

python爬虫--布隆过滤器实现去重
布隆过滤器
BloomFilter
布隆过滤器是由一个很长的二进制矢量和一系列哈希函数组成的。
二进制矢量本质是一个位数组:数组的每个元素都只占1bit空间,并且每个元素只能为0或1。
布隆过滤器还拥有k个哈希函数,当一个元素加入布隆过滤器中的时候,会使用k个哈希函数对其进行k次计算,得到k个哈希值,并且根据得到的哈希值,在维数组中把对应下标的值置位1。
若要判断这个数是否在布隆过滤器中,就对该元素进行k次哈希计算,得到的值在位数组中判断每个元素是否都为1,如果每个元素都为1,就说明这个值在布隆过滤器中。
Scrapy-Redis 的去重机制。Scrapy-Redis 将 Request 的指纹存储到了 Redis 集合中,每个指纹的长度为 40,例如 27adcc2e8979cdee0c9cecbbe8bf8ff51edefb61 就是一个指纹,它的每一位都是 16 进制数。
计算一下用这种方式耗费的存储空间。每个十六进制数占用 4 b,1 个指纹用 40 个十六进制数表示,占用空间为 20 B,1 万个指纹即占用空间 200 KB,1 亿个指纹占用 2 GB。当爬取数量达到上亿级别时,Redis 的占用的内存就会变得很大,而且这仅仅是指纹的存储。Redis 还存储了爬取队列,内存占用会进一步提高,更别说有多个 Scrapy 项目同时爬取的情况了。当爬取达到亿级别规模时,Scrapy-Redis 提供的集合去重已经不能满足我们的要求。所以我们需要使用一个更加节省内存的去重算法 Bloom Filter。
初始位数组
在 Bloom Filter 中使用位数组来辅助实现检测判断。在初始状态下,我们声明一个包含 m 位的位数组,它的所有位都是 0,如图

现在有一个待检测集合,表示为 S={x1, x2, ..., xn},接下来需要做的就是检测一个 x 是否已经存在于集合 S 中。
在 BloomFilter 算法中首先使用 k 个相互独立的、随机的哈希函数来将这个集合 S 中的每个元素 x1、x2、...、xn 映射到这个长度为 m 的位数组上,哈希函数得到的结果记作位置索引,然后将位数组该位置索引的位置 1。例如这里我们取 k 为 3,即有三个哈希函数,x1 经过三个哈希函数映射得到的结果分别为 1、4、8,x2 经过三个哈希函数映射得到的结果分别为 4、6、10,那么就会将位数组的 1、4、6、8、10 这五位置 1,如图
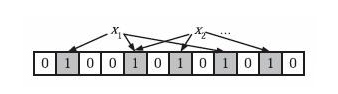
这时如果再有一个新的元素 x,要判断 x 是否属于 S 这个集合,会将仍然用 k 个哈希函数对 x 求映射结果,如果所有结果对应的位数组位置均为 1,那么我们就认为 x 属于 S 这个集合,否则如果有一个不为 1,则 x 不属于 S 集合。
例如一个新元素 x 经过三个哈希函数映射的结果为 4、6、8,对应的位置均为 1,则判断 x 属于 S 这个集合。如果结果为 4、6、7,7 对应的位置为 0,则判定 x 不属于 S 这个集合。
注意这里 m、n、k 满足的关系是 m>nk,也就是说位数组的长度 m 要比集合元素 n 和哈希函数 k 的乘积还要大。
存在的问题
但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。常见的补救办法是建立一个小的白名单,存储那些可能被误判的元素。但是如果元素数量太少,则使用散列表足矣。
另外,一般情况下不能从布隆过滤器中删除元素。我们很容易想到把位列阵变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题.
m,k,误判概率的计算应用
题目:
不安全网页的黑名单包含100亿个黑名单网页,每个网页的URL最多占用64字节。现在想要实现一种网页过滤系统,可以根据网页的URL判断该网站是否在黑名单上,请设计该系统。要求该系统允许有万分之一以下的判断失误率,并且使用的额外空间不要超过30G。
需求:
布隆过滤器的bitarray大小如何确定?
设bitarray大小为m,样本数量为n,失误率为p。
由题可知 n = 100亿,p = 0.01%
单个样本大小不影响布隆过滤器大小,因为样本会通过哈希函数得到输出值。
使用样本数量n和失误率p可以算出m,公式为:
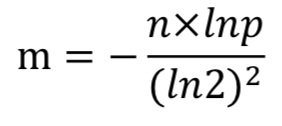
求得 m = 19.19n,向上取整为 20n。所以2000亿bit,约为25G。
# 1GB=1024MB 1MB=1024KB 1KB=1024Byte 1Byte=8bit
所使用哈希函数个数k可以由以下公式求得:
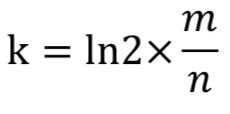
ln2约等于0.7也就是最优k值
所以 k = 14,即需要14个哈希函数。
通过 m = 20n, k = 14,可以通过以下公式算出设计的布隆过滤器的真实失误率为0.006%。
# 也就是当k值越接近0.7*m/n的值时,误判概率越小
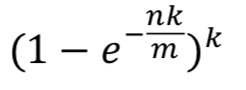
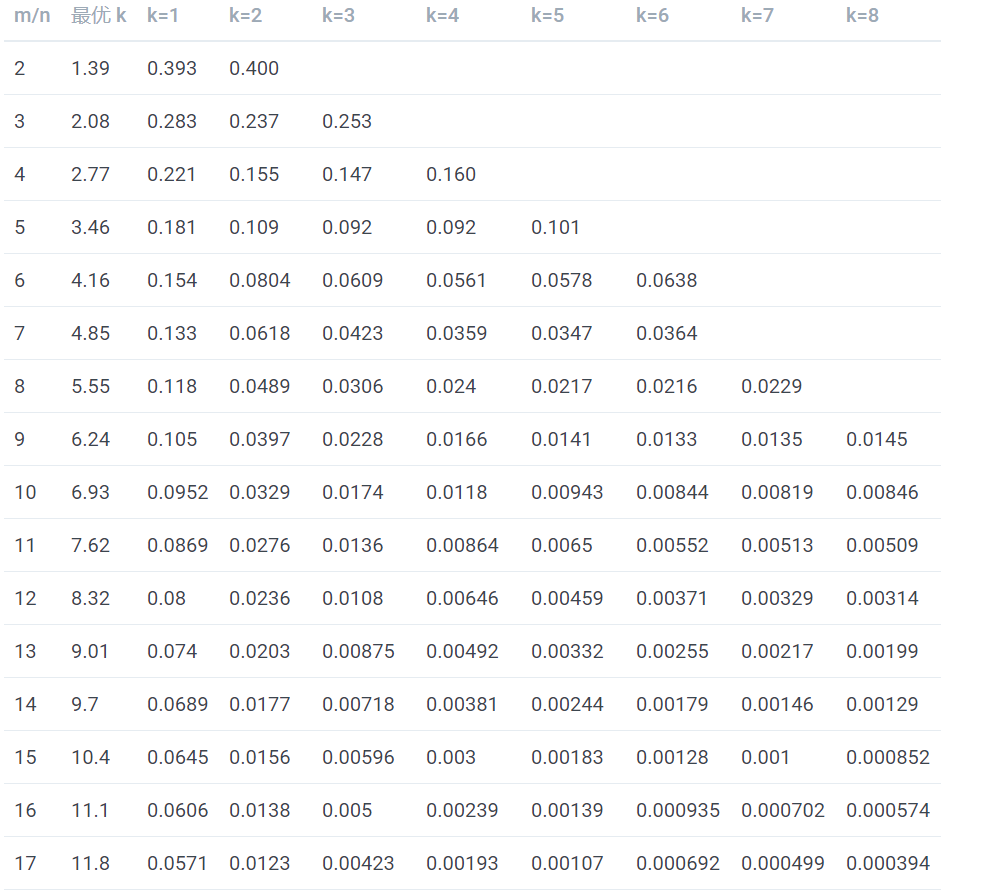
表中第一列为 m/n 的值,第二列为最优 k 值,其后列为不同 k 值的误判概率,可以看到当 k 值确定时,随着 m/n 的增大,误判概率逐渐变小。当 m/n 的值确定时,当 k 越靠近最优 K 值,误判概率越小。另外误判概率总体来看都是极小的,在容忍此误判概率的情况下,大幅减小存储空间和判定速度是完全值得的
BloomFilter和在scrapy中的应用
首先进行安装
pip3 install scrapy-redis-bloomfilter
进行配置
# 去重类,要使用 BloomFilter 请替换 DUPEFILTER_CLASS
DUPEFILTER_CLASS = "scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter"
# 哈希函数的个数,默认为 6,可以自行修改
BLOOMFILTER_HASH_NUMBER = 6
# BloomFilter 的 bit 参数,默认 30,占用 128MB 空间,去重量级 1 亿
BLOOMFILTER_BIT = 30
DUPEFILTER_CLASS 是去重类,如果要使用 BloomFilter 需要将 DUPEFILTER_CLASS 修改为该包的去重类。
BLOOMFILTER_HASH_NUMBER 是 BloomFilter 使用的哈希函数的个数,默认为 6,可以根据去重量级自行修改。
BLOOMFILTER_BIT 即前文所介绍的 BloomFilter 类的 bit 参数,它决定了位数组的位数,如果 BLOOMFILTER_BIT 为 30,那么位数组位数为 2 的 30 次方,将占用 Redis 128MB 的存储空间,去重量级在 1 亿左右,即对应爬取量级 1 亿左右。如果爬取量级在 10 亿、20 亿甚至 100 亿,请务必将此参数对应调高。
测试
from scrapy import Request, Spider
class TestSpider(Spider):
name = 'test'
base_url = 'https://www.baidu.com/s?wd='
def start_requests(self):
for i in range(10):
url = self.base_url + str(i)
yield Request(url, callback=self.parse)
# Here contains 10 duplicated Requests
for i in range(100):
url = self.base_url + str(i)
yield Request(url, callback=self.parse)
def parse(self, response):
self.logger.debug('Response of ' + response.url)
运行项目输出结果
{'bloomfilter/filtered': 10,
'downloader/request_bytes': 34021,
'downloader/request_count': 100,
'downloader/request_method_count/GET': 100,
'downloader/response_bytes': 72943,
'downloader/response_count': 100,
'downloader/response_status_count/200': 100,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 8, 11, 9, 34, 30, 419597),
'log_count/DEBUG': 202,
'log_count/INFO': 7,
'memusage/max': 54153216,
'memusage/startup': 54153216,
'response_received_count': 100,
'scheduler/dequeued/redis': 100,
'scheduler/enqueued/redis': 100,
'start_time': datetime.datetime(2017, 8, 11, 9, 34, 26, 495018)}
结果中'bloomfilter/filtered': 10,
这就是 BloomFilter 过滤后的统计结果,可以看到它的过滤个数为 10 个,也就是它成功将重复的 10 个 Reqeust 识别出来了,测试通过。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号