【C&C++】C&C++性能分析与优化
C&C++性能分析与优化
一、总体原则
CPU处理时间 = 指令数*平均每条指令需要时钟周期数*每个时钟周期的时间
编译器优化:
- 软件实现是否高效
- 代码冗余识别与优化
- 实现算法优化
编译系统优化能力:
- 编译选项优化
- 现代编译技术演进
运行期效率优化:
- 内存/缓存效率:
- I-Cache/D-Cache效率优化
- 时间空间互换
- CPU指令体系:
- 矢量指令/SIMD
- 原子化指令
- 并发与锁机制:
- 线程并发冲突消减
- 无锁、免锁机制
软件性能优化的总体原则:
- 降冗余:减少指令数量
- 提效率:提升访存效率、提升指令效率、降低执行阻塞
二、CPU和内存
1. CPU体系结构
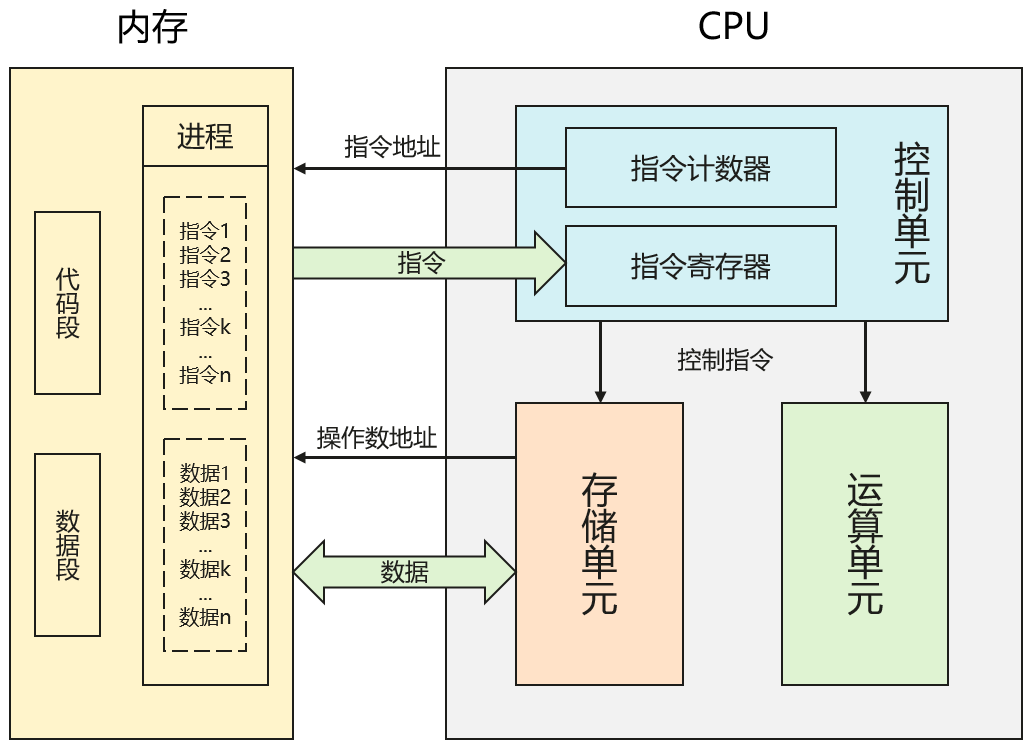
- CPU:中央处理器(Central Processing Unit),是一台计算机的运算核心和控制核心,它的功能主要是解释计算机指令以及处理计算机软件中的数据。
- 逻辑架构:从逻辑上CPU可以分为3个模块,也即控制单元(调度)、运算单元(算术运算和逻辑运算)和存储单元(传递命令、记录数据和计算结果),这三部分通过内部总线连接起来。
- 指令:CPU依靠指令来计算和控制计算机系统,一套这样的指令称之为指令集。
- 指令执行流程:一个典型的冯诺依曼架构指令执行分为五个阶段,包括取指阶段(IF)、指令译码阶段(ID)、指令执行阶段(EXE)、访存取数阶段(MEM)和写回阶段(WB)。
2. CPU流水
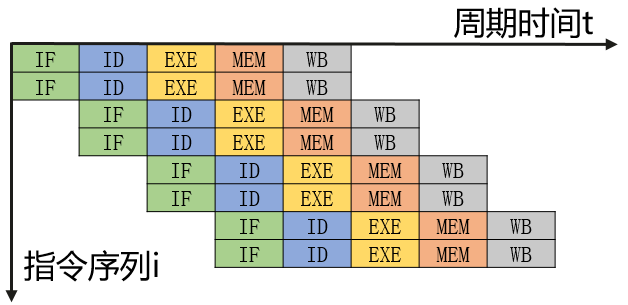
CPU流水线概述
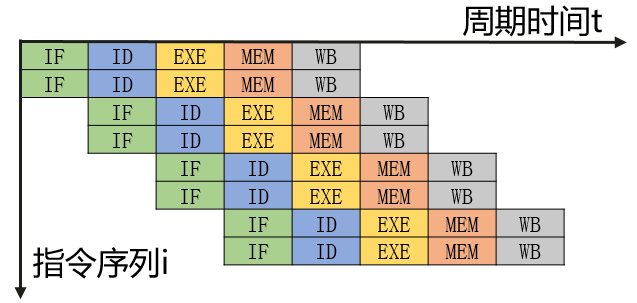
CPU流水线方式:将一条指令分成若干Stage,流水线方式前后两条指令的Stage在时间上可以重叠执行。如下图,9个时钟周期完成了5条指令,每个指令平均用时1.8个时钟周期,更理想的情况下,当流水线满载时,每个时钟周期都可以输出一条指令。流水线方式每条指令的绝对执行时间并未缩短,但却通过并行使得指令的运行速度大幅提升。
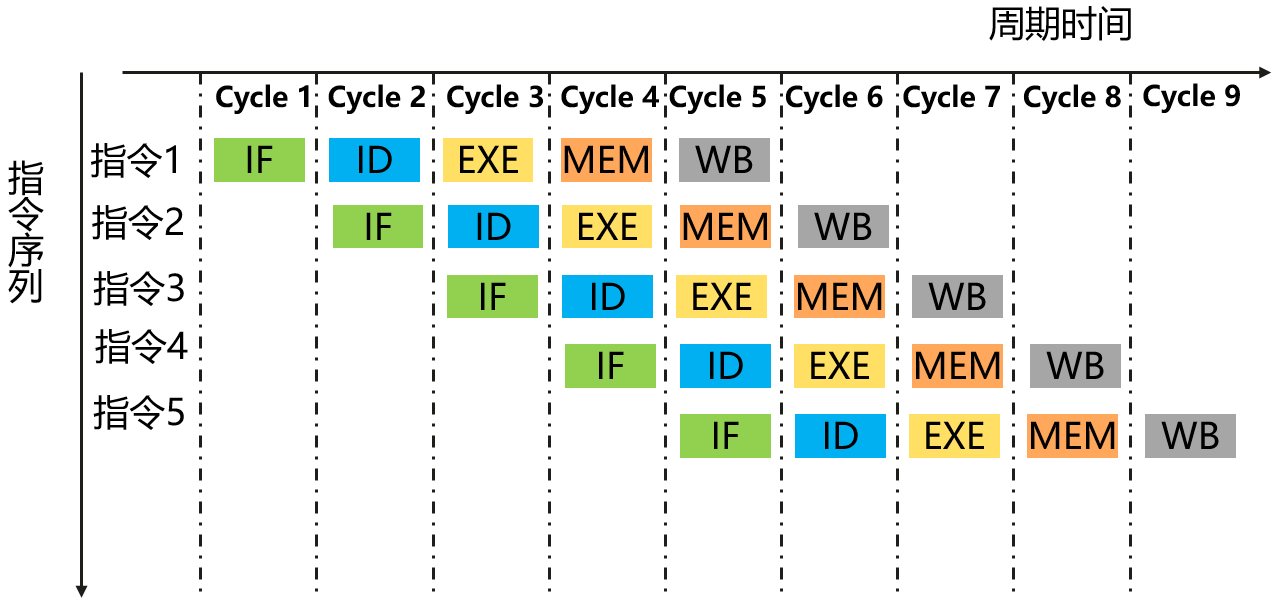
| Stage | 描述 | 硬件部件 |
|---|---|---|
| IF | 取指令 | IMem |
| ID | 指令译码 | Reg |
| EXE | 指令执行 | ALU |
| MEM | 访存取数 | DMem |
| WB | 写回 | Reg |
CPU流水线:主要问题
流水线主要问题:流水线带来CPU吞吐率大幅提高的同时,也面临着一些风险,一旦指令流水线执行乱序可能会导致无法得到正确计算结果,流水线风险包含了结构、数据和控制三类典型的风险。
-
结构冒险
也称资源冲突,指的是用不同指令争用同一部件产生的冲突,如图所示,取指和取操作数会发生访存冲突。
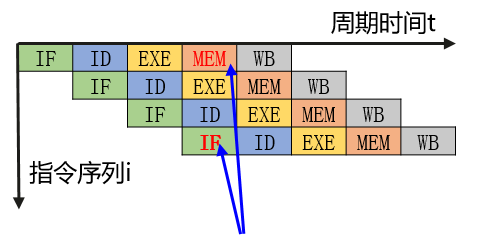
解决方式:
-
流水线完成第一条指令对数据的存储器访问时,暂停取后一条指令;
-
设置独立存储器存放操作数和指令;
-
采用指令预取技术,将指令预取到指令队列中,这样取数操作便可以独占存储器访问。
-
-
数据冒险
也称数据冲突,指的是在同一个程序中,后一条指令必须等待前一条指令执行完成才能执行后一条指令的情况,如图所示,后面的几条指令必须等候r1的计算结果
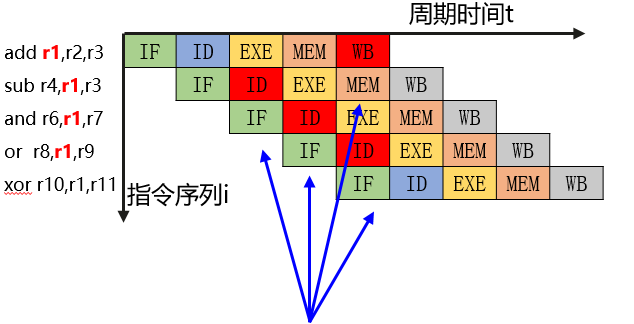
解决方式:
- 硬件阻塞(stall):把遇到数据相关的指令及其后续指令都暂停一到几个时钟周期,直到问题消失;
- 软件阻塞:在遇到数据相关的指令后续插入多个空指令“NOP”,直到问题消失 ;
- 数据旁路技术:产生结果直接送给运算单元;
- 编译优化:通过编译器调整指令顺序解决数据依赖。
-
控制冒险
指的是由转移指令而引起的流水线中断,如图所示,第三条指令会引发跳转,从而后面的流水被破坏。
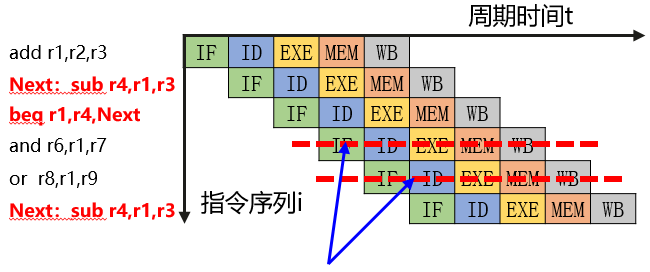
解决方式:
-
尽早判别转移是否发生,尽早生成转移目标地址;
-
预取转移成功和不成功两个控制流方向上的目标指令;
-
加快和提前形成条件码;
-
提高转移方向的猜准率。
-
多发流水线技术
-
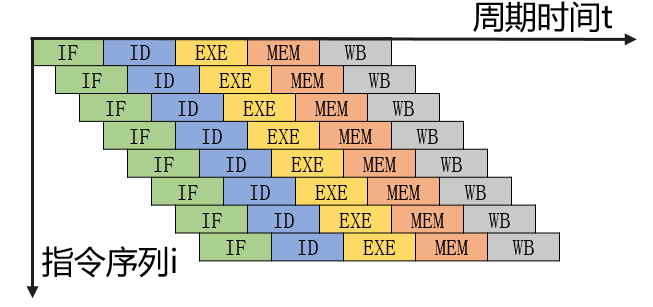
超标量技术
-
每个时钟周期内可并发多条独立指令
-
要配置多个功能部件
-
不能调整指令的执行顺序
-
通过编译优化技术,可以把可并行执行的指令搭配起来
-
-
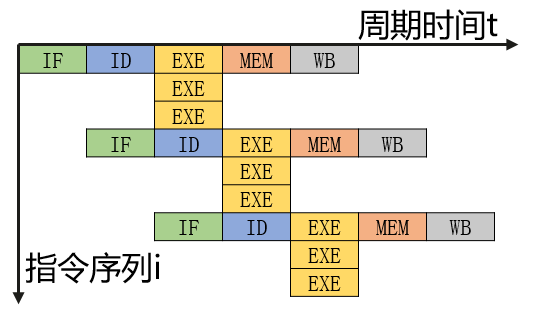
超流水技术
-
在一个时钟周期内再分段(本例3段)
-
在一个时钟周期内一个功能部件要使用多次(本例3次)
-
不能调整指令的执行顺序
-
需要通过编译程序解决优化问题
-
-
超长指令字技术
-
有编译程序挖掘出指令间潜在的并行性,将多条能并行操作的指令组合成一条
-
具有多个操作码字段的超长指令字
-
采用多个处理部件
-
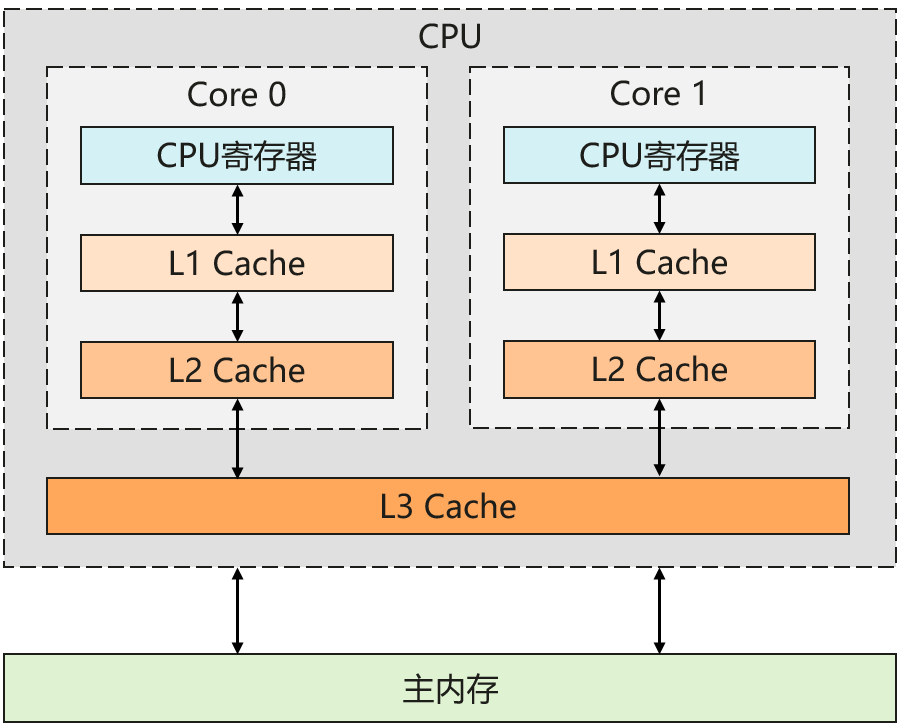
3. 分级缓存
Cache子系统
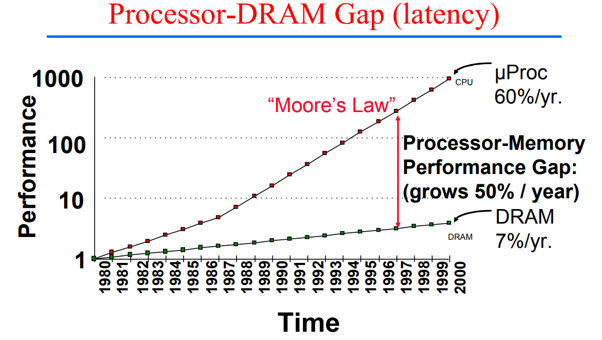
Memory Wall:限制处理器发挥的主要瓶颈
从1980到2000,CPU每年速度提升60%,主存速度只能提升7%;
Cache基本结构
CPU局部性原理:
-
时间局部性:如果一个信息项正在被访问,那么在近期它很可能还会被再次访问
-
空间局部性:如果一个存储器的位置被引用,那么将来他附近的位置也会被引
Cache Line:
内存映射到到cache的传输的最小单位就是 cache line,现在一般都是64字节,就算CPU只取一个字节,也会把这个字节所在的内存段64字节全部映射到cache中。
| 内存层次 | 访问时延 | 容量 |
|---|---|---|
| L1 | 4 Cycles | i-Cache:32KB~64KB/Core d-Cache:32KB~64KB/Core |
| L2 | 10 Cycles | 256KB ~ 1MB/Core |
| L3 | 35 ~ 45 Cycles | 512KB ~ 2MB/Core |
| 主内存 | 150 ~ 300 cycles | XX Gb |
4.Cache地址映射
Cache地址映射规则
-
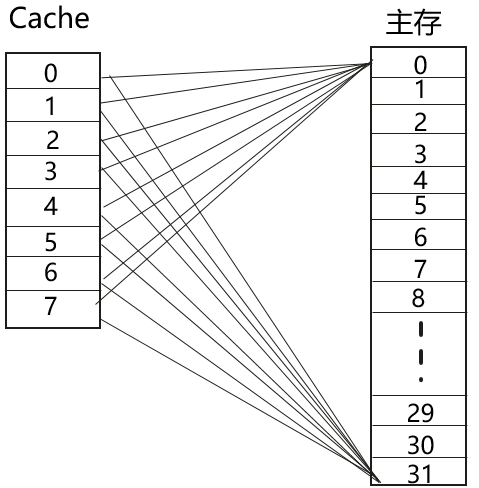
全互联映射
特点:主存中任意一个块可以映射到Cache中的任意一个行
优点:灵活性好,Cache中只要有空行,就可以调入需要的主存数据
缺点:Cache利用率不高,需要存储主存标记位。速度慢,访问Cache时需要遍历Cache Line,判断主存是否在Cache中。比较电路复杂。适用于简单系统
-
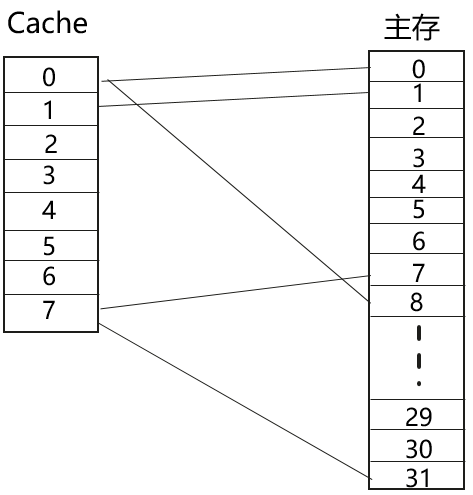
直接映射
特点:主存中的一块数据只能映射到Cache中固定行
CacheLine Idx= Block Idx Mod CacheLine Num
优点:硬件实现简单,成本低
缺点:灵活性差。如果Cache容量小,容易发生冲突,影响性能。一般使用大容量Cache
-
组相连映射
特点:全互联和直接映射的折中方案,主存和Cache分组,主存中一个组内的块数和Cache的组数相同,组间直接映射,组内全映射。
常采用的组相连结构Cache,每组内有2、4、8、16块,称为2、4、8、16路组相连。
组相连兼顾全互联和直接映射的有点,目前主流CPU均采用多路组相连的地址映射方式
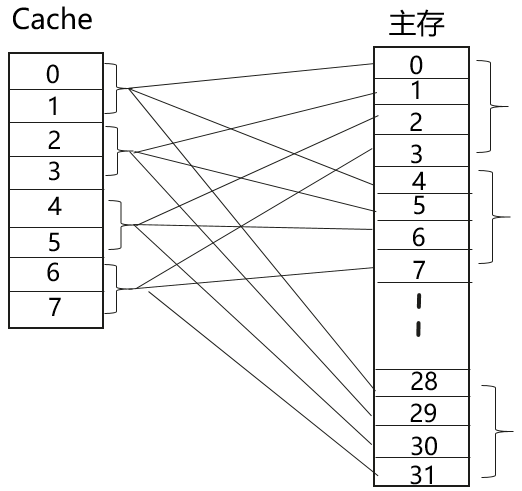
Cache获取方式
内存地址构成:
-
lblock offset: 说的是对于内存地址来说,其后block offset个字节的数据会构成一个和cache做数据交换的块,故就是cache块的大小;
-
Set index: 用来确定内存该被映射到cache里的哪一组。
-
tag: 用来在使用index选出cache组后,通过tag获取cache块位于哪一路。
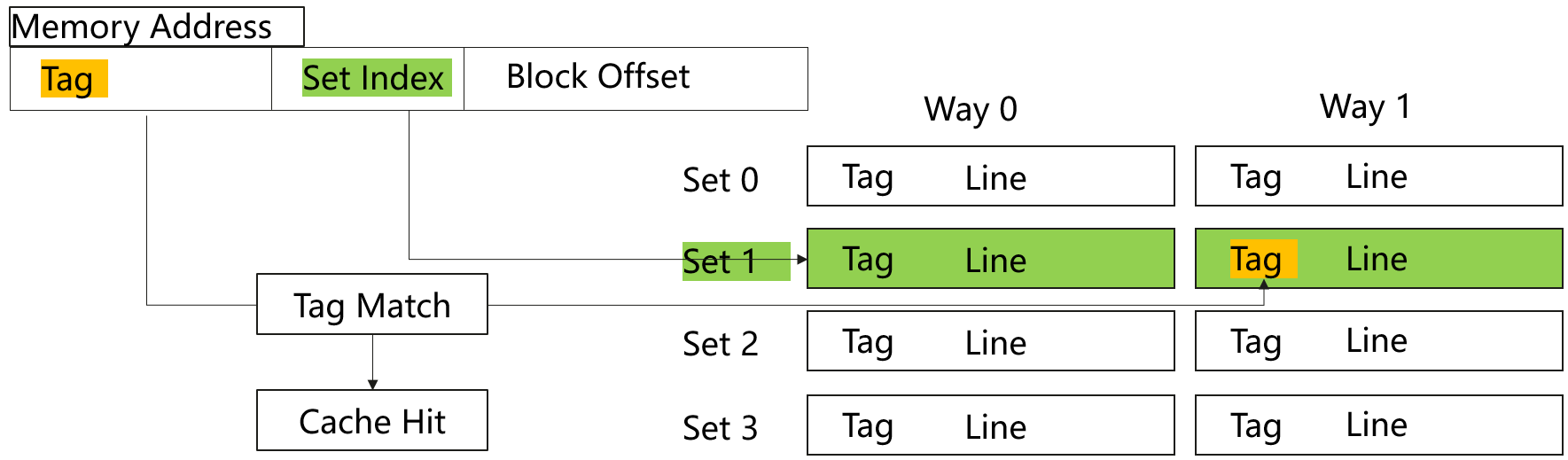
Cache更新策略
Cache容量有限,当Cache空间被占满,需要从主存加载数据到Cache时,需要选择一个Cache Line来替换。
常用的替换策略有以下几种:
-
随机算法(Rand):随机法是随机地确定替换的存储块。设置一个随机数产生器,依据所产生的随机数,确定替换块。这种方法简单、易于实现,但命中率比较低。
-
最久未使用算法(LRU, Least Recently Used):LRU法是依据各块使用的情况,总是选择那个最长时间未被使用的块替换。每块也设置一个计数器,Cache每命中一次,命中块计数器清零,其他各块计数器增1。当需要替换时,将计数值最大的块换出,这种方法比较好地反映了程序局部性规律,Cache命中率较高。
-
最不经常使用算法(LFU, Least Frequently Used):将最近一段时期内,访问次数最少的块替换出Cache。每块设置一个计数器,从0开始计数,每访问一次,计数加1,当需要替换时将计数最小的替换出去。
Cache一致性协议MESI
缓存一致性:一个物理CPU一般都会有多个物理core,每个物理core在程序运行时可以支持一个并发,利用超线程技术可以支持两个并发,每个物理core都拥有自己的L1、L2 cache,一个物理CPU上所有的物理core共享一个L3 cache。因为每个core都有自己的cache,所以一个cache line可能被映射到多个core的cache中,这就会有cache不一致的问题,如果这个时候其中一个core修改了cache line,那就会有多个cache line不一致的问题。
缓存状态:CPU中Cache Line状态,使用2bit表示。
| 状态 | 描述 | 监听任务 | 转态转换 |
|---|---|---|---|
| M 修改 (Modified) | 该Cache Line有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。 | 缓存行必须时刻监听所有试图读该缓存行相对应主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S(共享)状态之前被延迟执行。 | 当被写回主存之后,该缓存行的状态会变成独享(exclusive)状态。 |
| E 独享、互斥 (Exclusive) | 该Cache line有效,数据和内存中的数据一致,数据只存在于本Cache中。 | 缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S(共享)状态。 | 当CPU修改该缓存行中内容时,该状态可以变成Modified状态 |
| S 共享 (Shared) | 该Cache line有效,数据和内存中的数据一致,数据存在于很多Cache中。 | 缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。 | 当有一个CPU修改该缓存行时,其它CPU中该缓存行可以被作废(变成无效状态 Invalid)。 |
| I 无效 (Invalid) | 该Cache line无效。 | 无 | 无 |
MESI状态转换示意
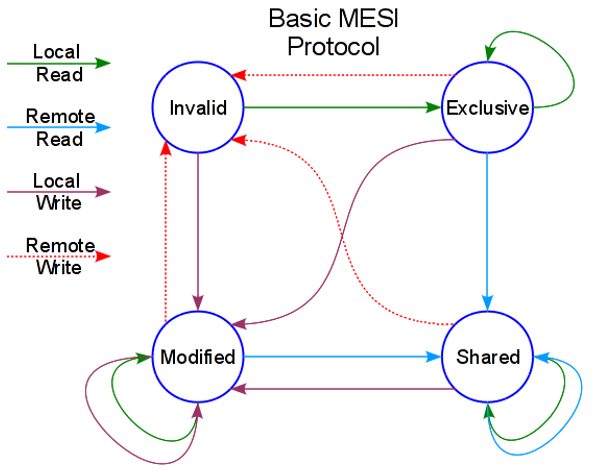
-
本地读取(Local Read):本地cache读取本地cache中的数据
-
远端读取(Remote Read):其它cache读取本地cache中的数据
-
本地写入(Local Write):本地cache将数据写入本地cache中
-
远端写入(Remote Write):其它cache将数据写入本地cache中
多个Cache Line状态关系
| 状态 | M 修改 (Modified) | E 独享、互斥 (Exclusive) | S 共享 (Shared) | I 无效 (Invalid) |
|---|---|---|---|---|
| M 修改 (Modified) | ⅹ | ⅹ | ⅹ | √ |
| E 独享、互斥 (Exclusive) | ⅹ | ⅹ | ⅹ | √ |
| S 共享 (Shared) | ⅹ | ⅹ | √ | √ |
| I 无效 (Invalid) | √ | √ | √ | √ |
举例,例如有某个变量a = 1;
Cache line处于M(修改)状态,其他Cache对此变量都是I(无效)状态
Cache line处于S(共享)状态,其他Cache对此变量可以是I(无效)状态,也可以是S(共享)状态
5.虚拟内存管理
虚拟地址空间
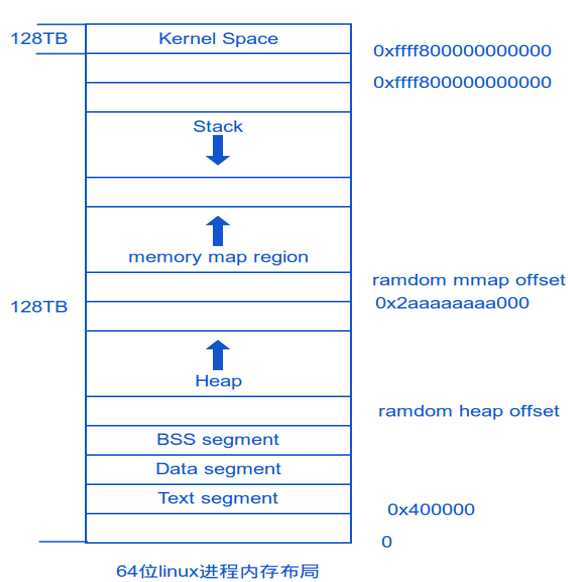
虚拟内存:内核给每个进程独立的地址空间,用户态进程不能直接操作物理内存,通过MMU进行虚拟内存和物理内存的映射。以32位系统来说,寻址空间范围为4G,最大4G虚拟地址空间,内核占用1G,理论每个进程最大可用3G。
虚机地址空间分布:
-
程序段(Text):程序代码在内存中的映射,存放函数体的二进制代码。
-
初始化过的数据(Data):已初始化的全局变量、静态变量(全局和局部)、常量数据。
-
未初始化过的数据(BSS):未初始化的全局变量和静态变量。
-
栈(Stack):存储局部、临时变量,函数调用时,存储函数的返回指针,用于控制函数的调用和返回。在程序块开始时自动分配内存,结束时自动释放内存,其操作方式类似于数据结构中的栈
-
堆(Heap):存储动态内存分配,需要程序员手工分配,手工释放
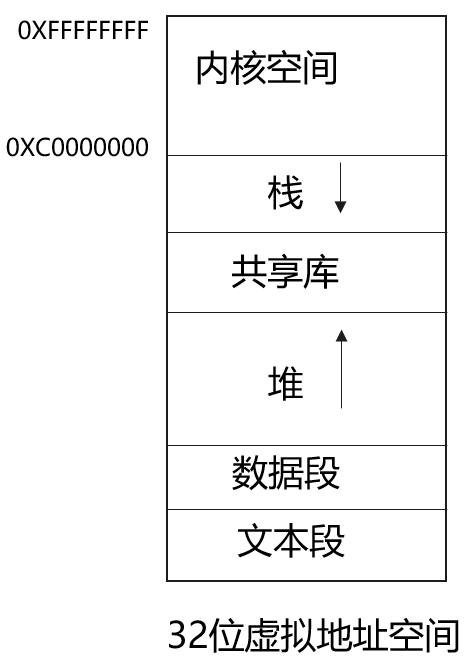
虚拟地址映射
-
一级页表:
需要内存较大,以32位系统为例,虚拟地址空间4GB。假设页大小4KB,需要410241024KB/4KB个,每个页表项4B存储,4G空间映射需要约4M大小;虚机地址空间是每个进程独立,如果系统有100个进程,则就需要400M物理内存空间。
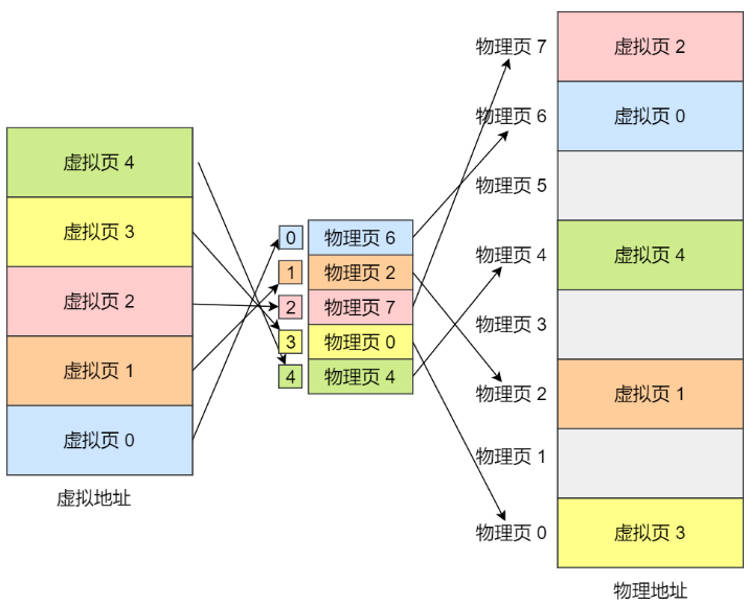
-
多级页表:
对于 64 位的系统,一般采用四级目录,页表项只有在下级页表存在记录的时候才创建,减少无效空间消耗。
PGD(Page Global Directory);PUD(Page Upper Directory);
PMD(Page Middle Directory);PTE(Page Table Entry);
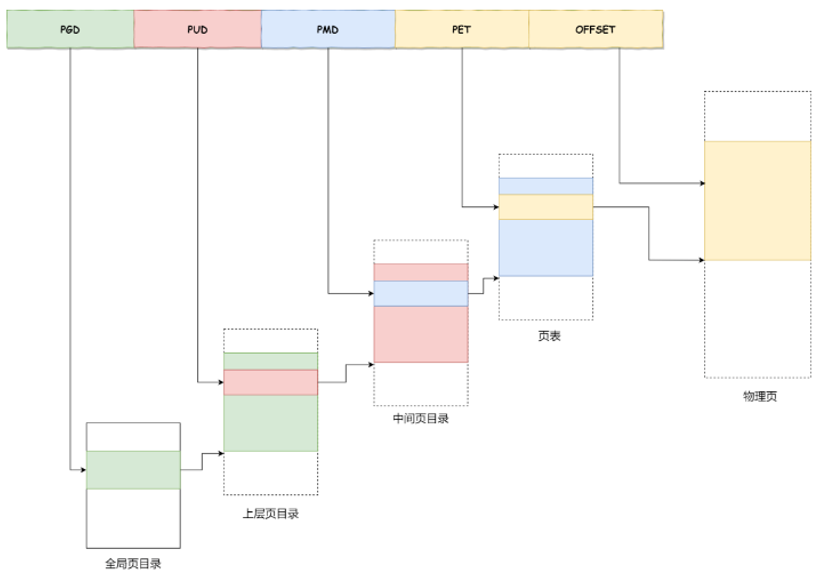
内存地址转换
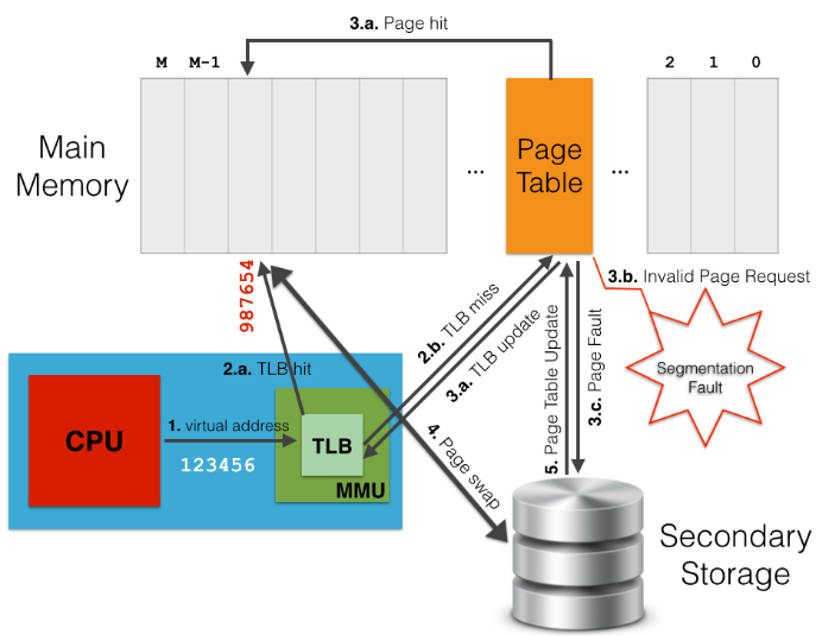
多级页表虽然解决了内存空间占用的问题,但是由于页表层级的增加,会导致从页表查询效率变差。因此引入TLB(translation lookaside buffer)用于缓存虚拟地址到物理地址的映射关系。
虚拟地址到物理地址转换的过程:
-
MMU首先从TLB获取物理地址,TLB命中的话,返回对应的物理地址;
-
如果TLB中没有找到虚拟地址对应的物理地址(TLB Miss),则从页表中获取对应的物理地址,页表命中,返回对应的物理地址,同时更新TBL。
-
页表未命中,产生Page Fault,则需要从磁盘加载数据到主存。
6. 常见性能优化手段
1)增加指令并发度
超标量技术:
-
每个时钟周期内可并发多条独立指令
-
要配置多个功能部件
-
不能调整指令的执行顺序
-
通过编译优化技术,可以把可并行执行的指令搭配起来
循环展开
int Calc(int *array, int bound)
{
int sum = 0;
for (int i = 0; i < bound; ++i) {
sum += array[i];
}
return sum;
}
循环unroll :循环迭代间并行度技术:
将循环中多个连续的指令组合到一个循环中去完成来节省工作。
减少循环的总迭代次数。
减少控制循环的指令执行的次数。
int Calc(int *array, int bound)
{
int sum = 0;
int boundOpt = (bound >> 2) << 2;
for (int j = 0; j < boundOpt; j += 4) {
sum += array[j];
sum += array[j + 1];
sum += array[j + 2];
sum += array[j + 3];
}
for (int i = boundOpt; i < bound; ++i)
{
sum += array[i];
}
return sum;
}

2) 分支预测
在计算机体系结构中,分支预测器(英语:Branch predictor)是一种数字电路,在分支指令执行结束之前猜测哪一路分支将会被执行,以提高处理器的指令流水线的性能。使用分支预测器的目的,在于改善指令流水线的流程,减少流水线停顿。
Intel分支预测处理单元:
1、Branch Target Buff(分支目标缓冲器BTB)
2、The Static Predictor(静态预测器)
BTB基本结构:
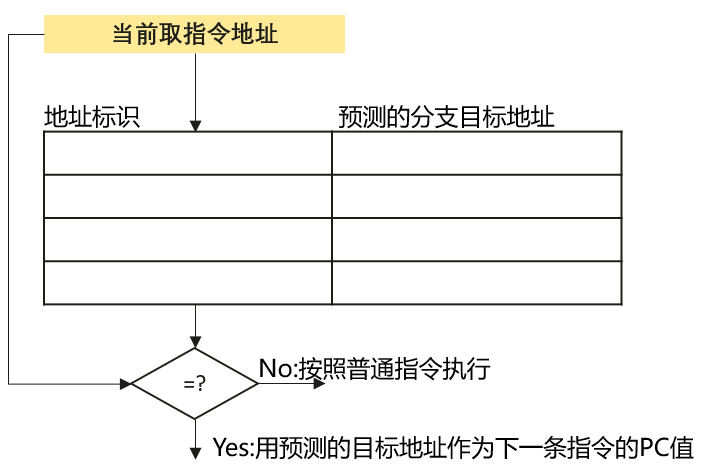
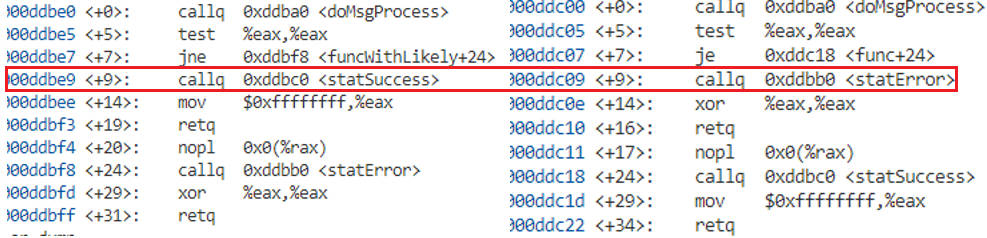
通过使用GCC的build-in function __****builtin_expect(GCC v2.96版本引入),将最有可能执行的分支告诉编译器,从而触发编译器对生成指令的顺序调整,从而尽可能发挥CPU指令预取的优势,提高指令Cache的命中率来提高程序性能。
预测成功的概率大点,使用Likely,编译器调整处理成功的汇编指令到判断条件后面,以便在指令加载的时候更好的利用局部性原理,提供指令的Cache命中率
int funcWithLikely(int msgType)
{
if (LIKELY((doMsgProcess(msgType) == 0))) {
statSuccess(msgType);
doResp(msgType);
return -1;
}
statError(msgType);
doResp(msgType);
return 0;
}

3)数据预取
CPU访问数据的时候会优先从Cache中获取数据,如果数据在Cache中不存在(Cache Miss),则需要到主存获取数据,主存的访问延时一般在150 ~ 300个Cycle,因此如果遇到Cache Miss会导致CPU流水线出现多个周期的停顿,极大影响效率。
数据预取的目的就是在下一个load & store指令到来之前,先将数据从主存调入Cache,尽量减少CacheMiss带来的延迟。
数据预取分类:
-
Software Data Prefetch(软件数据预取):
软件预取是在程序中显示地插入预取指令,以非阻塞的方式让处理器从DRAM中读取指定地址的数据进Cache。
-
Hardward Data Prefetch(硬件数据预取):
硬件预取器通过跟踪Load指令数据地址的变化规律来预测将会被访问到的内存地址,并提前从DRAM中读取这些数据到Cache。
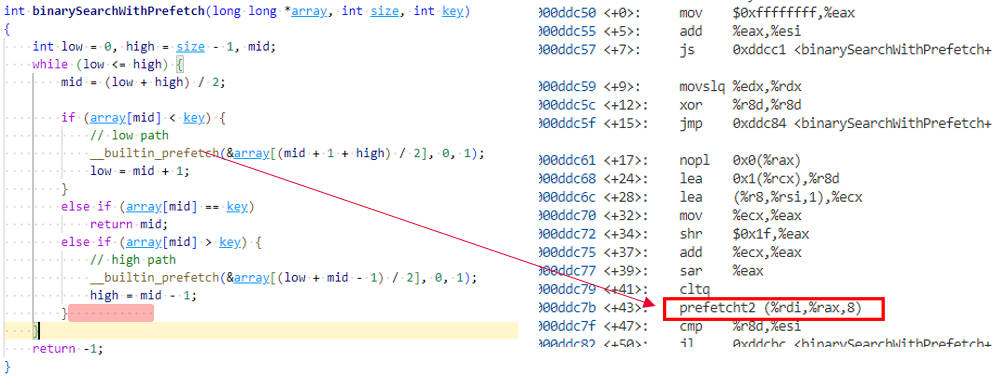
通过使用GCC的build-in function __builtin_prefetch,对数据进行手工预取,提高内存访问性能。


三、进程和线程
1. Linux进程基础
进程是用以执行用户程序的环境,包括进程地址空间内的数据和内核里的元数据(上下文)
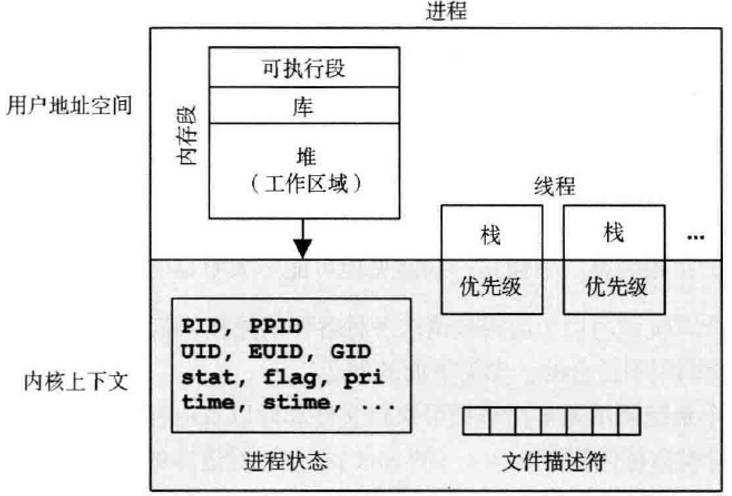
栈:存放函数参数、局部变量等,使用一级缓存
堆:动态内存,程序中分配释放,使用二级缓存
使用栈的效率相比堆要高
2. 动态链接库机制
linux 下的动态链接是通过 PLT&GOT实现。并通过GOT&PLT实现延迟绑定。
全局偏移表(GOT, Global Offset Table)用来存放外部的函数地址的数据表,
程序链接表(PLT,Procedure Link Table)存放额外代码的表
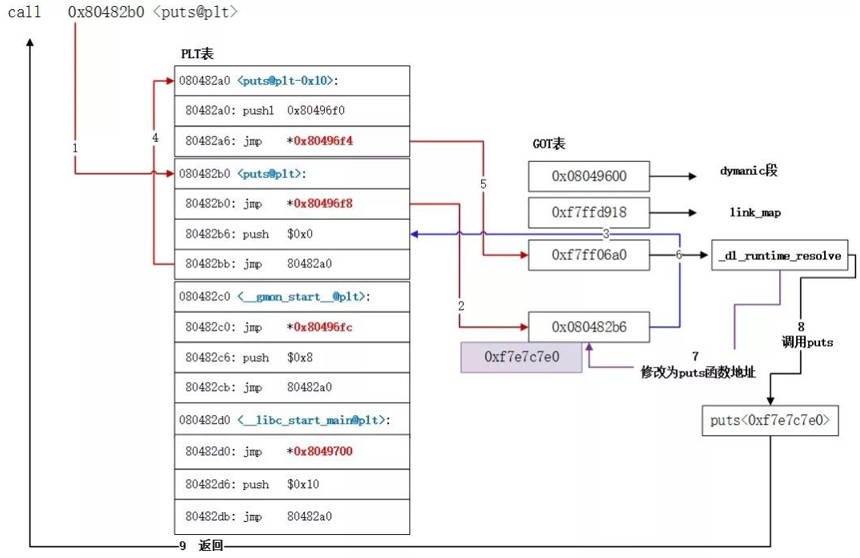
使用-fPIC时,模块内部的函数和变量均放置到PLT或GOT表中
第一,加载性能验证,创建1000个so文件,创建一个exe文件,main函数为空,测试加载时间。
第二,执行性能验证,创建1000个so文件,再创建一个exe文件,exe中的main函数分别调用每个so文件中的一个函数。使用代码如下
| 测试项 | No pic load | Pic load | Pic execute | No pic execute |
|---|---|---|---|---|
| 执行命令 | time ./no-pic-load | time ./pic-load | time ./fpic-pic | time ./fpic-no-pic |
| 时间 | 0.318s | 0.001s | 4m18.562s | 2m17.656s |
3. 多核多线程调度机制
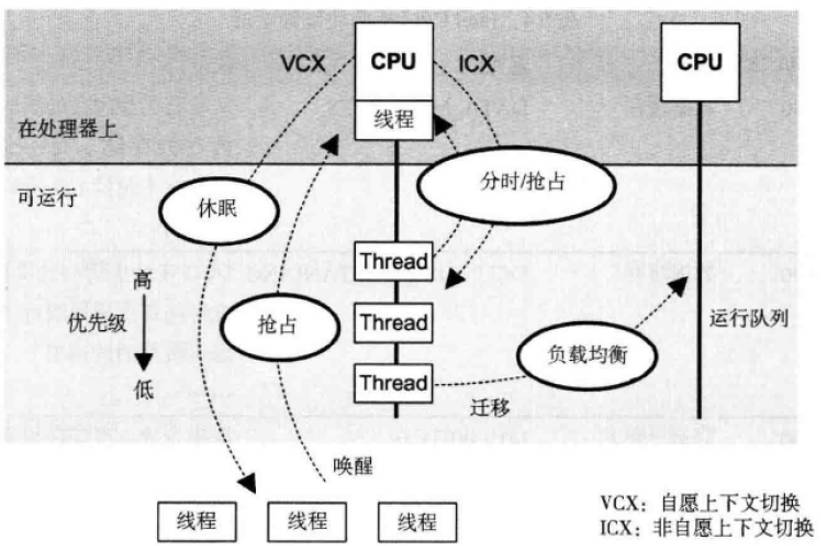
CFS调度器策略:
-
SCHED_NORMAL 分时调度,用户进程默认策略
-
SCHED_BATCH 假定任务是cpu密集的,有较小的调度开销和较大的交互时延
RT类调度器策略:
-
SCHED_FIFO 有优先级的先进先出
-
SCHED_RR FIFO的简单增强,相同的优先级有时间分片机制
4. 并发与并行
并发:一个处理器同时处理多个任务。
并行:多个处理器或者是多核的处理器同时处理多个不同的任务。
常用同步原语:
-
自旋锁
-
互斥锁
-
读写锁
优化方式:
-
正确选择锁
-
减小临界区范围
-
减少竞争
-
无锁机制
-
免锁机制
伪共享:
多线程修改互相独立的变量时,如果变量共享同一个缓存行(cache line) ,就会无意中影响彼此的性能,这就是伪共享
优化方式:
热点数据进行cache line对齐

 浙公网安备 33010602011771号
浙公网安备 33010602011771号