

Java IO流02:文件字节流和缓冲字节流
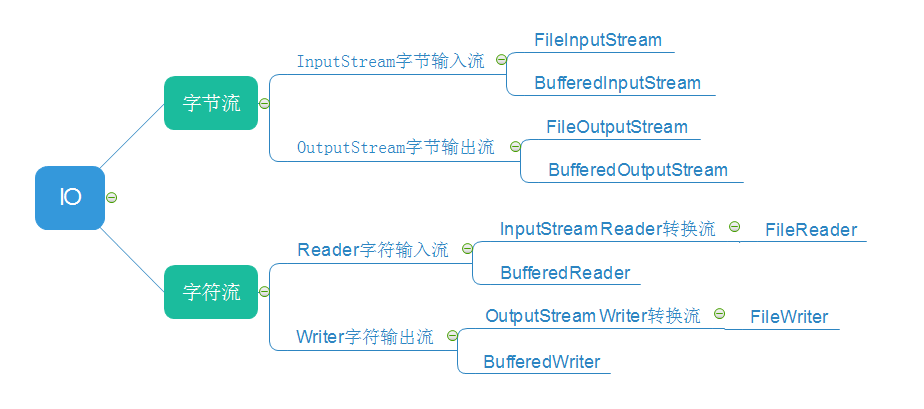
文件字节流
FileInputStream子类
文件字节输入流,继承抽象父类字节输入流(InputStream)
read(byte[])方法一次读取多个字节,将读到的内容存入字节数组(存的是ASCII码,如果有中文字符,数组长度需大于等于3),返回实际读到的字节个数;如果读完了就返回-1
import java.io.FileInputStream;
public class Main{
/**
* 使用IO流必须抛出异常
*/
public static void main(String[] args) throws Exception {
/**
* 创建FileInputStream对象,指定要读取的文件,内容为”中bdfsfg“
*/
FileInputStream f1 = new FileInputStream("d:\\in.txt");
FileInputStream f2 = new FileInputStream("d:\\in.txt");
/**
* 要用int类型来接收byte类型的ASCII码,原因见后
*/
int data;
/**
* 1、read()方法一次只能读取一个字节,返回值为ASCII码(0~255),当返回-1说明已读取完毕
* 输出为“ä¸-bdfsfg”,因为”中“占3个字节,所以只能被拆成三个不相干的字符
*/
while ((data = f1.read()) != -1){
System.out.print((char) data);
}
System.out.println();
/**
* 2、read(byte[])方法一次能读取多个字节,返回值为每次读到的字节个数
* 需要创建一个存放结果的字节数组,长度就是每次想要读取的字节个数,数组存放的也是ASCII码
* 注意最后一次的返回值可能会小于数组长度,可以用count变量来记录每次取得的长度
*/
byte[] arr = new byte[3];
int count;
while ((count = f2.read(arr))!= -1) {
/**
* 输出为“中bdfsfg”,即数组长度至少大于等于3才能完整读出汉字(如果汉字不是刚好在一个字节数组中的话,也会乱码,因此最好是使用字符流传输汉字)
* 如果最后一次读取的长度不足length,则数组后面的内容没有被覆盖会和上一次一样,因此用count指定长度避免数据紊乱
*/
System.out.println(new String (arr, 0, count));
}
/**
* 读取完以后要关闭
*/
f1.close();
f2.close();
}
}
拓展:read()方法返回值为什么是int而不是byte?
在计算机中,正数用原码表示,负数用补码表示。单字节的1的原码是00000001,-1的原码是10000001(符号位取反),-1的反码是11111110(除符号位都取反),-1的补码就是11111111(反码加1)。
如果在读字节的时候遇到111111111,那么这11111111是byte类型的-1,程序遇到-1就会停止,后面的数据就读不到了。所以在读取的时候用int类型接收,这样会在11111111前面补上24个0凑足4个字节,那么byte类型的-1就变成int类型的255了,这样可以保证整个数据读完,而结束标记的-1就是int类型。
FileOutputStream子类
文件字节输出流,继承抽象父类字节输出流(OutputStream)
write(byte[])方法一次写入字节数组中存放的多个字节
import java.io.FileOutputStream;
public class Main{
public static void main(String[] args) throws Exception {
/**
* 创建FileOutputStream对象,指定要写入的文件
* 默认是覆盖写入,加参数true则是追加写入
*/
FileOutputStream out = new FileOutputStream("d:\\out.txt", true);
/**
* 1、write()方法一次只能写入一个字节,传入数字默认会转换为ASCII码,超出一个字节的字符只会写入第一个字节
*/
out.write(397);
out.write('a');
out.write('中');
/**
* 2、write(byte[])方法一次能写入多个字节
* getBytes()方法将字符串转换为字节数组
*/
String str = "Mainworld";
byte[] by = str.getBytes();
out.write(by);
out.close();
}
}
练习:复制文件
import java.io.FileInputStream;
import java.io.FileOutputStream;
public class Main{
public static void main(String[] args) throws Exception {
FileInputStream in = new FileInputStream("d:\\in.pdf");
FileOutputStream out = new FileOutputStream("d:\\out.pdf");
byte[] arr = new byte[1024];
while ((in.read(arr)) != -1){
out.write(arr);
}
in.close();
out.close();
}
}
缓冲字节流(增强文件字节流)
BufferedInputStream子类
缓冲字节输入流,继承抽象父类过滤输入流(FilterInputStream)
以其他字节输入流作为参数,先将数据存储在缓冲区中(8K),提高IO效率,减少访问磁盘的次数
虽然有缓冲区,但是read()方法还是只能读取一个字节
import java.io.BufferedInputStream;
import java.io.FileInputStream;
public class Main{
public static void main(String[] args) throws Exception {
FileInputStream f1 = new FileInputStream("d:\\in.txt");
FileInputStream f2 = new FileInputStream("d:\\in.txt");
/**
* BufferedInputStream创建对象之前,要先创建一个字节输入流,将其作为参数
*/
BufferedInputStream buffer1 = new BufferedInputStream(f1);
BufferedInputStream buffer2 = new BufferedInputStream(f2);
int data;
/**
* BufferedInputStream默认创建了缓冲区,大小为8K
* 但是read()方法还是只能读取一个字节
*/
while ((data = buffer1.read()) != -1){
System.out.println((char) data);
}
System.out.println();
byte[] arr = new byte[3];
int count;
while ((count = buffer2.read(arr))!= -1) {
System.out.println(new String (arr, 0, count));
}
/**
* 只需要关闭BufferedInputStream对象
*/
buffer1.close();
buffer2.close();
}
}
BufferedOuputStream子类
缓冲字节输出流,继承抽象父类过滤输出流(FilterOutputStream)
import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
public class Main{
public static void main(String[] args) throws Exception {
FileOutputStream file = new FileOutputStream("d:\\buff.txt");
/**
* 创建BufferedOutputStream对象,将字节输出流对象作为参数
*/
BufferedOutputStream buffer = new BufferedOutputStream(file);
for (int i = 0; i < 10; i++) {
/**
* \r\n可以识别为换行符
*/
buffer.write("Mainworld\r\n".getBytes());
}
/**
* 关闭前默认调用了flush()方法刷新数据,否则数据还在缓冲区
*/
buffer.close();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号