python字符串前缀u,b,r,f
今天看别人写的代码得时候,发现他在好多字符串前面加了前缀,就查了一下这些前缀得含义,记录一下。
u
字符串默创建以Unicode编码存储,可以存储中文,这个在python2中比较常用,可以用来防止含中文字符串出现乱码得情况,不过在python3中,由于字符串默认就是Unicode编码,貌似用处就没有很大了。
举个例子
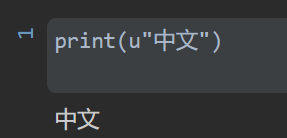
print(u"中文")
b
b是bytes得缩写,表示该字符串是bytes类型,其实也就是我们平时说的Ascll码。
这就比较有意思了,上一个说到Python3里字符串默认是unicode,所以一般不用u,而Python2的字符串本身就是bytes类,所以对python2来说,b可用可不用。
当然,其实在我们平时写python程序的时候也不会管这些东西,这些玩意都只会用在一些对编码格式有要求得方法里面,比如send、recv 之类得。
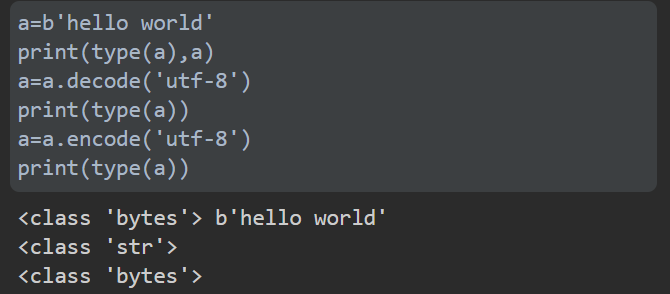
找含义的时候,看到大佬附的 Python3 中,bytes 和 str 的互相转换方式,也顺带放上来吧
str.encode('utf-8')
bytes.decode('utf-8')
举个例子
r
说到r,就不得不先说说python里的转义字符,对,就是下面这张表里的这堆东西
| 转义字符 | 说明 |
|---|---|
| \n | 换行符,将光标位置移到下一行开头。 |
| \r | 回车符,将光标位置移到本行开头。 |
| \t | 水平制表符,也即 Tab 键,一般相当于四个空格。 |
| \a | 蜂鸣器响铃。注意不是喇叭发声,现在的计算机很多都不带蜂鸣器了,所以响铃不一定有效。 |
| \b | 退格(Backspace),将光标位置移到前一列。 |
| \\ | 反斜线 |
| \' | 单引号 |
| \" | 双引号 |
| \ | 在字符串行尾的续行符,即一行未完,转到下一行继续写。 |
| (写的时候没想到markdown把我写的转义字符给转义了) |
这些转义字符都有一个共同点就是\开头,那万一我字符串里的\我就要是\而不是用来转义呢?这时候r就上场了,他的作用就是让字符串里的转义字符失效,也就是告诉计算机我这个字符串他就是一个纯字符串,没有其他杂七杂八的东西
举个例子对比
print('123\n456')
print(r'123\n456')
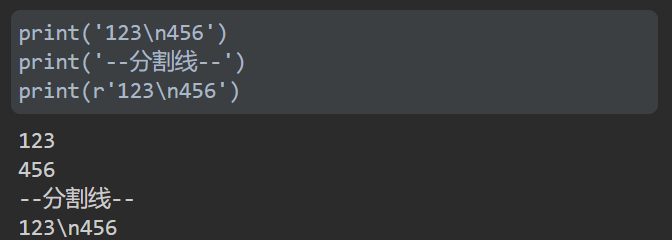
效果非常明显!
f
这个我看很多介绍里都没写,仔细一找才知道他是python3.6刚加的。
他的作用是格式化字符串,也就相当于一大堆的format,你加上后就会支持在字符串中加入一些python表达式,直接上例子吧,直接讲也讲不清楚
a=1
b=2
print(f'a+b={a+b}')
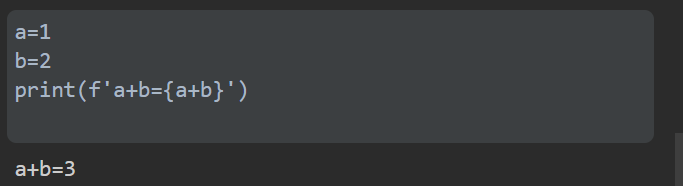
这样一看就懂了吧,用这玩意不比用format香嘛 [旺柴]
参考文献
[1]https://www.cnblogs.com/songzhenhua/p/13236794.html
[2]https://blog.csdn.net/weixin_42165585/article/details/80980739
[3]http://c.biancheng.net/view/2176.html
如有错误,欢迎指正
同时发布在CSDN中:https://blog.csdn.net/tangkcc/article/details/119868258

 浙公网安备 33010602011771号
浙公网安备 33010602011771号