


4.1 正则表达式常用符号
4.1.1 一般字符
正则表达式的一般字符有3个,如下表所示。
| 字符 | 含义 |
| . | 匹配任意单个字符(不包括换行符\n) |
| \ | 转义字符(把有特殊含义的字符转换成字面意思) |
| [...] | 字符集。对应字符串集中的任意字符 |
说明:
⑴“.”字符为匹配任意单个字符。例如,a.b可以的匹配的结果为abc、aic、a&c等,但不包括换行符。
⑵“\”字符为转义字符,可以把字符改变为原来的意思。听上去不是很好理解,例如“.”字符是匹配任意的单个字符,但有时不需要这个功能,只想让它代表一个点,这时就可以使用“\.”,就能匹配为“.”了。
⑶[...]为字符集,相当于在中括号中任选一个。例如a[bcd],匹配的结果为ab、ac和ad。
4.1.2 预定义字符集
正则表达式预定义字符集有6个,如下表所示。
| 预定义字符集 | 含义 |
| \d | 匹配一个数字字符。等价于[0-9] |
| \D | 匹配一个非数字字符。等价于[^0-9] |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等。等价于[\f\n\r\t\v] |
| \S | 匹配任何非空白字符。等价于[^\f\n\r\t\v] |
| \w | 匹配包括下画线的任何单词字符。等价于'[A-Za-z0-9]' |
| \W | 匹配任何非单词字符。等价于'[^A-Za-z0-9]' |
正则表达式的预定义字符集易于理解,在爬虫实战中,常常会匹配数字而过滤掉文字部分的信息。例如“字数3450”,只需要数字信息,可以通过“\d+”来匹配数据,“+”为数量词,匹配前一个字符1或无限次,这样便可以匹配到所有的数字,数量词将在4.1.3节中详细讲解。
4.1.3 数量词
正则表达式中的数量词列表如表所示。
| 数量词 | 含义 |
| * | 匹配前一个字符0或无限次 |
| + | 匹配前一个字符1或无限次 |
| ? | 匹配前一个字符0或1次 |
| {m} | 匹配前一个字符m次 |
| {m,n} | 匹配前一个字符m至n次 |
说明:
⑴“*”数量词匹配前一个字符0或无限次。例如,ab*c匹配ac、abc、abbc和abbbc等。
⑵“+”与“*”很类似,只是至少匹配前一个字符一次。例如,ab+c匹配abc、abbc和abbbc等。
⑶“?”数量词匹配前一个字符0或1次。例如,ab?c匹配ac和abc。
⑷“{m}”数量词匹配前一个字符m次。例如,ab{3}c匹配abbbc。
⑸“{m,n}”数量词匹配前一个字符m至n次。例如,ab{1,3}c匹配abc、abbc和abbbc。
4.1.4 边界匹配
边界匹配的关键符号如下表所示。
| 边界匹配 | 含义 |
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
| \A | 仅匹配字符串开头 |
| \Z | 仅匹配字符串结尾 |
说明:
⑴“^”匹配字符串的开头。例如,^abc匹配abc开头的字符串。
⑵“$”匹配字符串的结尾。例如,abc$匹配abc结尾的字符串。
⑶“\A”匹配字符串的开头。例如,\Aabc
⑷“\Z”匹配字符串的结尾。例如,abc\Z
边界匹配在爬虫实战中的使用比较少,因为爬虫提取的数据大部分为标签中的数据,例如<span class="stats-vote"><i class="number">186</i>好笑</span>中提取数字信息,边界匹配在这里没有任何作用。
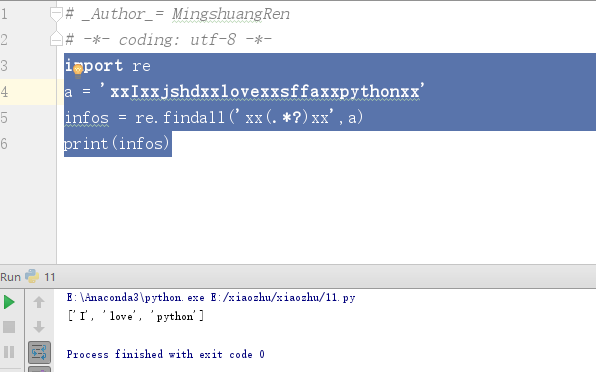
最后介绍爬虫实战中常用的(.*?),“()”表示括号的内容作为返回结果,“.*?”是非贪心算法,匹配任意的字符。例如,字符串‘xxIxxjshdxxlovexxsffaxxpythonxx’,可以通过'xx(.*?)xx'匹配符合这种规则的字符串,代码如下:
import re a = 'xxIxxjshdxxlovexxsffaxxpythonxx' infos = re.findall('xx(.*?)xx',a) #findall方法返回的为列表结构 print(infos)
程序运行结果如图所示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号