


5.1.2 Lxml库的使用
1、修正HTML代码
Lxml为XML解析库,但也很好地支持了HTML文档的解析功能,这为使用Lxml库爬取网络信息提供了支持条件,如图所示。

这样就可以通过Lxml库来解析HTML文档了:
from lxml import etree text = ''' <div> <ul> <li class="red"><h1>red flowers</h1></li> <li class="yellow"><h2>yellow flowers item</h2></li> <li class="white"><h3>white flowers</h3></li> <li class="black"><h4>black flowers</h4></li> <li class="blue"><h5>blue flowers</h5></li> </ul> </div> ''' html = etree.HTML(text) print(html) #Lxml库解析数据,为Element对象
打印结果如下图所示。
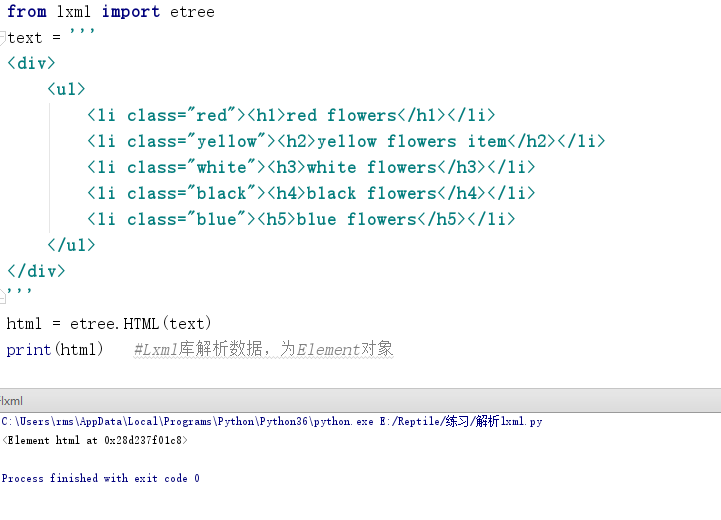
首先导入Lxml中的etree库,然后利用etree.HTML进行初始化,最后把结果打印出来。可以看出,etree库把HTML文档解析为Element对象,可以通过以下代码输出解析过的HTML文档。
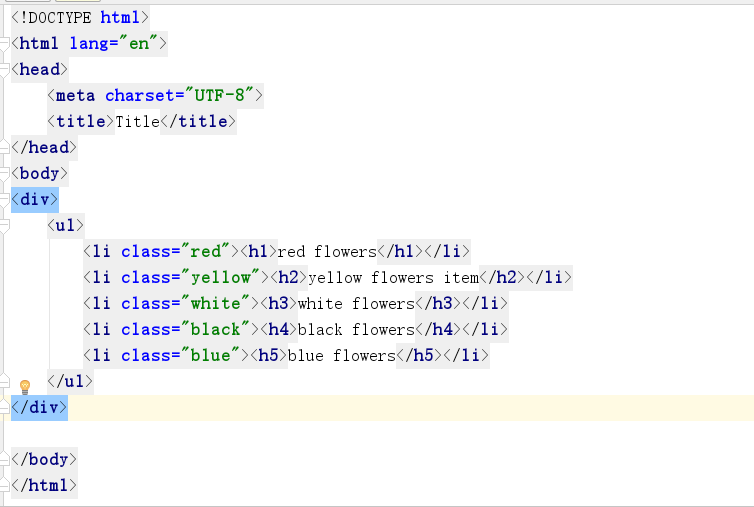
from lxml import etree text = ''' <div> <ul> <li class="red"><h1>red flowers</h1></li> <li class="yellow"><h2>yellow flowers item</h2></li> <li class="white"><h3>white flowers</h3></li> <li class="black"><h4>black flowers</h4></li> <li class="blue"><h5>blue flowers</h5></li> </ul> </div> ''' html = etree.HTML(text) result = etree.tostring(html) print(result) #Lxml库解析可自动修正HTML
打印结果如下图所示。
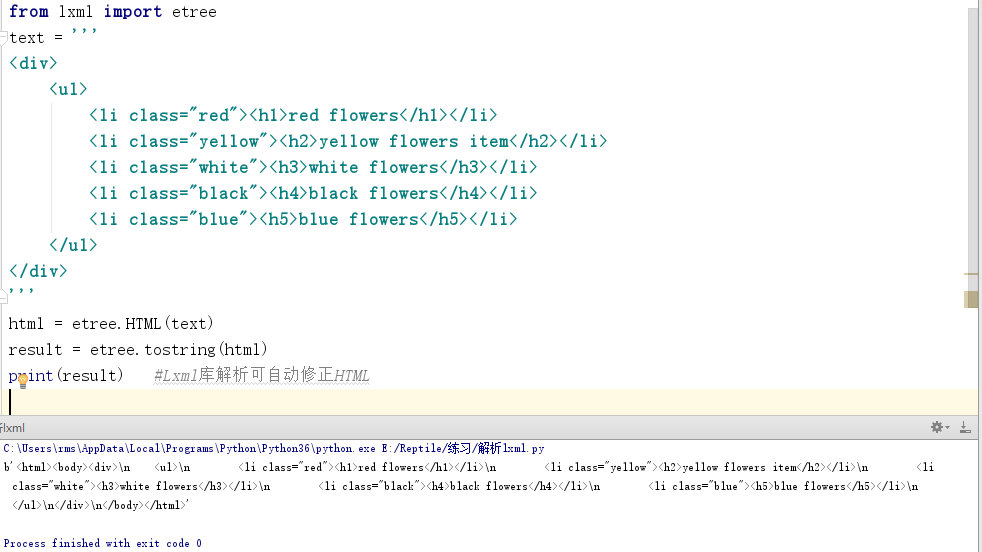
这里体现了Lxml库一个非常实用的功能就是自动修正HTML代码,读者应该注意到了最后一个li标签,其实笔者把尾标签删掉了,是不闭合的。不过,Lxml因为继承了libxml2的特性,具有自动修正HTML代码的功能,这里不仅补齐了li标签,而且还添加了html和body标签。
2、读取HTML标签
除了直接读取字符串,Lxml库还支持从文件中提取内容。我们可以通过PyCharm新建一个flower.html文件。在所需建立文件的位置右击,在弹出的快捷菜单中选择New|HTML File命令,如图所示。
新建好的HTML文件,已经自动生成了html、head和body标签,也可以通过单击PyCharm右上角的浏览器符号,在本地打开制作好的HTML文件,如图所示。
把前面的字符串复制在HTML文档中,如图所示。最后通过浏览器打开制作好的HTML文件,如下图所示。

注意:该HTML文件只能在本地打开。
这样便可通过Lxml库读取HTML文件中的内容了,可以通过下面的代码读取;
from lxml import etree html = etree.parse('flower.html') result = etree.tostring(html,pretty_print=True) print(result)
利用parse()方法,也可以得到相同的结果。
注意:HTML文件与代码文件在同一层时,用相对路径就可以进行读取,如果不在同一层,使用绝对路径即可。
3、解析HTML文件
完成了前面的步骤后,便可利用requests库获取HTML文件,用Lxml库来解析HTML文件了。
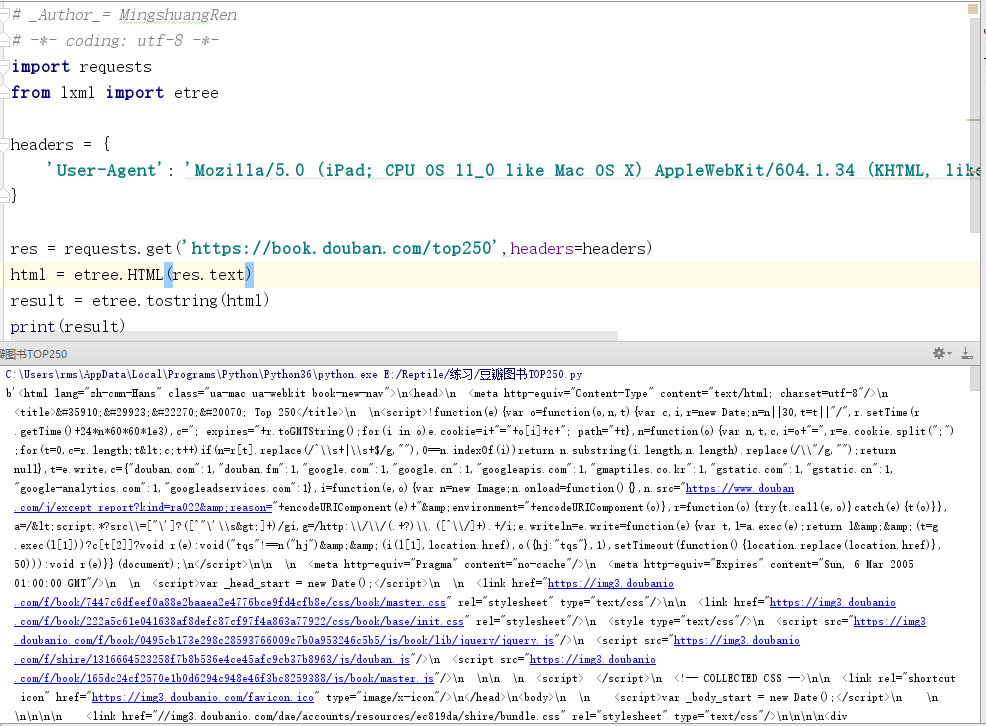
import requests from lxml import etree headers = { 'User-Agent': 'Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1' } res = requests.get('https://book.douban.com/top250',headers=headers) html = etree.HTML(res.text) result = etree.tostring(html) print(result)
注意:该网站为豆瓣图书TOP250第1页。
程序运行结果如下图所示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号