


3.4.1 新写文章标题列表
我们的任务很明确,要实现向访问网站的用户展示作者及其文章的功能,如下图所示。
前面已经编写过文章标题列表,这里要“新”写(不是“重写”),肯定与前面的不同。不过,基本逻辑还是一样的,不同之处在于展示效果。
首先要编写的是视图函数,这次要新建一个编写视图函数的文件./article/list_views.py,这样做的目的主要是让读者理解视图函数的文件不一定都是views.py,然后创建一个展示文章标题的视图函数article_titles(),其代码如下。
1 from django.shortcuts import render 2 from django.core.paginator import Paginator,EmptyPage,PageNotAnInteger 3 from .models import ArticleColumn,ArticlePost 4 5 def article_titles(request): 6 article_title = ArticlePost.objects.all() 7 paginator = Paginator(article_title,2) 8 page = request.GET.get('page') 9 try: 10 current_page = paginator.page(page) 11 articles = current_page.object_list 12 except PageNotAnInteger: 13 current_page = paginator.page(1) 14 articles = current_page.object_list 15 except EmptyPage: 16 current_page = paginator.page(paginator.num_pages) 17 articles = current_page.object_list 18 return render(request,"article/list/article_titles.html",{"articles":articles,"page":current_page})
下面配置本应用的URL,就是创建./article/urls.py文件,并输入如下代码。
1 from . import views,list_view #① 2 3 path('list-article-titles/',list_view.article_titles,name="article_titles"),
因为视图函数article_titles()在list_views.py文件中,所以要通过语句①引入list_views。
接下来是编写前端模板文件。在./templates/article目录中创建list目录,在创建article_titles.html模板文件,即./templates/article/list/article_titles.html,其代码如下。
1 {% extends "base.html"} 2 {% block title %} articles {% endblock %} 3 {% block content %} 4 <div class="row text-center vertical-middle-sm"> 5 <h1>阅读,丰富头脑,善化行为</h1> 6 </div> 7 <div class="container"> 8 {% for article in articles %} 9 <div class="list-group"> 10 <a href="#" class="list-group-item active"> 11 <h4 class="list-group-item-heading">{{article.title}}</h4> 12 <p class="list-group-item-text">作者:{{article.author.uesrname}}</p> #① 13 <p class="list-group-item-text">概要:{{article.body|slice:'70'|linebreaks}}</p> #② 14 </a> 15 </div> 16 {% endfor %} 17 {% include "paginator.html" %} #③ 18 </div> 19 {% endblock %}
语句①中的变量用于得到该文章作者的用户名。在./article/models.py中我们定义了ArticlePost数据模型类,其中属性author = models.ForeignKey(User,related_name="article"),所以就能够以{{article.author.username}}方式得到用户名。
语句②中的{{article.body}}用于显示该文章对象的所有文章内容,但是后面用管道符“|”对显示的内容做了限制(有一种常见的说法叫做“过滤器”),“slice:'70'”的含义是将前面的变量所导入的内容“切下”前70个字符。“slice”是根据字符数量来截取部分内容的,与之类似的还有一个truncatewords,读者不妨将语句②中的变量更换为{{article.body|truncatewords:'70'|linebreaks}},看看有什么效果。slice是“切下”一定数量的字符,从内容的开头计算,只要是一个字符就算一个,空格也算一个字符;而truncatewords则是截取一定数量的words(单词),在英语中words之间用空格分割,所以它会根据空格进行截取,但是遇到中文就麻烦了,中文怒用空格分开各个词语,除非分段的地方。所以,如果读者按照笔者所说的更换了,就会看到对中文基本没有截取(读者的文章估计没有70个段落)。为了测试出上面说的效果,读者不仅要发布几篇英文文章,也要发布几篇中文文章。
语句②中还有一个过滤器linebreaks,其意义从名字上可以推断一下。读者可以把它删除,看一下效果。linebreaks的作用是允许原文中的换行HTML标记符继续产生效用。
语句③是很熟悉的内容,将前面已经写好的分页模板引入。
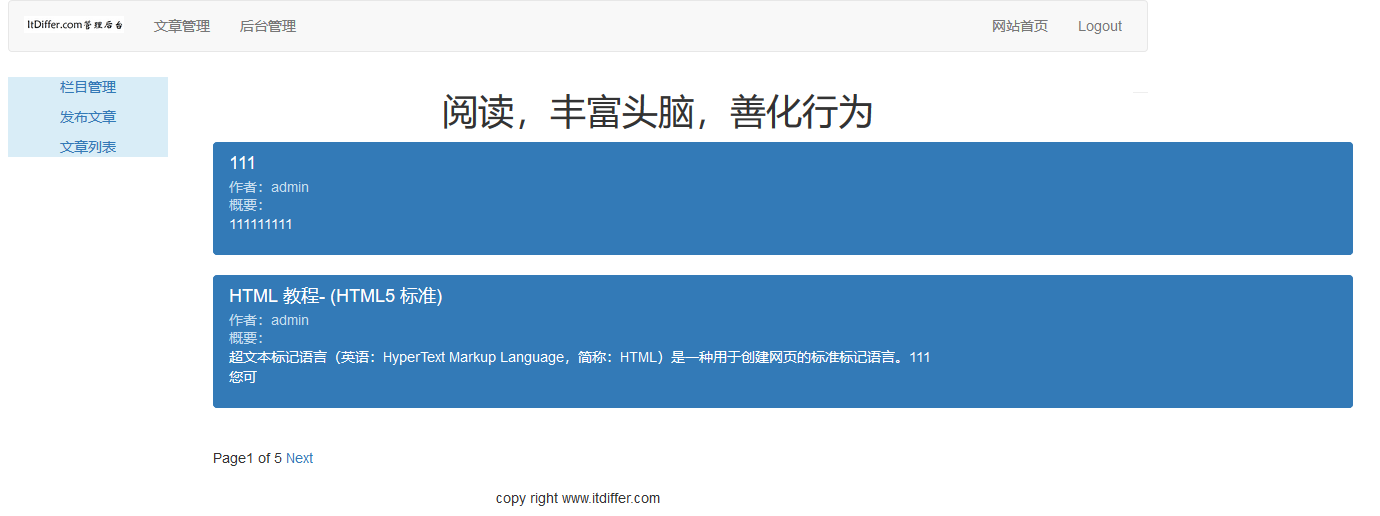
检查Django服务是否已经启动,在浏览器的地址栏中输入http://127.0.0.1:8000/article/list-article-titles/地址,不管用户是否登录,都能看到如下图所示的效果。
列表完成后,下面要查看文章内容。
其实前面编写过查看文章内容的功能,在./article/views.py文件中增加如下视图函数(不要忘记在文件顶部引入get_object_or_404)
1 def article_detail(request,id,slug): 2 article = get_object_or_404(ArticlePost,id=id,slug=slug) 3 return render(request, "article/list/article_detail.html", {"article": article})
上述代码中的click_article_detail()函数与以往不同,它不检查用户是否处于登录状态。
在.article/urls.py文件中增加如下URL配置代码。
1 re_path('list-article-detail/(?P<article_id>\d+)/(?P<slug>[-\w]+)/$',list_view.article_detail,name="list_article_detail"), 2 ]
在urls.py文件中,将上面的URL和前面已经有的URL配置re_path('list-article-detail/(?P<article_id>\d+)/(?P<slug>[-\w]+)/$',list_view.article_detail,name="list_article_detail")进行对比,虽然都有article_detail()函数,但因为在不同模块(views/list_views)中,所以两个函数互不影响,但是name的值要区分开,在同一个URL配置文件中不要出现相同的name。
在./templates/article/list中创建模板文件article_detail.html,下面的代码和./templates/article/column里面的article_detail.html一样,不过这仅仅是在本节。
1 {% extends "article/base.html" %} 2 {% load staticfiles %} 3 {% block title %}article list{% endblock %} 4 {% block content %} 5 <div> 6 <header> 7 <h1>{{ article.title }}</h1> 8 <p>{{user.username }}</p> 9 </header> 10 11 <link rel="stylesheet" href='{% static "editor/css/editormd.preview.css" %}' /> 12 <div id="editormd-view"> 13 <textarea id="append-test" style="display:none;"> 14 {{ article.body }} 15 </textarea> 16 </div> 17 18 </div> 19 <script src="{% static 'js/jquery-3.3.1.js' %}"></script> 20 <script src="{% static 'editor/lib/marked.min.js' %}"></script> 21 <script src="{% static 'editor/lib/prettify.min.js' %}"></script> 22 <script src="{% static 'editor/lib/raphael.min.js' %}"></script> 23 <script src="{% static 'editor/lib/underscore.js' %}"></script> 24 <script src="{% static 'editor/lib/sequence-diagram.min.js' %}"></script> 25 <script src="{% static 'editor/lib/flowchart.min.js' %}"></script> 26 <script src="{% static 'editor/lib/jquery.flowchart.min.js' %}"></script> 27 <script src="{% static 'editor/editormd.js' %}"></script> 28 29 <script type="text/javascript"> 30 $(function(){ 31 editormd.markdownToHTML("editormd-view",{ 32 htmlDecode:"style,script,iframe", // you can filter decode 33 emoji:true, 34 taskList:true, 35 tex:true, //默认不解析 36 flowChart:true, //默认不解析 37 sequenceDiagram:true, //默认不解析 38 }); 39 }); 40 </script> 41 {% endblock %}
再编辑./templates/article/list/article_titles.html模板文件,在文章标题外面的<a>标签中增加超链接对象,代码如下。
1 <a href="{{article.get_absolute_url}}" class="list-group-item active"
如果现在处于登录状态,请退出,否则测试不到下述现象。对于浏览文章,我们约定任何人都可以。
刷新http://127.0.0.1:8000/article/list-article-titles/页面,把鼠标指针移到文章标题上,先不要单击,看浏览器底端,一般会有对象地址,显示的超链接地址是不是预想的那个呢?是的。但是当你单击鼠标的时候,就出问题了,如下图所示。
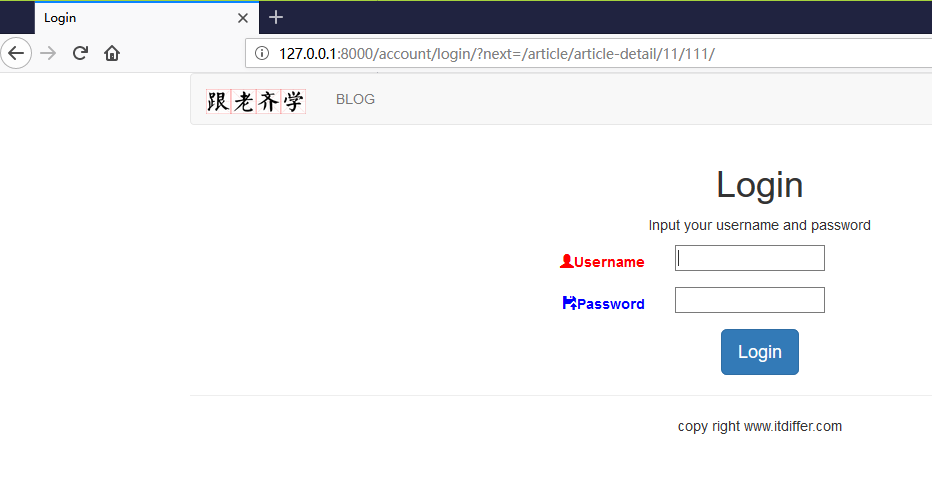
单击后自动跳转到登录页面,程序要求我们必须登录。这是什么原因?
虽然我们没有在视图函数中要求登录,但是因为使用了{{article.get_absolute_url}},而深藏在./article/models.py中的ArticlePost类的get_absolute_url()方法中有reverse("article:article_detail",args=[self.id,self.slug]),"article_detail"要求用户必须是登录状态(本质是views.article_detail要求用户登录才能执行),并且路径也与我们设置的路径不同。显然,不能照抄了。
3.4.2 重新编写“查看文章”功能
直接套用时遇到了问题,问题的关键在于不能再使用{{article.get_absolute_url}}。
如何修改呢?
问题的根源是ArticlePost类中的get_absolute_url()方法,那么就可以弃之不用,再写一个方法。将如下方法追加到./article/models.py中的ArticlePost类中。
1 def get_url_path(self): 2 return reverse("article:list_article_detail",args=[self.id,self.slug]) #①
语句①的写法和return reverse("article:list_article_detail",args=[self.id,self.slug])的效果是一样的,只不过语句①不再需要用户登录,这就是前面URL配置中的name不采用同一个名字的用途。
然后将./article/list/article_titles.html中的超链接修改为:
1 <a href="{{article.get_url_path}}" class="list-group-item active">
刷新文章列表页面后,单击文章标题,测试是否能够查看文章内容,如下图所示。
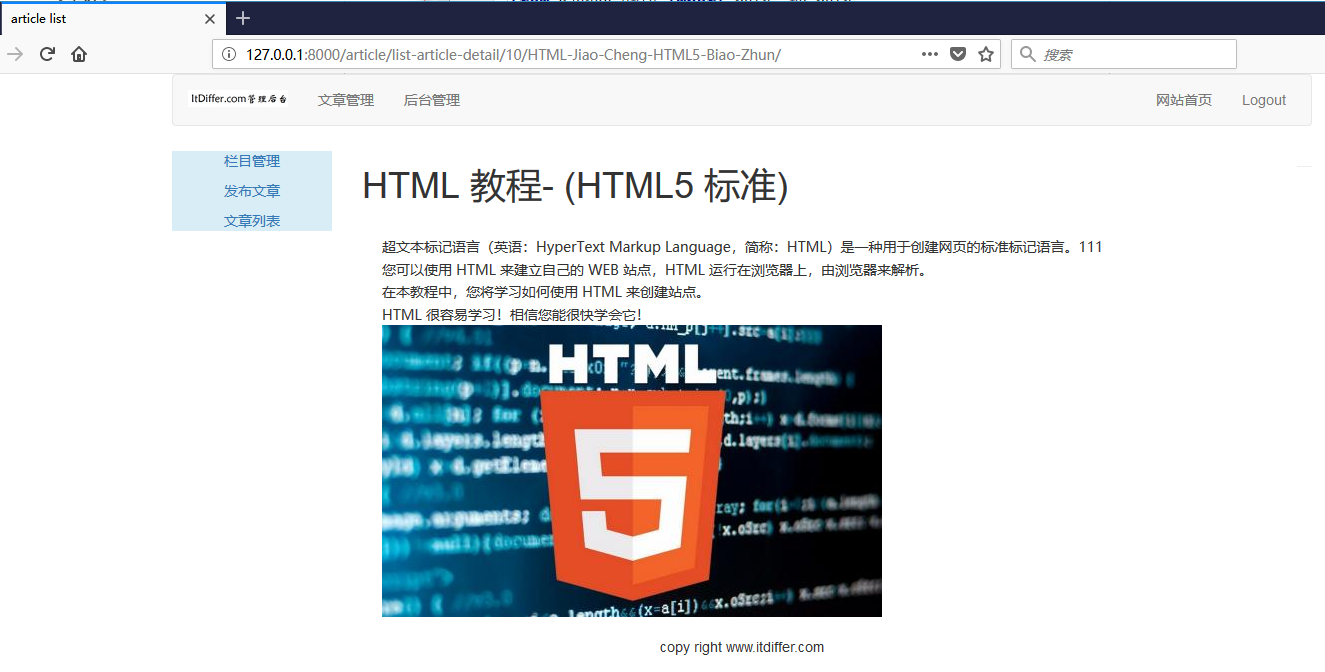
完美显示。
貌似到这里就已经能够实现所有功能了。但是,这种方法其实存在一个隐患。早文章的URL中,我们使用的是数据库自增的id,这就是隐患,如果因为某种原因,自增id发生了变化,比如合并数据库表(可能是低概率,就怕万一),这时候再按照原来的URL访问,就不能找到那篇文章了。就一般情况而言,网上发布的文章,应该具有一个永久的URL,所以,应该给每篇文章增加一个单独的固定id(或者别的标识),通过这个固定的id(标识)访问该文章。
3.4.3 知识点
1、模板:过滤器
Django模板中的过滤器,常常根据需要在模板中显示变量形式时使用。其基本样式是{{value|filter}},其中filter是过滤器。Django模板提供了多种针对变量数值的过滤器。
- capfirst,将变量的第一个字符转换为大写,如果第一个字符不是字母则过滤器失败。例如{{ value|capfirst }},如果value是“django”,则输出“Django”。
- cut,移除变量中的字符。例如{{ value|cut:"" }},如果value是“learn django”,则输出“learndjango”。
- date,根据指定的格式输出时间。例如 {{ value|date:"D d M Y" }},如果value是datetime对象的实例(比如常用的datetime.datetime.now()),则输出类似于“Web 09 Jan 2008”样式的字符串。官方文档中列出了各种格式字符的说明。
- join,使用字符链接列表元素,其效果类似Python中的str.join(list).例如{{ value|join:"//""}},如果value是['a','b','c'],则会输出“a//b//c”
以上内容是根据官方文档的说明整理出来的,在官方文档中还有很多。
这些都是内置的过滤器,在某些时候还需要自定义。本书后面的项目也会演示如何自定义一个过滤器。
2、表单:表单类
在模板中,由<form></form>组成表单,里面是一个一个的<input>,这个表单通过<form>规定的方式提交到Django的视图部分,通常使用POST或者GET方式。本书中的项目都使用了POST。视图得到提交来的表单数据之后,在处理这些表单数据时,可以使用一个与数据模型(Model)类相似的类,即Form(表单)类。当然,不用也可以,但用了更简洁。
表单类也是一个普通的Python类,这个类里面定义了一些变量(类的属性),这些变量分别对应着HTML中的<input>。我们知道,在<input>中有不同的类型,从而规定是文本输入框还是按钮等。在表单类,也是通过类似在数据模型类中声明字段类型的方式,规定了变量的类型。
1 from django import forms 2 class LoginForm(forms.Form): 3 username = forms.CharField() 4 password = forms.CharField(widget=forms.PasswordInput)
通过前面的编程实践,我们已经认识到,数据模型类中的字段及其类型、表单类中的变量及其类型、模板中的<input>及其类型,都是一一对应的,否则数据无法正确保存。因此,如果没有特别需要,在表单类中乐意直接使用内部类class Meta声明与数据模型类中对应的变量。
例如:
1 class UserInfoForm(forms.ModelForm): 2 class Meta: 3 model = UserInfo 4 fields = ("school","company","profession","address","aboutme","photo")
在内部类Meta中,以model=UserInfo说明表单中各个字段的来源,然后用fields变量说明在本表单类中用到的字段,如果选择所有字段,则可以使用fields="__all__",还可以使用exclude=["school"]的方式排除某些字段。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号