

并发concurrent---3
背景:并发知识是一个程序员段位升级的体现,同样也是进入BAT的必经之路,有必要把并发知识重新梳理一遍。
ConcurrentHashMap:
在有了并发的基础知识以后,再来研究concurrent包。普通的HashMap为非线程安全的,在高并发场景下要使用线程安全版本的ConcurrentHashMap;
众所周知HashTable可以保证线程安全但却效率低下,而HashMap是非线程安全但效率却高于HashTable,于是ConcurrentHashMap就孕育而生成为二者的结合体,为了更好的理解ConcurrentHashMap先看下这两个Map。
HashMap:
HashMap之所以具有很快的访问速度,因为它是根据键的hashCode值来存储数据,在大多数情况下可以直接定位到它的值,但遍历的顺序是不确定的;HashMap的key可以为null,但是最多只允许一条记录的键为null,另外允许多条记录(value)的值为null,key为null的键值对永远都放在一table[0]为头节点的链表中;HashMap为非线程安全的,适用于单线程环境下,即在任一时刻都可以有多个线程同时对HashMap进行读或写操作,可以会导致数据的不一致;如果一定要使用HashMap又要保证线程安全,则可以用Collection的synchronizedMap方法或ConcurrentHashMap都OK;HashMap是基于哈希实表实现的,每一个元素是一个key-value对,其内部通过单链表结局冲突问题的,当Map容量不足(超过了阀值)时链表会自动增长;HashMap实现了Serializable接口,因此其支持序列化,并且实现了Cloneable接口,可以被克隆;
HashMap存储数据的过程:
HashMap内部维护了一个存储数据的Entry数组,HashMap采用链表解决冲突,每一个Entry本质上其实是一个单向链表;当要添加一个key-value对时,首先会通过hash(key)方法技术hash值,然后通过indexFor(hash,length)求该key-value对的存储位置,其计算方法是先用Hash&0x7FFFFFFF后,再对length取模,这就保证了每一个key-value对都能存入HashMap,当计算出相同的位置是,由于存入位置是一个链表,所以把这个key-value对插入链表头。
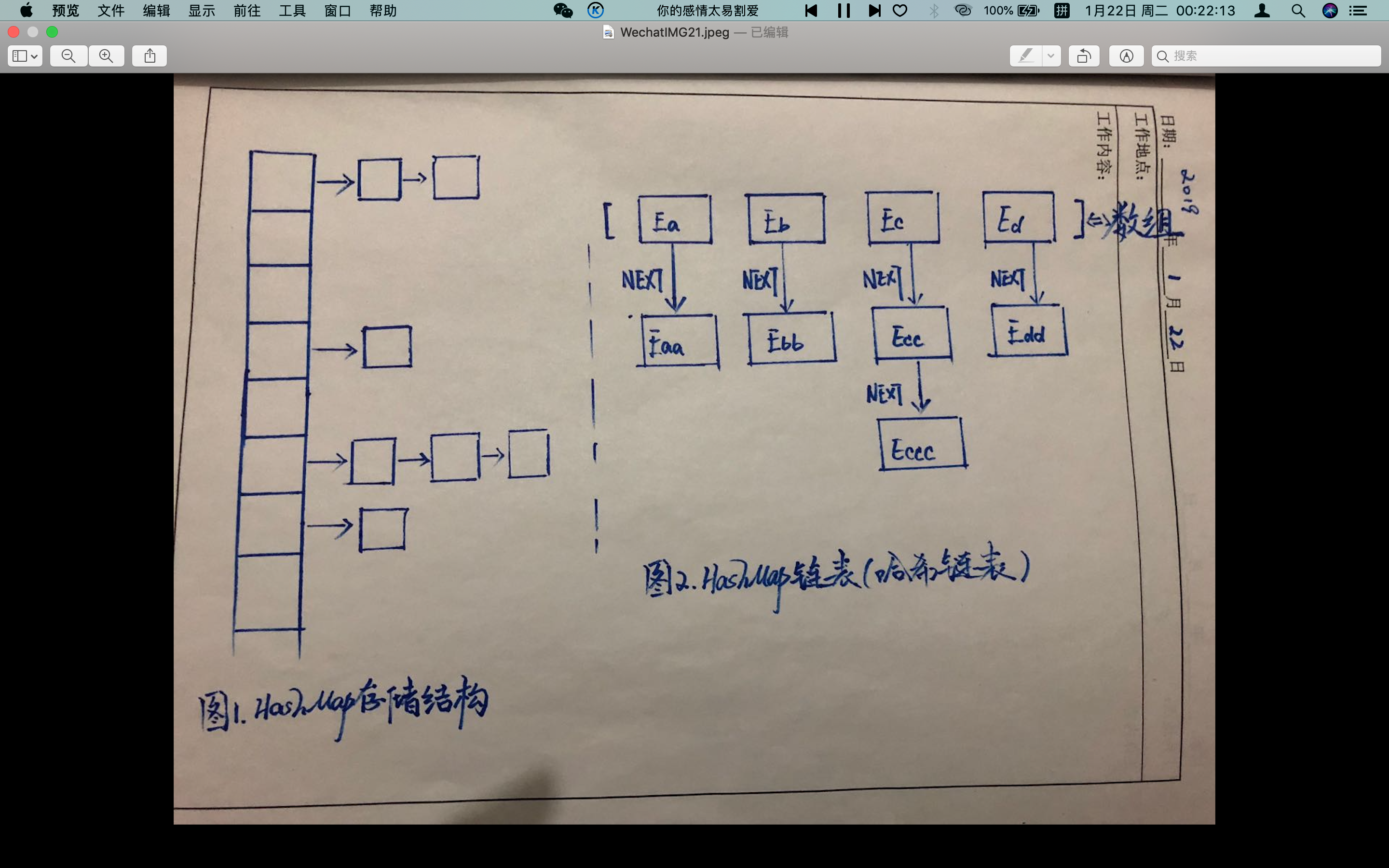
如上图1 所示,最左边竖列排的多个方格就代表哈希表,也叫哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中;HashMap内存储数据的Entry数组默认是16,如果没有对Entry扩容机制的话,当存储的数据一多,Entry内部的链表会很长,这就失去了HashMap的存储意义了,所以HashMap内部有自己的扩容机制(当size大于threshold时,对HashMap进行扩容)。 上图2 是HashMap的链表存储结构,其中E*代表一个Node节点,每个Node节点就对应着一个key-value的mapping映射;每个Node除了保存了key和value的映射之外,还保存了它下一Node的引用(Eb保存了Ebb的引用,而Ebb保存了Ebbb的引用);图2中,每一个链表如Ec-->Ecc-->Eccc,这三个节点的key是不相等的。
分析HashMap源码会发现其内部有几个重要的变量如:size用于记录HashMap的底层数组中已用槽的数量、threshold用于HashMap的阈值判断,看是否需要调整HashMap的容量(threshold = 容量*加载因子)、DEFAULT_LOAD_FACTOR = 0.75f,即加载因子默认0.75。 HashMap的扩容是是新建了一个HashMap的底层数组,通过调用transfer方法,将就HashMap的全部元素添加到新的HashMap中(此步需要重新计算元素在新的数组中的索引位置,导致HashMap扩容成为一个相当耗时的操作),So我们在用HashMap的时,最好能提前预估下HashMap中元素的个数,这样有助于提高HashMap的性能。
HashTable:
HashTable的功能与HashMap类似,如同样是基于哈希表实现的、内部也是通过单链表解决冲突问题、容量不足时也会自动增加、同样实现了Seriablizable接口支持序列化、实现了Cloneable接口可克隆;不同的是HashTable继承自Dictionary类且为线程安全的(任一时间只有一个线程可以写HashTable,但性能不如
ConcurrentHashMap),而HashMap继承AbstractMap类且非线程安全。
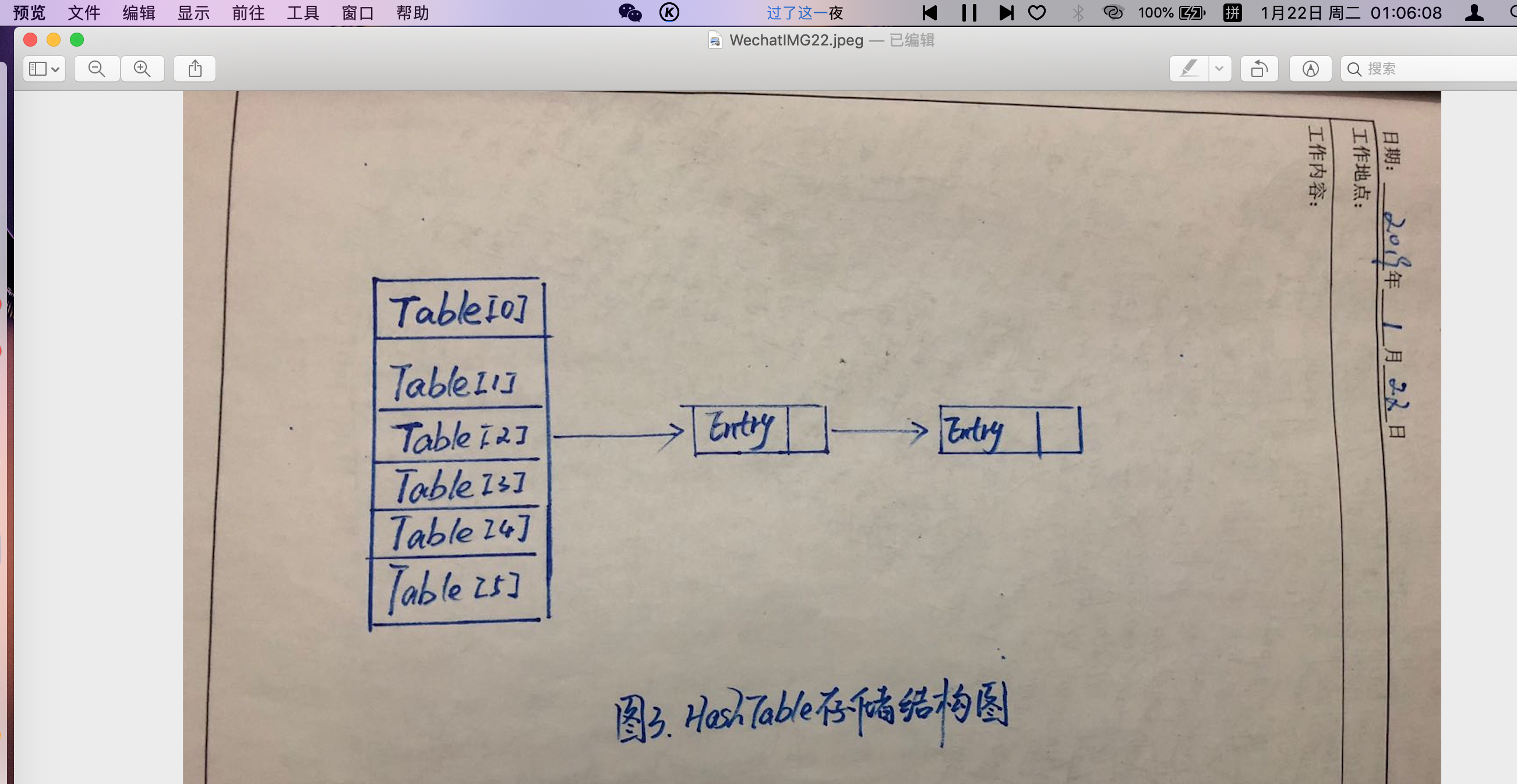
如图3,HashTable只有一把锁,当一个线程访问HashTable的同步方法时,会将整张table 锁住,当其他线程也想访问HashTable 同步方法时,就会进入阻塞或轮询状态。也就是确保同一时间只有一个线程对同步方法的占用,避免多个线程同时对数据的修改,由此确保线程的安全性;但HashTable 对get,put,remove 方法都使用了同步操作,这就造成如果两个线程都只想使用get 方法去读取数据时,因为一个线程先到进行了锁操作,另一个线程就不得不等待,这样必然导致效率低下,而且竞争越激烈,效率越低下。
ConcurrentHashMap(并发且线程安全):
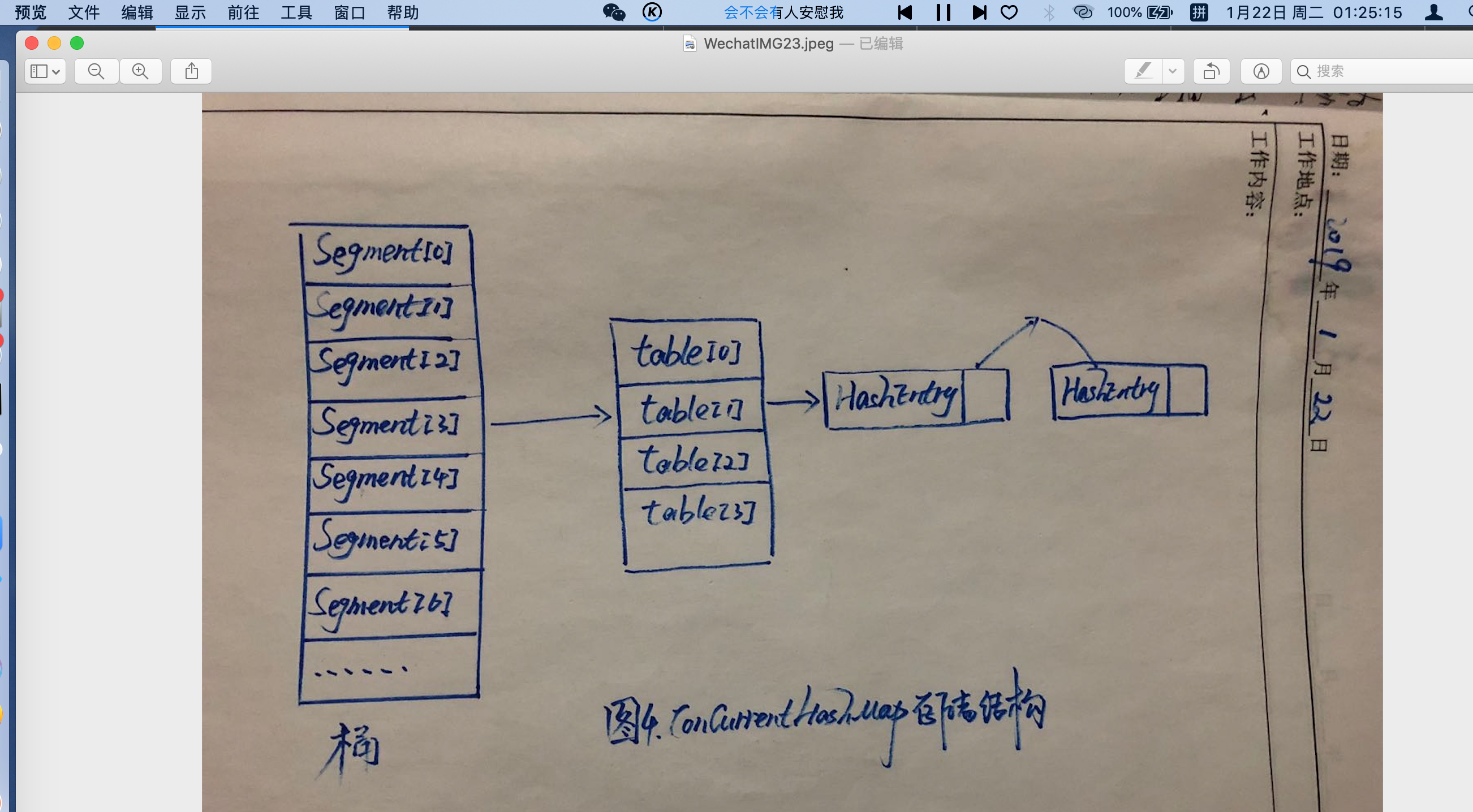
ConcourrentHashMap是通过分段锁技术来保证线程安全的[case:一个人到酒店开房可直接在前台办理入住,三个陌生人到酒店开房登记入住,另外两个则要先排队等第一个办理结束(普通的Map),要是三个人所住的每个楼层都有一个可以办理入住的前台就无需排队了(ConcurrentHashMap)];ConcurrentHashMap主要由Segment(桶)和HashEntry(节点)两大数据组成,如下图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号