
sql题,选出每门科目前三名的学生
一、常见数据库
关系型数据库:Oracle、DB2、SQLServer、MySQL
非关系型数据库:MongoDB
创建成绩表并插入数据:
create table StuScore(StuId int,Subject nvarchar(10),Score float); insert into StuScore values(1,'语文',70); insert into StuScore values(1,'数学',60); insert into StuScore values(1,'英语',90); insert into StuScore values(2,'语文',78); insert into StuScore values(2,'数学',67); insert into StuScore values(2,'英语',80); insert into StuScore values(3,'语文',89); insert into StuScore values(3,'数学',60); insert into StuScore values(3,'英语',97); insert into StuScore values(4,'语文',50); insert into StuScore values(4,'数学',67); insert into StuScore values(4,'英语',70); insert into StuScore values(5,'语文',79); insert into StuScore values(5,'数学',65); insert into StuScore values(5,'英语',79); insert into StuScore values(6,'语文',74); insert into StuScore values(6,'数学',56); insert into StuScore values(6,'英语',87);
二、Oracle完成
用oracle的语言比较简洁,目前在 MSSQLServer、Oracle、DB2 等主流数据库中都提供了对开窗函数的支持,不过 MYSQL 暂时还未对开窗函数给予支持。
1、开窗函数
与聚合函数一样,开窗函数也是对行集组进行聚合计算,但是它不像普通聚合函数那样每组只返回一个值,开窗函数可以为每组返回多个值,因为开窗函数所执行聚合计算的行集组是窗口。
开窗函数格式: 函数名(列) OVER(选项)
OVER 关键字后的括号中还经常添加选项用以改变进行聚合运算的窗口范围。如果 OVER 关键字后的括号中的选项为空,则开窗函数会对结果集中的所有行进行聚合运算。
例子:
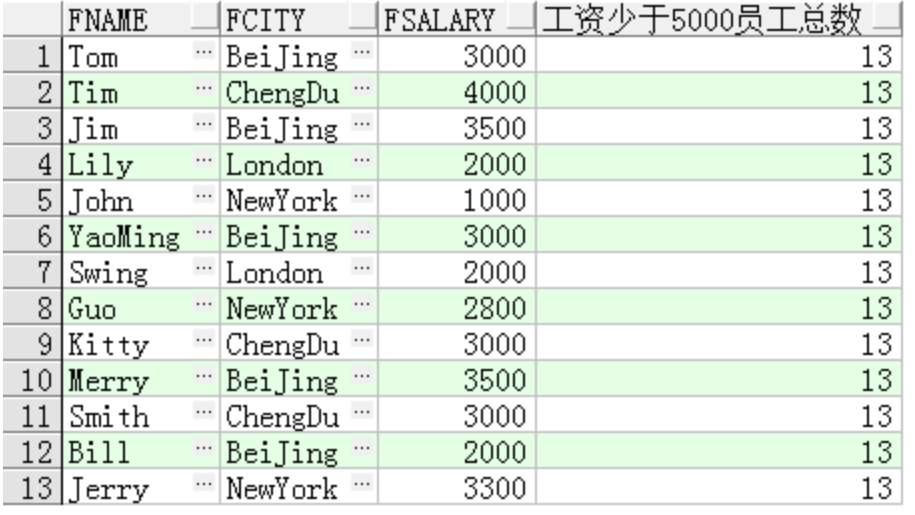
select fname, fcity, fsalary, count(*) over() 工资小于5000员工数
from t_person
where fsalary < 5000
返回所有满足工资小于5000的记录,通过聚合函数count计算这些记录的个数。
如果用MySQL实现就比较麻烦:
select fname, fcity,fsalary,
(select count(*) from t_person where fsalary < 5000) 工资少于5000员工总数
from t_person
where fsalary < 5000;
结果如下:
2、partition by
开窗函数的 OVER 关键字后括号中的可以使用 PARTITION BY 子句来定义行的分区来供进行聚合计算。类似于GROUP BY,但与 GROUP BY 子句不同是,PARTITION BY 子句创建的分区是独立于结果集的,创建的分区只是供进行聚合计算的,而且不同的开窗函数所创建的分区也不互相影响。即使用Partiton by字句定义行的分区或组,可以用paritition by对定义的行组计算聚集(当遇到新组的时候复位),并返回每个值(每个组中的每个成员),而不是一个用一个组表示表中的这个值的所有实例。下面这个例子具体的展现了它的作用:
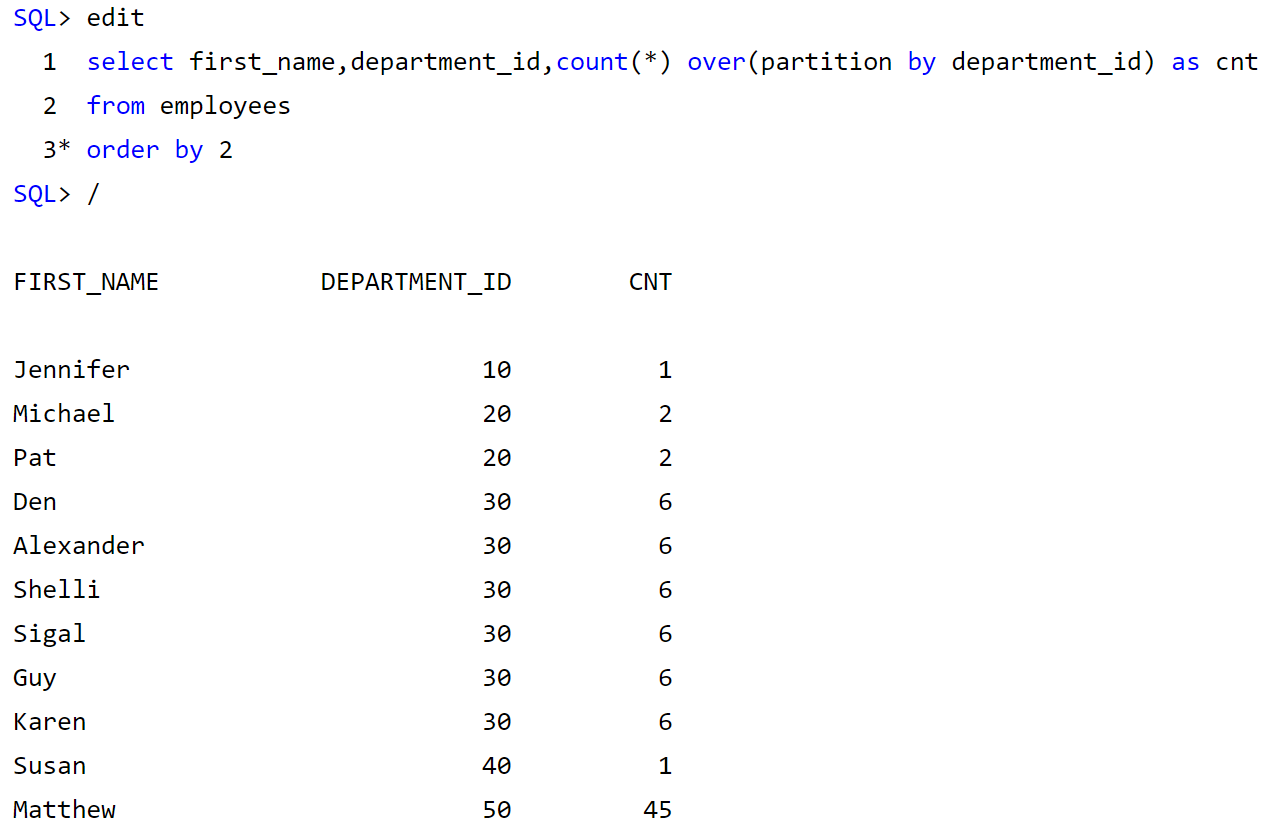
注意:原表中的每一行都会返回,并得出他对应分组后的聚合计算值。
3、row_number()
除了可以在开窗函数中使用COUNT()、SUM()、MIN()、MAX()、AVG()等这些聚合函数,还可以在开窗函数中使用一些高级的函数,有些函数同时被DB2和Oracle同时支持,比如RANK()、DENSE_RANK()、ROW_NUMBER(),而有些函数只被Oracle支持,比如RATIO_TO_REPORT()、NTILE()、LEAD()、LAG()、FIRST_VALUE()、LAST_VALUE()。
row_number():从1开始,为每一条分组记录返回一个数字,返回的主要是“行”的信息,并没有排名
语法:ROW_NUMBER() OVER (PARTITION BY COL1 ORDER BY COL2)
功能:表示根据COL1分组,在分组内部根据 COL2排序,而这个值就表示每组内部排序后的顺序编号(组内连续的唯一的)
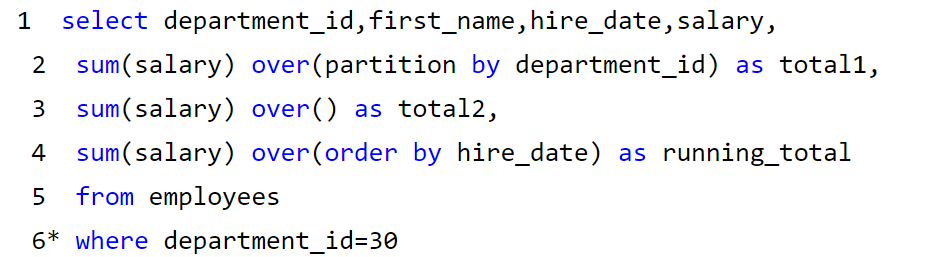
4、order by
下面这个例子很好的说明了order by 在窗口函数中的作用:
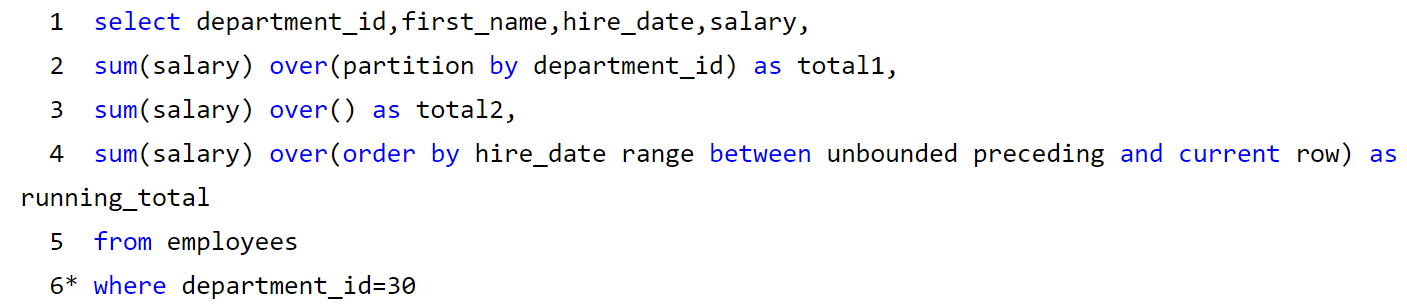
等价于:

5、解决问题
语法:
select * from
(select *,row_number() over(partition by Subject order by Score desc) rn
from StuScore)
where rn<4;
按照科目分区,将每个科目按照成绩从大到小排序并给出顺序号(不同科目顺序重新从1开始),在这个结果集上取每个科目前三个。
注意:where筛选在新结果集上进行的,以下语句是错误的:
select * from
(select *,row_number() over(partition by Subject order by Score desc) rn
from StuScore
where rn<4);
因为在子查询中,根据语句执行顺序,先执行where筛选,在进行字段选择、聚合函数选择,因此还未执行row_number() over(partition by Subject order by Score desc) rn就出现rn进行筛选,是有误的。
补充子查询:
• 出现在select子句中:将子查询返回结果作为主查询的一个字段或者计算值(标量子查询、列子查询)
• 出现在where/having子句中:将子查询返回的结果作为主查询的条件(标量子查询、行子查询、列子查询、表子查询)
• 出现在from或join子句中:将子查询返回的结果作为主查询的一个表(标量子查询、行子查询、列子查询、表子查询)
备注:子查询必须添加表别名,如果需要引用表子查询中的计算字段,必须添加列别名才可以引用
三、MySQL实现
由于MySQL是没有开窗函数等函数,因此比较复杂。
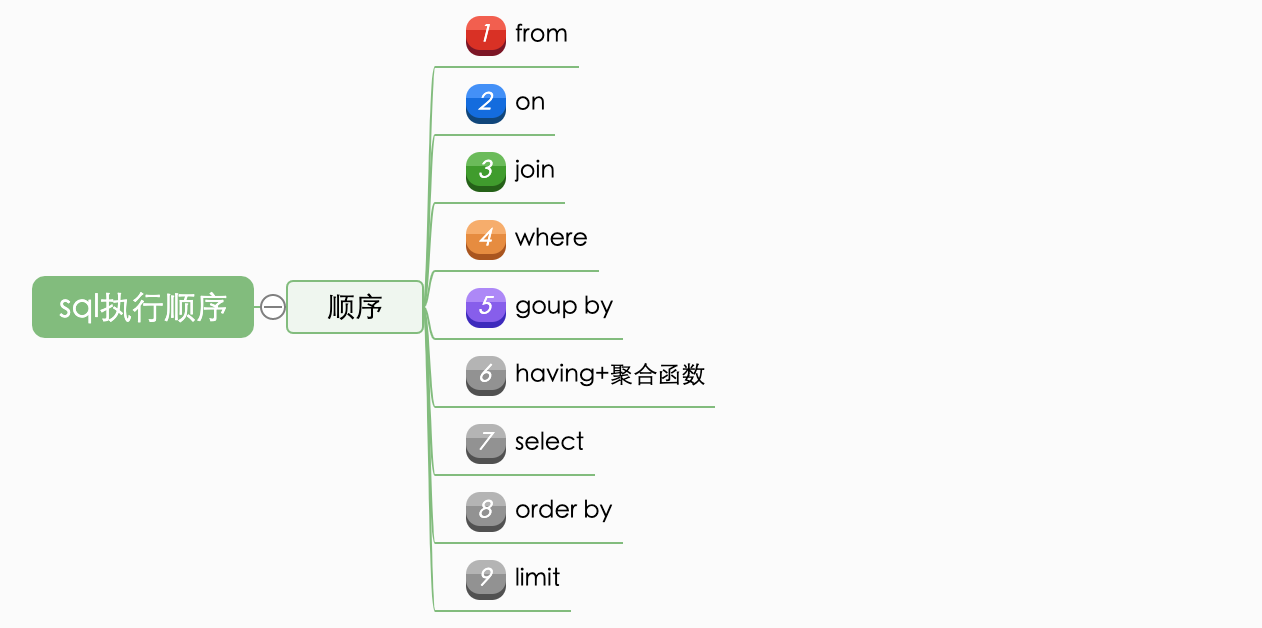
语法:
SELECT *
FROM StuScore s
WHERE EXISTS(SELECT COUNT(*) FROM StuScore ss WHERE ss.Score>=s.Score and ss.Subject=s.Subject GROUP BY ss.Subject HAVING COUNT(*)<=3)
ORDER BY Subject,Score DESC;
子查询思路如下:
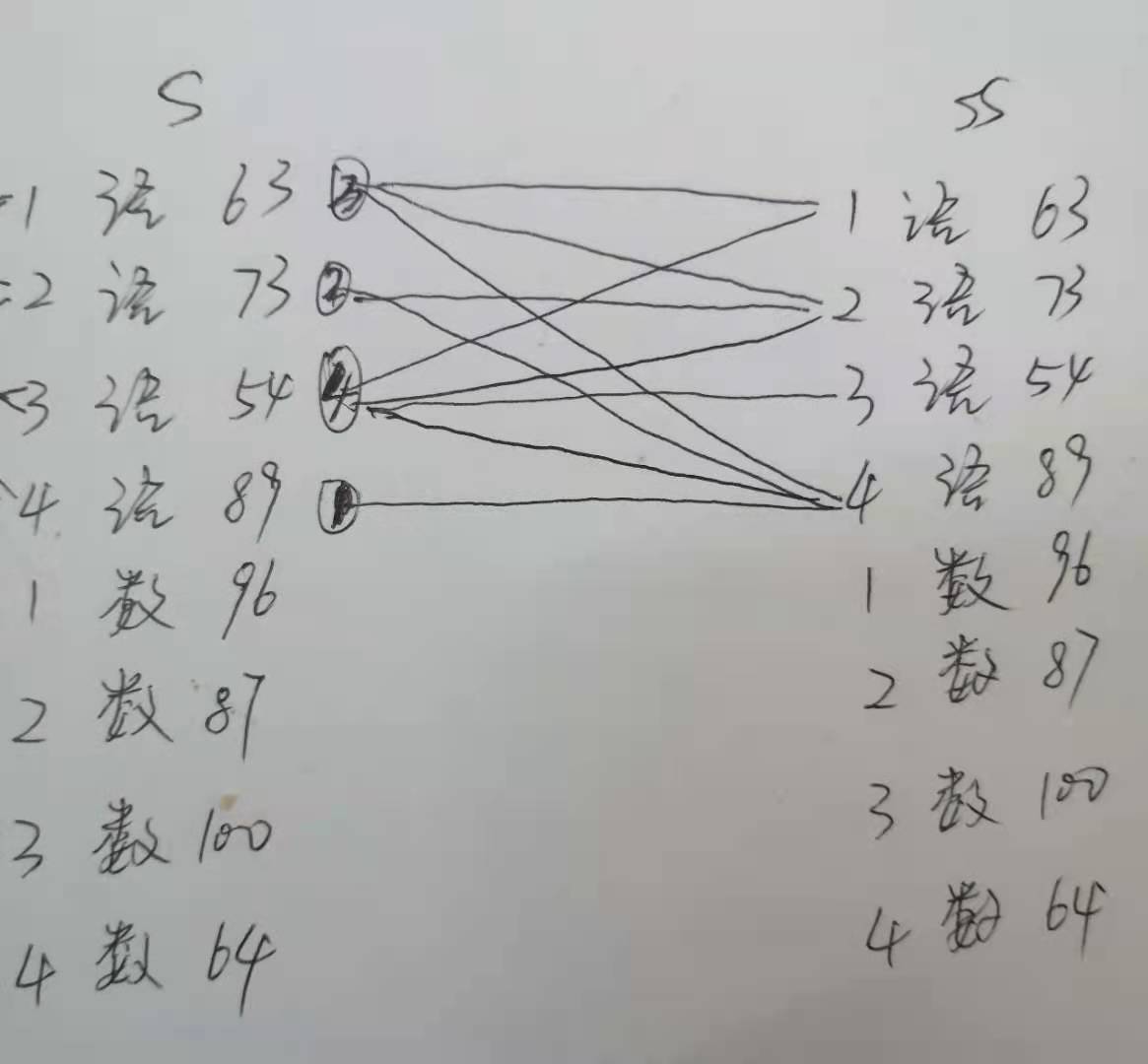
s表和ss表是同一张表,将得到的结果按照科目(主排序关键字)、成绩(次排序关键字)
补充order by:
(1)多字段排序是按照一个字段一个字段进行,先安排第一个字段排序,如果第一个字段一样,才利用第二个字段进行排序。如下图:
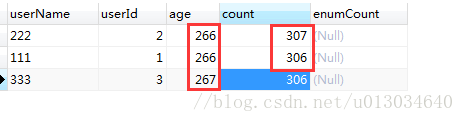
(2)order by code,name desc不等同于order by code asc, name desc
实际上MySQL会先以code进行降序排序,在code进行降序排序的基础上,再使用name进行降序排序
(3)如果想不同字段不同排序标准,需要在每个字段后面加上排序准则,如:order by code asc, name desc
MySQL就会先以code进行升序排序,在code进行升序排序的基础上,再使用name进行降序排序
详细学习版参见:
https://blog.csdn.net/mfkpie/article/details/16364513
https://www.cnblogs.com/lihaoyang/p/6756956.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号