

MySQL03:事务和索引
事务
事务执行基本要素(ACID)
原子性(Atomicity):事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生
一致性(Consistency):事务前后数据的完整性必须保持一致
隔离性(Isolation):数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离
持久性(Durability):事务一旦被提交,它对数据库中数据的改变就是永久性的,即使数据库发生故障也不应该对其有任何影响
事务隔离
不隔离导致的问题
脏读:一个事务读取了另外一个事务未提交的数据
不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同(这个不一定是错误,只是某些场合不对)
虚读(幻读):在一个事务内读取到了别的事务插入的数据,导致前后读取数量总量不一致
手动提交事务
MySQL默认开启了事务自动提交
CREATE DATABASE `shop`;
USE `shop`;
CREATE TABLE `account`(
`id` INT(3) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) NOT NULL,
`money` DECIMAL(9, 2) NOT NULL,
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
INSERT INTO `account`(`name`, `money`) VALUES ('A', 2000), ('B', 1000);
SET autocommit = 0; -- 关闭事务自动提交
START TRANSACTION; -- 手动开启事务
UPDATE `account` SET `money` = `money` - 500 WHERE `name` = 'A';
UPDATE `account` SET `money` = `money` + 500 WHERE `name` = 'B';
COMMIT; -- 提交
ROLLBACK; -- 回滚
SET autocommit = 1; -- 开启事务自动提交
SAVEPOINT 保存点名; -- 设置事务还原点
ROLLBACK TO SAVEPOINT 保存点名; -- 回滚还原点
RELEASE SAVEPOINT 保存点名; -- 删除还原点
事务隔离级别
SELECT @@tx_isolation; -- 查询当前事务隔离级别
SET TRANSACTION ISOLATION LEVEL 级别; -- 设置事务隔离级别
| 隔离级别 | 描述 |
|---|---|
| Serializable | 可避免脏读、不可重复读、虚读情况的发生(串行化) |
| Repeatable read | 可避免脏读、不可重复读情况的发生(可重复读) |
| Read committed | 可避免脏读情况发生(读已提交) |
| Read uncommitted | 最低级别,以上情况均无法保证(读未提交) |
索引
索引是帮助MySQL高效获取数据的数据结构,可以大大加快数据的查询速度,但创建和维护索引组要耗费时间,因此索引不是越多越好
索引原理
在数据库查询中,减少磁盘访问时数据库的性能优化的主要手段
为什么索引能提升数据库查询效率呢?根本原因就在于索引减少了查询过程中读写磁盘的IO次数
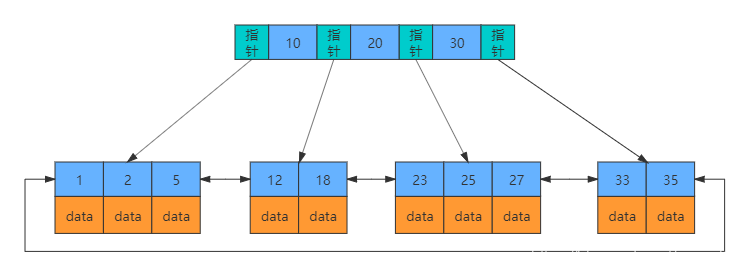
那么它是如何做到的呢?使用B+树
B+树
B树每个节点中不仅包含数据的key值,还有data值;要保存同样多的key,就需要增加树的高度;树的高度每增加一层,查询时的磁盘I/O次数就增加一次,进而影响查询效率
而B+树的数据只出现在叶子节点,且叶子节点增加了一个链指针可以相互访问,与B树相比,大大增加了每个节点存储的key值数量,降低了树的高度
为什么不用红黑树:磁盘存取依赖局部性原理与磁盘预读,但红黑树因为自旋转,逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的效率明显比B-Tree差很多
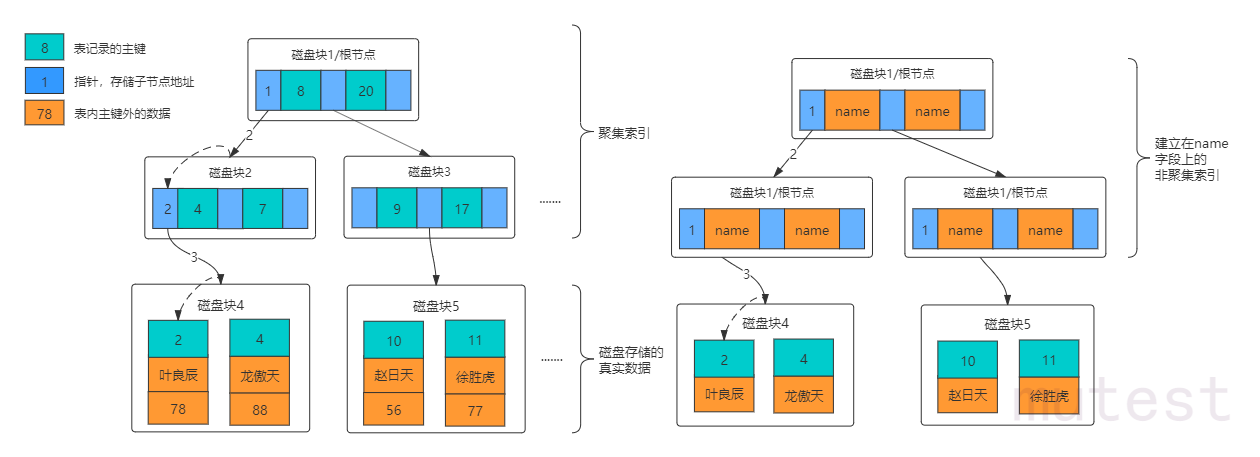
聚集索引与非聚集索引
聚集索引(InnoDB):
- 索引数值和物理地址是保持一致顺序的,索引较大的行,其物理地址也比较靠后
- 与非聚集索引相比,有着更快的检索速度,但当表发生数据增删改时,索引树也要相应修改,导致开销更大一些
- 建立条件:
- 在InnoDB中,聚集索引默认就是主键索引
- 如果表中没有定义主键,那么该表的第一个唯一非空索引被作为聚集索引
- 如果没有主键也没有合适的唯一索引,那么InnoDB内部会生成一个隐藏的主键作为聚集索引
非聚集索引(MyISAM):
非聚集索引叶子节点上存储的是索引字段自身值和主键索引
回表二次查询:使用聚集索引查询可以直接定位到记录,而非聚集索引需要扫描两遍索引树,即先通过非聚集索引定位到主键值,再通过聚集索引定
位到目标值,性能比聚集索引低
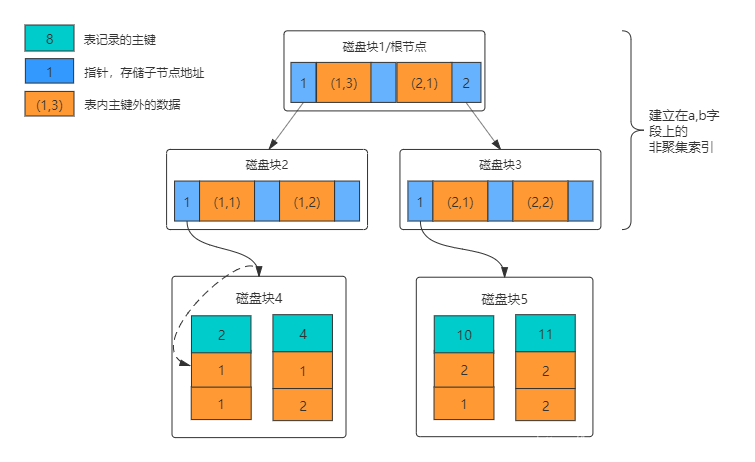
联合索引(多列索引/复合索引/组合索引)
非聚集索引会导致回表二次查询,解决方法是建立联合索引,该索引指向多个字段,但是B+树只能根据一个字段来构建,因此依据最左边的字段来构建B+树
最左匹配原则:因为联合索引是依据最左边的字段来构建的,因此查询时必须要先查左边的字段,才能查剩下的字段,左边字段称为右边字段的前导列
索引分类
主键索引(PRIMARY KEY)
唯一标识、只能存在一个
不允许值重复或者值为空
唯一索引(UNIQUE KEY)
唯一标识、可存在多个不同的唯一索引
创建唯一性索引的目的不是为了提高访问速度,而是为了避免数据出现重复,但允许有空值
全文索引(FULLTEXT KEY)
用来查找文本中的关键字,只能在 CHAR、VARCHAR 或 TEXT类型的列上创建,允许插入重复值和空值
普通索引(KEY)
没有任何限制,唯一目的就是加快系统对数据的访问速度,在定义索引的列中可以插入重复值和空值
索引的创建
SHOW INDEX FROM `account`; -- 显示所有的索引信息
CREATE TABLE 表名 (字段名 字段类型 [,...], 索引类型(字段名 [,...])); -- 在创建表的同时创建
CREATE 索引类型 索引名 ON 表名 (字段名 [,...]) -- 在已有的表上创建索引,但该语句不能创建主键
ALTER TABLE 表名 ADD 索引类型 索引名(字段名 [,...]); -- 在已有的表上创建索引
索引原则
1、索引不是越多越好
2、不要对经常变动的的数据加索引
3、小数据量的表不需要加索引
4、索引一般加在经常要被查询的字段上
索引的失效
1、WHERE条件包含多字段,但其中有字段没有索引时,不会使用索引
2、联合索引中违反最左匹配原则,不会使用索引
3、查询条件不是等值或范围查询时,更倾向于全表扫描而不会使用索引
4、范围查询可以用到索引(必须是最左前缀),但是范围查询后面的查询无法用到索引
5、使用OR条件时,除非每个字段都有索引,否则不会使用索引
6、模糊查找时,如果通配符%在字符串最前面,会导致索引失效而进行全表查找
7、在字段名上进行计算或者使用函数,会导致索引失效
MySQL优化
EXPLAIN
EXPLAIN命令模拟优化器执行SQL语句,从而知道MySQL是如何处理SQL语句,分析查询语句和表结构的性能瓶颈
作用:可以看到表的读取顺序、数据读取操作的操作类型、哪些索引可以使用、哪些索引被实际使用、表之间的引用、每张表有多少行被优化器查询
EXPLAIN SELECT * FROM 表名; -- 在SQL语句前面加上EXPLAIN即可
常用结果分析
| 字段 | 释义 |
|---|---|
| id | 按SELECT语句出现的顺序增长,值越大执行优先级越高,值相同则从上往下执行,值为 NULL 最后执行 |
| select_type | 表示查询类型,如简单查询(SIMPLE)、复杂查询(PRIMARY)、子查询(SUBQUERY)等 |
| type | 表示关联类型或访问类型,如根据主键索引(system、const)、唯一或普通索引(ref)、范围查找(range)、全表查找(index) |
| key | 实际使用的索引 |
| rows | 大致估算出找到所需的记录所需要读取的行数 |
| Extra | 额外信息,如索引覆盖(Using index)、前导列(Using index condition)、回表(NULL)、WHERE过滤(Using where)等 |
索引选择性与前缀索引优化
索引选择性指不重复的索引值与表记录数的比值,比值越大则索引价值越大
前缀索引优化:用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销
前缀索引兼顾索引大小和查询速度,但是其缺点是不能用于ORDER BY和GROUP BY操作
主键选择与插入优化
尽量在InnoDB上采用自增字段做主键
如果表使用自增主键,那么每次插入新的记录,会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页,形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上
如果使用非自增主键(如身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页中间的某个位置,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片
百万级数据库测试
-- 创建表
CREATE TABLE `app_user`(
`id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) DEFAULT '' COMMENT '用户昵称',
`email` VARCHAR(50) NOT NULL COMMENT '用户邮箱',
`phone` VARCHAR(20) DEFAULT '' COMMENT '手机号',
`gender` TINYINT(4) UNSIGNED DEFAULT '0' COMMENT '性别(0:男;1:女)',
`password` VARCHAR(100) NOT NULL COMMENT '密码',
`age` TINYINT(4) DEFAULT '0' COMMENT '年龄',
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8mb4 COMMENT='app用户表';
-- 定义函数,插入100万条数据
DELIMITER $$
CREATE FUNCTION mock_data()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i < num DO
INSERT INTO `app_user`(`name`, `email`, `phone`, `gender`, `password`, `age`)
VALUES (CONCAT('用户名', i), '123456789@qq.com', CONCAT('18', FLOOR(RAND() * ((999999999-100000000) + 100000000))),
FLOOR(RAND() * 2), UUID(), FLOOR(RAND() * 2) * 100);
SET i = i + 1;
END WHILE;
RETURN i;
END;
-- 执行函数
SELECT mock_data();
-- 测试没有索引时查询时间
SELECT * FROM `app_user` WHERE `name`='用户名10000'; -- 0.901 sec
EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户名10000'; -- type:ALL,rows:992168
-- 测试有索引时查询时间
CREATE INDEX `id_app_user_name` ON `app_user`(`name`); -- 创建索引
SELECT * FROM `app_user` WHERE `name`='用户名10000'; -- 0.010 sec
EXPLAIN SELECT * FROM `app_user` WHERE `name`='用户名10000'; -- type:ref,rows:1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号