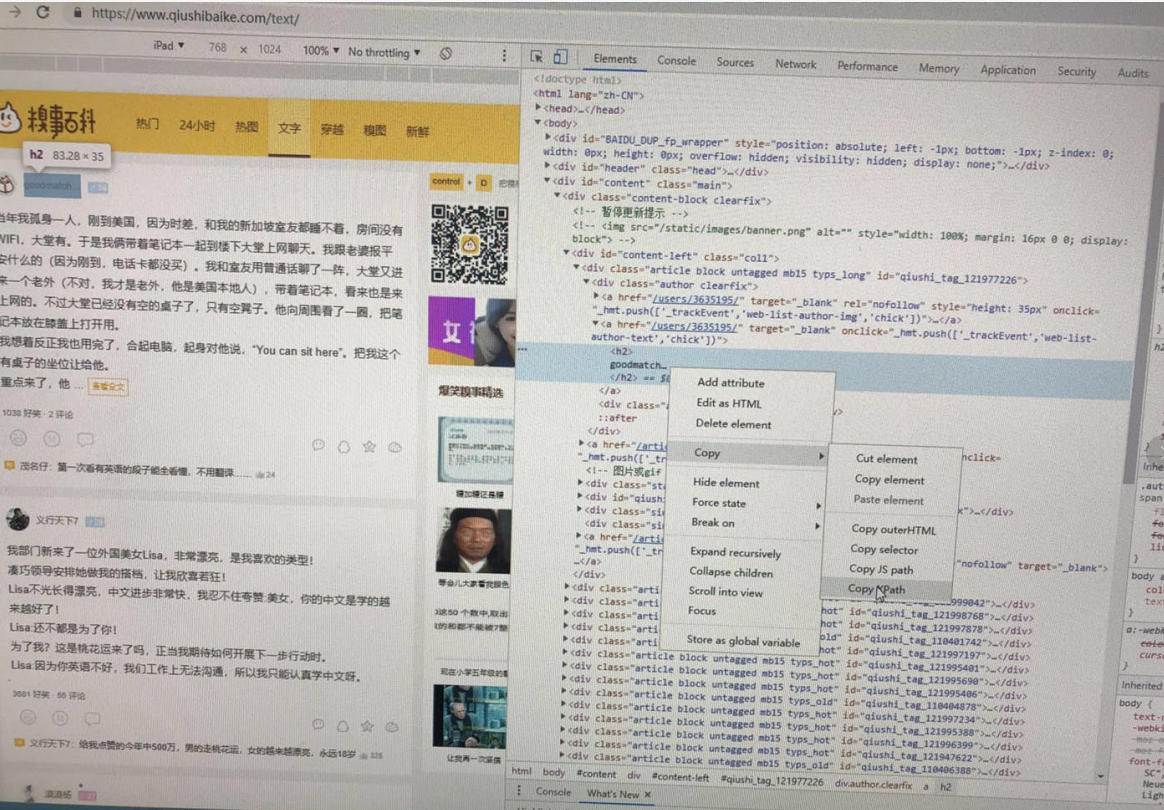
⑴鼠标光标定位到想要提取的数据位置,右击,从弹出的快捷菜单中选择“检查”命令。
⑵在网页源代码中右击所选元素。
⑶从弹出的快捷菜单中选择Copy Xpath命令。这时便能得到:
//*[@id="qiushi_tag_121999042"]/div[1]/a[2]/h2
通过代码即可得到用户id:
import requests from lxml import etree headers = { 'User-Agent': 'Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1' } url = 'http://www.qiushibaike.com/text/' res = requests.get(url,headers=headers) selector = etree.HTML(res.text) id = selector.xpath('//*[@id="qiushi_tag_121999042"]/div[1]/a[2]/h2/text()') print(id)
注意:通过/text()可以获取标签中的文字信息。
结果为:

上面的结果为列表的数据结构,可以通过切片获取为字符串数据结构:
import requests from lxml import etree headers = { 'User-Agent': 'Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1' } url = 'http://www.qiushibaike.com/text/' res = requests.get(url,headers=headers) selector = etree.HTML(res.text) id = selector.xpath('//*[@id="qiushi_tag_121999042"]/div[1]/a[2]/h2/text()')[0] print(id)
当需要进行用户ID的批量爬取时,通过类似于BeautifulSoup中的selector()方法删除谓语部分是不可行的。这时的思路为“先抓大后抓小,寻找循环点”。打开Chrome浏览器进行“检查”,通过“三角形符号”折叠元素,找到每个段子完整的信息标签,如图所示,每个div标签为一个段子信息。

⑴首先通过复制构造div标签路径,此时的路径为:
'//div[@class="article block untagged mb15 typs_hot" ]'
这样就定位到了每个段子信息,这就是“循环点”。
⑵通过Chrome浏览器进行“检查”定位用户ID,复制Xpath到记事本中:
//*[@id="qiushi_tag_121999042"]/div[1]/a[2]/h2
因为第一部分为循环部分,将其删除得到:
div[1]/a[2]/h2
这便是用户ID的信息。
注意:这里就不需要斜线作为开头了。
完整获取用户ID的代码如下:
import requests from lxml import etree headers = { 'User-Agent': 'Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1' } url = 'http://www.qiushibaike.com/text/' res = requests.get(url,headers=headers) selector = etree.HTML(res.text) url_infos = selector.xpath('//div[@class="article block untagged mb15 typs_hot" ]') # url_infos = selector.xpath('//div[@class="article block untagged mb15 typs_old" ]') # url_infos = selector.xpath('//div[@class="article block untagged mb15 typs_long" ]') for url_info in url_infos: id = url_info.xpath('div[1]/a[2]/h2/text()')[0] print(id)
程序运行结果如图所示。

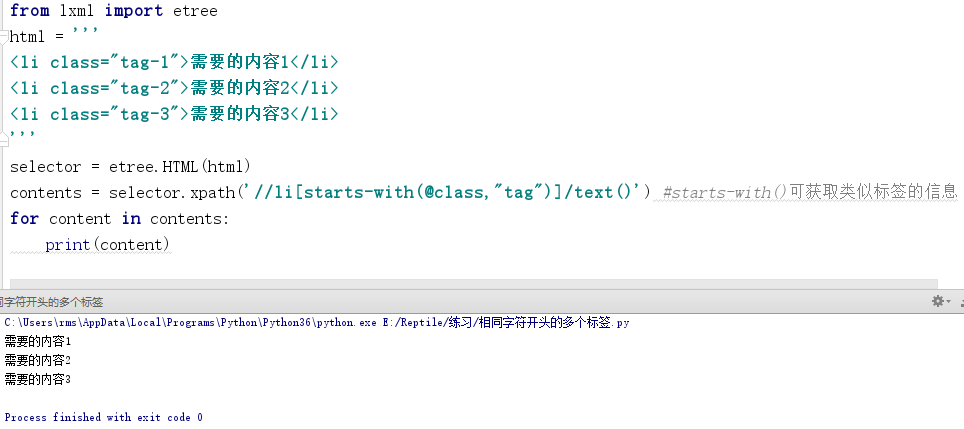
有时候会遇到相同的字符开头的多个标签:
<li class="tag-1">需要的内容1</li> <li class="tag-2">需要的内容2</li> <li class="tag-3">需要的内容3</li>
想同时爬取时,不需要构造多个Xpath路径,通过starts-with()便可以获取多个标签内容:
from lxml import etree html = ''' <li class="tag-1">需要的内容1</li> <li class="tag-2">需要的内容2</li> <li class="tag-3">需要的内容3</li> ''' selector = etree.HTML(html) contents = selector.xpath('//li[starts-with(@class,"tag")]/text()') #starts-with()可获取类似标签的信息 for content in contents: print(content)
程序运行结果如图所示。
当遇到标签套标签情况时:
<div class="red">需要的内容1 <h1>需要内容2</h1> </div>
想同时爬取文本内容,可以通过string(.)完成:
from lxml import etree html2 = ''' <div class="red">需要的内容1 <h1>需要内容2</h1> </div> ''' selector = etree.HTML(html2) content1 = selector.xpath('//div[@class="red"]')[0] content2 = content1.xpath('string(.)') #string(.)方法可用于标签套标签情况 print(content2)
程序运行结果如下图

5.2.4 性能对比
前面提到Lxml库的解析速度快,但是“口说无凭”,本节将会通过代码对正则表达式、Beautiful和Lxml进行性能对比。
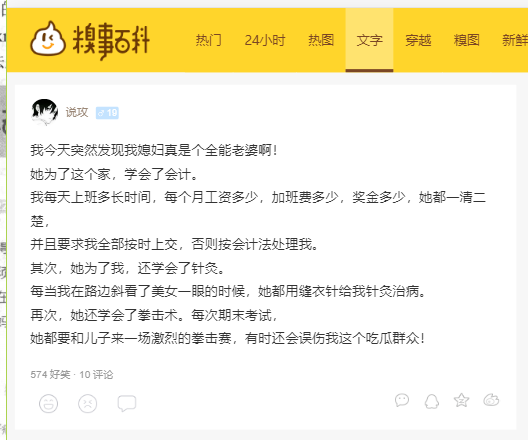
⑴通过3种方法爬取糗事百科文字内容中的信息,如图所示。
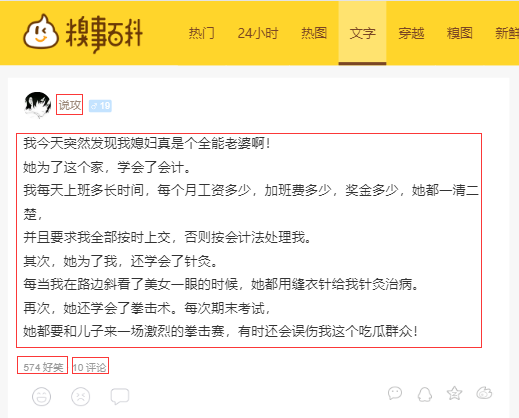
⑵由于是比较性能,爬取的信息并不是很多,爬取的信息有:用户ID、发表段子文字信息、好笑数量和评论数量,如图所示。
⑶爬取的数据只做返回,不存储。代码如下:
1 import requests 2 import re 3 from bs4 import BeautifulSoup 4 from lxml import etree 5 import time #导入相应库文件 6 7 headers = { 8 'User-Agent': 'Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1' 9 } #加入请求头 10 11 urls = ['https://www.qiushibaike.com/text/page/{}/'.format(str(i)) for i in range(1,36)] #构造urls 12 13 def re_scraper(url): #用正则爬虫 14 res = requests.get(url,headers=headers) 15 ids = re.findall('<h2>(.*?)</h2>',res.text,re.S) 16 contents = re.findall('<div class="content">.*?<span>(.*?)</span>',res.text,re.S) 17 laughs = re.findall('<span class="stats-vote"><i class = "number">(\d+)</i>',res.text,re.S) 18 comments = re.findall('<i class="number">(\d+)</i>评论',res.text,re.S) 19 for id,content,laugh,comment in zip(ids,contents,laughs,comments): 20 info = { 21 'id':id, 22 'content':content, 23 'laugh':laugh, 24 'comment':comment 25 } 26 return info #只返回数据,不存储 27 28 def bs_scraper(url): 29 res = requests.get(url,headers=headers) 30 soup = BeautifulSoup(res.text,'lxml') 31 ids = soup.select('a > h2') 32 contents = soup.select('div >span') 33 laughs = soup.select('span.stats-vote >i') 34 comments = soup.select('i.number') 35 for id,content,laugh,comment in zip(ids,contents,laughs,comments): 36 info = { 37 'id':id.get_text(), 38 'content':content.get_text(), 39 'laugh':laugh.get_text(), 40 'comment':comment.get_text() 41 } 42 return info 43 44 def lxml_scraper(url): #lxml爬虫 45 res = requests.get(url,headers=headers) 46 selector = etree.HTML(res.text) 47 url_infos = selector.xpath('//div[@class="article block untagged mb15 typs_hot"]') 48 try: 49 for url_info in url_infos: 50 id = url_info.xpath('div[1]/a[2]/h2/text()')[0] 51 content = url_info.xpath('a[1]/div/span/text()')[0] 52 laugh = url_info.xpath('div[2]/span[1]/i/text()')[0] 53 comment = url_info.xpath('div[2]/span[2]/a/i/text()')[0] 54 info = { 55 'id': id, 56 'content': content, 57 'laugh': laugh, 58 'comment': comment 59 } 60 return info 61 except IndexError: 62 pass 63 64 if __name__ == '__main__': 65 for name,scraper in [('Regular expressions',re_scraper),('BeautifulSoup',bs_scraper),('Lxml',lxml_scraper)]: 66 start = time.time() 67 for url in urls: 68 scraper(url) 69 end = time.time() 70 print(name,end-start)
程序运行结果如下图所示。

代码分析:
⑴第1~5行导入相应的库。
⑵第7~9行通过Chrome浏览器的开发者工具,复制User-Agent,用于伪装为浏览器,便于爬虫的稳定性。
⑶第11行构造所有URL。
⑷第13~62行定义3种爬虫方法函数。
⑸第64~70行为程序的入口,通过循环依次调用3种爬虫方法函数,记录开始时间,循环爬取数据,记录结束时间,最后打印出所需时间。
由于硬件条件的不同,执行的结果会存在一定的差异性。不过3种爬虫方法之间的相互差异性是相当的,下表中总结了每种爬虫方法的优缺点。
| 爬取方法 | 性能 | 使用难度 | 安装难度 |
| 正则表达式 | 快 | 困难 | 简单(内置模块) |
| BeautifulSoup | 慢 | 简单 | 简单 |
| Lxml | 快 | 简单 | 相对困难 |
当网页结构简单并且想要避免额外依赖的话(不需要安装库),使用正则表达式更为合适。当需要爬取的数据量较少时,使用较慢的BeautifulSoup也不成问题。当数据量大,需要追求效益时,Lxml是最好的选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号