《机器学习》第一次作业——第一至三章学习记录和心得
一、模式识别的基本概念
1.1模式识别
1.定义:模式识别是根据已有的知识表达,针对待识别模式,判别决策其所属的类别或者预测其对应的回归值。
2.本质:模式识别本质上是一种推理过程

3.应用实例:计算机视觉(字符识别,交通标志识别,动作识别等),人机交互(语音识别等)、医学领域(模式识别)、网络领域(应用程序识别)、金融领域(模式识别、股票价格预测)、机器人领域(目标抓取)、无人车领域(无人驾驶)。
4.数学表达:可以看成一做函数映射f(x),将待识别模式x从输入空间映射到输出空间,f(x)是关于已有知识的表达。

1.2模型的概念
1.模型:关于已有知识的一种表达方式,即函数f(x)。
2.模型的组成
从广义上看:特征提取+回归器+判别函数
从狭义上看:特征提取+回归器+判别函数

3 特征&特征空间
(1)特征:可以用于区分不同类别模式的、可测量的量。
(2)特征向量(feature vector):多个特征构成的(列)向量。


1.3 特征向量的相关性
1.点积的代数定义

2.残差向量:向量x分解到向量y方向上得到的投影向量与原向量x的误差。

3.欧式距离
1.4机器学习基本概念
1.线性模型:模型结构是线性的(直线、面。超平面)

适用场景:数据是线性可分或线性表达的
2.非线性模型:模型结构是非线性的(曲线。曲面、超曲面):y=g(x)
适用场景:数据是线性不可分或者线性不可表达
eg:多项式、神经网络、决策树等
3.样本量(N)与模型参数量(M)的联系
(1)如果N==M:参数唯一解
(2)如果N>>M(over-determined):没有准确的解
(3)如果N<<M(under-determined):无数解或无解
4.目标函数
(1)对于over -determined的情况,需要额外添加一个标准,通过优化该标准来确定一个近似解。该标准就叫目标函数(Objective function),也称作代价函数或损失函数
(2)对于under-determined的情况,还需要在目标函数中加入能够体现对于参数解的约束条件,据此从无数个解中选出最优的一个解。
5.优化算法:最小化或最大化目标函数的技术

1.5机器学习的方式
1.监督室学习:训练样本及输出真值都给定情况下的机器学习算法。通常使用最小化训练误差作为目标函数进行优化。
2.无监督式学习:之给定训练样本、没有给输出真值情况下的机器学习算法。难度远高于监督式算法。
应用:聚类(Clustering)、图像分割(Image Segmentation)。
3.半监督式学习:既有标注的训练样本,又有未标注的训练样本情况下的学习算法。可以看做有约束条件的无监督式学习。
应用:网络流数据。
4.强化学习:机器自行探索决策、真值滞后反馈的过程。
应用:Alpha Go等
1.6评估方法与性能指标
1.评估方法:
(1)留出法:
随机划分:将数据集随机分为两组:训练集和测试集。利用训练集训练模型,然后利用测试集评估模型的量化指标。
取统计值:为了克服单次随机划分带来的偏差,将上述随机划分进行若干次,取量化指标的平均值(以及方差、最大值等)作为最终的性能量化评估结果。
(2)K折交叉验证
将数据集分割成K个子集,从其中选取单个子集作为测试集,其他K - 1个子集作为训练集。交叉验证重复K次,使得每个子集都被测试-次;将K次的评估值取平均,作为最终的量化评估结果。
(3)留一验证
每次只取数据集中的一个样本做测试集,剩余的做训练集。每个样本测试一次,取所有评估值的平均值作为最终评估结果。等同于K折交叉验证,K为数据集样本总数。
1.7性能指标度量
二类分类:真阳性(TP),假阳性(FP),真阴性(TN),假阴性(FN)

1.准确度:(TP+TN)/(TP+TN+FP+FN)
2.精度&召回率:
精度:TP/(TP+FP)
召回率:TP/(TP+FN)
精度高、召回率高,则模型性能越好。
3.F-Score

如果a=1,则

4.PR、ROC、AUC
二、基于距离的分类器
2.1 基于距离的分类器的基本概念:
- 把测试样本到每个类之间的距离作为决策模型,将测试样本判定为与其距离最近的类。
1.MED分类器
(1)概念:最小欧式距离分类器(Minimum Euclidean Distance Classifier)
(2)距离度量:马氏距离
(3)类的原型:均值

(4)缺陷:会选择方差较大的类

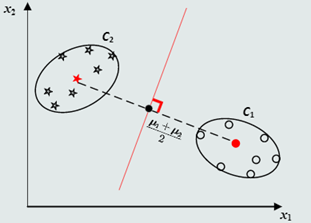
1.决策边界:
(1)对于2个类而言,MED分类器的决策边界方程为:
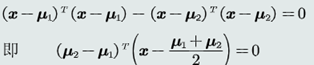
关于x的一次函数
(2)在高维空间中,决策边界为超平面
2.2.特征白化(去除特征相关性)
1.目的:将原始特征映射到一个新的特征空间,使得在新空间中特征的协方差矩阵为单位矩阵,从而去除特征变化的不同及特征之间的相关性
2.步骤:分为两步,先去除特征之间的相关性(解耦, Decoupling) ,然后再对特征进行尺度变换(白化, Whitening),使每维特征的方差相等。
3.转换矩阵W1的特性:转换前后欧氏距离保持不变,说明W1只是起到了旋转的作用。
三、贝叶斯决策和学习
3.1贝叶斯决策与MAP分类器
1.引言:
MICD分类器的问题:当两个类均值一样时,MICD偏向于方差大的类。
在此种情况,决策真值应该是倾向于方差小(分布紧致)的类。
2.后验概率:用于分类决策(找后验概率大的那个类)
3.贝叶斯规则

4.MAP分类器:将测试样本决策分类给后验概率最大的那个类。

(1)决策误差:概率误差等于未选择的类所对应的后验概率。
平均误差为样本概率误差的均值。
(2)目标:最小化概率误差,即分类误差最小化。

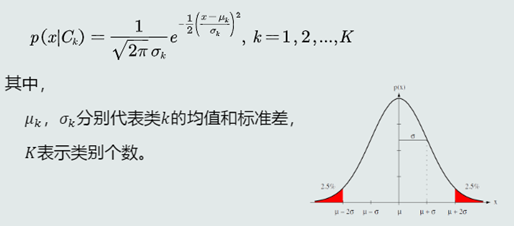
3.2MAP分类器:高斯观测概率
1.观测似然概率为一维高斯分布的分布函数:
3.决策边界
方程表达为
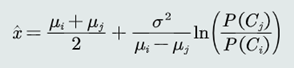
方便与MED分类器进行比较,也可以写为

在方差相同的情况下,MAP决策边界偏向先验可能性较小的类,即分类器决策偏向先验概率高的类
MAP分类器可以解决MICD分类器存在的问题。
当方差不同时,MAP分类器倾向选择方差较小的类。
3.3决策风险与贝叶斯分类器
1.决策风险的概念:贝叶斯决策不能排除出现错误判断的情况,由此会带来决策风险。
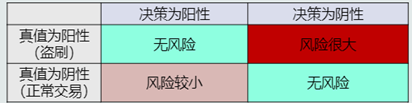
2.贝叶斯分类器
在MAP分类器的基础上,加入决策风险因素,得到贝叶斯分类器。贝叶斯分类器选择决策风险最小的类。

贝叶斯决策的期望损失

3.4最大似然估计
1.最大似然估计
定义

2.高斯分布参数估计
对于参数偏导置零

4.均值估计
关于u的最大似然估计
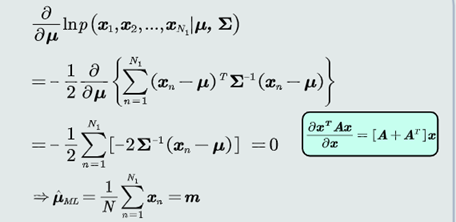
高斯分布均值的最大似然估计等于样本的均值
5.协方差估计

高斯分布协方差的最大似然估计等于所有训练模式的协方差。
3.5最大似然的估计偏差
1.无偏估计:
定义:如果一个参数的估计量的数学期望是该参数的真值,则估计量称作无偏估计。
2.高斯均值

均值的最大似然估计是无偏估计。
3.高斯协方差
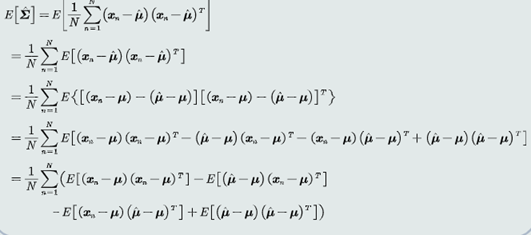

协方差的最大似然估计是有偏估计
5.高斯协方差估计偏差

一个较小的数。
3.6贝叶斯估计
1.定义

2.参数的后验概率

3.高斯观测似然

5.贝叶斯估计:不断学习能力
它允许最初的、基于少量训练样本的、不太准的估计。
随着训练样本的不断增加,可以串行的不断修正参数的估计值,从而达到该参数的期望真值。
6.观测似然概率的估计

观测似然概率可以看做是关于x的高斯分布
3.8 KNN估计
1.KNN估计:给定x,找到其对应的区域R使其包含k个训练样本,以此计算p(x)、
概率密度的表达式
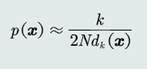

2.KNN估计的优缺点:
优点:可以自适应的确定x相关的区域R的范围。
缺点:KNN概率密度估计不是连续函数。
不是真正的概率密度表达,概率密度函数积分是oo而不是1。
3.8 直方图与核密度估计
1.直方图估计
原理:基于无参数概率密度估计的基本原理:

区域R的确定
直接将特征空间分为m个格子(bins),每个格子即为一个区域R,即区域的位置固定。
平均分格子大小,所以每个格子的体积(带宽)设为V= h,即区域的大小固定。
相邻格子不重叠。
落到每个格子里的训练样本个数不固定,即k值不需要给定。
2.直方图估计的优缺点:
优点:
固定区域R:减少由于噪声污染造成的估计误差。
不需要存储训练样本。
缺点:
固定区域R的位置:如果模式x落在相邻格子的交界区域,意味着当前格子不是以模式x为中心,导致统计和概率估计不准确。
固定区域R的大小:缺乏概率估计的自适应能力,导致过于尖锐或平滑。
3.核密度估计
估计也是基于无参数概率密度估计的基本原理
区域R的确定:以任意待估计模式x为中心、固定带宽h,以此确定一个区域R。
4.概率密度估计

核函数可以是高斯分布、均匀分布、三角分布等。
6.核密度估计的优缺点:
优点:
以待估计模式x为中心、自适应确定区域R的位置(类似KNN)。
使用所有训练样本,而不是基于第k 个近邻点来估计概率密度,从而克服KNN估计存在的噪声影响。
如果核函数是连续,则估计的概率密度函数也是连续的。
缺点:
与直方图估计相比,核密度估计不提前根据训练样本估计每个格子的统计值,所以它必须要存储所有训练样本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号