


4.3 构建类目树
首先获取出发地站点,输入以下代码。
import requests url = 'https://touch.dujia.qunar.com/depCities.qunar' strhtml = requests.get(url) dep_dict = strhtml.json() for dep_item in dep_dict['data']: for dep in dep_dict['data'][dep_item]: print(dep)
代码运行结果如图所示。
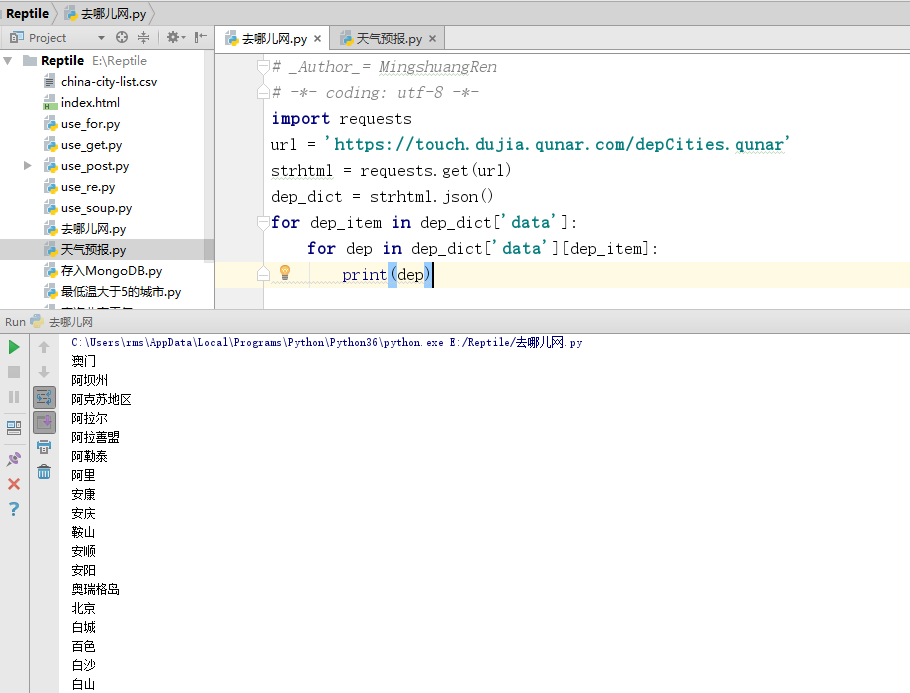
然后根据出发地站点获取目的地,继续输入以下代码。
import requests import urllib import time url = 'https://touch.dujia.qunar.com/depCities.qunar' strhtml = requests.get(url) dep_dict = strhtml.json() for dep_item in dep_dict['data']: for dep in dep_dict['data'][dep_item]: print(dep) url = 'https://touch.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep)) time.sleep(1) strhtml = requests.get(url) arrive_dict = strhtml.json() for arr_item in arrive_dict['data']: for arr_item_1 in arr_item['subModules']: for query in arr_item_1['items']: print(query['query'])
代码运行结果如图所示。
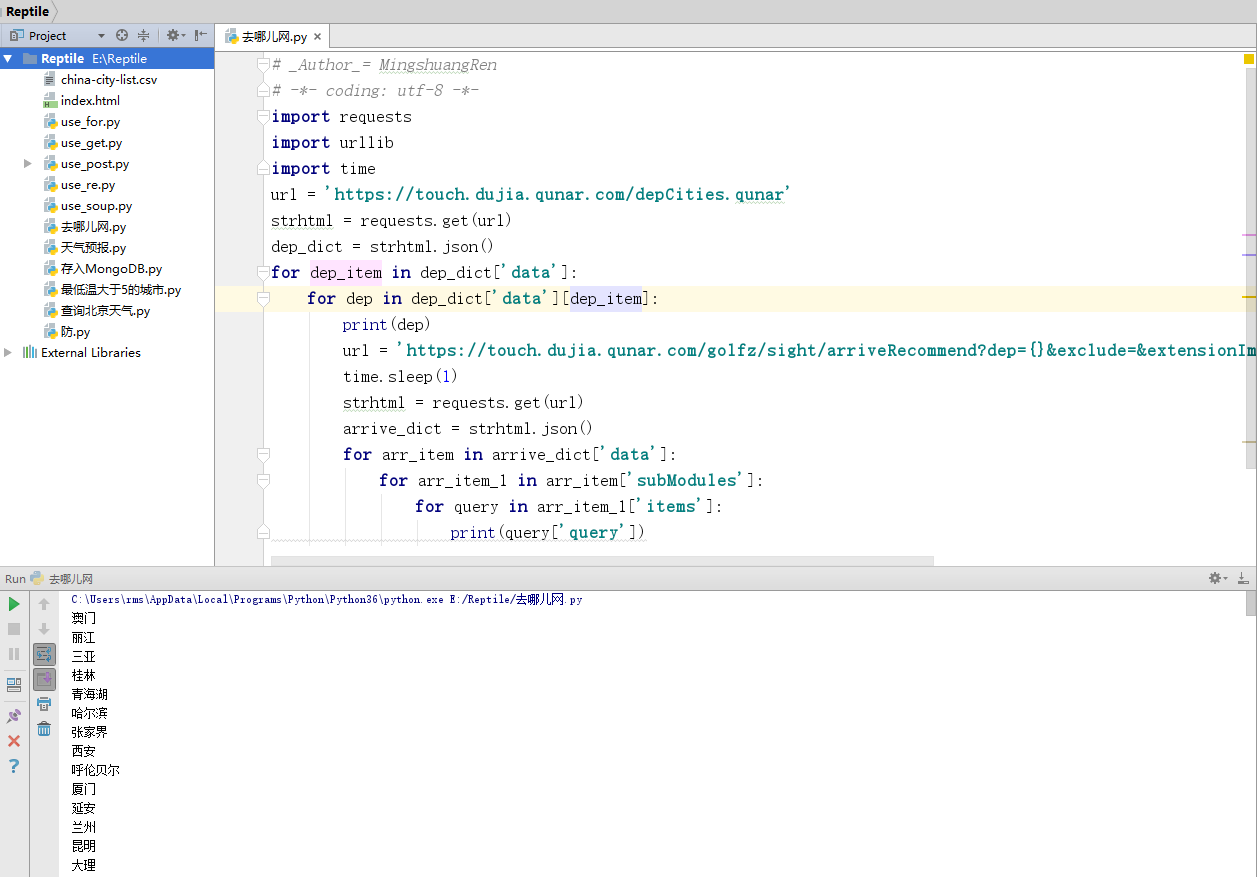
通过观察打印结果,发现目的地有多个重复项(在网页上也可以发现),如果基于这个有重复项的类目树获取数据,会造成资源浪费,因此要先对目的地进行去重。接下来在上一段代码中补充去重的代码。
import requests import urllib import time url = 'https://touch.dujia.qunar.com/depCities.qunar' strhtml = requests.get(url) dep_dict = strhtml.json() for dep_item in dep_dict['data']: for dep in dep_dict['data'][dep_item]: a = [] #新增去重代码 print(dep) url = 'https://touch.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep)) time.sleep(1) strhtml = requests.get(url) arrive_dict = strhtml.json() for arr_item in arrive_dict['data']: for arr_item_1 in arr_item['subModules']: for query in arr_item_1['items']: if query['query'] not in a: #新增去重代码 a.append(query['query']) #新增去重代码 print(a)
代码运行结果如图所示。
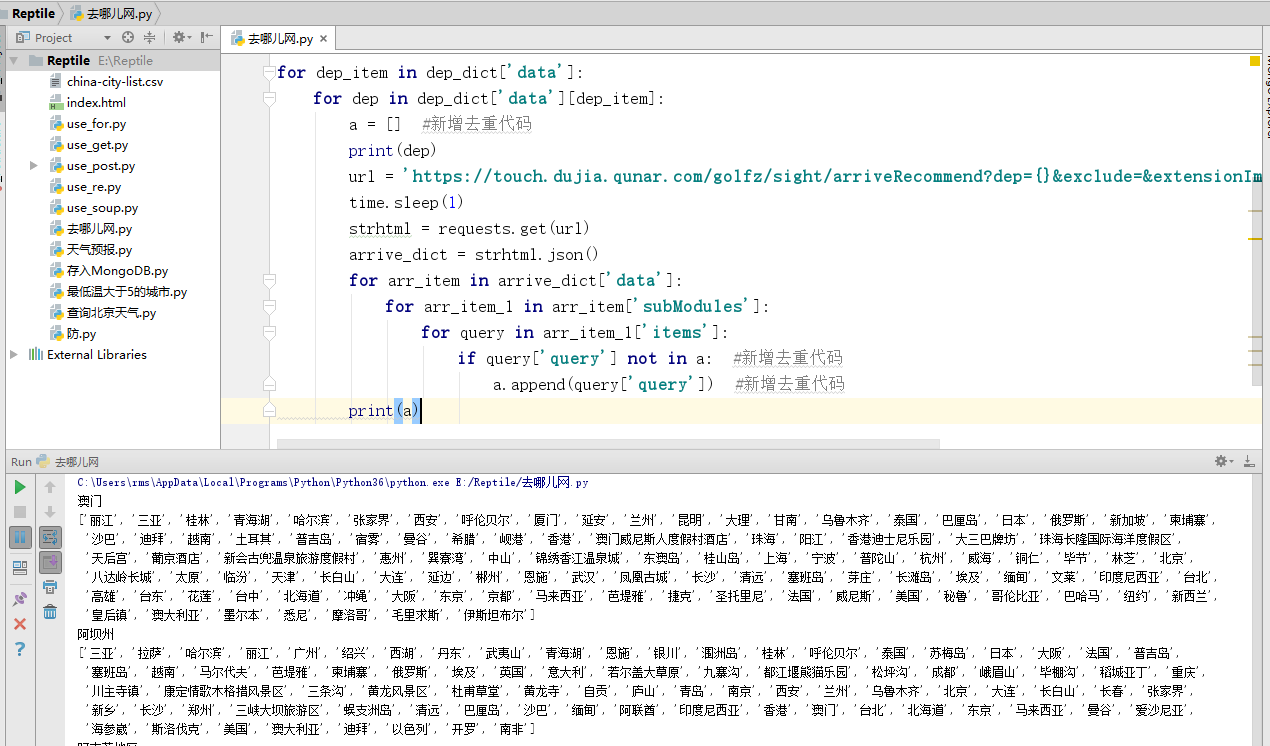
由于去重针对的是每个出发地站点下的目的地,因此需要在获取出发地站点的位置定义一个空的列表a,每一次循环都会重置a。
最后判断目的地是否在列表a中,如果没有就用append(合并)方法将目的地加入到列表a中,代码如下。
if query['query'] not in a: a.append(query['query'])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号