
OpenMP - 编译制导(一)- for
编译制导是对程序设计语言的扩展。通过对串行程序添加制导语句实现并行化。
编译制导语句由下列几部分组成:
- 制导标识符 ( #pragma omp )
- 制导名称(parallel,for,section等)
- 子句(private, shared, reduction, copyin等)
并行域制导
一个并行域就是一个能被多个线程并行执行的程序段。在并行域结尾有一个隐式同步(barrier)。
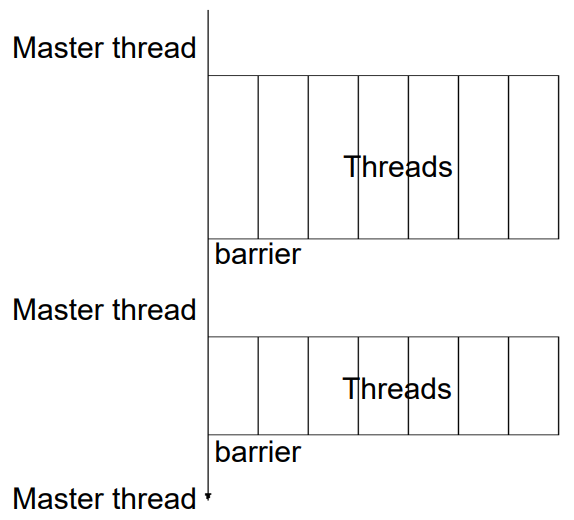
for循环制导
#include <iostream>
#include <omp.h>
using namespace std;
int main(int argc, char* argv[]){
int max_threads = omp_get_max_threads();
int num_procs = omp_get_num_procs();
cout << "max threads: " << max_threads << " num procs: " << num_procs << endl;
#pragma omp parallel for
for (int i = 0; i < 10; ++i) {
int num = omp_get_num_threads();
int id = omp_get_thread_num();
cout << "thread " << id << " --> " << i << endl;
}
return 0;
}注:#pragma omp parallel for指令,它的创建线程的数量并不是由循环的迭代次数决定的,而是由OpenMP根据当前系统的配置和设置来确定的。一般来说,OpenMP会根据可用的CPU核心数量和其他因素来决定创建多少个线程来执行循环。线程和迭代之间可能并不是一一对应的,即一个线程可能执行多个迭代,或者多个线程可能合作执行一个迭代(这取决于循环的划分方式)。
要指明节点的进程数salloc -p com -N 1 -n 32,否则默认为1,并且n要小于等于节点cpu核心数. ---》omp_get_max_threads() ---》32
调度子句schedule
schedule子句用于指定在并行循环中如何分配迭代给不同的线程。schedule指令允许你控制迭代的分配方式,以优化性能或者满足特定需求。该子句给出迭代循环划分后的块大小和线程执行的块范围。
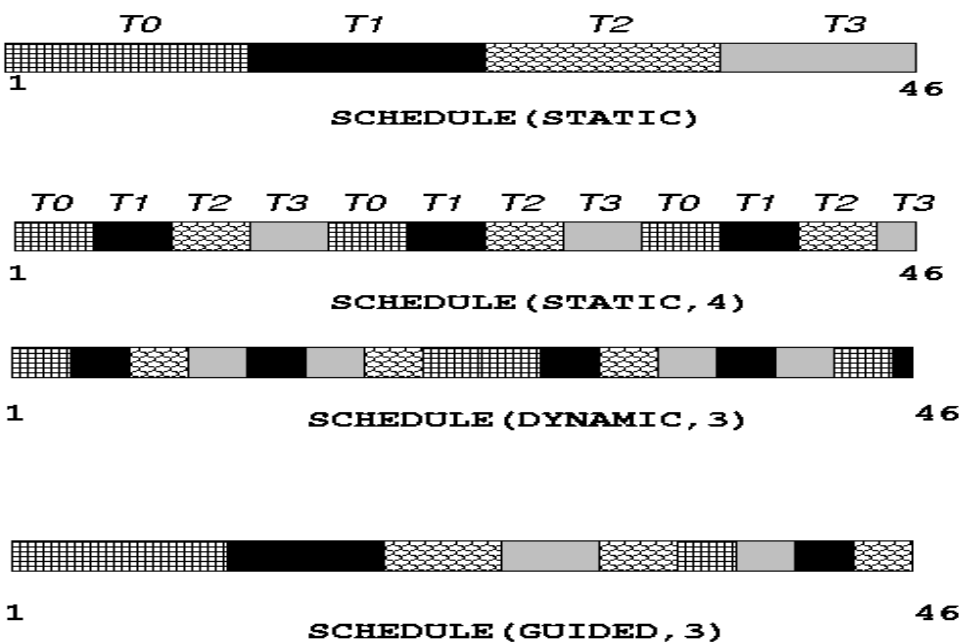
static
schedule (static, chunksize):省略chunksize,迭代空间被划分成(近似)相同大小的区域,每个线程被分配一个区域;如果chunksize被指明,迭代空间被划分为chunksize大小,然后被轮转的分配给各个线程。
#include <iostream>
#include <omp.h>
using namespace std;
int main(int argc, char* argv[]){
int d[10], id, k;
#pragma omp parallel for private(id) num_threads(4) schedule(static)
for (int i = 0; i < 12; ++i) {
id = omp_get_thread_num();
d[i] = id;
}
for (int i = 0; i < 10; ++i) {
cout << "thread " << d[i] << " --> " << i << endl;
}
return 0;
}schedule(static)
thread 0 --> 0
thread 0 --> 1
thread 0 --> 2
thread 1 --> 3
thread 1 --> 4
thread 1 --> 5
thread 2 --> 6
thread 2 --> 7
thread 2 --> 8
thread 3 --> 9
thread 3 --> 10
thread 3 --> 11schedule(static, 2)
thread 0 --> 0
thread 0 --> 1
thread 1 --> 2
thread 1 --> 3
thread 2 --> 4
thread 2 --> 5
thread 3 --> 6
thread 3 --> 7
thread 0 --> 8
thread 0 --> 9
thread 1 --> 10
thread 1 --> 11dynamic
schedule (dynamic, chunksize):划分迭代空间为chunksize大小的区间,然后基于先来先服务方式分配给各线程;省略chunksize时,其默认值为1。
schedule(dynamic, 2)
thread 0 --> 0
thread 0 --> 1
thread 1 --> 2
thread 1 --> 3
thread 1 --> 4
thread 1 --> 5
thread 1 --> 6
thread 1 --> 7
thread 1 --> 8
thread 1 --> 9
thread 3 --> 10
thread 3 --> 11schedule(dynamic)
thread 0 --> 0
thread 0 --> 1
thread 0 --> 2
thread 2 --> 3
thread 0 --> 4
thread 2 --> 5
thread 2 --> 6
thread 2 --> 7
thread 2 --> 8
thread 3 --> 9
thread 2 --> 10
thread 2 --> 11guided
schedule (guided, chunksize):动态地将迭代块分配给不同的线程,但是会随着迭代的进行而减小块的大小。这对于初始迭代比较耗时,而后续迭代较快的情况非常有效。chunksize指明最小的区间大小,默认为1。
runtime
schedule (runtime):在运行时动态地决定循环迭代的调度方式。当使用schedule(runtime)时,OpenMP会在程序运行时根据系统环境和可用资源来选择最合适的调度策略。具体来schedule(runtime)不直接指定迭代分配给线程的方式(如静态、动态或指导),而是将这个决策留给了OpenMP运行时库。可以自动适应不同的运行环境和资源情况,以达到最优的性能。
#pragma omp parallel for schedule(runtime)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号