
5.RDD操作综合实例
一、词频统计
A. 分步骤实现
- 准备文件
- 下载小说或长篇新闻稿

- 上传到hdfs上
hdfs dfs -put /home/hadoop/5case.txt ./5case
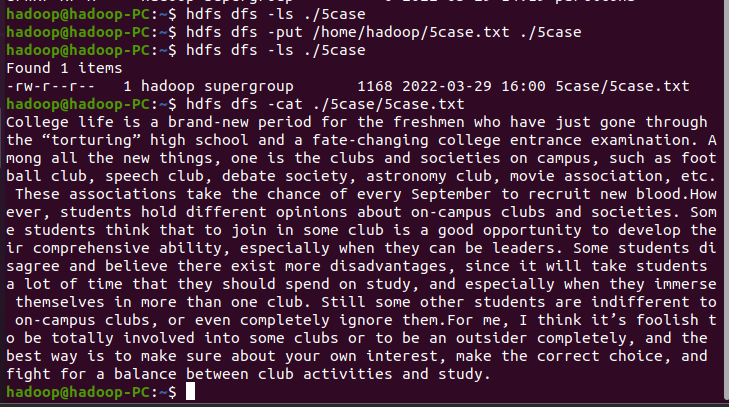
- 读文件创建RDD
lines = sc.textFile("/user/hadoop/5case/5case.txt")
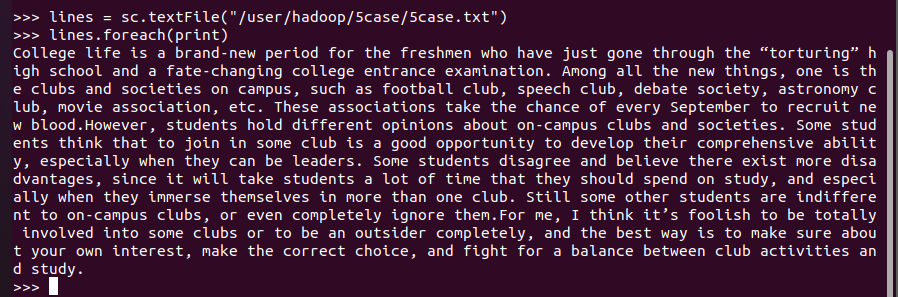
- 分词
pattern = ''' |,|\.|\’|“|”| ''' |为间隔符 \为防转义符
words = lines.flatMap(lambda line:re.split(pattern,line))
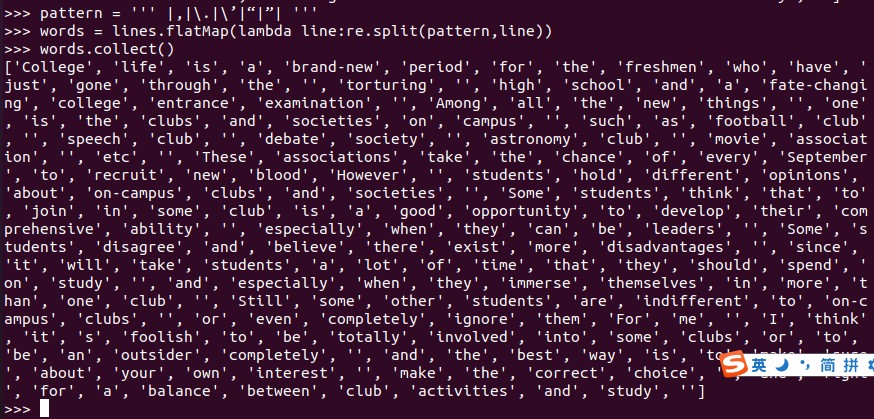
- 排除大小写lower(),map()
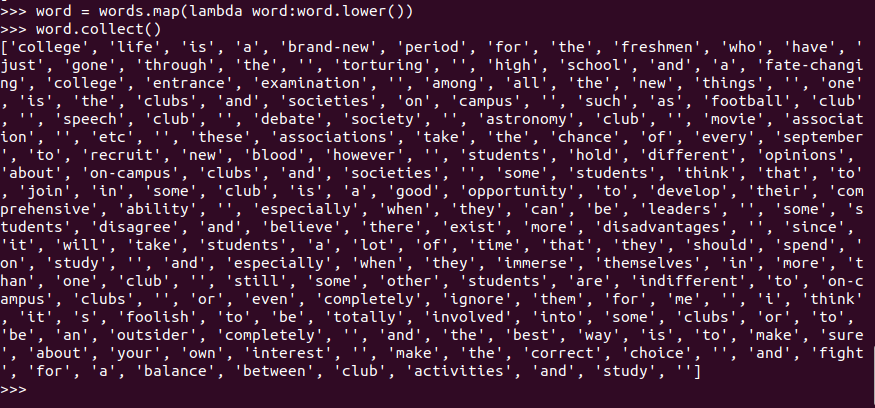
words.map(lambda word:word.lower())
标点符号re.split(pattern,str),flatMap(),
停用词,可网盘下载stopwords.txt,filter(),
with open("/home/hadoop/stopwords.txt") as stoplines:
stopwords = stoplines.read().split()
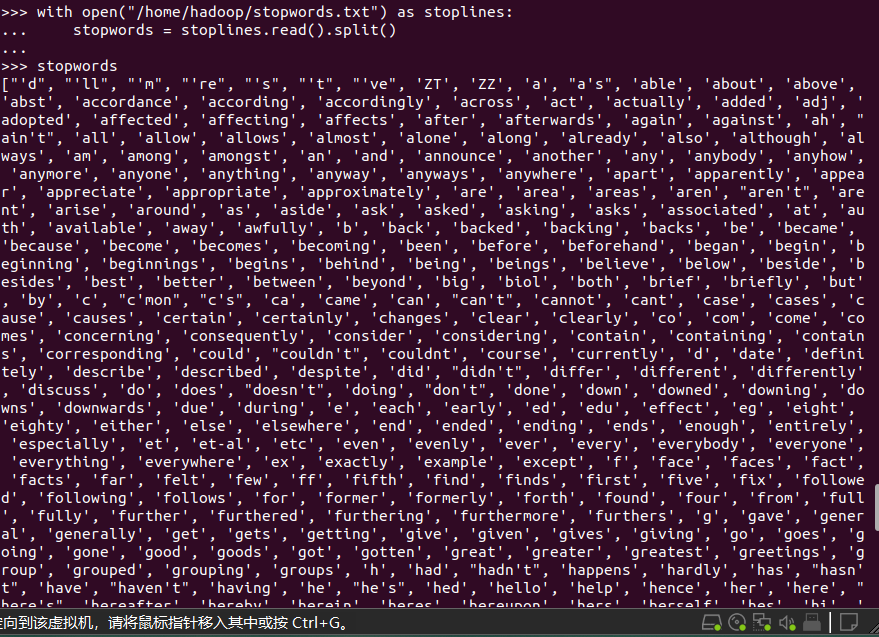
words.filter(lambda words:word not in stopwords)
word.filter(lambda x:x not in stopwords)过滤停顿词
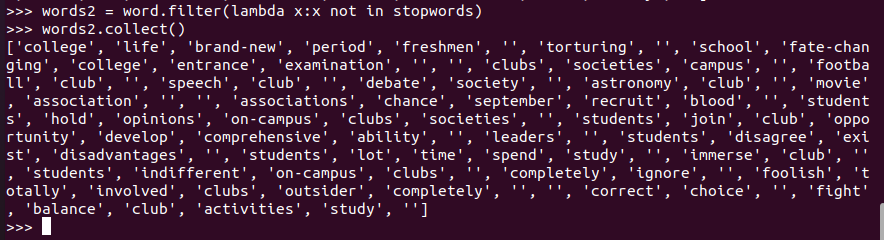
长度小于2的词filter()
word.filter(lambda x:x not in stopwords)
words2.filter(lambda x:len(x)>2) 过滤长度小于2的单词
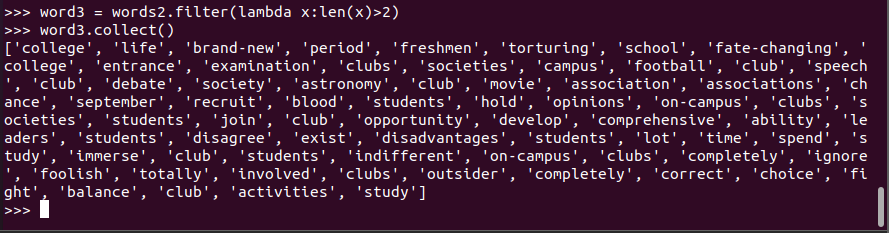
- 统计词频
word = words.map(lambda word:(word,1))
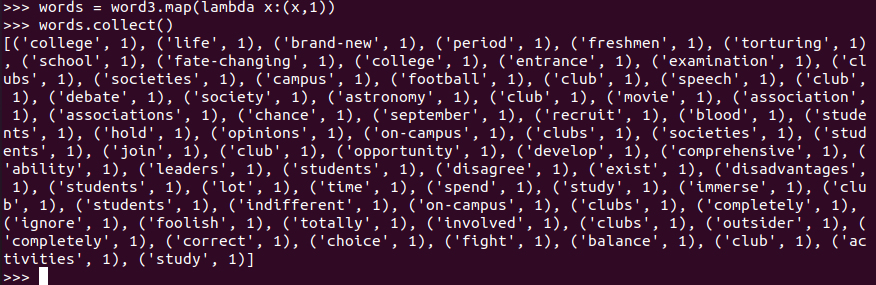
- 按词频排序
words.reduceByKey(lambda a,b:a+b)
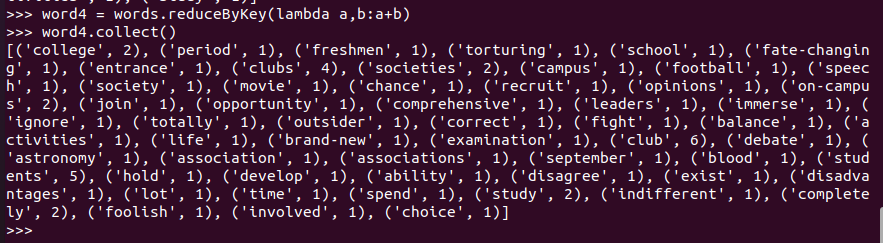
word4.sortBy(lambda x:x[1],False,1) ('students', 5) x[ 1 ]è5 False为降序,True为升序 1为处理存放的块数,默认为10块
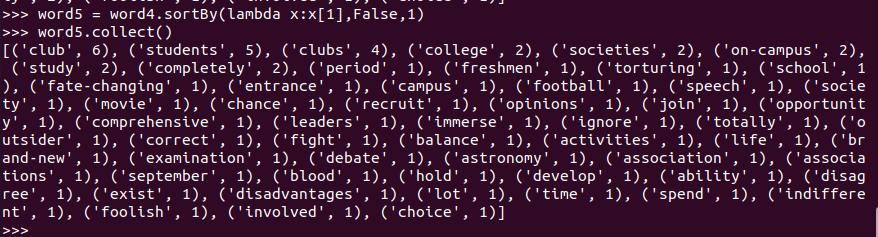
- 输出到文件
word5.saveAsTextFile("output")
- 查看结果
dfs dfs -cat /user/Hadoop/文件所在路径
B. 一句话实现:文件入文件出
C.和作业2的“二、Python编程练习:英文文本的词频统计 ”进行比较,理解Spark编程的特点,用自己的话进行表达。
RDD有RDD的方法函数,当RDD.collect()方法出来的列表形式会误认为当成RDD,执行下一命令时就会报错,说列表形式没有sortBy等之类的方法存在,Spark就是把一堆数据放到Rdd里面,通过RDD的底层方法去操作RDD然后输出成列表形式,当然这种方式肯定是比读取硬盘的速度要快,毕竟只是读取内存当中的数据。
二、求Top值
网盘下载payment.txt文件,通过RDD操作实现选出最大支付额的用户。
- 丢弃不合规范的行:
- 空行
- 少数据项
- 缺失数据
- 支付金额转换为数值型,按支付金额排序
- 取出Top3
导入文件
lines = sc.textFile('file:///home/hadoop/payment.txt')
内容按照逗号分隔
itmes = lines.map(lambda line:line.split(',')) 不使用mapfilter
看看每个行的大小
itmes.map(lambda item:len(item)).collect()
收集内容完整不为空的数据
temp=itmes.filter(lambda item:len([i for i in item if len(i)>0])==4) 注意最后不要加collect() 否则变成列表 使用take(3)收集前三个数据会报错
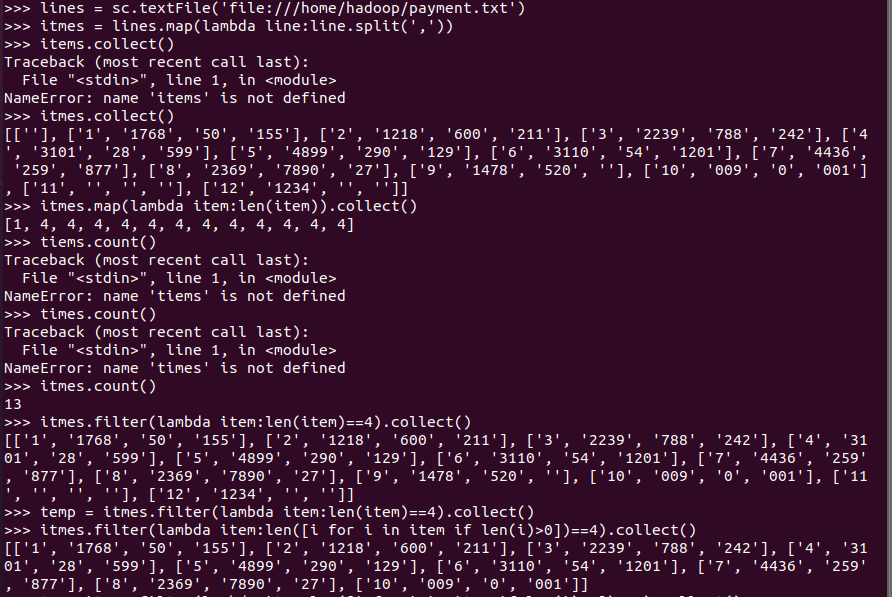
进行排序后,输出top3
top3=temp.sortBy(lambda tm:int(tm[2].False)).take(3)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号