


4.3 综合案例1-------爬取《斗破苍芎》全文小说
本节将利用Requests库和正则表达式方法,爬取斗破苍穹小说网(http://www.doupoxs.com/doupocangqiong/)中该小说的全文信息,并把爬取的数据存储到本地文件中。
4.3.1 爬虫思路分析
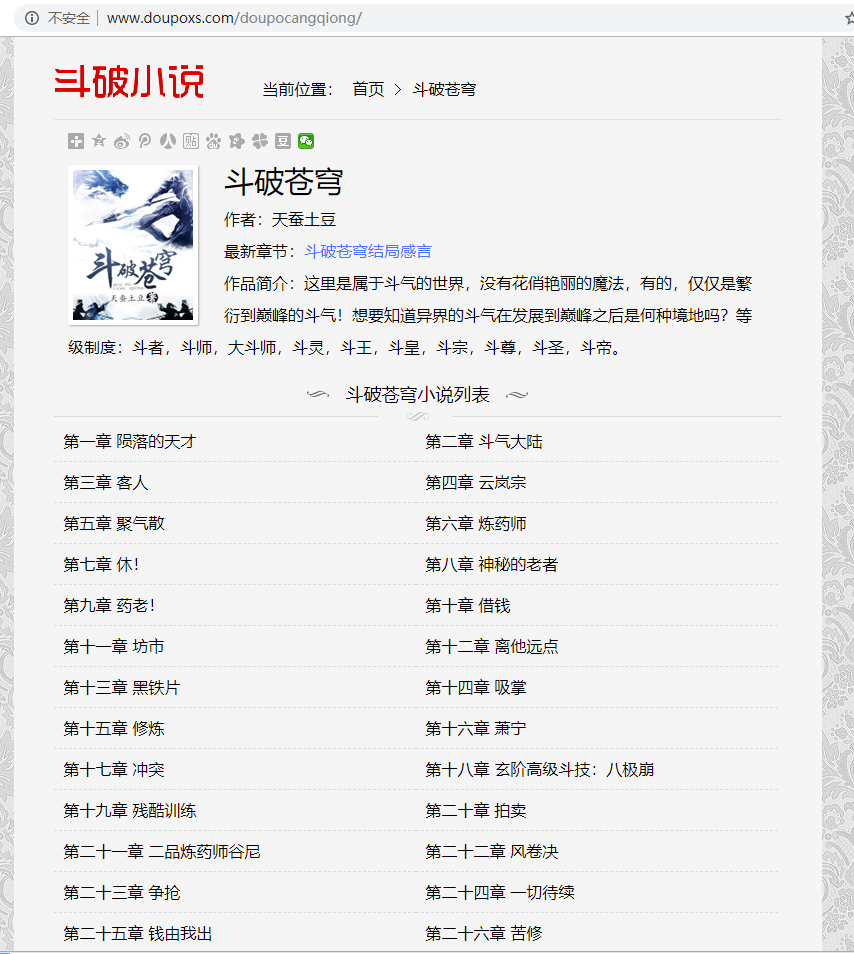
⑴本节爬取的内容为斗破苍芎小说网的全文小说,如图所示。
⑵爬取所有章节的信息,通过手动浏览,以下为前5章的网址:
http://www.doupoxs.com/doupocangqiong/1.html http://www.doupoxs.com/doupocangqiong/2.html http://www.doupoxs.com/doupocangqiong/3.html http://www.doupoxs.com/doupocangqiong/4.html http://www.doupoxs.com/doupocangqiong/5.html
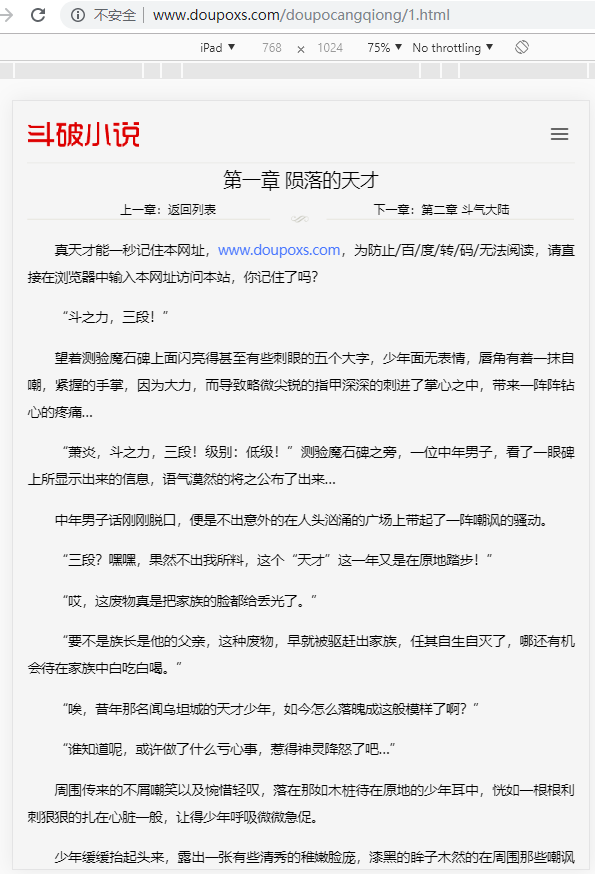
⑶需要爬取的信息为全文的文字信息,如图所示。
⑷运用python对文件的操作,把爬取的信息存储在本地TXT文本中。
4.3.2 爬虫代码及分析
1 import requests 2 import re 3 import time 4 5 headers = { 6 'User-Agent': 'Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1' 7 } #加入请求头 8 9 f = open('E:\data\doupo.txt','a+') #新建TXT文档,追加的方式 10 11 def get_info(url): #定义获取信息的函数 12 res = requests.get(url,headers=headers) 13 if res.status_code == 200: #判断请求码是否为200 14 contents = re.findall('<p>(.*?)</p>',res.content.decode('utf-8'),re.S) 15 for content in contents: 16 f.write(content+'\n') #正则获取数据写入TXT文件中 17 else: 18 pass #不为200就pass掉 19 20 if __name__ == '__main__': #程序主入口 21 urls = ['http://www.doupoxs.com/doupocangqiong/{}.html'.format(str(i)) for i in range(1,1665))] #构造多页URL 22 for url in urls: 23 get_info(url) #循环调用get_info()函数 24 time.sleep(1) #睡眠1秒 25 26 f.close() #关闭TXT文件
程序运行的结果保存在计算机,文件名为doupo的文档中,如下图所示。

代码分析:
⑴第1~3行导入程序需要的库,Requests库用于请求网页获取网页数据。运用正则表达式不需要用BeautifulSoup解析网页数据,而是使用Python中的re模块匹配正则表达式。time库的sleep()方法可以让程序暂停。
⑵第5~8行通过Chrome浏览器的开发者工具,复制User-Agent,用于伪装为浏览器,便于爬虫的稳定性。
⑶第10行新建TXT文档,用于存储小说的全文信息。
⑷第12~19行定义get_info()函数,用于获取网页信息并存储信息。传入YRL后,进行请求。通过正则表达式定位到小说的文本内容,并写入TXT文档中。
⑸第21~26行为程序的入口。通过对网页URL的观察,使用列表的推导式构造所有小说URL,并依次调用get_info()函数,time.sleep(1)的意思是没循环一次,让程序暂停1秒,防止请求网页频率过快而导致爬虫失败。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号