


2.1爬虫原理
现实生活中使用浏览器访问网页时,网络到底做了什么?本节将简单地介绍网络连接原理,并以此介绍爬虫原理。
2.1.1 网络连接
网络连接像是自助饮料售货机上购买饮料一样:购买者只需选择所需饮料,投入硬币(或纸币),自助饮料售货机就会弹出相应的商品。如图所示,计算机(购买者)带着请求头和消息体(硬币和所需饮料)向服务器(自助饮料售货机)发起一次Request请求(购买),相应的服务器(自动饮料售货机)会返回计算机相应的HTML文件作为Response(相应的商品)。
注意:这里是一个GET请求。

对于学习爬虫技术,读者只需知道最基本的网络连接原理即可。计算一次Request请求和服务器端的Response回应,即实现了网络连接。计算机Request请求带着的请求头和消息体是什么以及网络更底层的东西,不是本文所介绍的范围。
2.1.2 爬虫原理
了解网络连接的基本原理后,爬虫原理就很好理解了。网络连接需要计算机一次Request请求和服务器端的Response回应。爬虫也是需要做两件事:
⑴模拟计算机对服务器发起Request请求。
⑵接收服务器端的Response内容并解析、提取所需的信息。
但互联网网页错综复杂。一次的请求和回应不能够批量获取网页的数据,这时就需要设计爬虫的流程。本书中主要用到两种爬虫所需的流程,即多页面和跨页面爬虫流程。
1、多页面爬虫流程
多页面网页结构如图所示。

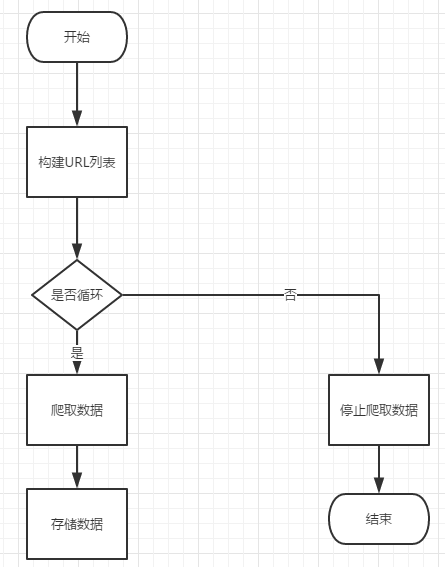
有的网页存在多页的情况,每页的网页结构都相同或类似,这种类型的网页爬虫流程为:
⑴手动翻页并观察各网页的URL构成特点,构造出所有页面的URL存入列表中。
⑵根据URL列表依次循环取出URL。
⑶定义爬虫函数。
⑷循环调用爬虫函数,存储数据。
⑸循环完毕,结束爬虫程序,如图所示。
2、跨页面爬虫流程
列表页和详细页分别如图所示。


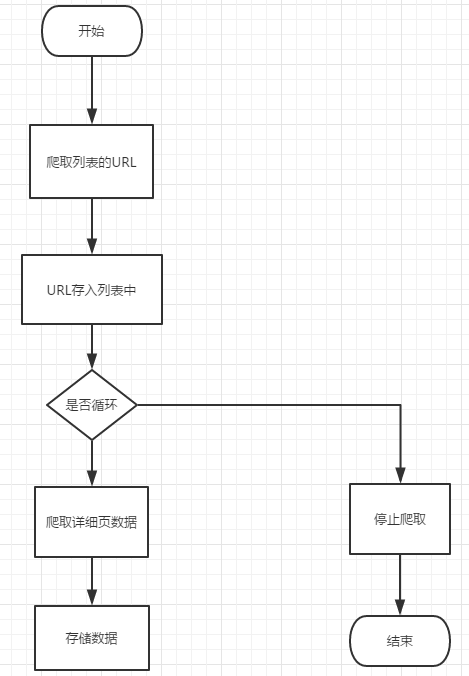
这种跨页面的爬虫程序流程为:
⑴定义爬取函数爬取列表页的所有专题的URL。
⑵将专题URL存入列表中(种子URL)。
⑶定义爬取详细页数据函数。
⑷进入专题详细页面爬取详细页数据。
⑸存储数据,循环完毕,结束爬虫程序,如图所示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号