任务8,泰坦尼克号
按老师给的代码第一次提交得分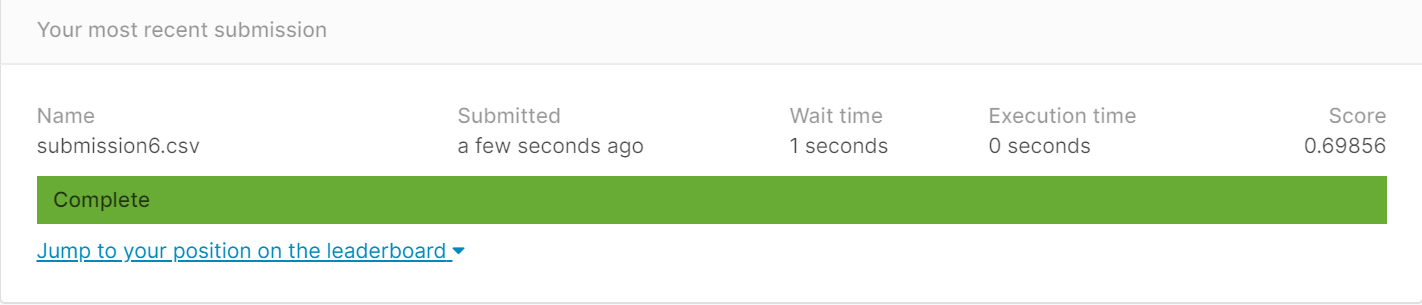
下面进行改进
一, 首先进行数据的清洗
先观察数据,首选'Pclass','Sex','Age'作为是否生还(Survived)的 考虑条件来建模
“Sex”的数值是字符型,于是用特征编码将性别用0,1表示
随后发现”Age”中有缺少值,由于age是数值量,可以直接使用,那么在”Age”的缺失值处理中,可以采用的是删除法,和填补法。
(一, 删除法)
由于缺失值超过原数据的10%,所以不考虑用删除法
(二, 填补法)
(1) 用0填补
(因为该属性是年龄,用0填补可能误差比较大)
老师给的代码中就是用0填补
得分为0.69856
(2) 用平均值填补
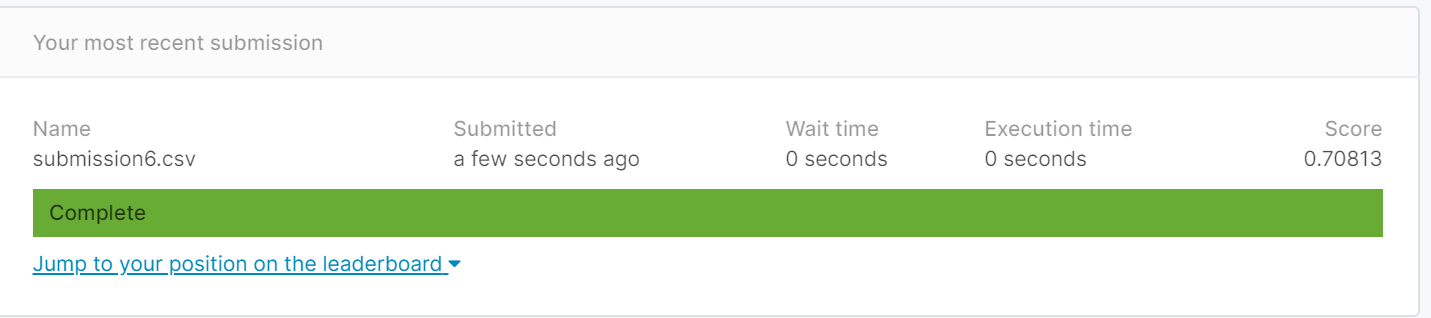
将Age的缺失值由0改为该列的平均值后得分为0.70813
(默认K=5)
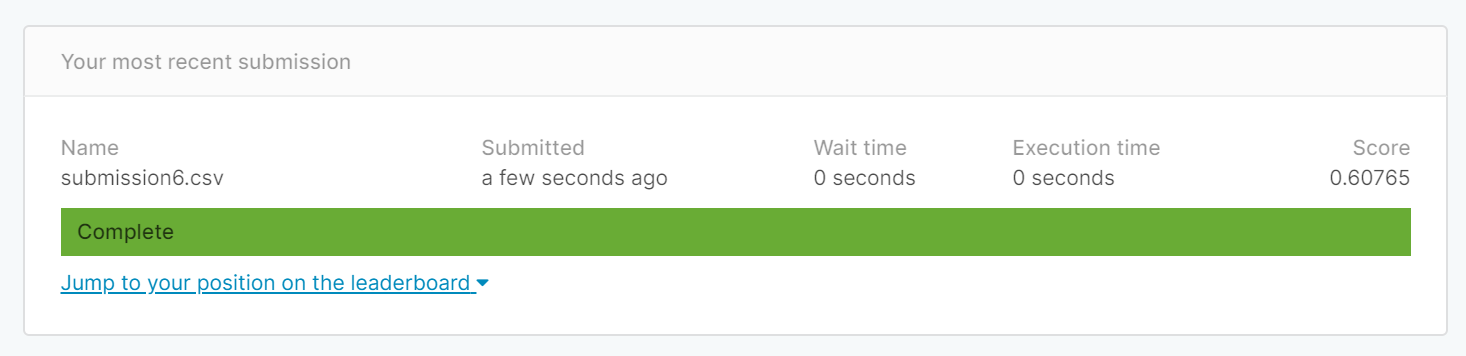
(3) 用中位数填补
将Age的缺失值由0改为该列的中位数后得分为0.60765
(默认K=5)
说明在本题中使用平均值比用0和中位数更好,于是在下面的尝试中都是采用Age缺少值填补为平均值的方法
二,训练KNN模型,以及用KNN模型做预测
在继续改进的时候想到,会不会KNN的K值对结果有影响。
(KNN的K值默认是5,得分为0.70813)
通过K折交叉验证来选择KNN模型中的K值
——查了资料发现,K折交叉验证的K的取值没有一定的要求,现在较流行的是十折交叉验证和留一法。
(1) 5折交叉验证后best_k值为1,把K值改为1后,发现得分比K值为5小
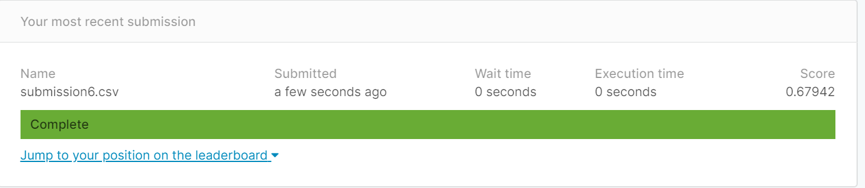
(2) 留一法后,得到best_k为13
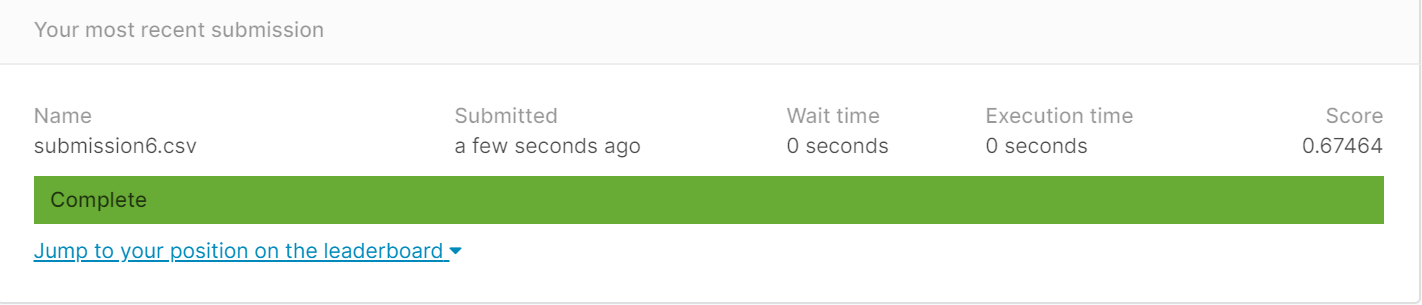
结果更低了,再试十折交叉验证
(3) 十折验证法后得到best_k=7
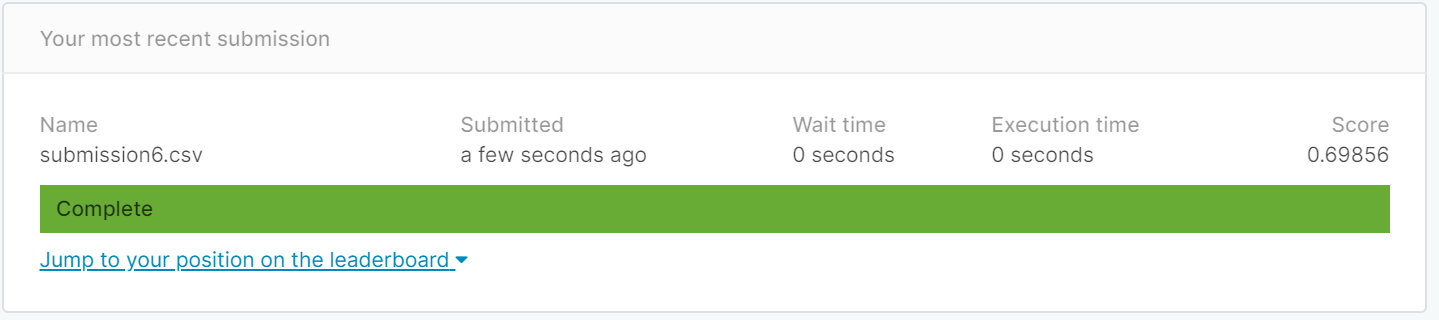
虽然比留一法的高,但是没有当K等于5时高,为什么K折交叉验证法不能找出最优的K值呢?
在搜索其他博客时发现有人用KNN算法时K取3,于是我又在上述的基础上把K改为3,分数更高了
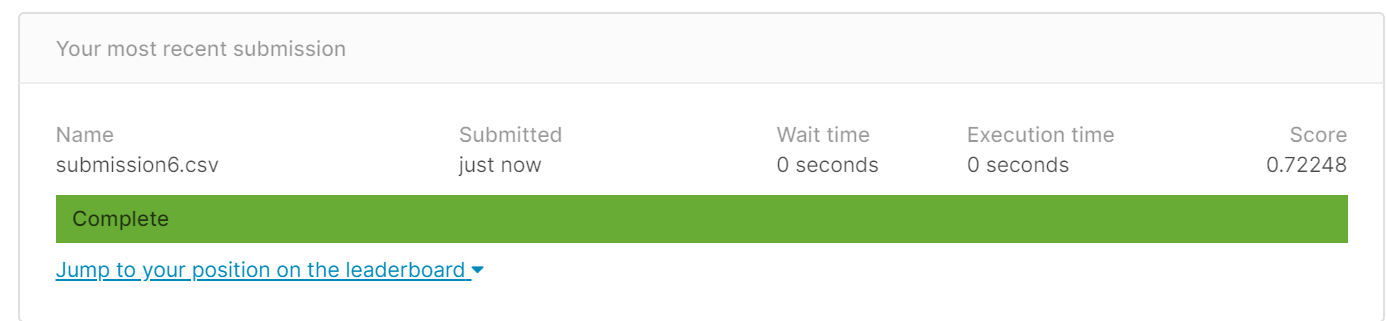
三,添加特征
(一) 添加'Embarked'上船城市
考虑到上船城市不同可能会影响结果,于是加入该特征
由于只有两个缺失值,于是直接把缺失值赋为“S”
下面是我把'Embarked'的值S,C,Q直接用0,1,2(标签编码)代替时得到的结果
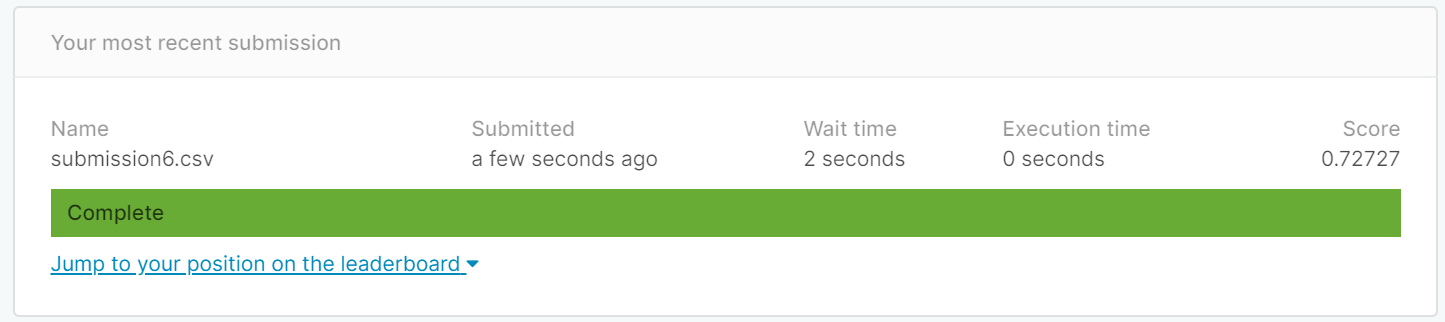
但是因为0,1,2之间有大小之分,但是我认为这三个城市更适合用独热编码(向量)来表示
于是得到下面的结果

很神奇,用标签编码得到的分数要比独热编码高,但是我还是想不出为什么,直到我看到了一篇博客,里面说道
“S口岸,登船人数644,女性乘客占比46%;C口岸,登船人数168,女性占比接近77%;Q口岸,登船人数77,女性占比接近88%。前面已知女性生存率明显高于男性生存率,所以上述问题可能由性别因素引起。”
因为女性的存活率会比女性的高,所以用0,1,2分别表示S,C,Q确实是有大小的区别,但很有可能不是因为城市,而是因为该城市上船的女性比例较高,这只是我的一个想法,可能有其他我没想到的原因。
(二)添加堂兄弟和堂兄妹个数(SibSp)、父母和孩子的个数(Parch)
(1) 添加堂兄弟和堂兄妹个数(SibSp)、父母和孩子的个数(Parch),并且删除'embarked‘
得分:0.69856
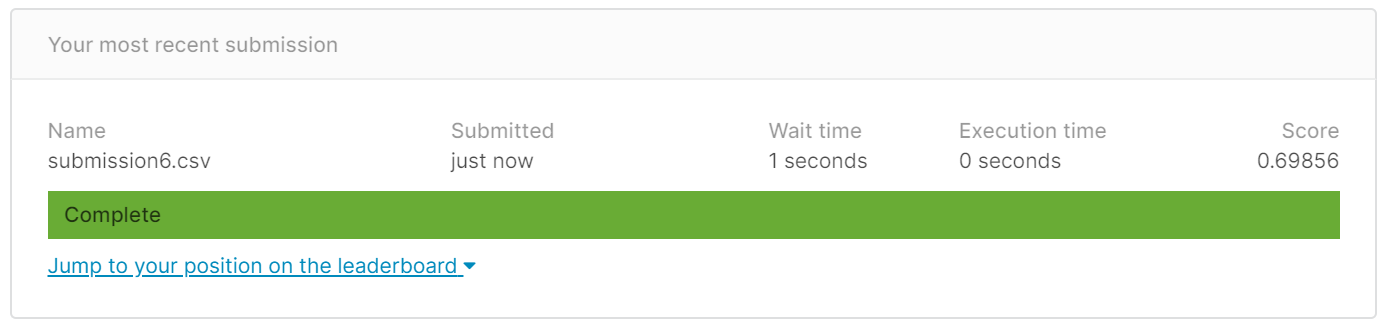
得分比原来不添加还低
(2)添加堂兄弟和堂兄妹个数(SibSp)、父母和孩子的个数(Parch),并且添加'embarked‘
得分:0.68412
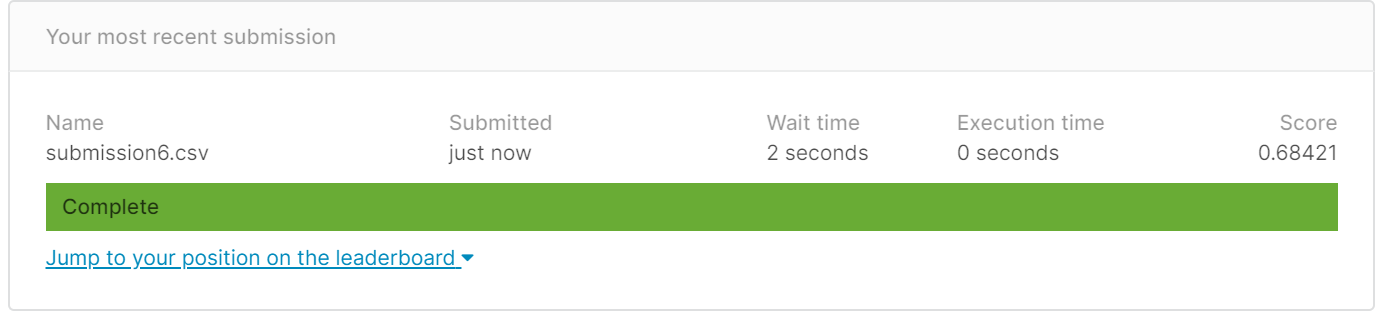
反而比不添加Embarked更低。
可能是否有家人在这个因素对是否生存没有直接的联系.
(3)添加父母和孩子的个数(Parch),并且添加'embarked‘
得分:0.72248
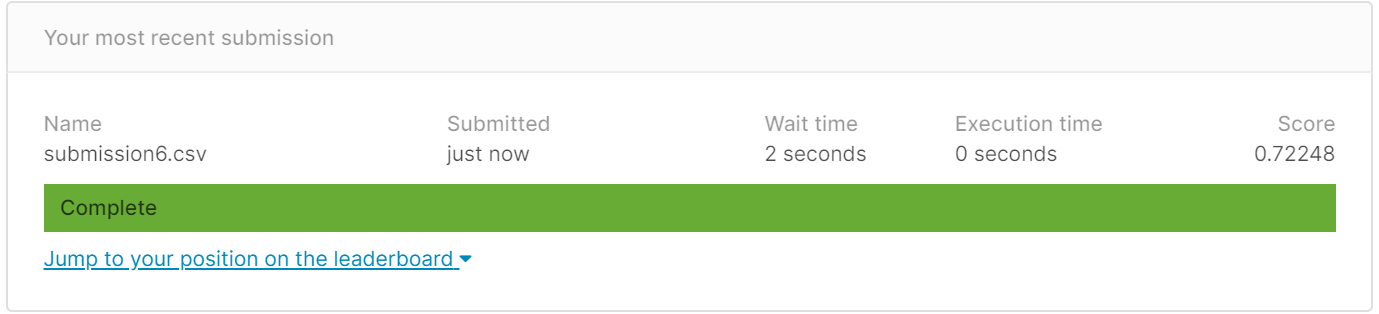
(4)添加堂兄弟和堂兄妹个数(SibSp)并且添加'embarked‘
得分:0.67464
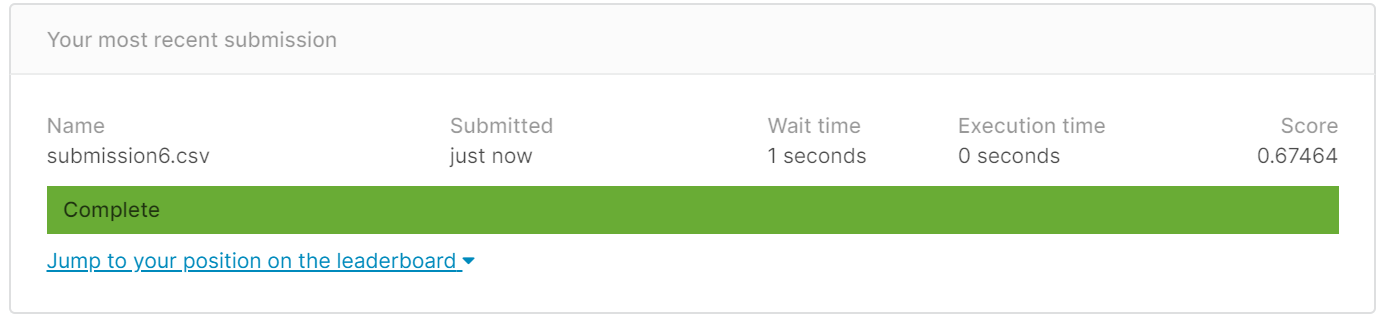
(5)删Embarked,只用Parch
得分:0.70813
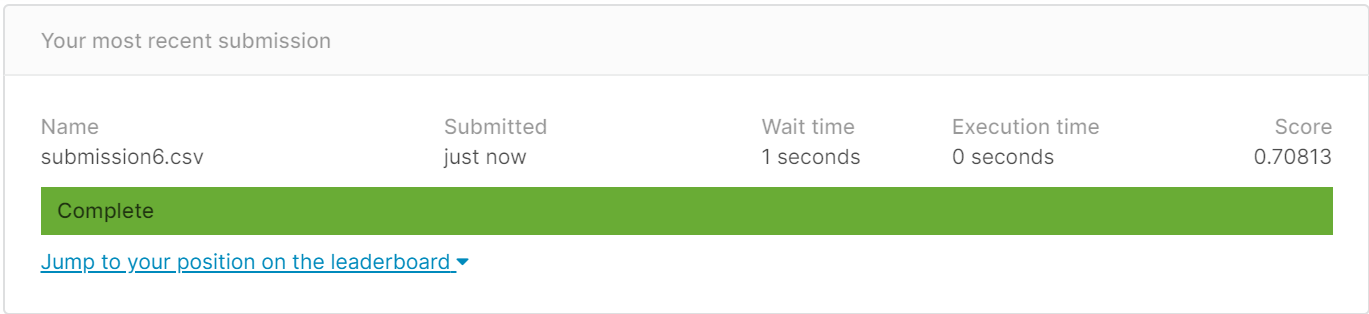
(6)删Embarked,只留SibSP
得分:0.68421
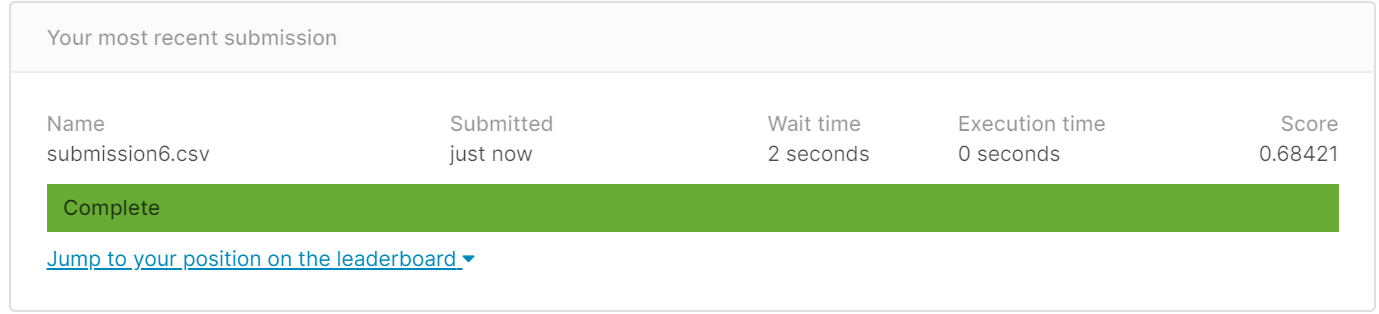
上述情况表示,加上SibSp和Parch之后的得分要比不加时都低,这两个特征不考虑
最后得分最高的情况是:
(1) “Age”的缺失值用平均数填补,“Embarked”的缺失值用众数填补
(2) 只考虑'Age''Sex''Pclass'和“Embarked”这四个特征
(3) 'Embarked'用标签编码而不是独热编码
(4) KNN算法中参数n_neighbors取3值
最高得分:0.72727
心得总结:
(1) 在分析数据时没有做到把数据可视化来观察,而是凭感觉选出“年龄性别舱位等级”这些特征来拟合模型。
(2) 验证的顺序有点乱,应该一个验证完再尝试下一个。
(3) 不仅对训练数据'train'要进行数据清洗,对测试数据'test'也要。
(4) 有一个疑惑的问题,为什么K折交叉验证法得出的best_k K值得分不是最高的?难道是KNN的K值在这个问题中没什么影响吗?
最后上代码
1 import pandas as pd 2 train = pd.read_csv(r'C:\Users\tanha\Desktop\机器学习\train.csv') 3 test = pd.read_csv(r'C:\Users\tanha\Desktop\机器学习\test.csv') 4 print(train) 5 6 traindata = train[['Pclass','Sex','Age','Embarked']].copy() 7 #trainlabel = pd.Series(train['Survived']) 8 trainlabel = train['Survived'].copy()#目标值 9 #为何要.copy()? https://www.jianshu.com/p/72274ccb647a 10 11 #对性别以0-1取代,male-1,female-0 12 traindata.loc[traindata.Sex =='female', 'Sex'] = 0 13 traindata.loc[traindata.Sex =='male', 'Sex'] = 1 14 #对城市也同样用0,1,2取代S,C,Q 15 traindata.loc[traindata.Embarked =='S', 'Embarked'] = 0 16 traindata.loc[traindata.Embarked =='C', 'Embarked'] = 1 17 traindata.loc[traindata.Embarked =='Q', 'Embarked'] = 2 18 traindata 19 20 #查看缺失值情况 21 traindata.info() 22 #显示Age的缺失值 23 traindata[traindata.Age.isnull()] 24 traindata[traindata.Embarked.isnull()] 25 26 ##填充Age的缺失值为0 27 #traindata.loc[traindata.Age.isnull(), 'Age'] = 0 28 #填充Age的缺失值为该列平均值mean() 29 #中位数median() 30 print(traindata.Age.mean()) 31 traindata.loc[traindata.Age.isnull(), 'Age'] = traindata.Age.fillna(round(traindata.Age.mean(),1)) 32 #填充Embarked的缺失值为0 33 traindata.loc[traindata.Embarked.isnull(), 'Embarked'] = 0 34 traindata.head(10) 35 36 from sklearn.model_selection import train_test_split 37 train_data, test_data, train_label, test_label = train_test_split(traindata, trainlabel, random_state=7, test_size=0.3 ) 38 print(len(train_data), len(test_data),len(train_label)) 39 type(train_data) 40 type(train_label) 41 42 #选出一个K的值 43 #把训练集分为训练数据和验证数据 44 import numpy as np 45 from sklearn.model_selection import KFold 46 from sklearn.neighbors import KNeighborsClassifier 47 48 #X = np.array(traindata[['Pclass', 'Sex', 'Age']]) 49 X = np.array(traindata) 50 #y = np.array(trainlabel['Survived']) 51 y = trainlabel.values.ravel() 52 #已经把X,y化为列表 53 54 kf = KFold(n_splits=891,shuffle=True) #如果要使用留一法交叉验证,那n_splits=样本数量 55 56 ks = [1,3,5,7,9,11,13,15,17,19,20] 57 58 best_k = ks[0] 59 best_score = 0 60 61 for k in ks: 62 curr_score = 0 63 64 for train_index, valid_index in kf.split(X): 65 clf = KNeighborsClassifier(n_neighbors=k) 66 clf.fit(X[train_index], y[train_index]) 67 curr_score += clf.score(X[valid_index], y[valid_index]) 68 69 avg_score = curr_score/891 #前面n_splits=5,5折交叉验证 70 71 if avg_score>best_score: 72 best_score = avg_score 73 best_k = k 74 print("current best score is: %.2f"%best_score, "best k: %d"%best_k) 75 76 print("after cross validtion, the final best k is: %d"%best_k) 77 78 from sklearn.neighbors import KNeighborsClassifier 79 clf = KNeighborsClassifier(n_neighbors=3) 80 81 clf.fit(traindata, trainlabel) 82 83 pred = clf.predict(test_data) 84 85 from sklearn.metrics import accuracy_score 86 accuracy_score(pred, test_label) 87 88 #清洗test数据 89 testdata = test[['Pclass','Sex','Age','Embarked']].copy() 90 #对性别以0-1取代,male-1,female-0 91 testdata.loc[testdata.Sex =='female', 'Sex'] = 0 92 testdata.loc[testdata.Sex =='male', 'Sex'] = 1 93 94 testdata.loc[testdata.Embarked =='S', 'Embarked'] = 0 95 testdata.loc[testdata.Embarked =='C', 'Embarked'] = 1 96 testdata.loc[testdata.Embarked =='Q', 'Embarked'] = 2 97 98 #查看缺失值情况 99 testdata.info() 100 #显示Age的缺失值 101 testdata[testdata.Age.isnull()] 102 103 #填充Embarked的缺失值为0 104 testdata.loc[testdata.Embarked.isnull(), 'Embarked'] = 0 105 106 #填充Age的缺失值为该列平均值 107 testdata.loc[testdata.Age.isnull(), 'Age'] = testdata.Age.fillna(round(testdata.Age.mean(),1)) 108 testdata.head(100) 109 110 import numpy as np 111 #testdata = test[['Pclass','Sex','Age','Embarked']].copy() 112 result0 = clf.predict(testdata) 113 index = test['PassengerId'] 114 sumission = pd.DataFrame({'PassengerId':test['PassengerId'].values,'Survived':result0.astype(np.int32)}) 115 #sumission = sumission.reset_index(drop=True) 116 #index = test_data['PassengerId'] 117 sumission['Survived'] = result0 118 sumission = sumission.reset_index(drop=True) 119 sumission.to_csv(r'C:\Users\tanha\Desktop\机器学习\submission6.csv',index=0)#不保留行索引
参考博客:
python 分析泰坦尼克号生还率(数据可视化很清晰)
https://blog.csdn.net/sixkery/article/details/83239375
用Python随机森林预测泰坦尼克号生存情况
https://www.cnblogs.com/annebang/p/8731300.html
Kaggle泰坦尼克数据科学解决方案
https://www.cnblogs.com/zackstang/p/8185531.html
GridSearchCV,CV调优超参数使用】【K最近邻分类器 KNeighborsClassifier 使用】【交叉验证】
https://blog.csdn.net/feifei_csdn/article/details/84103071

 浙公网安备 33010602011771号
浙公网安备 33010602011771号