CS:APP Chapter 5 程序优化-读书笔记
5 程序优化
优化性能的时候要理解系统
-
程序是怎样被编译和执行的?
-
现代处理器与存储系统是如何运作的
-
怎样去测量程序性能并定位程序的性能瓶颈
-
在保持代码完整性的前提下,改进程序性能
程序是复杂的,但是过程应该要是简洁的,冗余的变量、表达式,错误的顺序等等都可能会极大地限制程序的性能释放,但是这些问题的处理,往往要比算法复杂度的较低要来的轻松,甚至可以通过编译器的优化来使得一些程序员的陋习在底层无声被改变!
刚开始编译原理或是计算机组成原理的时候,可能会觉得程序代码和汇编至少是一一对应的吧,怎样也不会差的太离谱,后来了解了程序优化,才知道原来编译器为我们做了如此之多的工作,从寄存器分配,代码选择与排序调度,不可达的代码,到低效代码的清除等。
但是编译器也是有局限的,作为一个创造者,你很难预测你的程序在运行过程中出现的所有问题,而对于编译器就更难了,只能通过现有的静态代码,做静态分析,排除一些语法,语义错误,运行时的错误几乎无法排查,除非做很多的预置条件去判断,而且往往局部代码分析要比全局的分析代价来的小的多,所以新版本的 GCC 在单独的文件中进行了过程间分析。
因此,受制于代码的编译器在面对无法确定的优化风险时,只能遵循代码原本的含义,不能做过于激进的优化导致其变化,所以编译器必须是保守的。
常用的优化手段
不考虑具体的处理器与编译器,仅仅是对 C 语言
代码移动
减少计算执行的频率,移动哪些总是产生相同结果的表达式,并且这些表达式在循环或者很多地方被多次调用。
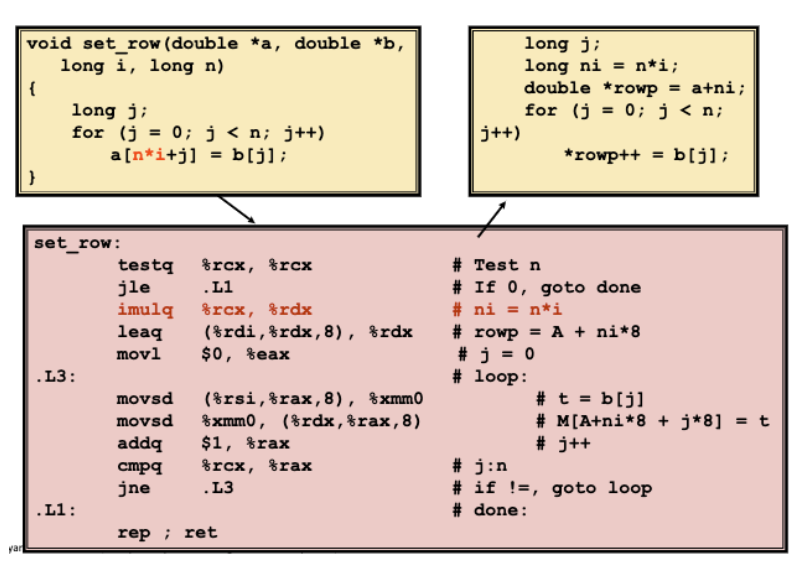
复杂运算简化
使用代价更小的方法替换那些代价高昂的操作,例如使用移位操作替换乘法操作,不过一般是对那些 2 的次方进行替换。
16 * x > x << 4
或者使用加法来替换多次乘法。
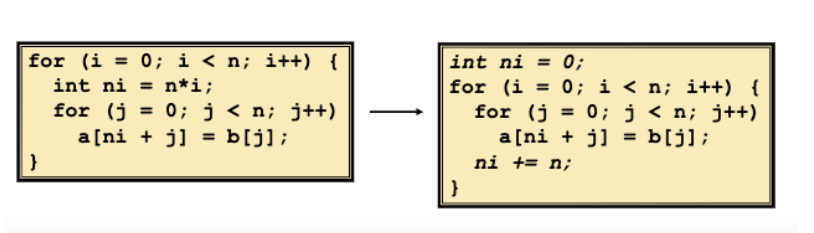
这里用ni+=n来替换int ni = n*i,减少了乘法操作,在 Intel Nehalem 处理器中,整数的乘法需要 3 个 CPU 周期。
共享公共子表达式

这样使得 4 次乘法操作变成了一次乘法与四次加法的形式。
妨碍优化的障碍之一: 函数调用
以字符串转为小写的函数为例子
void lower1(char *s){
size_t i;
for (i = 0; i < strlen(s); i++) {
if (s[i] >= 'A' && s[i <= 'Z']) {
s[i] -= ('A' - 'a');
}
}
}
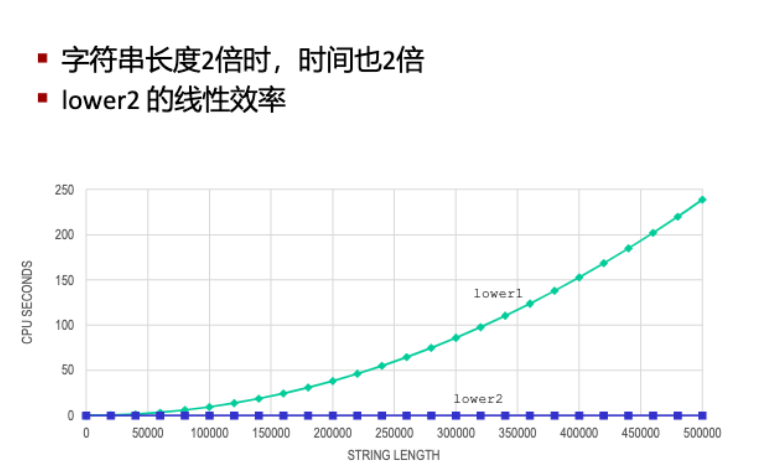
这个函数的瓶颈在于每一次判断 i 是否超过 s 的长度时,都会调用一次strlen,这一步的代价非常的高,因此每次查询字符串的长度,都需要遍历字符串,复杂度为 \(O (N)\),所以这个函数最终的复杂度来到了 \(O (N^2)\),使得结果无法接受。
因此对于这种每次都会调用,但是调用的结果都是一样的函数,我们应该将其抽离出来,存放在一个变量中保存,使得每次循环只需要比较一次即可,而不需要执行函数。
于是我们就可以写出下面这个函数。
void lower2(char *s){
size_t i;
size_t len = strlen(s)
for (i = 0; i < len; i++) {
if (s[i] >= 'A' && s[i <= 'Z']) {
s[i] -= ('A' - 'a');
}
}
}
这样子只需要调用一次strlen是我们的效率得到了提升。
内存调用相关优化
for (int i = 0; i < n; i++) {
b[i] = 0;
for (int j = 0; j < n; j++)
b[i] += a[i * n + j];
}
在这段代码中,重复调用了很多次b[i],而实际上这个变量只是起到一个存储的作用,却让程序每次都会访问内存,因此会引起较大的开销。
生成的汇编代码如下
# sum_rows1 inner loop
.L4:
movsd (%rsi,%rax,8), %xmm0 # FP load
addsd (%rdi), %xmm0 # FP add
movsd %xmm0, (%rsi,%rax,8) # FP store
addq $8, %rdi
cmpq %rcx, %rdi
jne .L4
在此处的第 3 行中,就是从内存中读取b[i]的值,而且这是在一个循环中,其执行次数会非常非常多,导致效率降低。
于是我们可以使用一个临时变量来存储行相加的结果,在相加完成之后再把结果赋值给b[i]。
存储器别名的使用
-
两个不同的内存引用指向了同一个存储器
-
在C语言中很容易发生
-
因为C中允许做地址运算
-
直接访问存储结构
-
-
C中常常使用局部变量
- 局部变量会在循环中累计,而编译器并不会检查存储器的别名使用情况。
超标量处理器
超标量处理器可以在一个时钟周期内并行执行多个指令,这些指令都是从同一个连续的指令流中获取的,通常被动态调度。
好处是不需要特定的代码插入,超标量处理器就可以利用绝大多数程序代码所具有的指令并行性来并行执行代码。
现代处理器往往可以同一时间执行多条指令,这种技术一般通过流水线来实现,而遇到一条指令依赖于上一条指令的运行结果时,就需要等待上一条指令运算完成,才能接着运行,这样就形成了顺序依赖性。
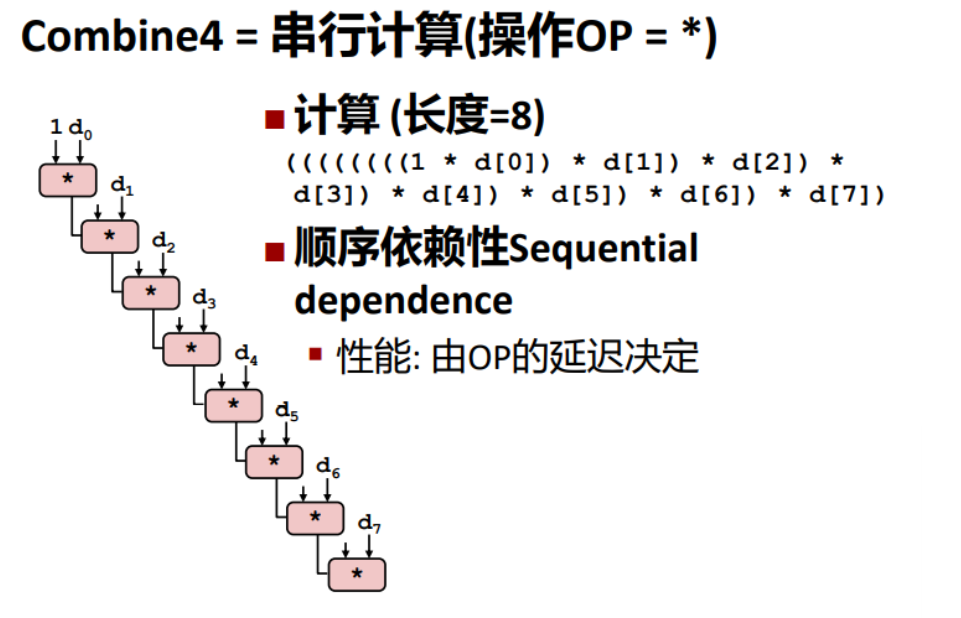
顺序依赖性会降低处理器的运行效率。
我们可以通过带重组的循环展开来破解这种顺序依赖性。
void unroll2a_combine(vec_ptr v, data_t *dest)
{
long length = vec_length(v);
long limit = length-1;
data_t *d = get_vec_start(v);
data_t x = IDENT;
long i;
/* Combine 2 elements at a time */
for (i = 0; i < limit; i+=2) {
x = (x OP d[i]) OP d[i+1];
}
/* Finish any remaining elements */
for (; i < length; i++) {
x = x OP d[i];
}
*dest = x;
}
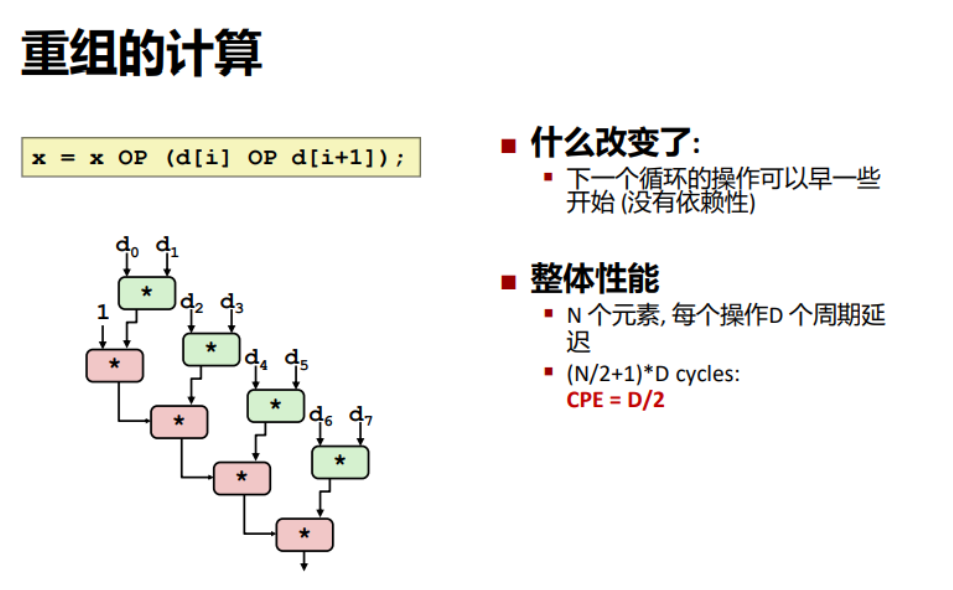
重组展开
我们将其中一个循环的操作赋值语句替换成这样的语句:
x = x OP (d[i] OP d[i+1]);
这样原先的数据依赖就变成了非线性
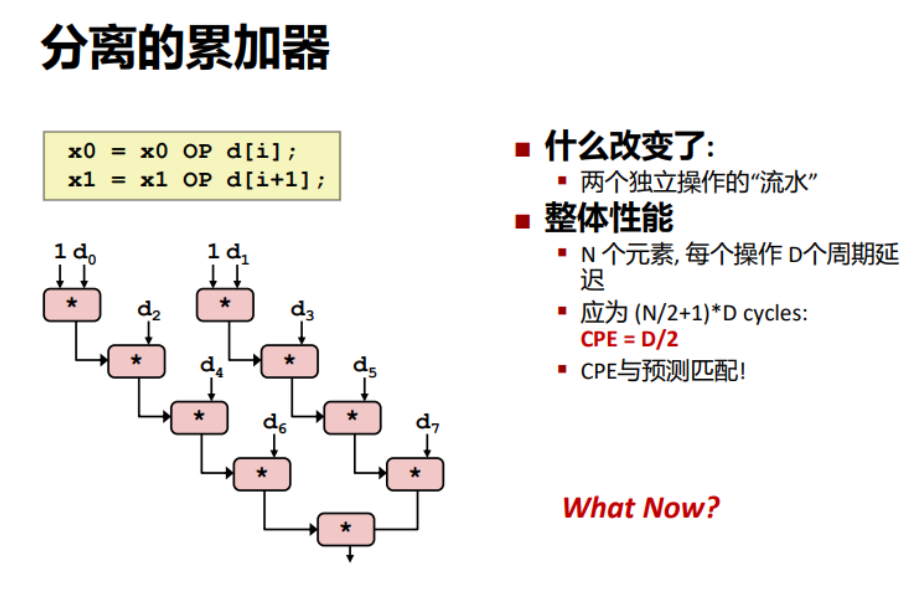
使用分别的累加器
for (i = 0; i < limit; i+=2) {
x0 = x0 OP d[i];
x1 = x1 OP d[i+1];
}
相当于把奇数和偶数的操作总和分别存放在两个变量中,在最后在进行合并,不过这要求该操作具有交换律!
*dest = x0 OP x1;
这样依赖就变成了
编写高性能代码
-
使用优化良好的编译器
-
汇编级别优化
-
使用更低时间复杂度/空间复杂度的算法
-
编写编译器友好的代码
-
注意函数调用,在循环里重复调用会产生相同结果的函数
-
注意存储器引用,C语言中对指针的使用
-
-
注意最内部的循环,因为大多数工作在此处完成。
-
-
机器级别优化
-
应该要注意代码的指令级别并行,避免顺序依赖
-
避免不可预测的分支,应该让分支代码尽量可预测
-
使用代码缓存
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号