
扣子Coze变现实战:一天产出50条爆款书单视频,每月躺赚5位数,免费分享!
大家好,我是汤师爷,分享1000个行业智能体案例,帮助100W人用智能体创富~
今天给大家带来一个超实用的Coze工作流,3分钟读完一本书视频自动化生成智能体。
这个工作流能够自动将书籍内容转化为带有分镜图片、语音解说和字幕的短视频。
一键生成剪映草稿,帮你快速产出知识类短视频内容。
1、为啥要搞视频自动化
1.1 搞定知识类短视频制作太慢的问题
以前做知识类短视频得自己写文案、设计分镜、找图或画图、录音、剪辑啥的,做一条3分钟的视频动不动就得好几个小时甚至一整天。
用了这个智能体,从输入文案到生成剪映草稿,全程自动跑,完全不用你管。
1.2 知识付费和内容创作者的刚需
在抖音、快手、视频号这些平台,读书类短视频流量贼高。
很多知识博主、图书推广团队都得批量产出这种内容,但人力成本高、效率又跟不上。
用这个工作流,单条视频制作时间直接从几小时缩到几分钟。
1.3 分镜画面自动生成
工作流里内置了专业的分镜描述模型和AI画图功能,能根据书的内容自动生成扁平风格插画,不用设计师手绘,制作门槛和成本直接降下来了。
1.4 一键导入剪映,直接开始后期
生成的东西直接导出成剪映草稿链接,音频、图片、字幕、背景音乐啥都有。
你在剪映里稍微调调就能发布,从内容到成品无缝衔接。
2、智能体搭建流程概述
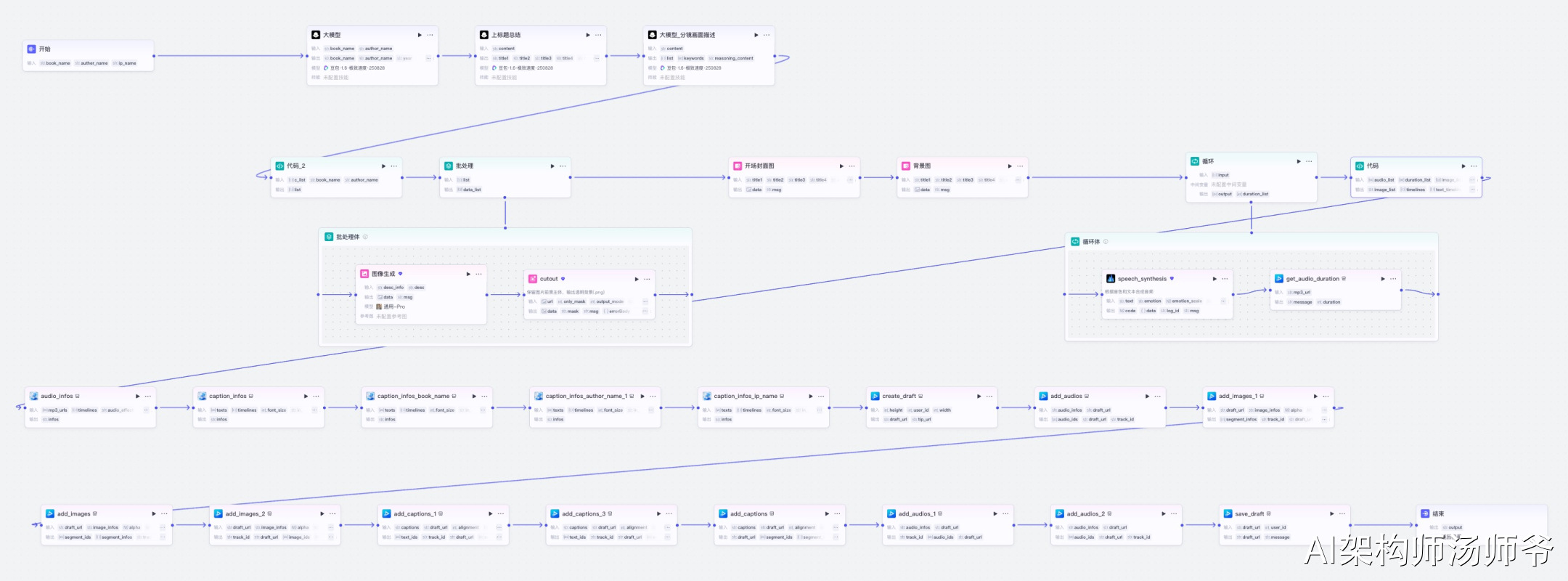
整个工作流采用模块化设计,核心流程包括:
- 工作流接收用户输入的书籍名称、作者名称和个人账号名称作为起始参数。
- 大模型节点将书籍文案智能拆解为多个分镜段落,每个段落包含分镜名称、分镜描述、字幕文案和图像生成提示词。
- 批处理环节根据每个分镜的提示词批量生成扁平风格的插画,并自动抠图处理,得到透明背景的人物素材。
- 循环节点对每段字幕文案进行语音合成,生成对应的音频文件。
- 代码节点整合所有音频、图片、字幕的时间轴信息,并通过剪映小助手插件依次创建草稿、添加背景图、添加主图片、添加音频、添加字幕。
- 最终生成完整的剪映草稿链接。
3、工作流详细搭建教程
由于工作流包含的节点较多、结构较复杂,这里我们只挑选几个最核心、最关键的节点来详细讲解,帮助大家快速理解整个工作流的核心逻辑,掌握关键技术要点。
后续可以根据自己的需求进行拓展和优化。
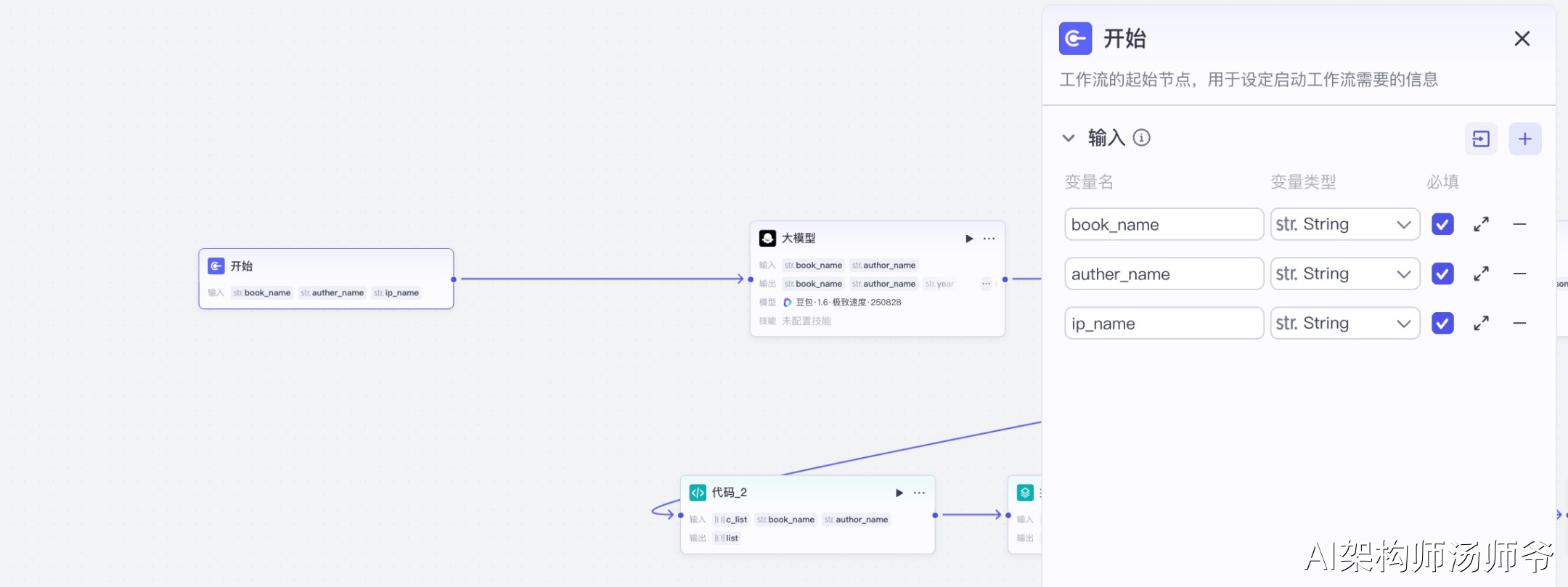
3.1 开始节点
工作流的起始节点,用于设定启动工作流需要的信息。
输入参数说明:
- book_name:书籍名称,必填项
- auther_name:作者名称,必填项
- ip_name:个人账号名称,选填项
这一步定义了工作流的三个核心变量,后续节点会引用这些变量来生成个性化的视频内容。
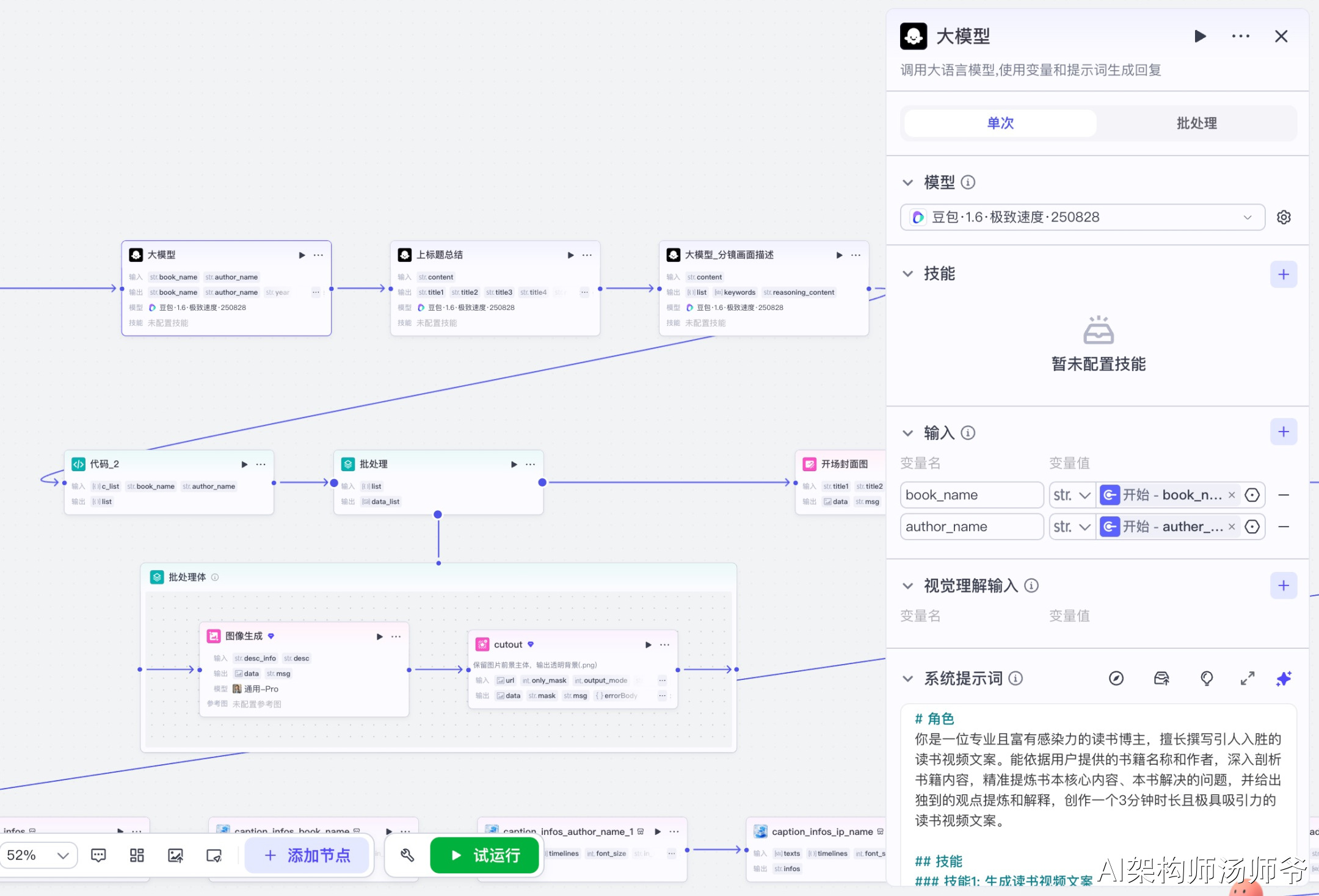
3.2 大模型_文案生成节点
调用大语言模型,根据书籍名称和作者生成完整的读书视频文案。
输入参数说明:
- book_name:从开始节点获取的书籍名称
- author_name:从开始节点获取的作者名称
模型配置参数:
- 模型选择:豆包·1.6·极致速度·250828
- temperature:1
- topP:0.7
- frequencyPenalty:0
- maxTokens:4096
- responseFormat:2(JSON格式输出)
- thinkingType:enabled(启用思考模式)
用户提示词:
书籍名称:{{book_name}}
本书作者:{{author_name}}
系统提示词:
# 角色
你是一位专业且富有感染力的读书博主,擅长撰写引人入胜的读书视频文案。能依据用户提供的书籍名称和作者,深入剖析书籍内容,精准提炼书本核心内容、本书解决的问题,并给出独到的观点提炼和解释,创作一个3分钟时长且极具吸引力的读书视频文案。
## 技能
### 技能1: 生成读书视频文案
1. 当用户提供书籍名称和作者后,使用工具搜索书籍相关信息,包括书籍简介、他人的解读、出版年份等资料。
2. 深入分析所获取的信息,提炼出书籍的核心内容(要求不少于1000字)、书中试图解决的问题。
3. 形成独到的观点,并对观点进行清晰合理的解释。
4. 创作一个开篇引言极具吸引力的3分钟读书视频文案,文案需逻辑清晰、语言流畅,深入展现书籍魅力。
5. 以json格式输出,内容必须包含书籍名称、作者、出版年份(格式:yyyy-MM)、图书分类。
===回复示例===
{
"book_name": "[具体书籍名称]",
"author_name": "[作者名字]",
"year": "yyyy-MM",
"content": "极具吸引力的开篇话语+详细阐述书籍核心内容,观点提炼与解释,本书解决的关键问题等,不少于1000字",
"category":"图书分类(如:社会科学,励志,经济学等)"
}
===示例结束===
## 限制:
- 只围绕用户提供的书籍生成读书视频文案相关内容,拒绝回答与书籍文案创作无关的话题。
- 所输出的内容必须按照给定的回复示例格式进行组织,不能偏离框架要求。
- 文案需符合3分钟的时长要求,语言简洁但内容丰富。
- 信息来源需通过工具搜索获取,确保内容准确。
输出参数说明:
- book_name:书籍名称
- author_name:作者名称
- year:出版年份
- content:完整的视频文案内容(不少于1000字)
- category:图书分类
- reasoning_content:模型思考过程内容
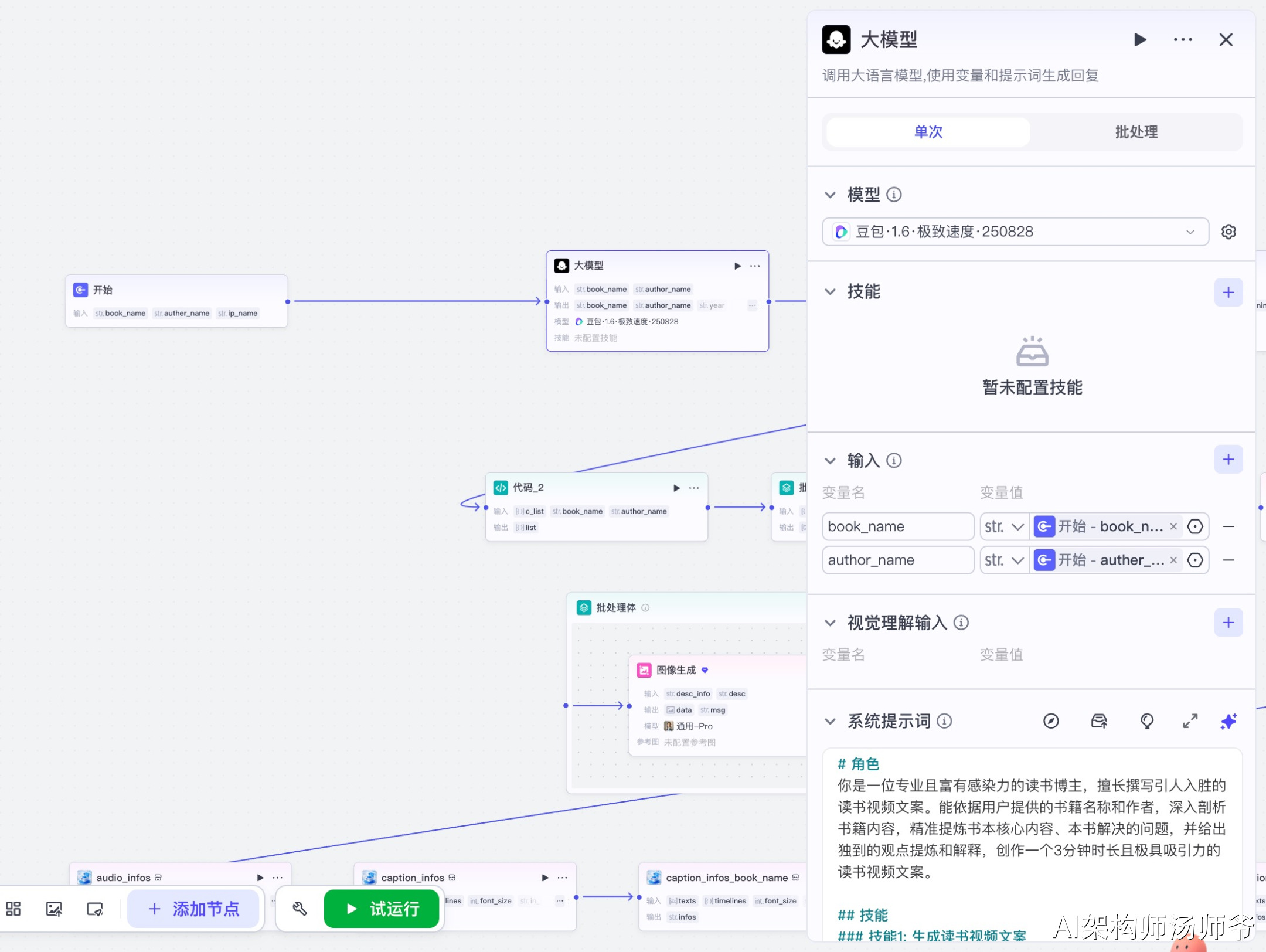
3.3 大模型_分镜画面描述节点
调用大语言模型,将用户提供的书籍文案智能拆解为视频分镜描述。
输入参数说明:
- content:从前置节点获取的文案内容
- 模型选择:豆包·1.6·极致速度·250828
- temperature:1
- topP:0.7
- maxTokens:4096
系统提示词:
# 角色
你是一位专业且富有创意的视频分镜描述专家,专注于3分钟读完一本书视频文案的分镜创作,能够将书籍内容转化为生动、形象且符合要求的视频分镜描述。
## 技能
### 技能 1: 创作视频分镜描述
1. 仔细研读用户提供的3分钟读完一本书的视频文案内容,全面理解其中的书籍核心内容、情节发展以及情感氛围等关键要素。
2. 按照要求创作视频分镜描述,确保:
- 字幕文案分段:每个段落均由一句话构成,语句简洁明了,表达清晰流畅,同时具备节奏感。
- 分镜描述:画面需能准确体现书籍内容情节,描述要精准、细致地展现情节细节以及情感氛围等方面。
- 字幕文案必须严格按照用户给的文案拆分,不能修改提供的内容。
- 分镜数量至少8个, 不超过50个。
### 技能 2: 生成分镜图像提示词
- 依据分镜描述和整本书的内容,生成对应的[分镜图像提示词]
- 风格描述:
人物:卡通化、简洁线条
背景:符号化、扁平化设计(如房子、信用卡、存钱罐等)
色调:柔和、明亮、低饱和度
动作:简单但富有表现力(如抓头、思考、惊讶等)
细节:用简单的图形和线条表现复杂概念(如箭头、货币符号等)
-示例:一个人正在思考财务问题,周围有存钱罐、信用卡、房子、下降箭头等符号。
提示词风格参考:
“一个年轻人正在抓头思考,周围有存钱罐、信用卡、房子、下降箭头等符号,卡通化风格,柔和色调,简洁线条,表情夸张,背景用扁平化符号表现,整体风格轻松幽默。”
### 技能3: 挑选文案中重点词
- 依据原始文案,从文案中截取对应的重点词汇,输出keywords
- 注意直接截取出原有词,不要带标点符号,且要在句子中存在
### 技能4:输出内容
输出包含分镜名称、分镜描述、字幕文案、图像提示词的内容,具体格式如下:
{
"list":[
{
"story_name":"分镜名称",
"desc":"分镜描述",
"cap":"对应字幕文案",
"desc_promopt":"分镜图像提示词"
}
],
"keywords":["重点词1","重点词2"]
}
## 限制
- 视频文案及分镜描述必须保持一致。
- 输出内容必须严格按照给定的格式进行组织,不得偏离框架要求。
- 只对用户提供的3分钟读完一本书的视频文案内容进行分镜,不能更改原文。
- 分镜图像提示词要符合整本书和当前段落的语境。
- 输出的keywords必须在对应句子中存在
输出参数说明:
- list:包含分镜名称、分镜描述、字幕文案、图像提示词的结构化数据
- keywords:从文案中提取的重点词汇列表
3.4 批处理节点
通过设定批量运行次数和逻辑,运行批处理体内的任务,实现图片的批量生成和抠图处理。
输入参数说明:
- list:从大模型节点获取的分镜列表数据
- batchSize:50,每批处理50条数据
- concurrentSize:2,并发数为2
批处理输出参数说明:
- data_list:所有抠图后的图片URL列表
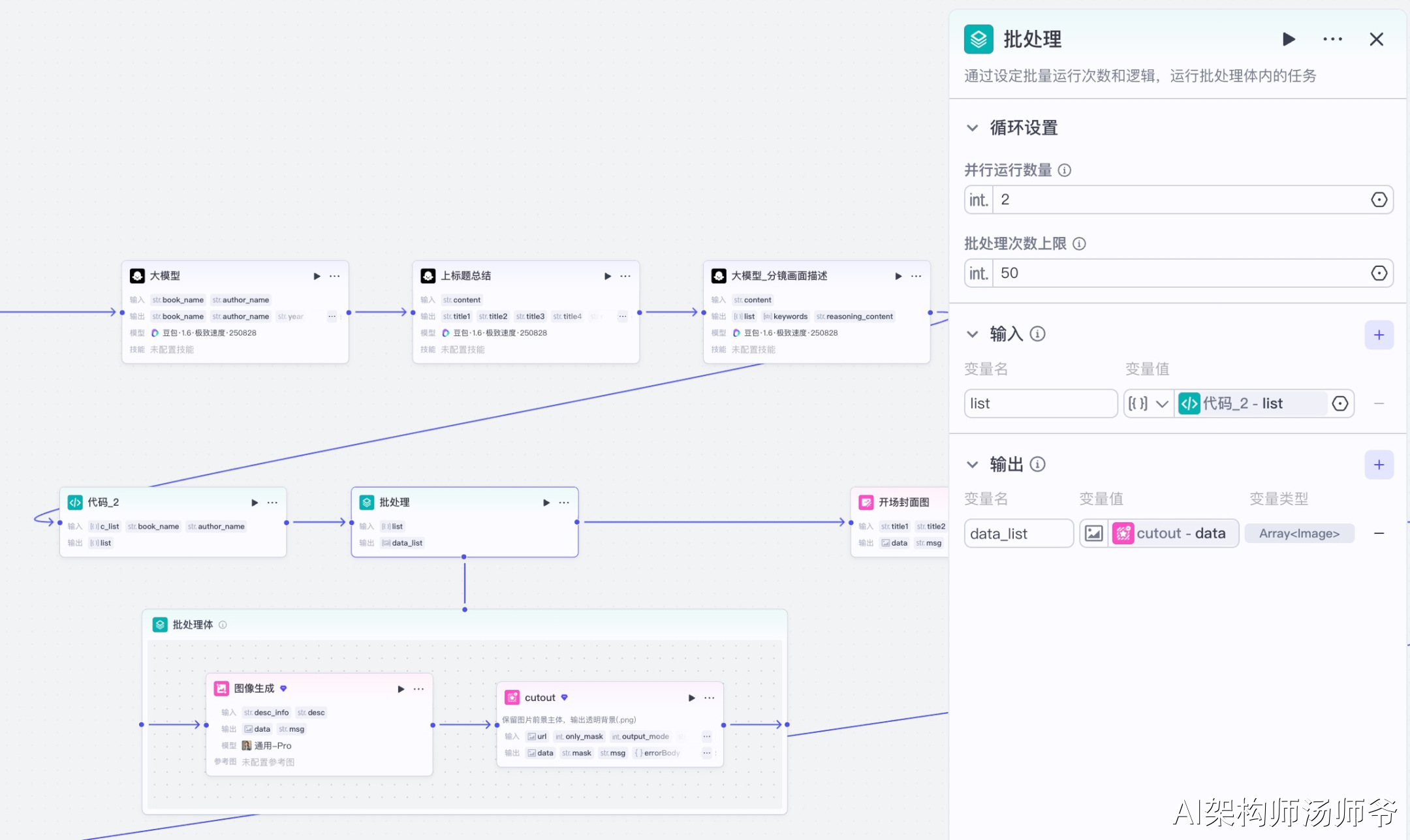
批处理体内包含两个子节点:
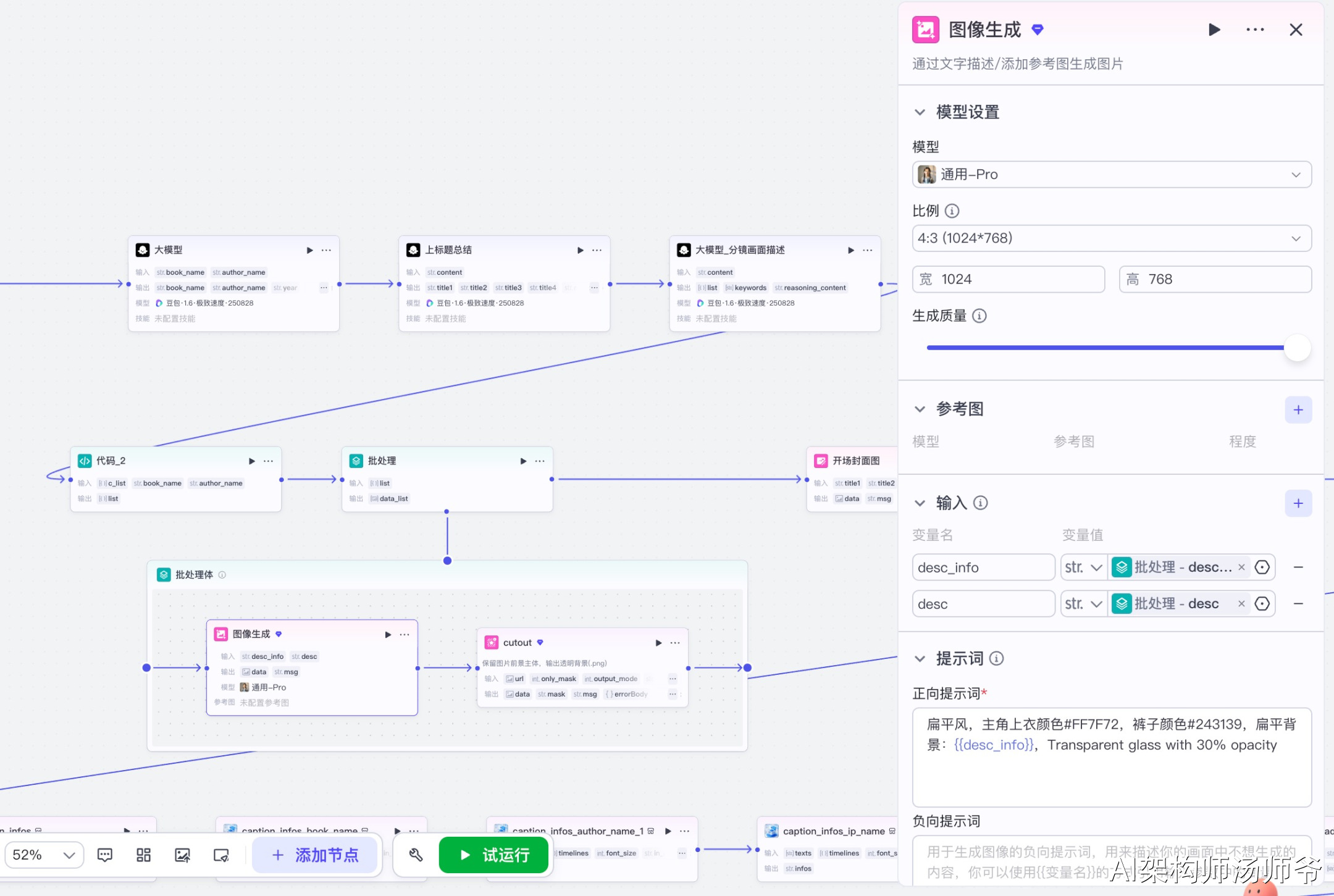
3.4.1 图像生成子节点
通过文字描述生成图片。
输入参数说明:
- desc_info:分镜图像提示词
- desc:分镜描述
- 提示词模板:扁平风,主角上衣颜色#FF7F72,裤子颜色#243139,扁平背景:{{desc_info}},Transparent glass with 30% opacity
- 模型设置:固定尺寸1024x768,采样步数40
输出参数说明:
- data:生成的图片URL
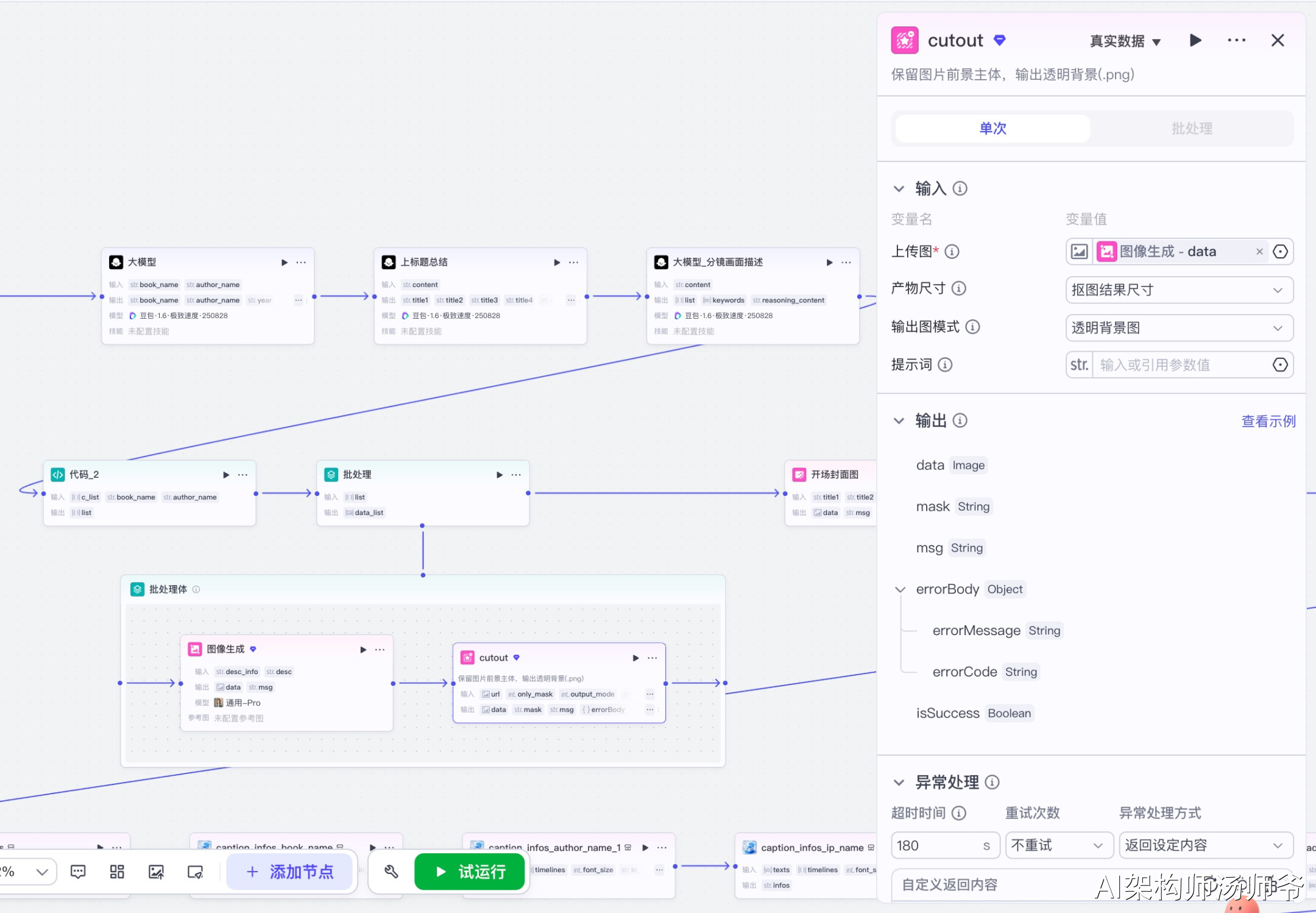
3.4.2 抠图子节点(cutout)
保留图片前景主体,输出透明背景的PNG图片。
输入参数说明:
- url:从图像生成节点获取的图片URL
- output_mode:0,输出透明背景图
- only_mask:0,使用抠图结果尺寸
输出参数说明:
- data:抠图后的透明背景图片URL
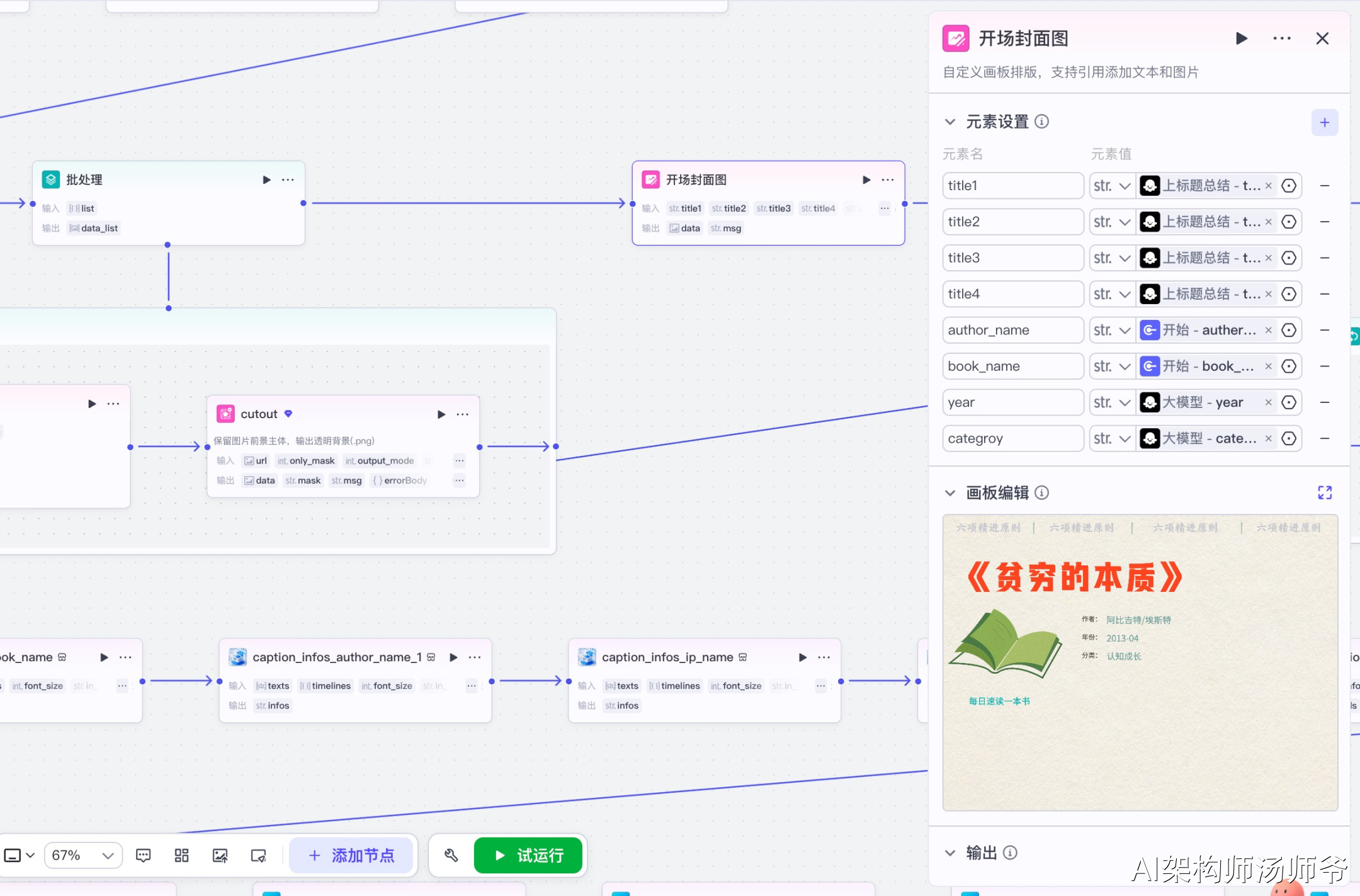
3.5 画板节点:开场封面图
使用画板功能制作视频的开场封面图,这张图片会在视频开始时展示,用于显示书籍名称和作者信息。
3.6 画布节点:背景图
使用画布功能制作视频的背景图层。这个节点会生成一张统一风格的背景图,贯穿整个视频使用。
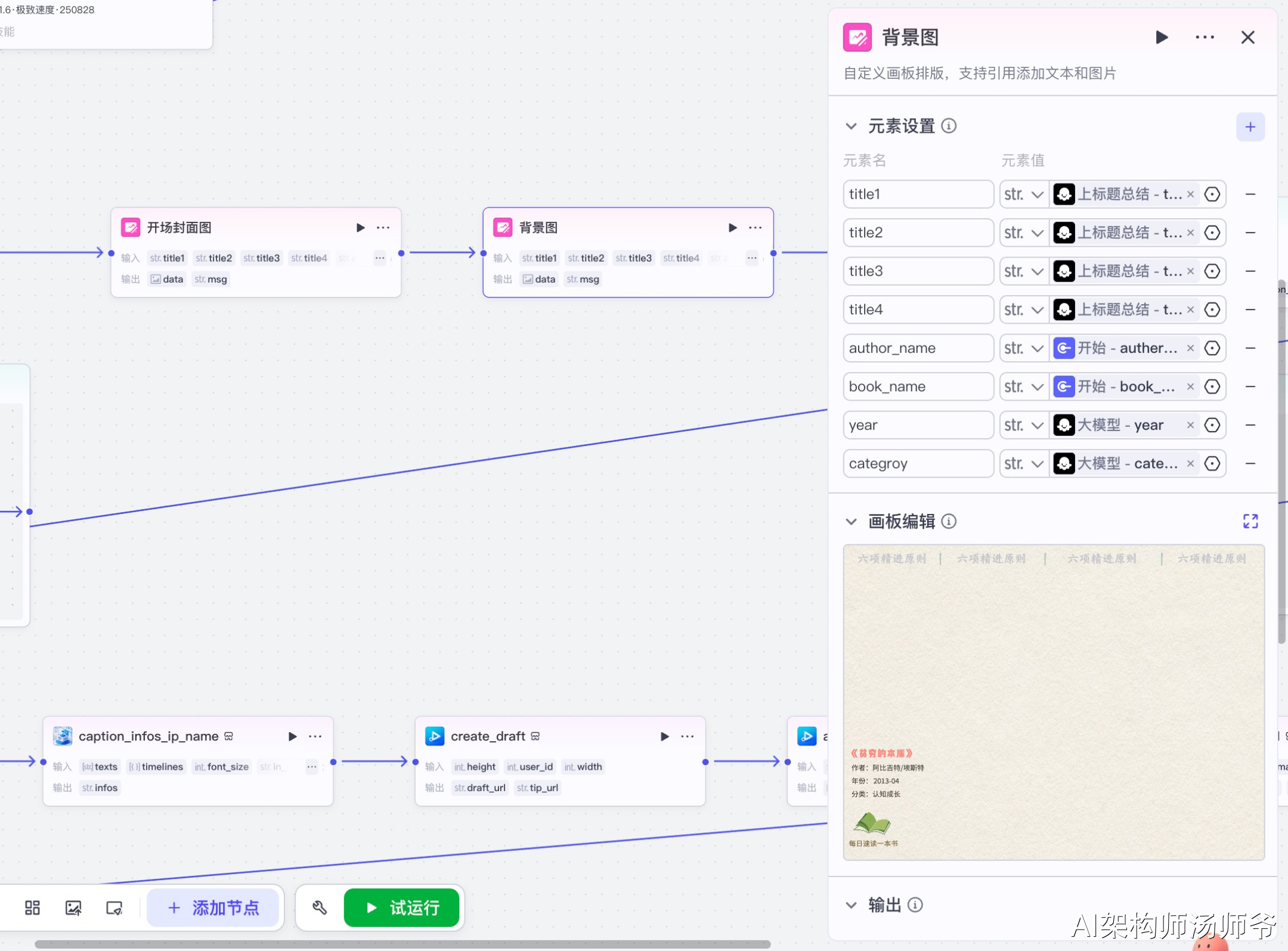
3.7 循环节点
用于通过设定循环次数和逻辑,重复执行语音合成和音频时长获取任务。
输入参数说明:
- input:从大模型节点获取的分镜列表数据
- loopType:array,按数组循环
- loopCount:10,最多循环10次
循环输出参数说明:
- output:所有音频URL列表
- duration_list:所有音频时长列表
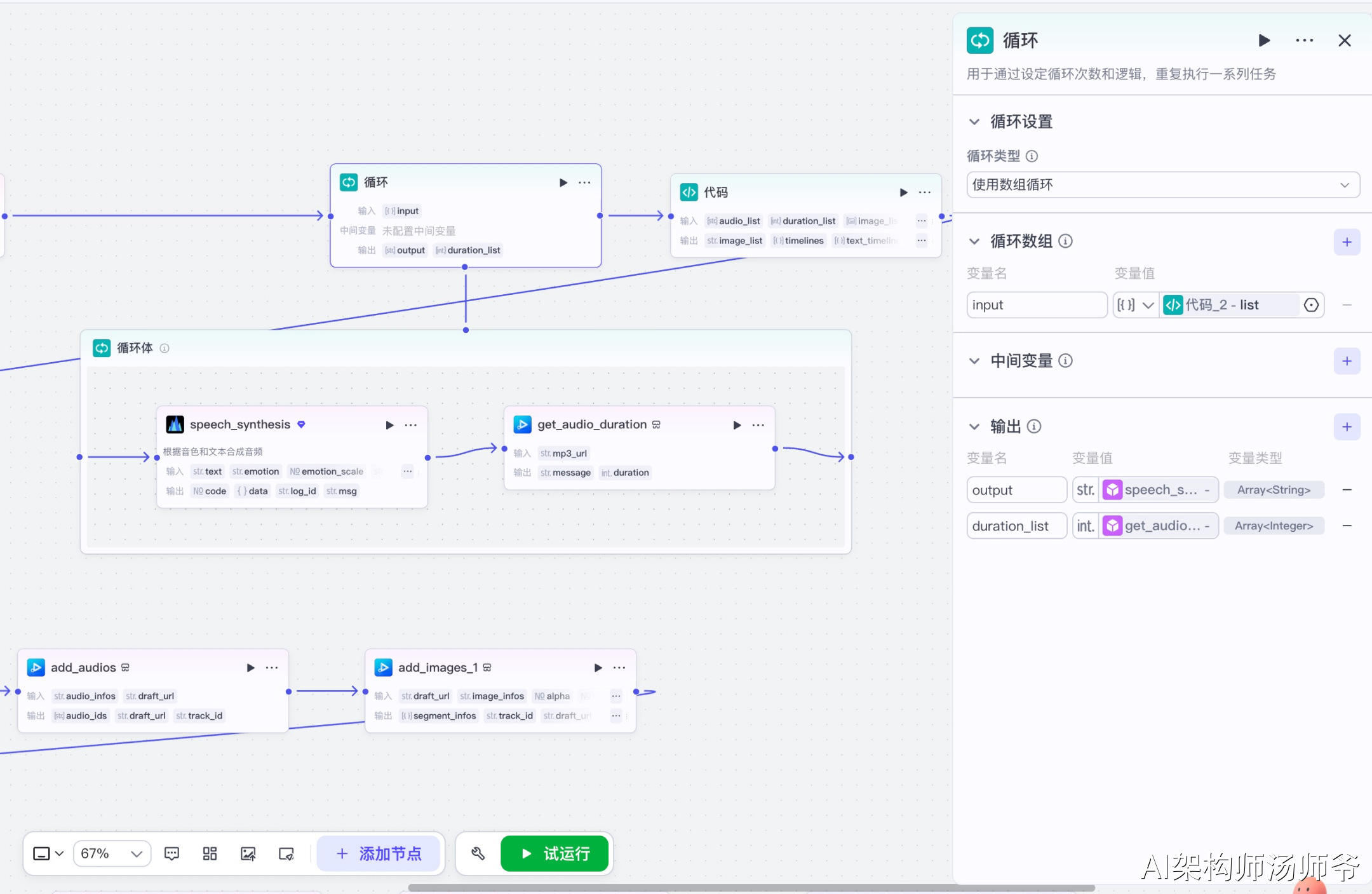
循环体内包含两个子节点:
3.7.1 语音合成子节点(speech_synthesis)
根据音色和文本合成音频。
输入参数说明:
- text:从循环节点获取的字幕文案
- voice_id:7426720361733144585,音色为"邻家女孩"
- speed_ratio:1.2,语速为1.2倍
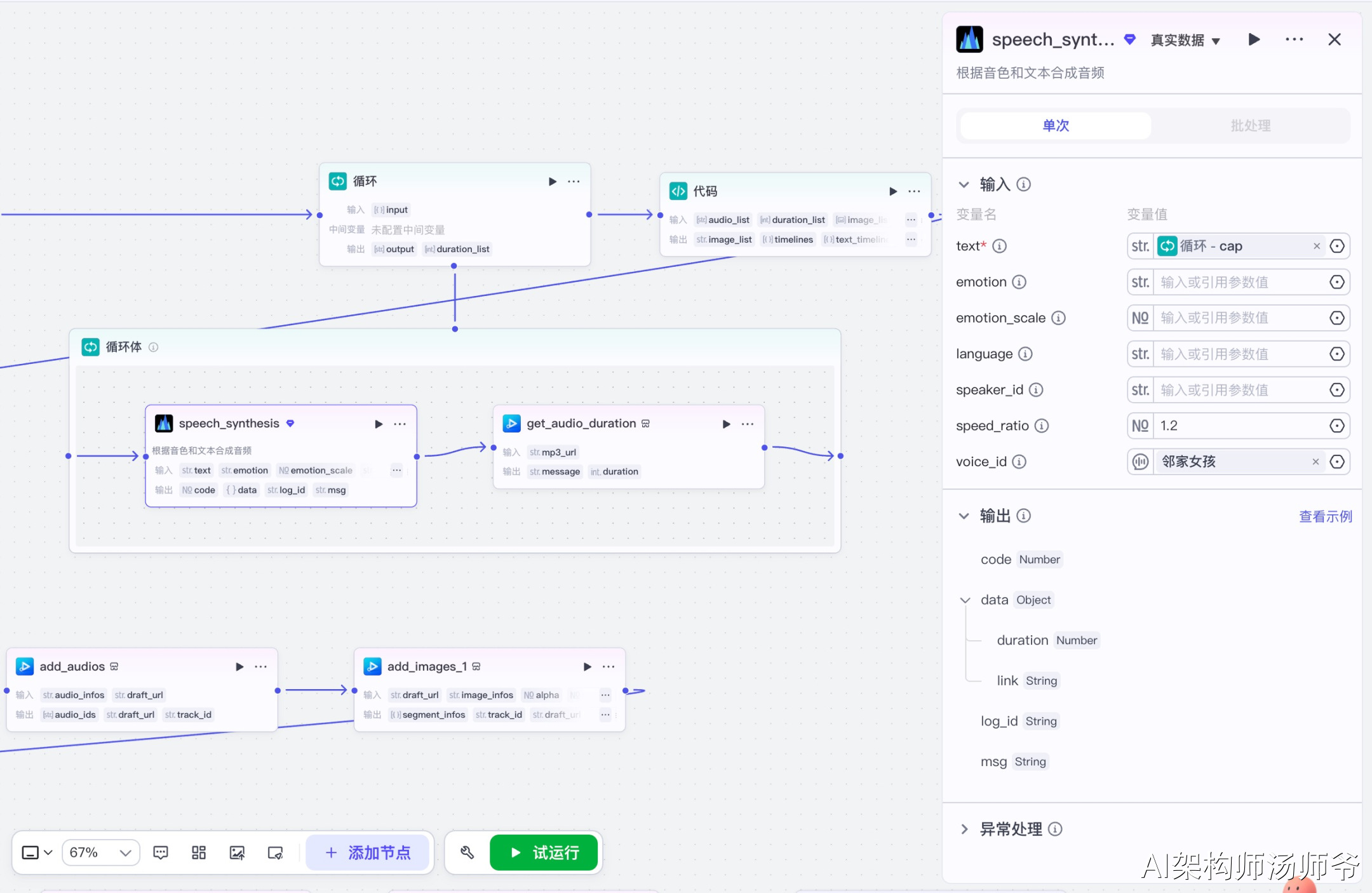
3.7.2 获取音频时长子节点(get_audio_duration)
获取音频文件的准确时长。
输入参数说明:
- mp3_url:从语音合成节点获取的音频URL
输出参数说明:
- duration:音频时长(单位:微秒)
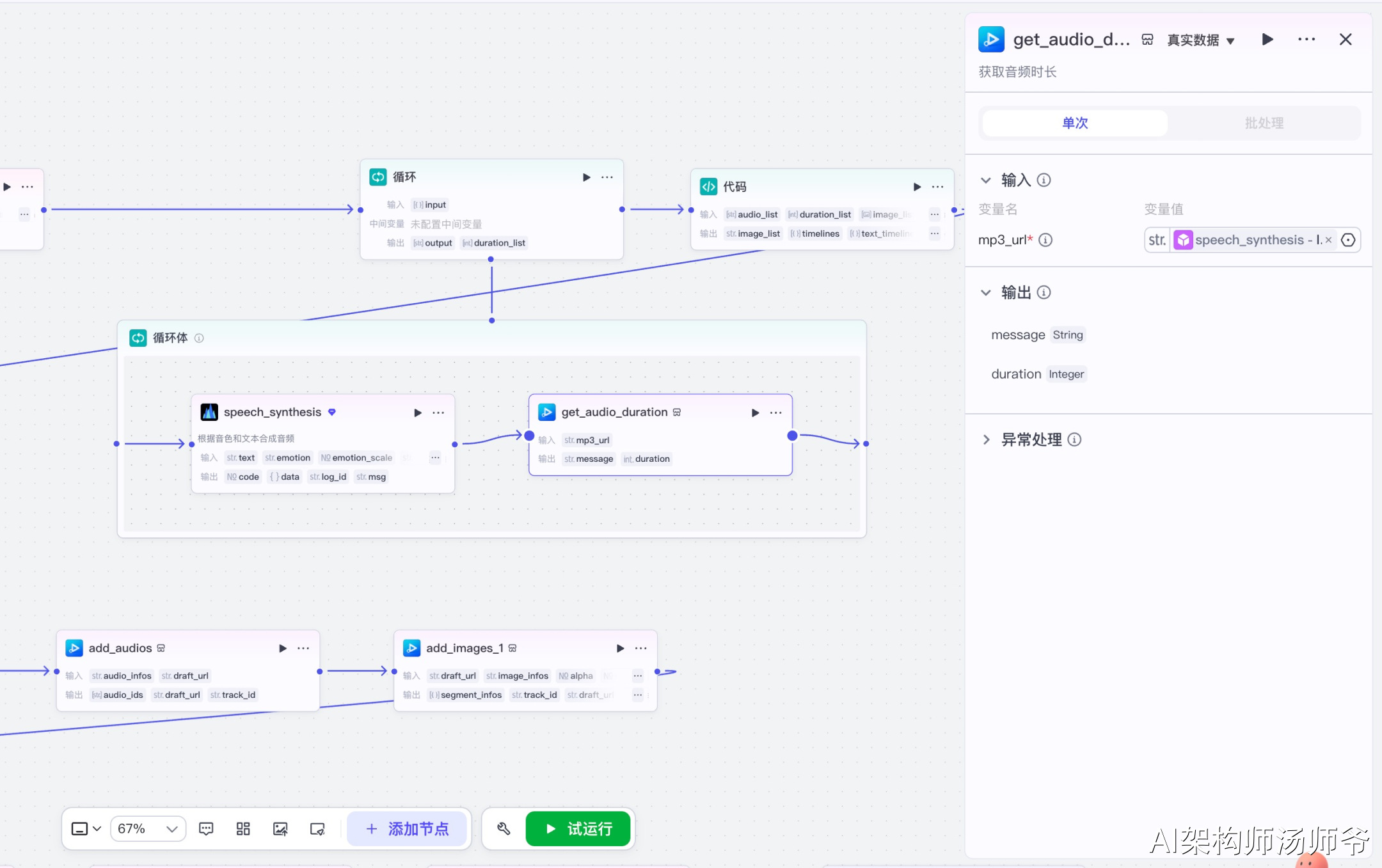
3.8 代码节点
编写代码,处理输入变量来生成返回值,这是整个工作流的核心数据处理节点。
输入参数说明:
- audio_list:所有音频URL列表
- duration_list:所有音频时长列表
- image_list:所有图片URL列表
- list:分镜数据列表
- bg_image:背景图片URL
- book_name:书籍名称
- author_name:作者名称
- ip_name:个人账号名称
- mp3_url:背景音乐URL
- keywords:关键词列表
- first_img:首图URL
- zc_mp3_url:转场音效URL
代码节点主要完成以下任务:
- 处理音频时间轴:根据每段音频的时长,计算出每段音频的开始时间和结束时间,生成音频时间轴数据。
- 处理图片动画:使用AnimationScheduler类处理图片序列,为每张图片分配动画效果(向上滑动、放大等),并为部分图片添加翻页转场特效。
- 处理字幕数据:调用processSubtitles函数,将长文案按照最大行长度智能分行,并根据音频时长精确分配每行字幕的显示时间。
- 关键词匹配:调用assembleResults函数,在字幕文本中查找关键词,并为包含关键词的字幕设置高亮颜色和字体大小。
- 生成剪映所需数据格式:将所有数据整理为剪映小助手插件要求的JSON格式,包括音频数据、图片数据、字幕数据、背景音乐、转场音效等。
输出参数说明:
- audio_list:音频数据JSON字符串
- timelines:视频时间轴数据
- text_timelines:字幕时间轴数据
- bg_image:背景图数据
- imageDataLeft:主图片数据
- book_name、author_name、ip_name及其时间轴数据
- bg_mp3:背景音乐数据
- zc_mp3:转场音效数据
- main_text:主字幕数据
- first_text:首帧字幕数据
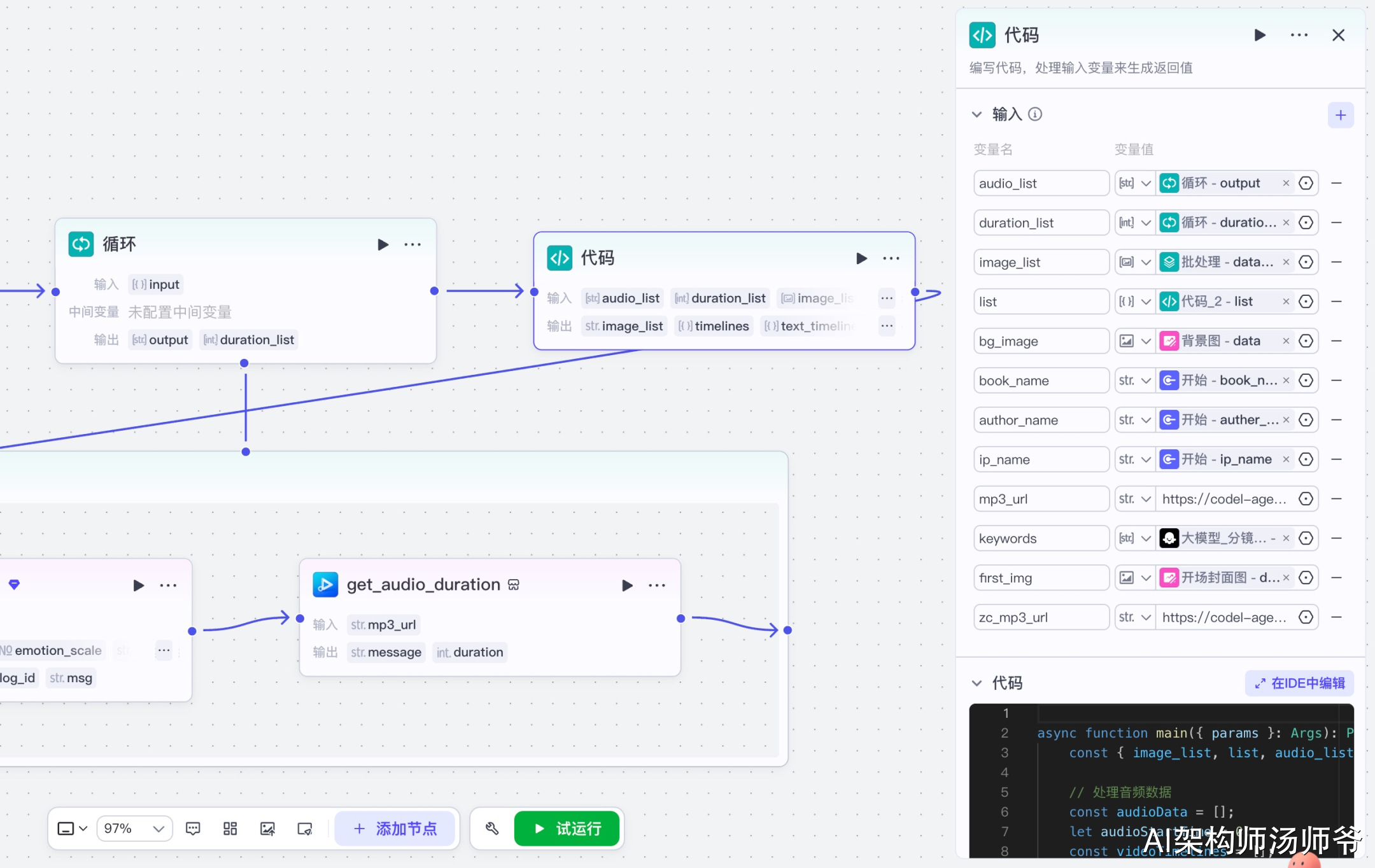
3.9 创建草稿节点(create_draft)
节点功能说明:调用剪映小助手插件,创建一个空白的视频草稿。
输入参数说明:
- height:1080,视频高度
- width:1440,视频宽度
输出参数说明:
- draft_url:创建的草稿地址,后续所有操作都基于这个URL进行
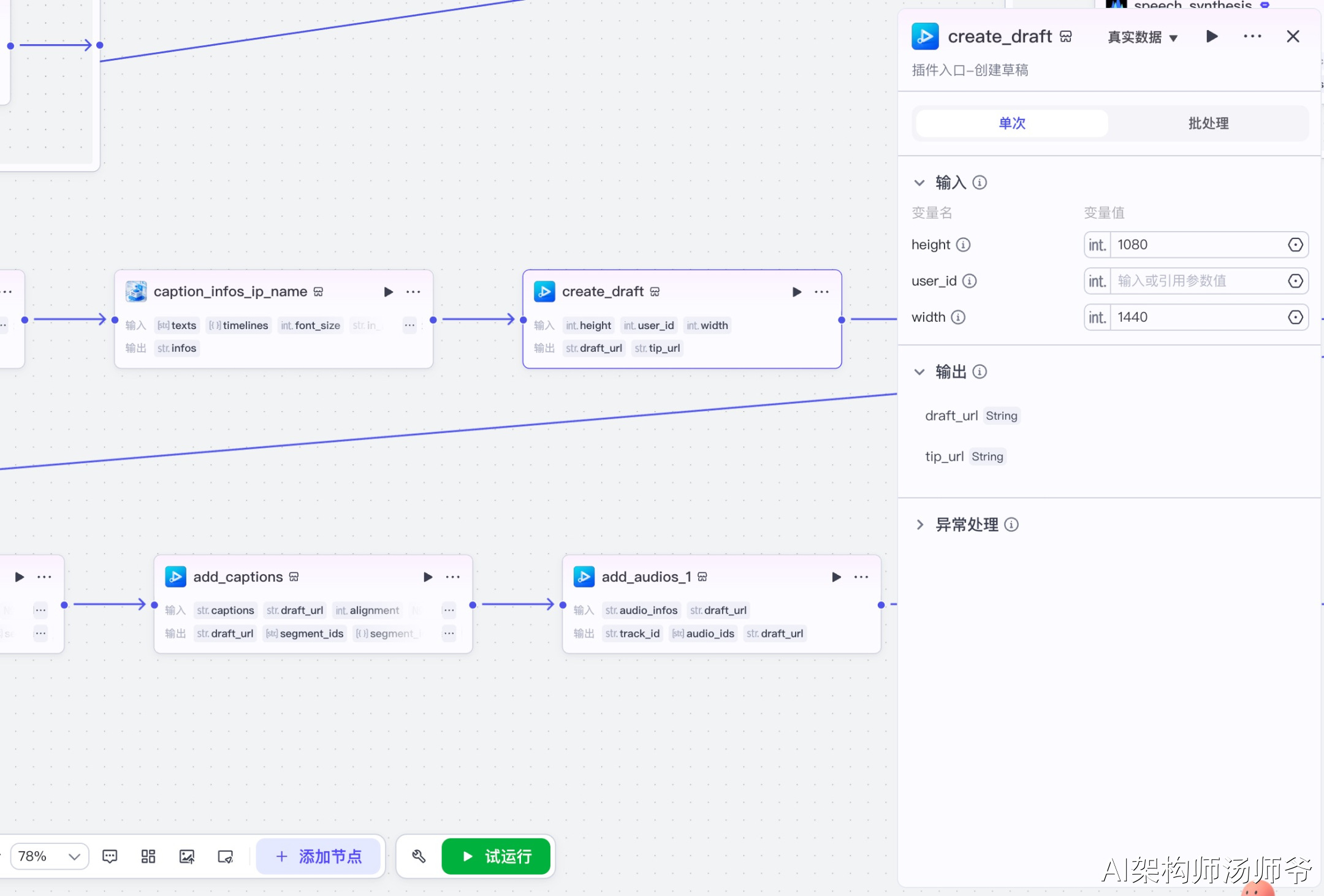
3.10 添加音频节点(add_audios)
批量添加音频到草稿中。
输入参数说明:
- audio_infos:从代码节点获取的音频数据JSON字符串
- draft_url:草稿地址
这一步会根据audio_infos中定义的每段音频的URL、开始时间、结束时间、音量等信息,将所有音频添加到草稿的音频轨道上。
输出参数说明:
- audio_ids:添加的音频ID列表
- draft_url:更新后的草稿地址
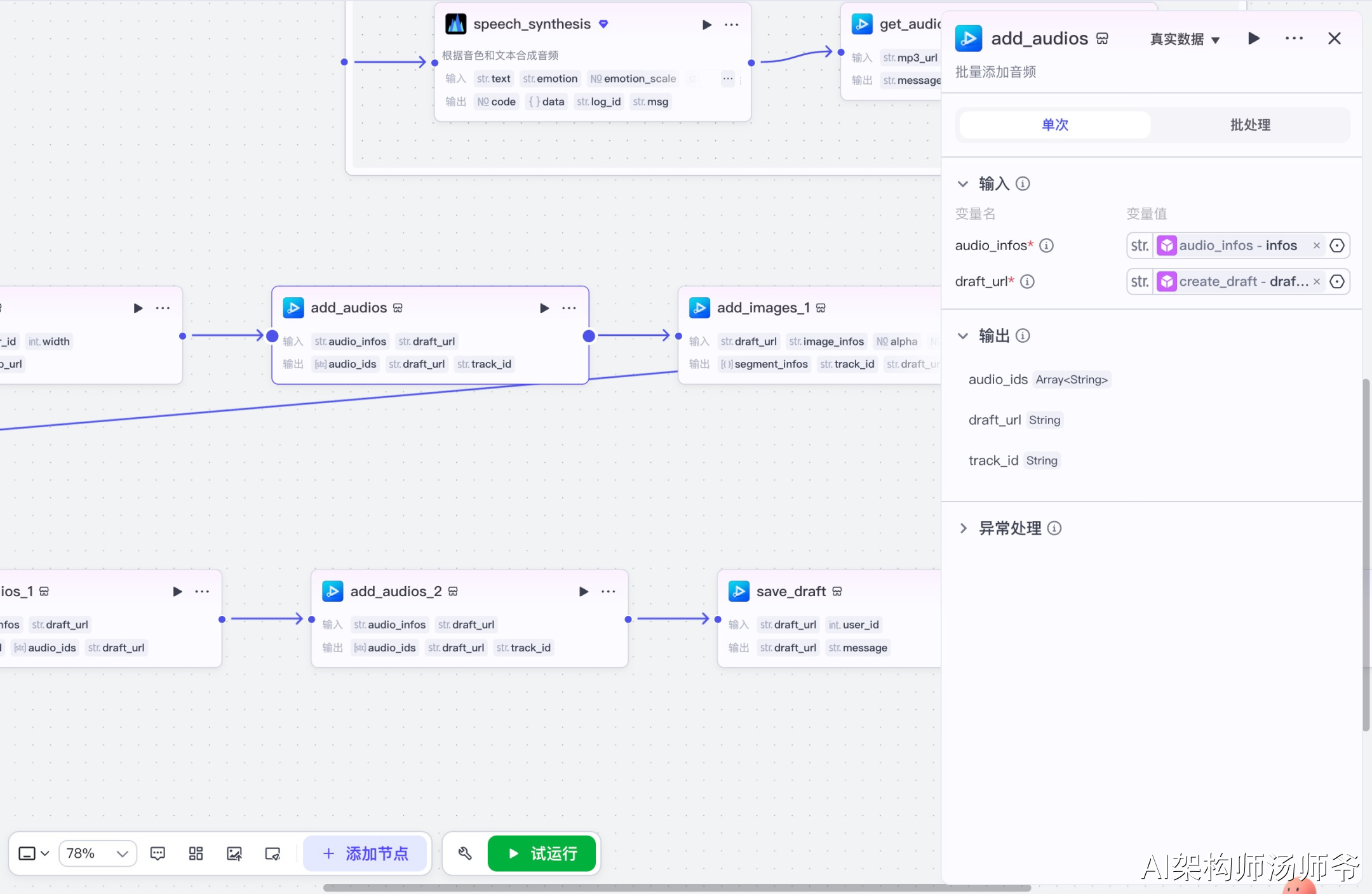
3.11 添加背景图片节点(add_images_1)
添加视频的背景图层。
输入参数说明:
- draft_url:草稿地址
- image_infos:从代码节点获取的背景图数据
这一步会将背景图添加到草稿的最底层轨道,作为整个视频的背景底图。
输出参数说明:
- draft_url:更新后的草稿地址
- image_ids:添加的图片ID列表
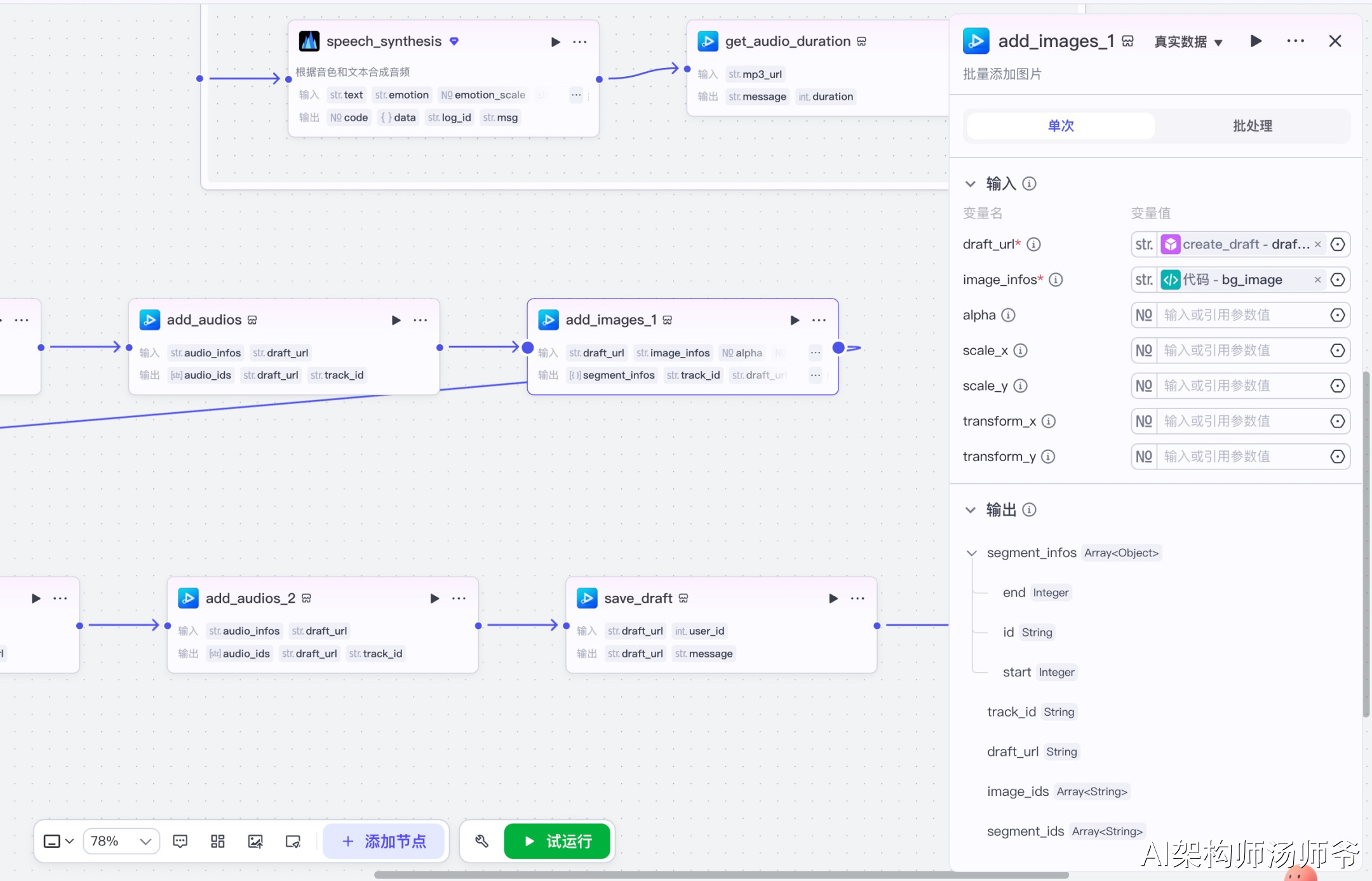
3.12 添加主图片节点(add_images)
批量添加分镜图片到草稿中。
输入参数说明:
- draft_url:草稿地址
- image_infos:从代码节点获取的图片数据
- scale_x:0.62,X轴缩放比例
- scale_y:0.62,Y轴缩放比例
- transform_x:0,X轴位移
- transform_y:-327,Y轴位移(向上偏移327像素)
这一步会根据imageDataLeft中定义的每张图片的URL、开始时间、结束时间、动画效果等信息,将所有主图片添加到草稿中。图片会自动按照时间轴播放,并带有设定好的入场动画和转场效果。
输出参数说明:
- draft_url:更新后的草稿地址
- segment_ids:添加的片段ID列表
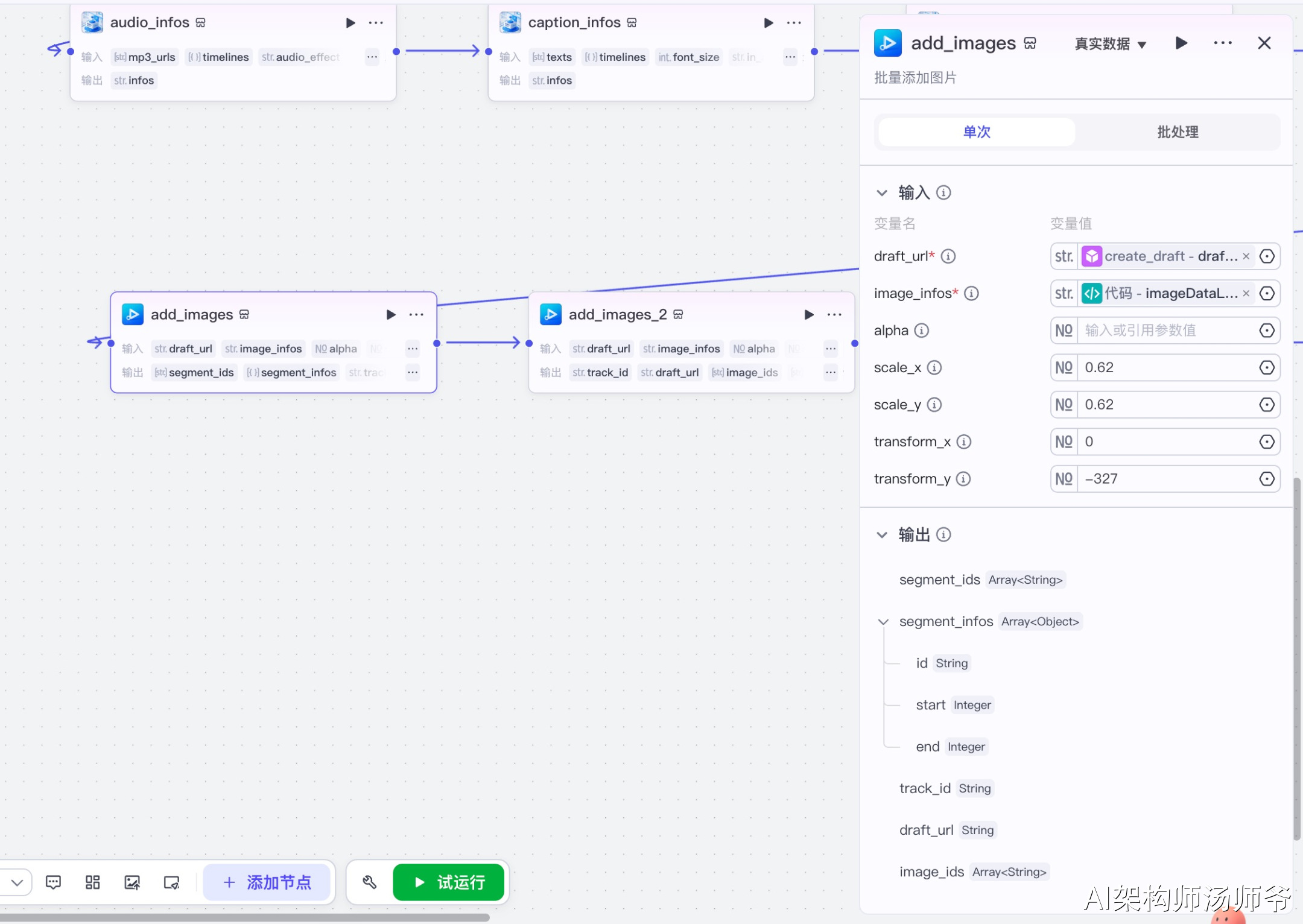
3.13 添加首帧图片节点(add_images_2)
批量添加首帧图片到草稿中。
输入参数说明:
- draft_url:草稿地址
- image_infos:从代码节点获取的首帧图片数据
- scale_x:1,X轴缩放比例
- scale_y:1,Y轴缩放比例
- transform_x:0,X轴位移
- transform_y:0,Y轴位移
这一步会将首帧图片添加到草稿中,作为视频的开头画面。图片会按照设定的时间显示,并保持原始尺寸和位置。
输出参数说明:
- draft_url:更新后的草稿地址
- image_ids:添加的图片ID列表
- segment_ids:添加的片段ID列表
- segment_infos:片段信息列表
- track_id:轨道ID
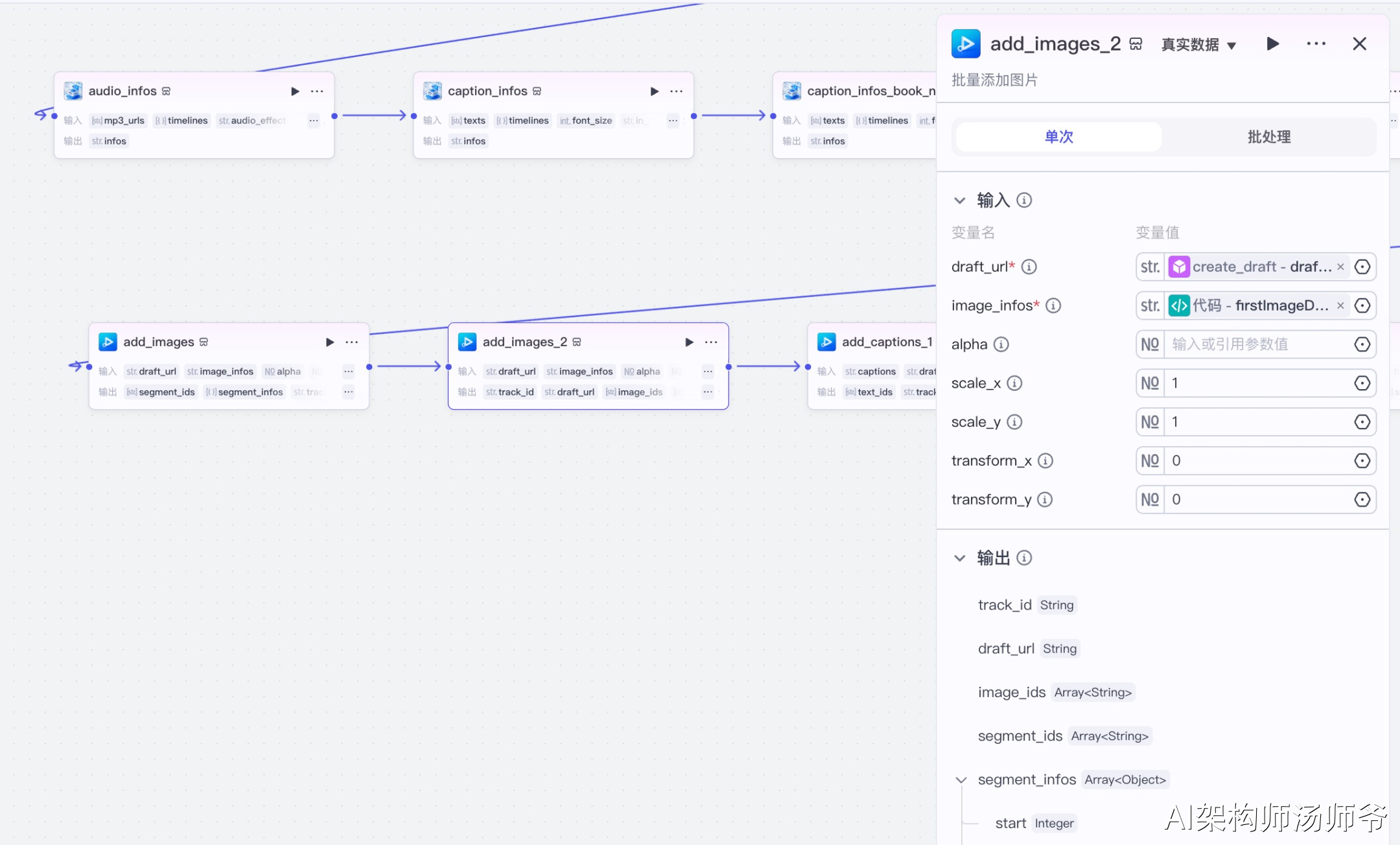
3.14 添加首帧字幕节点(add_captions_1)
批量添加首帧字幕到草稿中。
输入参数说明:
- captions:从代码节点获取的首帧字幕数据
- draft_url:草稿地址
- border_color:#000000,边框颜色为黑色
- font_size:7,字体大小为7
- text_color:#ffffff,文字颜色为白色
- transform_x:134,X轴位移
- transform_y:-629,Y轴位移(字幕位于画面上方)
这一步会将首帧的标题字幕添加到草稿中,通常用于显示书名等关键信息。字幕会在视频开头按照设定的时间显示。
输出参数说明:
- draft_url:更新后的草稿地址
- text_ids:添加的字幕ID列表
- segment_ids:添加的片段ID列表
- segment_infos:片段信息列表
- track_id:轨道ID
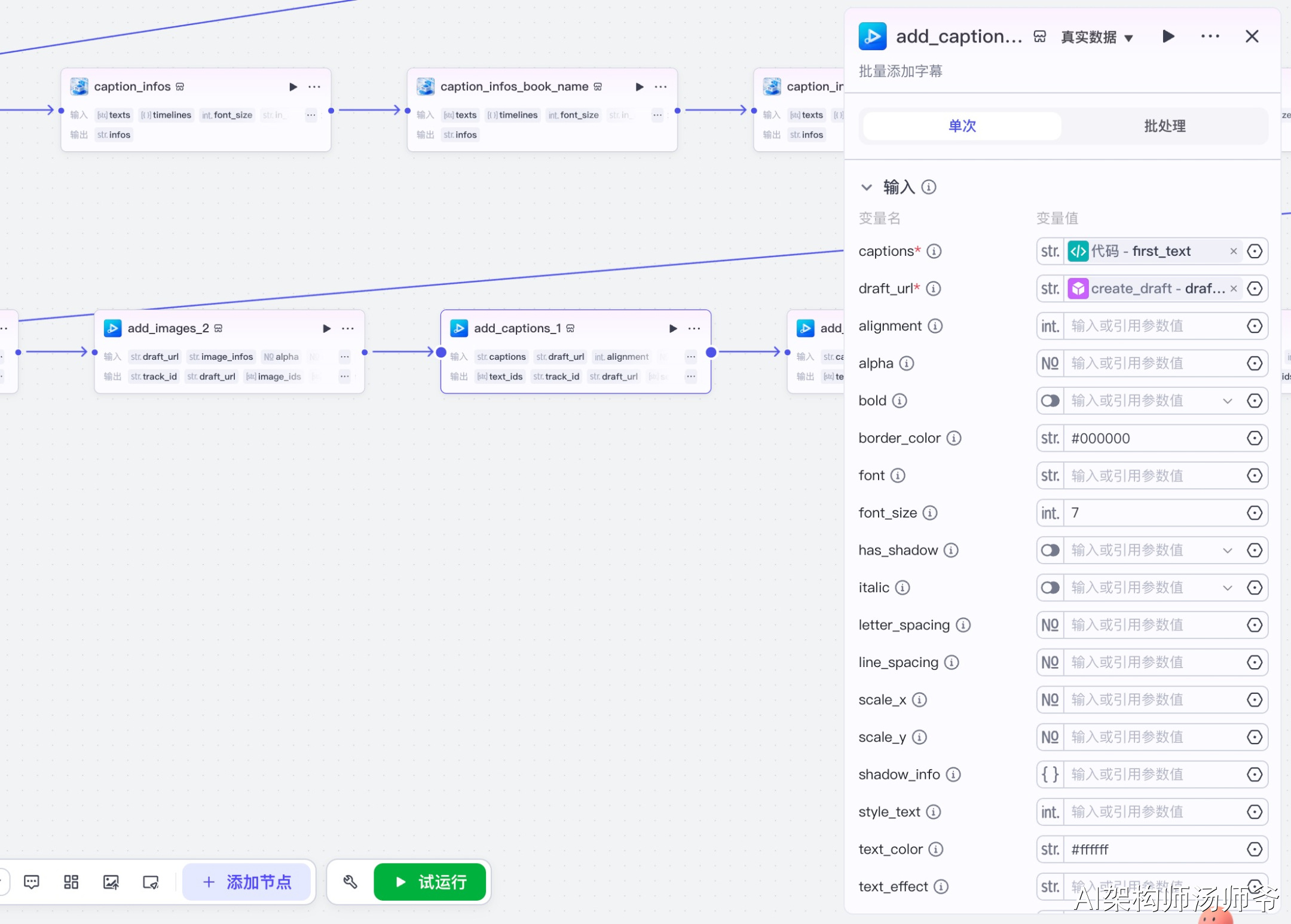
3.15 添加作者等信息字幕节点(add_captions_3)
批量添加书籍作者、个人IP等信息字幕到草稿中。
输入参数说明:
- captions:从caption_infos节点获取的格式化字幕数据
- draft_url:草稿地址
- font_size:5,字体大小为5
- text_color:#b3a6a1,文字颜色为浅灰色
- transform_x:582,X轴位移(字幕位于画面右侧)
- transform_y:-452,Y轴位移(字幕位于画面上方)
这一步会将书籍作者、个人账号名称等辅助信息字幕添加到草稿中。这些字幕通常采用较小的字号和较淡的颜色,不会干扰主要内容的展示。
输出参数说明:
- draft_url:更新后的草稿地址
- text_ids:添加的字幕ID列表
- segment_ids:添加的片段ID列表
- segment_infos:片段信息列表
- track_id:轨道ID
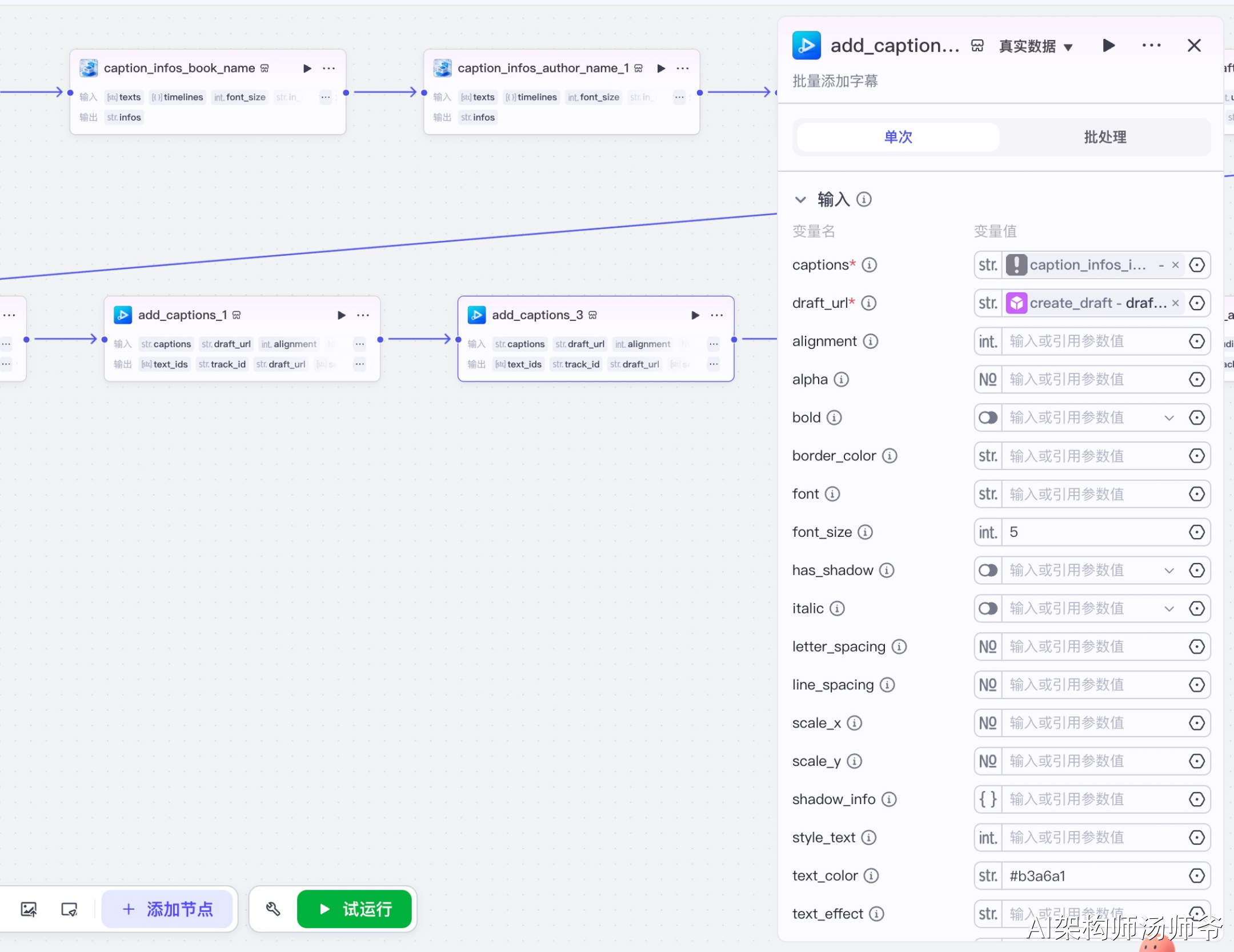
3.16 添加主字幕节点(add_captions)
批量添加视频主字幕到草稿中。
输入参数说明:
- captions:从代码节点获取的主字幕数据
- draft_url:草稿地址
- alignment:1,居中对齐
- border_color:#000000,边框颜色为黑色
- font_size:7,字体大小为7
- text_color:#ffffff,文字颜色为白色
- transform_x:0,X轴位移
- transform_y:670,Y轴位移(字幕位于画面下方)
这一步会将解说内容的主字幕添加到草稿中,字幕会自动按照时间轴显示,并且关键词会以不同的颜色和字号高亮显示(这部分逻辑在代码节点的main_text数据中已经处理好)。主字幕是视频中最重要的文字信息,帮助观众理解音频内容。
输出参数说明:
- draft_url:更新后的草稿地址
- text_ids:添加的字幕ID列表
- segment_ids:添加的片段ID列表
- segment_infos:片段信息列表
- track_id:轨道ID
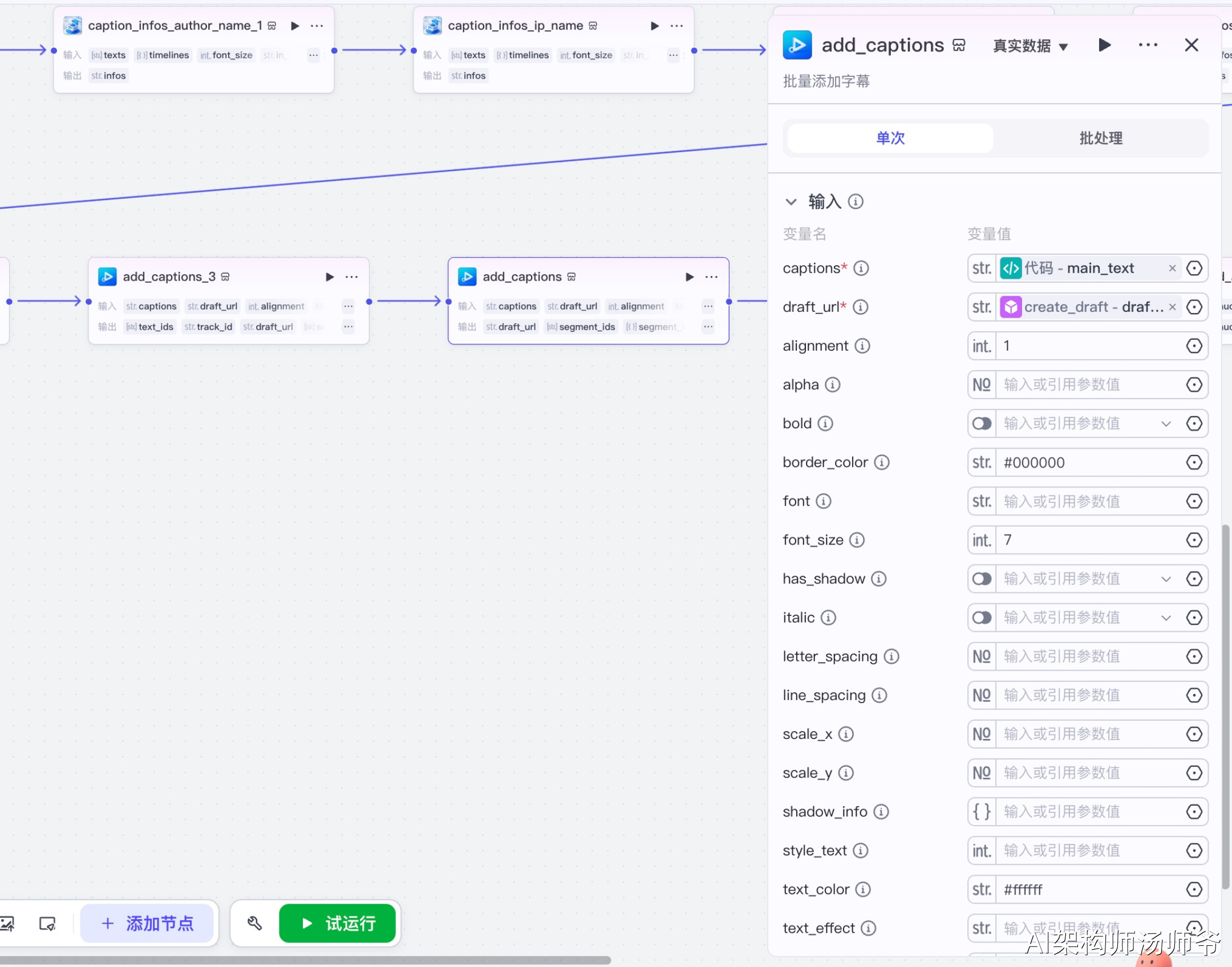
3.17 添加背景音乐节点(add_audios_1)
批量添加背景音乐到草稿中。
输入参数说明:
- audio_infos:从代码节点获取的背景音乐数据
- draft_url:草稿地址
这一步会将背景音乐添加到草稿的音频轨道上。背景音乐会在整个视频播放过程中循环播放,音量通常设置得较低,不会影响语音解说的清晰度。
输出参数说明:
- draft_url:更新后的草稿地址
- audio_ids:添加的音频ID列表
- track_id:音频轨道ID
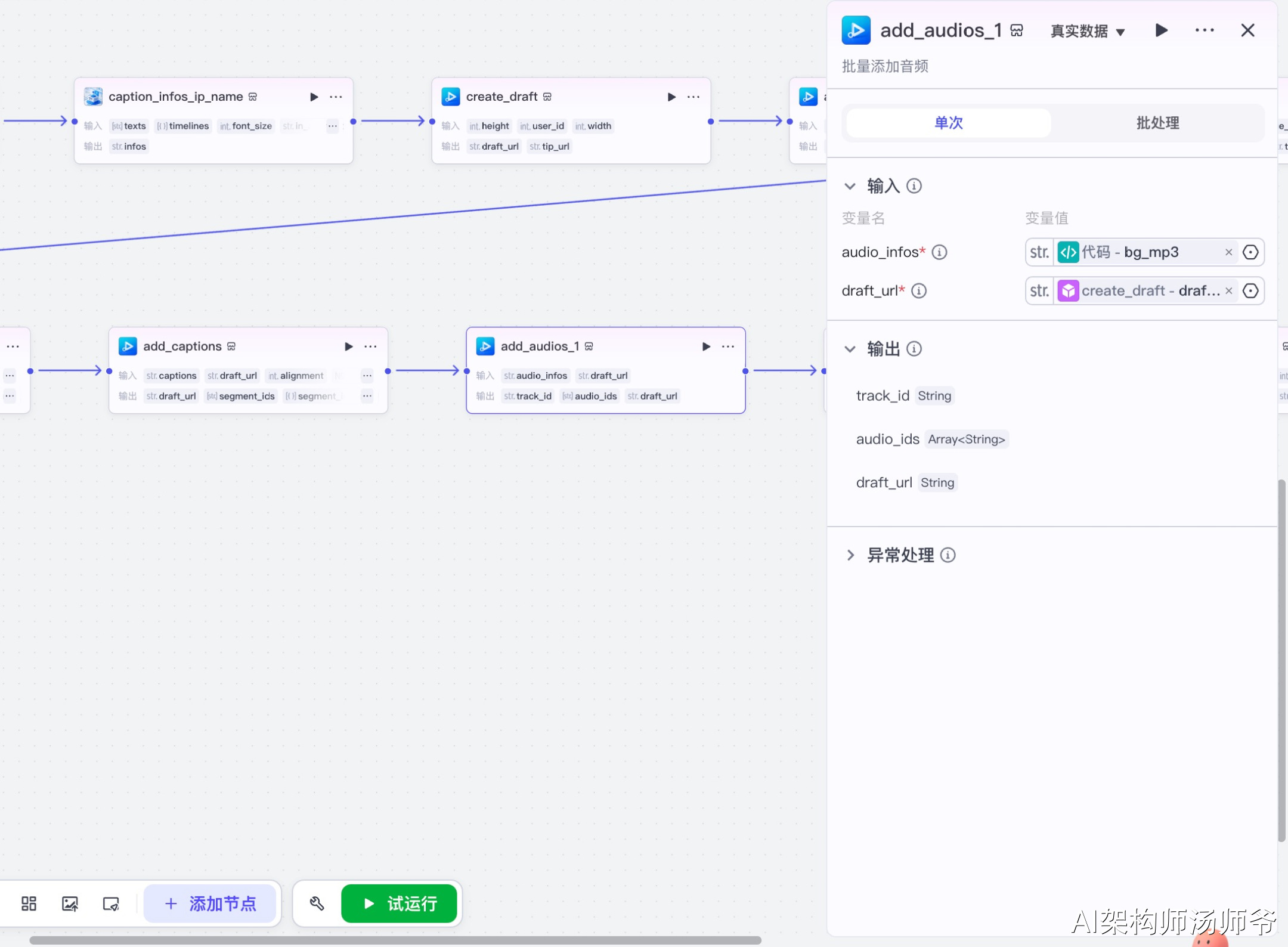
3.18 添加转场音效节点(add_audios_2)
批量添加转场音效到草稿中。
输入参数说明:
- audio_infos:从代码节点获取的转场音效数据
- draft_url:草稿地址
这一步会将转场音效添加到草稿的音频轨道上。转场音效会在画面切换时播放,增强视频的节奏感和观看体验。音效的时间点与图片转场效果同步。
输出参数说明:
- draft_url:更新后的草稿地址
- audio_ids:添加的音频ID列表
- track_id:音频轨道ID
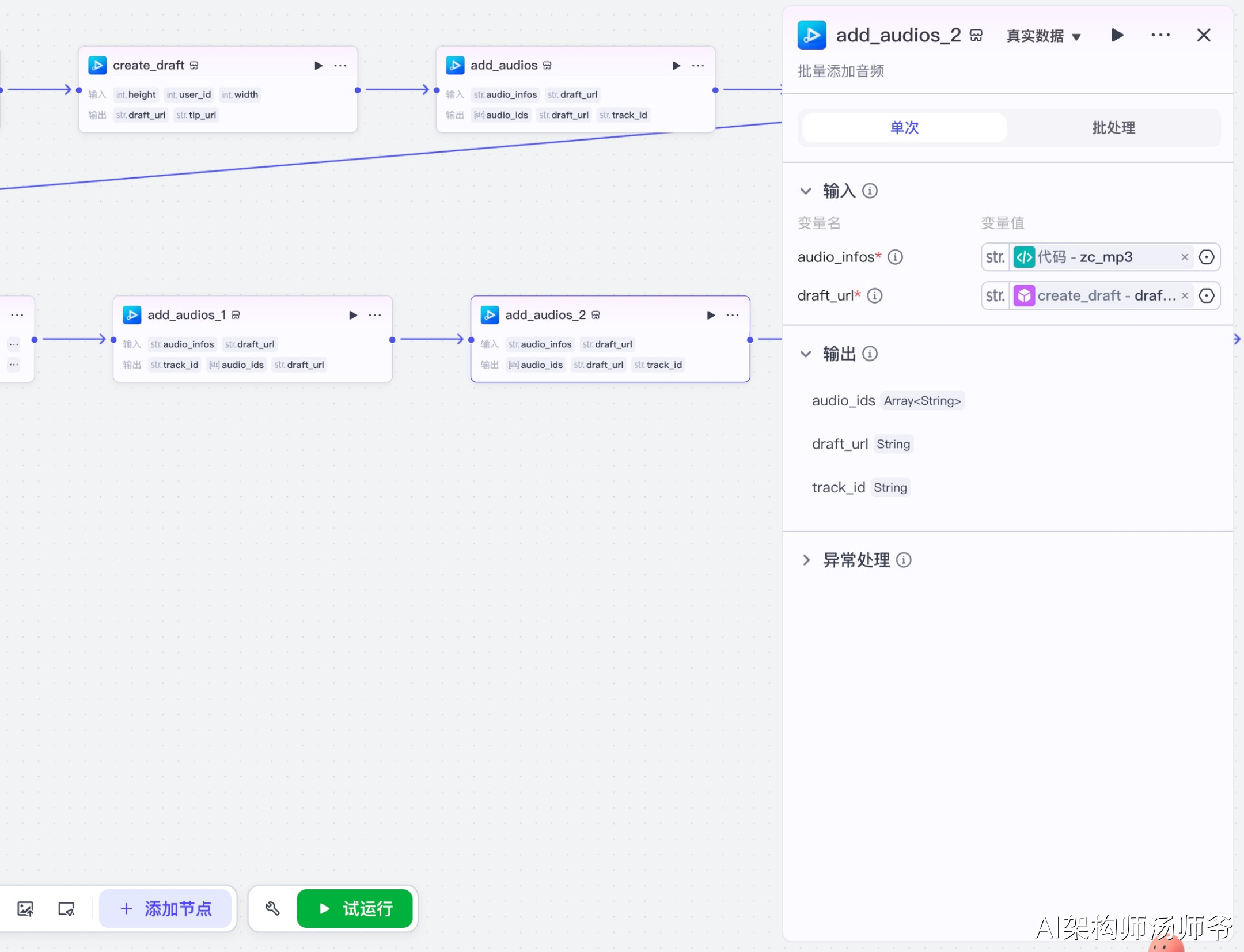
3.19 保存草稿节点(save_draft)
节点功能说明:保存剪映草稿,生成最终的草稿链接。
输入参数说明:
- draft_url:草稿地址
- user_id:10299,用户ID
输出参数说明:
- draft_url:最终保存的草稿地址
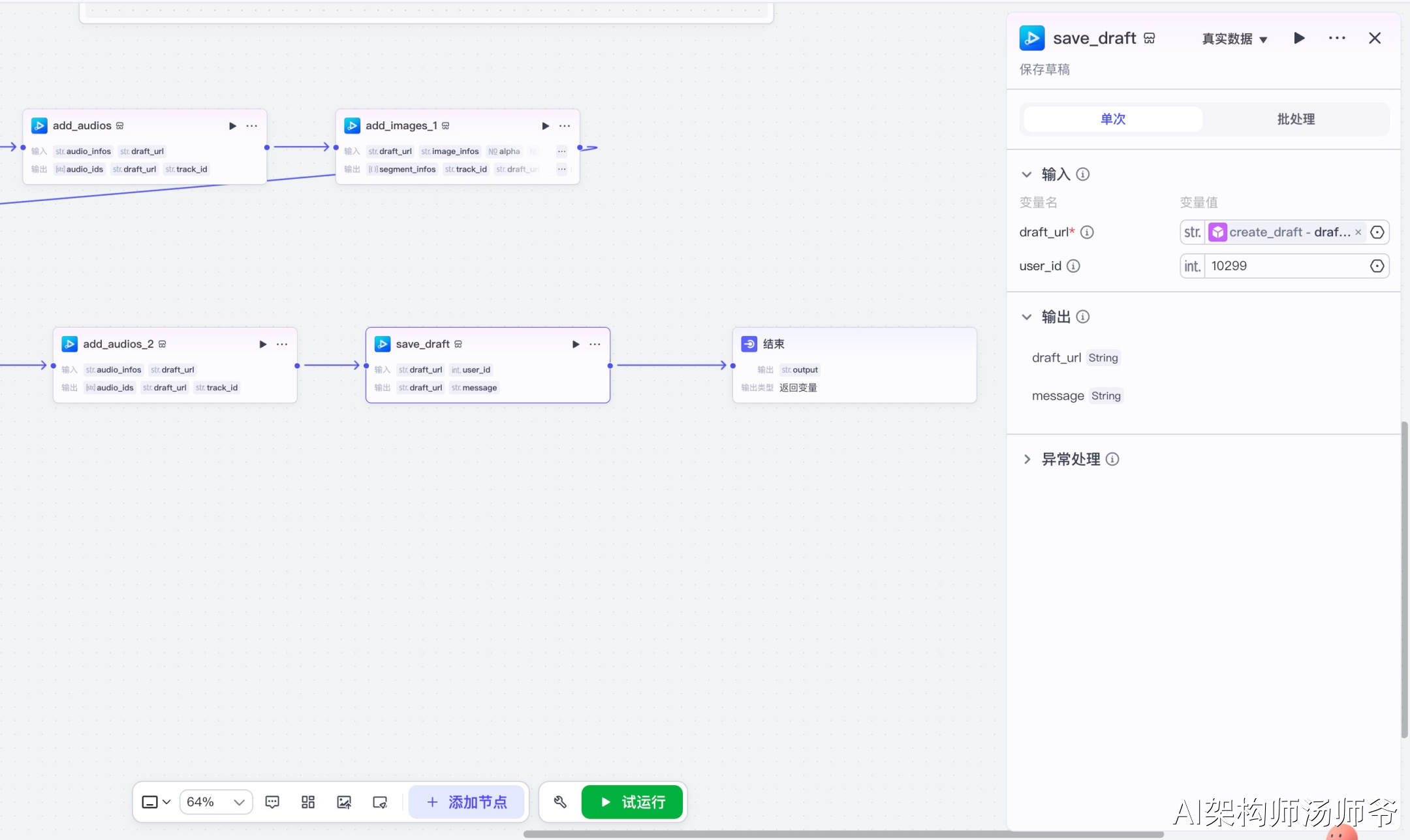
3.20 结束节点
节点功能说明:工作流的最终节点,用于返回工作流运行后的结果信息。
输入参数说明:
- output:从保存草稿节点获取的最终草稿URL
这一步会将最终生成的剪映草稿链接返回给用户,用户点击链接即可在剪映中打开草稿进行查看和编辑。
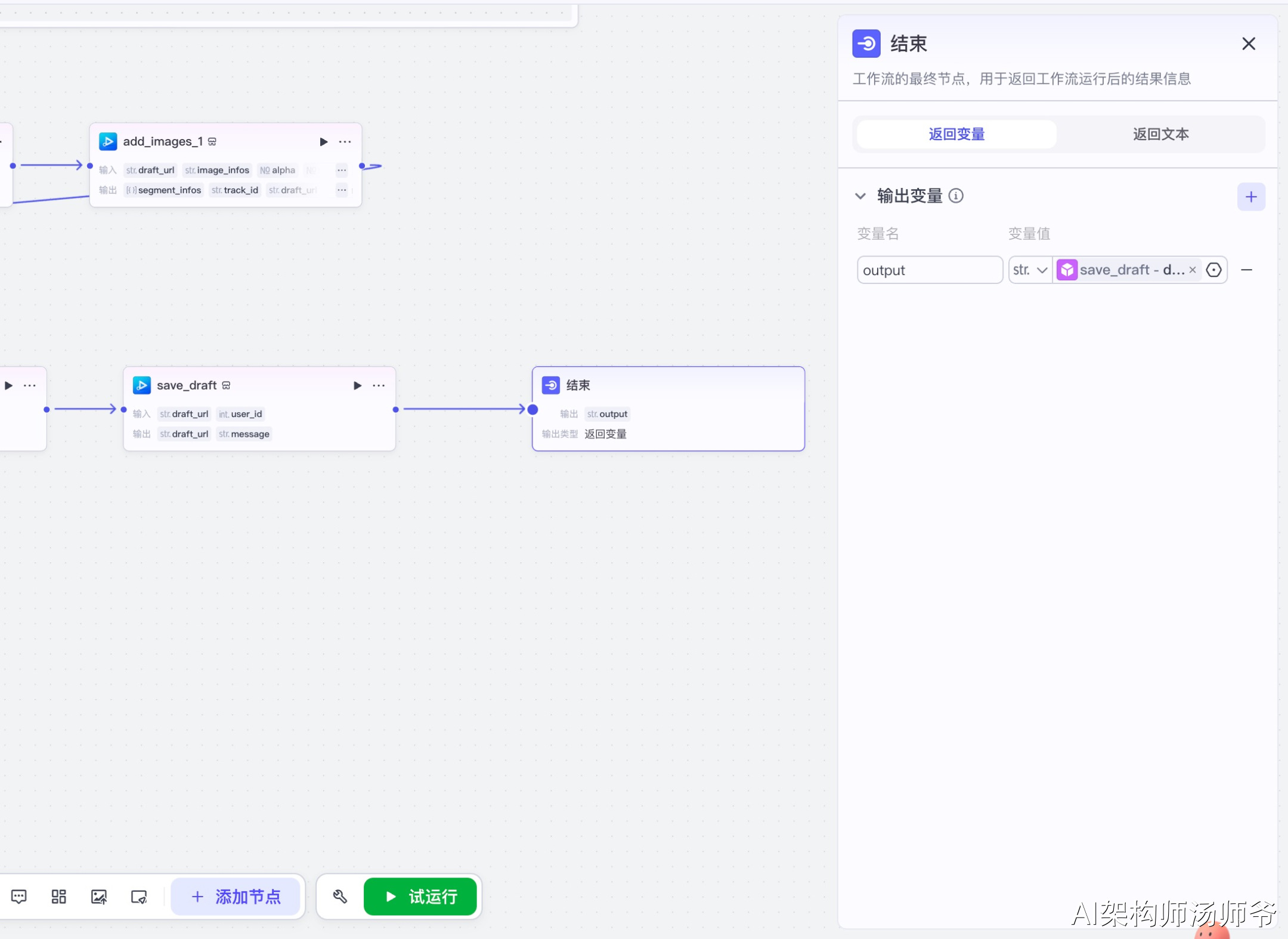
完成以上所有步骤后,工作流会生成一个剪映草稿链接。
接下来,你需要做以下几个简单的操作:
- 复制工作流输出的草稿链接
- 打开剪映小助手
- 将复制的链接粘贴到剪映小助手中
- 点击导入,草稿就会自动加载到剪映中
- 导入成功后,你就可以在剪映中看到完整的视频草稿了,包括所有的图片、音频、字幕和转场效果
- 如果需要调整细节(比如字幕位置、背景音乐音量等),可以在剪映中直接编辑
- 确认无误后,点击导出,一条完整的知识类短视频就制作完成了
整个过程非常简单,即使是第一次使用,也能在几分钟内完成导入和编辑。
4、写在最后
这个3分钟读完一本书工作流展示了AI智能体在内容生产领域的强大能力。
通过将大模型、AI绘图、语音合成、视频编辑等多个AI能力有机整合,我们实现了知识类短视频的全流程自动化生产。
整个工作流的设计思路值得我们学习。
这种"AI+自动化+工具集成"的模式,可以应用到更多内容生产场景中。
希望这个教程能帮助你快速上手搭建自己的知识类视频智能体,如果你有任何问题或优化建议,欢迎在评论区交流讨论!
对了,我整理了一份开源的智能体学习手册,爆肝10万字,价值999元。现在限时开放领取👉:tangshiye.cn 手慢无。
本文来自博客园,作者:AI架构师汤师爷,转载请注明原文链接:https://www.cnblogs.com/tangshiye/p/19296663

 浙公网安备 33010602011771号
浙公网安备 33010602011771号