
ubuntu系统ceph 操作篇
1、Ceph-FS 文件存储:
https://docs.ceph.com/en/latest/cephfs/
CephFs即ceph filesystem, 可以实现文件系统共享功能,客户端通过ceph协议挂载并使用ceph 集群作为数据存储服务。
Ceph FS 需要运行Meta Data Service(MDS)服务器,并守护进程为ceph-mds, ceph-mds进程管理与CephFS上存储得出文件相关的元数据,并协调对ceph存储集群的访问
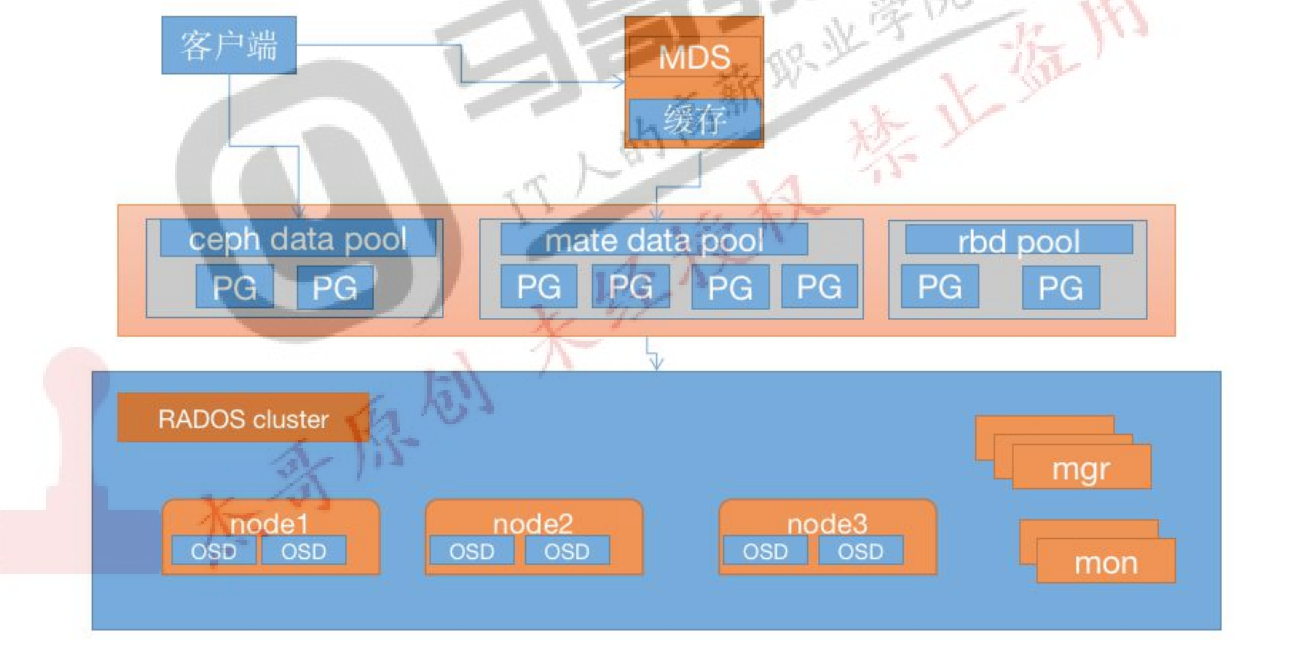
1.1:部署MDS服务:
在指定的ceph-mds 服务器部署ceph-mds 服务,可以和其他服务器混用(如 ceph-mon、ceph-mgr)
这里我们就部署在 二台 mgr节点上面
首先我们先登入mgr 上 并切换到root 下 查看ceph-mds 当前版本 并安装选择的版本
coinceres@ceph-mgr-node1:~$ sudo su - root
[sudo] password for coinceres:
root@ceph-mgr-node1:~# apt-cache madison ceph-mds
ceph-mds | 16.2.5-1bionic | https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic/main amd64 Packages
ceph-mds | 12.2.13-0ubuntu0.18.04.8 | http://hk.archive.ubuntu.com/ubuntu bionic-updates/universe amd64 Packages
ceph-mds | 12.2.13-0ubuntu0.18.04.4 | http://security.ubuntu.com/ubuntu bionic-security/universe amd64 Packages
ceph-mds | 12.2.4-0ubuntu1 | http://hk.archive.ubuntu.com/ubuntu bionic/universe amd64 Packages
root@ceph-mgr-node1:~# apt install ceph-mds=16.2.5-1bionic
切换到ceph-deploy节点上操作 添加 mds节点机器
lmttrade@ceph-deploy:~$ cd ceph-cluster/
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-deploy mds create ceph-mgr-node1
1.2: 验证MDS服务
MDS服务目前还无法正常使用,需要为MDS 创建存储池用于保存MDS的数据
lmttrade@ceph-deploy:~/ceph-cluster$ ceph mds stat
1 up:standby #当前为备用状态,需要分配pool才可以使用
1.3 : 创建CephFS metadata 和data 存储池:
使用CephFS 之前需要事先与集群中创建一个文件系统,并为其分别指定元数据和数据相关的存储池,如下命令将创建名为mycephfs的文件系统,它使用cephfs-metadata为元数据存储池
使用cephfs-data为数据存储池:
1.3.1:创建元数据存储池:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph osd pool create cephfs-metadata 32 32
pool 'cephfs-metadata' created #保存metadata的pool
1.3.2: 创建数据存储池:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph osd pool create cephfs-data 64 64
pool 'cephfs-data' created #保存数据的pool
查看存储池:

1.4 创建cephFS 并验证: (cephfs-metadata为元数据存储池 cephfs-data为数据存储池 )
lmttrade@ceph-deploy:~/ceph-cluster$ ceph fs new mycephfs cephfs-metadata cephfs-data
new fs with metadata pool 3 and data pool 4
查看CephFS 启用成功
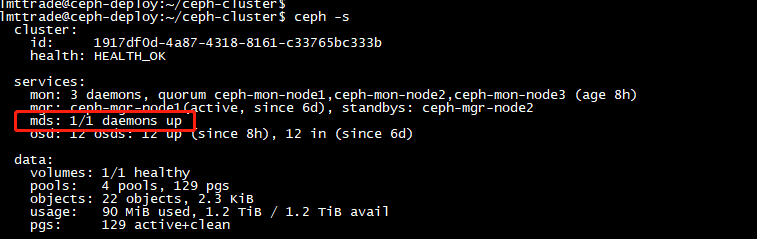
验证:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph mds stat
mycephfs:1 {0=ceph-mgr-node1=up:active} \\active 说明cephfs 创建成功可以挂载了
ceph 状态:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph fs status mycephfs

1.5:客户端挂载cephFS: (由于没有创建普通用户权限 这里我们暂时还使用admin 秘钥,后面创建普通权限秘钥再使用)
在cepf的客户端测试cephfs的挂载,需要指定mon及诶按的6789端口:
lmttrade@ceph-deploy:~/ceph-cluster$ cat ceph.client.admin.keyring
[client.admin]
key = AQBpERphK5YALBAA6+plU2ue07Booh7WG63Iuw==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
lmttrade@ceph-deploy:~/ceph-cluster$
挂载客户端使用是centos7
[root@ansible-node0 ~]# mount -t ceph 192.168.0.183:6789:/ /mnt -o name=admin,secret=AQBpERphK5YALBAA6+plU2ue07Booh7WG63Iuw==
[root@ansible-node0 ~]# df -h
一个 cephfs 适合多个 客户端同时挂载达到数据共享
2、CephX认证机制:
Ceph 使用cephx协议对客户端进行身份认证
cephx用于对ceph保存数据进行认证访问和授权,用于对访问ceph的请求进行认证和授权检测,与mon通信的请求都要经过ceph认证通过
但是也是可以在mon节点关闭cephx认证,但是关闭认证之后任何访问都将被允许,因此无法保证数据安全性
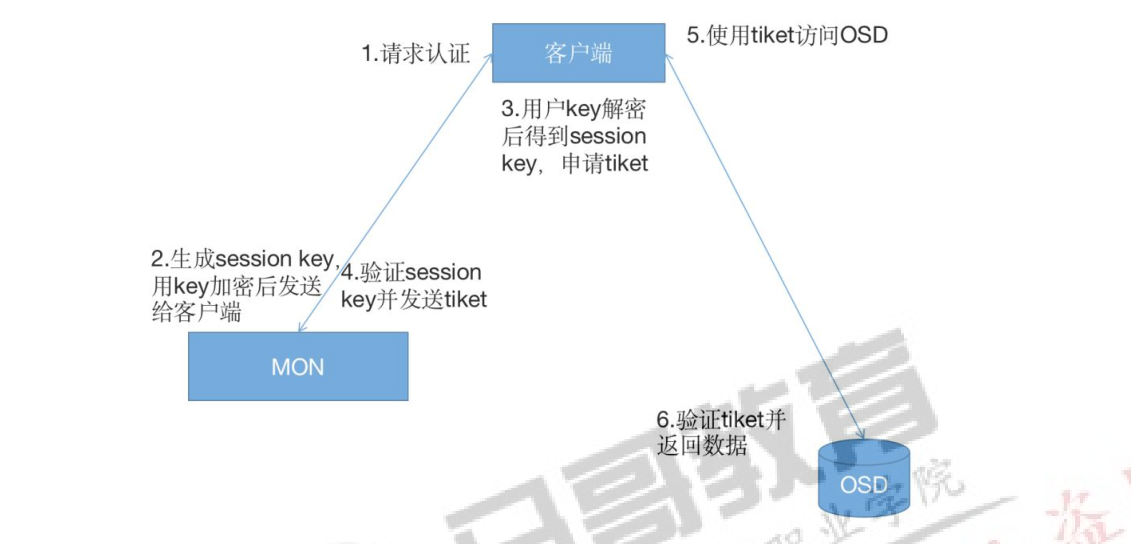
2.1、授权流程:
每个 mon 节点都可以对客户端进行身份认证并分发秘钥,因此多个 mon 节点就不存在单点故障和认证性能瓶颈
mon 节点会返回用于身份认证的数据结构,其中包含获取 ceph 服务时用到的 session key,session key 通 过 客 户 端 秘 钥 进 行 加 密 , 秘 钥 是 在 客 户 端 提 前 配 置 好 的 ,/etc/ceph/ceph.client.admin.keyring
客户端使用 session key 向 mon 请求所需要的服务,mon 向客户端提供一个 tiket,用于向实际处理数据的 OSD 等服务验证客户端身份,MON 和 OSD 共享同一个 secret,因此 OSD会信任所有 MON 发放的 tiket tiket 存在有效期
注意:
CephX 身份验证功能仅限制在 Ceph 的各组件之间,不能扩展到其他非 ceph 组件
Ceph 只负责认证授权,不 不 能 解 决 数 据 传 输 的 加 密 问
2.2 、访问流程:
无论 ceph 客户端是哪种类型,例如块设备、对象存储、文件系统,ceph 都会在存储池中将所有数据存储为对象:
ceph 用户需要拥有存储池访问权限,才能读取和写入数据
ceph 用户必须拥有执行权限才能使用 ceph 的管理命令


2.3、Ceph 用户:
用户是指个人(ceph 管理者)或系统参与者(MON/OSD/MDS)。
通过创建用户,可以控制用户或哪个参与者能够访问 ceph 存储集群、以及可访问的存储池及存储池中的数据。
ceph 支持多种类型的用户,但可管理的用户都属于 client 类型区分用户类型的原因在于,MON/OSD/MDS 等系统组件特使用 cephx 协议,但是它们为非客户端。
通过点号来分割用户类型和用户名,格式为 TYPE.ID,例如 client.admin。
lmttrade@ceph-deploy:~/ceph-cluster$ cat ceph.client.admin.keyring
[client.admin]
key = AQBpERphK5YALBAA6+plU2ue07Booh7WG63Iuw==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
2.4、ceph 授权和使能:
ceph 基于使能/能力(Capabilities,简称 caps )来描述用户可针对 MON/OSD 或 MDS 使用的授权范围或级别。
通用的语法格式:daemon-type ‘allow caps’ [...]
能力一览表:
r:向用户授予读取权限。访问监视器(mon)以检索 CRUSH 运行图时需具有此能力。
w:向用户授予针对对象的写入权限。
x:授予用户调用类方法(包括读取和写入)的能力,以及在监视器中执行 auth 操作的能
力。
*:授予用户对特定守护进程/存储池的读取、写入和执行权限,以及执行管理命令的能力
class-read:授予用户调用类读取方法的能力,属于是 x 能力的子集。
class-write:授予用户调用类写入方法的能力,属于是 x 能力的子集。
profile osd:授予用户以某个 OSD 身份连接到其他 OSD 或监视器的权限。授予 OSD 权限,使 OSD 能够处理复制检测信号流量和状态报告(获取 OSD 的状态信息)。profile mds:授予用户以某个 MDS 身份连接到其他 MDS 或监视器的权限。
profile bootstrap-osd:授予用户引导 OSD 的权限(初始化 OSD 并将 OSD 加入 ceph 集群),授权给部署工具,使其在引导 OSD 时有权添加密钥。
profile bootstrap-mds:授予用户引导元数据服务器的权限,授权部署工具权限,使其在引导元数据服务器时有权添加密钥。
MON 能力:
包括 r/w/x 和 allow profile cap(ceph 的运行图)
例如:
mon 'allow rwx'
mon 'allow profile osd'
OSD 能力:
包括 r、w、x、class-read、class-write(类读取))和 profile osd(类写入),另外 OSD 能力还允许进行存储池和名称空间设置。
osd 'allow capability' [pool=poolname] [namespace=namespace-name]
MDS 能力:
只需要 allow 或空都表示允许。
mds 'allow'
2.5、ceph 用户管理:
用户管理功能可让 Ceph 集群管理员能够直接在 Ceph 集群中创建、更新和删除用户。
在 Ceph 集群中创建或删除用户时,可能需要将密钥分发到客户端,以便将密钥添加到密
钥环文件中/etc/ceph/ceph.client.admin.keyring,此文件中可以包含一个或者多个用户认证信
息,凡是拥有此文件的节点,将具备访问 ceph 的权限,而且可以使用其中任何一个账户的
权限,此文件类似于 linux 系统的中的/etc/passwd 文件。
2.5.1、列出用户:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth list
mds.ceph-mgr-node1
key: AQCBcCJhda1EJBAADzrkMPcMzxl1W5FxhMMjaQ==
caps: [mds] allow
caps: [mon] allow profile mds
caps: [osd] allow rwx
osd.0
key: AQBgUhphB8tmBhAAAchP82CIqkgUwj1gaMIOIg==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQB6Uhph+84NDhAAy8FrQPozeLTbxSUROKxAGA==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin
key: AQBpERphK5YALBAA6+plU2ue07Booh7WG63Iuw==
caps: [mds] allow *
caps: [mgr] allow *
caps: [mon] allow *
caps: [osd] allow *
注意:TYPE.ID 表示法
针对用户采用TYPE.ID表示法,例如osd.0指定是osd类并且ID为0的用户(节点),client.admin是 client 类型的用户,其 ID 为 admin,
另请注意,每个项包含一个 key=xxxx 项,以及一个或多个 caps 项。
可以结合使用-o 文件名选项和 ceph auth list 将输出保存到某个文件。
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth list -o 123.key
2.5.3、用户管理:
添加一个用户会创建用户名 (TYPE.ID)、机密密钥,以及包含在命令中用于创建该用户的所有能力,用户可使用其密钥向 Ceph 存储集群进行身份验证。用户的能力授予该用户在 Cephmonitor (mon)、Ceph OSD (osd) 或 Ceph 元数据服务器 (mds) 上进行读取、写入或执行的能力,可以使用以下几个命令来添加用户:
2.5.3.1、ceph auth add:
此命令是添加用户的规范方法。它会创建用户、生成密钥,并添加所有指定的能力。
添加认证key (r:读权限、rwx 读写执行权限)这里我们定义client.tom 只能读mon 对储存池里的osd mypool 有读写执行 其他都读写执行不了
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth add client.tom mon 'allow r' osd 'allow rwx pool=mypool'
added key for client.tom
#验证 key
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get client.tom
[client.tom]
key = AQCLAyVhQxfpJRAA4ggf6u+YZNYdUfYfA8l21g==
caps mon = "allow r"
caps osd = "allow rwx pool=mypool"
exported keyring for client.tom
2.5.3.2:ceph auth get-or-create:
ceph auth get-or-create 此命令是创建用户较为常见的方式之一,它会返回包含用户名(在方括号中)和密钥的密钥文,如果该用户已存在,此命令只以密钥文件格式返回用户名和密钥,
还可以使用 -o 指定文件名选项将输出保存到某个文件。
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get-or-create client.jack mon 'allow r' osd 'allow rwx pool=mypool'
[client.jack]
key = AQCJESVhKYQvJRAAHF/hbm9wCat6K/DFK+c4bg==
验证用户:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get client.jack
[client.jack]
key = AQCJESVhKYQvJRAAHF/hbm9wCat6K/DFK+c4bg==
caps mon = "allow r"
caps osd = "allow rwx pool=mypool"
exported keyring for client.jack
2.5.3.3、ceph auth print-key:
只获取单个指定用户的 key 信息
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth print-key client.jack
AQCJESVhKYQvJRAAHF/hbm9wCat6K/DFK+c4bg==lmttrade@ceph-deploy:~/ceph-cluster$
2.5.3.4、修改用户能力:
使用 ceph auth caps 命令可以指定用户以及更改该用户的能力,设置新能力会完全覆盖当前的能力,因此要加上之前的用户已经拥有的能和新的能力,如果看当前能力,可以运行 cephauth get USERTYPE.USERID,如果要添加能力,使用以下格式时还需要指定现有能力:
root # ceph auth caps USERTYPE.USERID daemon 'allow [r|w|x|*|...] \
[pool=pool-name] [namespace=namespace-name]' [daemon 'allow [r|w|x|*|...] \
[pool=pool-name] [namespace=namespace-name]']
查看用户当前权限
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get client.jack
[client.jack]
key = AQCJESVhKYQvJRAAHF/hbm9wCat6K/DFK+c4bg==
caps mon = "allow r"
caps osd = "allow rwx pool=mypool"
exported keyring for client.jack
lmttrade@ceph-deploy:~/ceph-cluster$
修改用户权限
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth caps client.jack mon 'allow rw' osd 'allow rw pool=mypool'
updated caps for client.jack
验证
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get client.jack
[client.jack]
key = AQCJESVhKYQvJRAAHF/hbm9wCat6K/DFK+c4bg==
caps mon = "allow rw"
caps osd = "allow rw pool=mypool"
exported keyring for client.jack
2.5.3.5、删除用户:
要删除用户使用 ceph auth del TYPE.ID,其中 TYPE 是 client、osd、mon 或 mds 之一,ID 是用户名或守护进程的 ID。
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth del client.jack
updated
2.6、秘钥环管理:
ceph 的秘钥环是一个保存了 secrets、keys、certificates 并且能够让客户端通认证访问 ceph的 keyring file(集合文件),一个 keyring file 可以保存一个或者多个认证信息,每一个 key 都
有一个实体名称加权限,类型为:{client、mon、mds、osd}.name
当客户端访问 ceph 集群时,ceph 会使用以下四个密钥环文件预设置密钥环设置:
/etc/ceph/<$cluster name>.<user $type>.<user $id>.keyring #保存单个用户的 keyring
/etc/ceph/cluster.keyring #保存多个用户的 keyring
/etc/ceph/keyring #未定义集群名称的多个用户的 keyring
/etc/ceph/keyring.bin #编译后的二进制文件
2.6.1、导出用户认证信息至 keyring 文件:
将用户信息导出至 keyring 文件,对用户信息进行备份。
#创建用户:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get-or-create client.user1 mon 'allow r' osd 'allow * pool=mypool'
[client.user1]
key = AQBTMCVhDwgZOxAAPkydpZfOVyeZhDiDr4hVPg==
lmttrade@ceph-deploy:~/ceph-cluster$
#验证用户:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get client.user1
[client.user1]
key = AQBTMCVhDwgZOxAAPkydpZfOVyeZhDiDr4hVPg==
caps mon = "allow r"
caps osd = "allow * pool=mypool"
exported keyring for client.user1、
#创建 keyring 文件:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-authtool --create-keyring ceph.client.user1.keyring
creating ceph.client.user1.keyring
#导出 keyring 至指定文件
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get client.user1 -o ceph.client.user1.keyring
exported keyring for client.user1
#验证指定用户的 keyring 文件:
lmttrade@ceph-deploy:~/ceph-cluster$ cat ceph.client.user1.keyring
[client.user1]
key = AQBTMCVhDwgZOxAAPkydpZfOVyeZhDiDr4hVPg==
caps mon = "allow r"
caps osd = "allow * pool=mypool"
在创建包含单个用户的密钥环时,通常建议使用 ceph 集群名称、用户类型和用户名及 keyring来 命 名 , 并 将 其 保 存 在 /etc/ceph 目 录 中 。 例 如 为 client.user1 用 户 创 建ceph.client.user1.keyring。
2.6.2、从 keyring 文件恢复用户认证信息:
可以使用 ceph auth import -i 指定 keyring 文件并导入到 ceph,其实就是起到用户备份和恢复的目的:
首先删除用户
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth del client.user1
updated
确认用户被删除
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get client.user1
Error ENOENT: failed to find client.user1 in keyring
导入用户
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth import -i ceph.client.user1.keyring
imported keyring
验证已恢复用户
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get client.user1
[client.user1]
key = AQBTMCVhDwgZOxAAPkydpZfOVyeZhDiDr4hVPg==
caps mon = "allow r"
caps osd = "allow * pool=mypool"
exported keyring for client.user1
2.6.3:秘 钥 环 文 件 多 用 户:
一个 keyring 文件中可以包含多个不同用户的认证文件。
2.6.3.1:将多用户导出至秘钥环:
#创建 keyring 文件:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-authtool --create-keyring ceph.client.user.keyring
creating ceph.client.user.keyring
#把指定的 admin 用户的 keyring 文件内容导入到 user 用户的 keyring 文件:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-authtool ./ceph.client.user.keyring --import-keyring ./ceph.client.admin.keyring
importing contents of ./ceph.client.admin.keyring into ./ceph.client.user.keyring
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-authtool ./ceph.client.user.keyring --import-keyring ./ceph.client.user1.keyring
importing contents of ./ceph.client.user1.keyring into ./ceph.client.user.keyring
#验证 keyring 文件:
lmttrade@ceph-deploy:~/ceph-cluster$ cat ceph.client.user.keyring
[client.admin]
key = AQBpERphK5YALBAA6+plU2ue07Booh7WG63Iuw==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
[client.user1]
key = AQBTMCVhDwgZOxAAPkydpZfOVyeZhDiDr4hVPg==
caps mon = "allow r"
caps osd = "allow * pool=mypool"
3、Ceph RBD 使用:
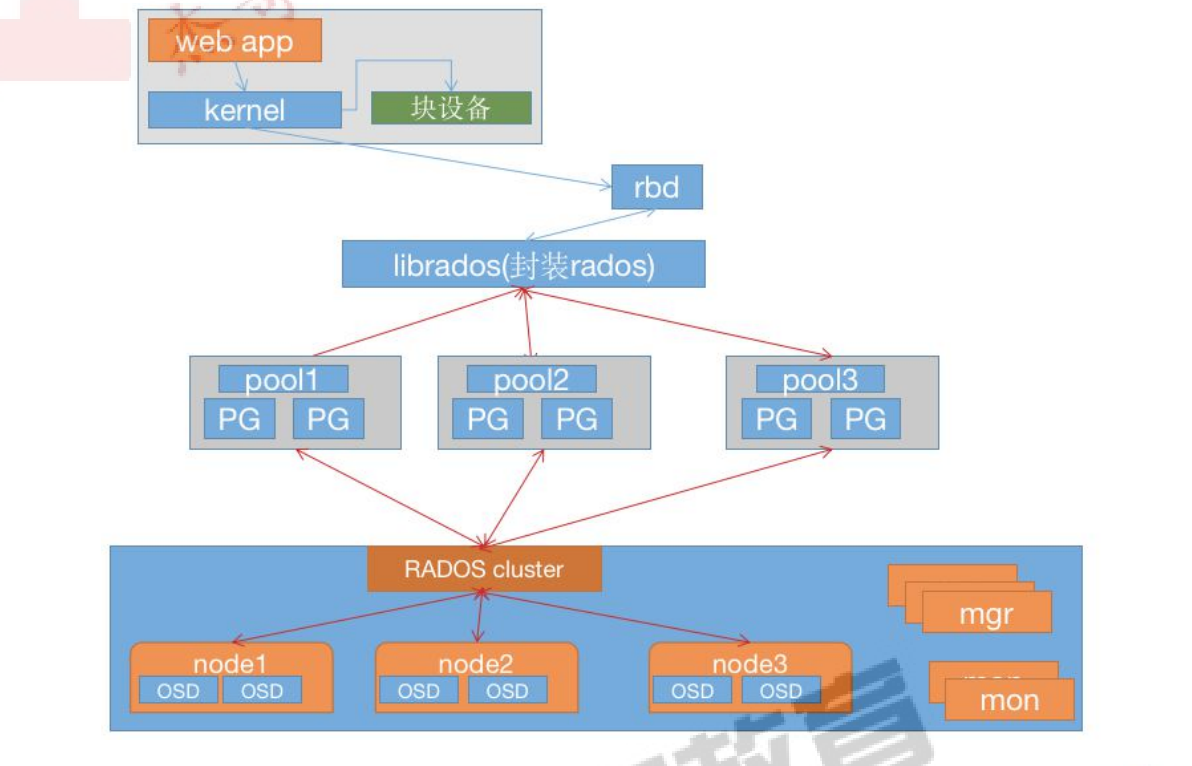
3.1、RBD架构图:
Ceph 可以同时提供对象存储 RADOSGW、块存储 RBD、文件系统存储 Ceph FS,RBD 即 RADOS Block Device 的简称,RBD 块存储是常用的存储类型之一,RBD 块设备类似磁盘可以被挂载,RBD 块设备具有快照、多副本、克隆和一致性等特性,数据以条带化的方式存储在 Ceph 集群的多个 OSD 中。
条带化技术就是一种自动的将 I/O 的负载均衡到多个物理磁盘上的技术,条带化技术就是将一块连续的数据分成很多小部分并把他们分别存储到不同磁盘上去。这就能使多个进程同时访问数据的多个不同部分而不会造成磁盘冲突,而且在需要对这种数据进行顺序访问的时候可以获得最大程度上的 I/O 并行能力,从而获得非常好的性能。
3.2:创建存储池:
#创建存储池:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph osd pool create rbd-data1 32 32
pool 'rbd-data1' created
#验证存储池
lmttrade@ceph-deploy:~/ceph-cluster$ ceph osd pool ls
device_health_metrics
mypool
cephfs-metadata
cephfs-data
rbd-data
#在存储池启用 rbd:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph osd pool application enable rbd-data1 rbd
enabled application 'rbd' on pool 'rbd-data1'
#初始化 rbd:
lmttrade@ceph-deploy:~/ceph-cluster$ rbd pool init -p rbd-data1
3.2.1 、创建 img 镜像:
rbd 存储池并不能直接用于块设备,而是需要事先在其中按需创建映像(image),并把映像文件作为块设备使用。rbd 命令可用于创建、查看及删除块设备相在的映像(image),以及克隆映像、创建快照、将映像回滚到快照和查看快照等管理操作。例如,下面的命令能够在指定的 RBD 即 rbd-data1 创建一个名为 myimg1 的映像:
3.2.2:创建镜像:
#创建三个镜像:
lmttrade@ceph-deploy:~/ceph-cluster$ rbd create data-img1 --size 3G --pool rbd-data1 --image-format 2 --image-feature layering
lmttrade@ceph-deploy:~/ceph-cluster$ rbd create data-img2 --size 3G --pool rbd-data1 --image-format 2 --image-feature layering
lmttrade@ceph-deploy:~/ceph-cluster$ rbd create data-img3 --size 3G --pool rbd-data1 --image-format 2 --image-feature layering
#验证镜像:
lmttrade@ceph-deploy:~/ceph-cluster$ rbd ls --pool rbd-data1
data-img1
data-img2
data-img3
#列出镜像个多信息:
lmttrade@ceph-deploy:~/ceph-cluster$ rbd ls --pool rbd-data1 -l
NAME SIZE PARENT FMT PROT LOCK
data-img1 3 GiB 2
data-img2 3 GiB 2
data-img3 3 GiB 2
3.3:配置客户端使用 RBD:
在 centos 或ubuntu 客户端挂载 RBD,并分别使用 admin 及普通用户挂载 RBD 并验证使用。
3.3.1、Ubuntu 客户端:
ubuntu客户端测试安装:ceph-common
root@ubuntu-node:~# sudo wget -q -O- 'https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add -
root@ubuntu-node:~# sudo echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >> /etc/apt/sources.list
root@ubuntu-node:~# apt update
root@ubuntu-node:~# apt install ceph-common -y
3.3.2、客户端配置yum源:
客户端要想挂载使用 ceph RBD,需要安装ceph客户端组件 ceph-common,但是ceph-common
不在 cenos 的 yum 仓库,因此需要单独配置 yum 源。#配置 yum 源:
[root@ansible-node0 ~]# yum install epel-release
[root@ansible-node0 ~]# yum install https://mirrors.aliyun.com/ceph/rpm-octopus/el7/noarch/ceph-release-1-1.el7.noarch.rpm -y
3.3.2:客端安装 ceph-common:
[root@ansible-node0 ~]#yum install ceph-common
3.3.3、客 户 端 使 用 普 通 账 户 挂 载 并 使用 用 RBD
测试客户端使用普通账户挂载并使用 RBD
3.3.3.1:创建普通账户并授权:
#创建普通账户
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth add client.shijie mon 'allow r' osd 'allow rwx pool=rbd-data1'
added key for client.shijie
#验证用户信息
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get client.shijie
[client.shijie]
key = AQB5QiVh53U/DxAA7BFgQmcKJgFjF1gDQA6S1w==
caps mon = "allow r"
caps osd = "allow rwx pool=rbd-data1"
exported keyring for client.shijie
#创建用 keyring 文件
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-authtool --create-keyring ceph.client.shijie.keyring
creating ceph.client.shijie.keyring
#导出用户 keyring
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get client.shijie -o ceph.client.shijie.keyring
exported keyring for client.shijie
#验证指定用户的 keyring 文件
lmttrade@ceph-deploy:~/ceph-cluster$ cat ceph.client.shijie.keyring
[client.shijie]
key = AQB5QiVh53U/DxAA7BFgQmcKJgFjF1gDQA6S1w==
caps mon = "allow r"
caps osd = "allow rwx pool=rbd-data1"
#往centos 客户端拷贝:ceph.conf 、 ceph.client.shijie.keyring
lmttrade@ceph-deploy:~/ceph-cluster$ scp ceph.conf ceph.client.shijie.keyring root@192.168.0.240:/etc/ceph/
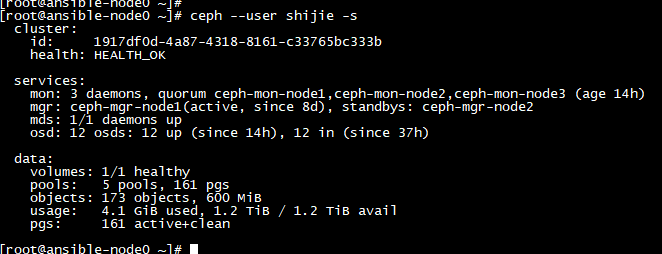
#在centos 客户端中测试用普通用户shijie 能否能读出 ceph -s
[root@ansible-node0 ~]# ceph --user shijie -s
客户端上操作:
3.3.3.2:映射rbd: (客户端上操作)
使用普通用户权限映射 rbd
#映射 rbd
[root@ansible-node0 ~]# rbd --user shijie -p rbd-data1 map data-img1
/dev/rbd0
#查看磁盘rbd0 是否存
[root@ansible-node0 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 1000M 0 part /boot
└─sda2 8:2 0 49G 0 part /
sr0 11:0 1 4.5G 0 rom
rbd0 253:0 0 3G 0 disk
#验证 rbd
[root@ansible-node0 ~]# fdisk -l /dev/rbd0
磁盘 /dev/rbd0:3221 MB, 3221225472 字节,6291456 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):4194304 字节 / 4194304 字节
创建测试目录
[root@ansible-node0 ~]# mkdir /data/mysql
[root@ansible-node0 ~]# mkfs.xfs /dev/rbd0
[root@ansible-node0 ~]# mount /dev/rbd0 /data/mysql
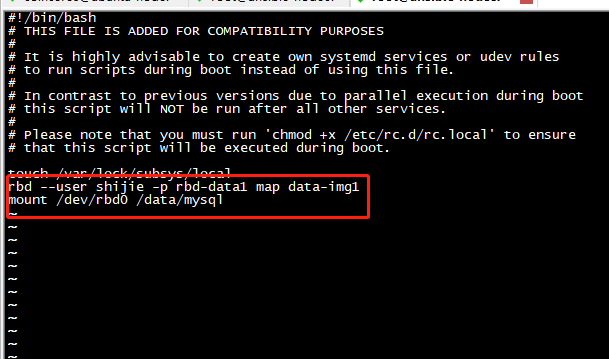
开机自动挂载:
[root@ansible-node0 ~]# cat /etc/rc.d/rc.local
rbd --user shijie -p rbd-data1 map data-img1
mount /dev/rbd0 /data/mysql
添加可执行权限
[root@ansible-node0 ~]# chmod a+x /etc/rc.d/rc.local
扩容
回到 deploy节点做扩容:(把data-img1 扩容到20G)
lmttrade@ceph-deploy:~/ceph-cluster$ rbd resize --pool rbd-data1 --image data-img1 --size 20G
在客户端上执行
[root@ansible-node0 ~]# resize2fs /dev/rbd0
以上扩容不需要停服和卸载
MDS 扩容 集群
另外两个mds 我们放在Mon2 mon3 节点上面
coinceres@ceph-mon-node2:~$ sudo su - root
root@ceph-mon-node2:~# apt install ceph-mds
coinceres@ceph-mon-node3:~$ sudo su - root
root@ceph-mon-node3:~# apt install ceph-mds
deploy节点 查看 当前fs 数量
lmttrade@ceph-deploy:~/ceph-cluster$ ceph fs status
mycephfs - 0 clients
========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ceph-mgr-node1 Reqs: 0 /s 12 15 12 0
POOL TYPE USED AVAIL
cephfs-metadata metadata 376k 377G
cephfs-data data 2124M 377G
MDS version: ceph version 16.2.5 (0883bdea7337b95e4b611c768c0279868462204a) pacific (stable)
lmttrade@ceph-deploy:~/ceph-cluster$
创建客户端普通用户账号
#创建账户
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth add client.yanyan mon 'allow r' mds 'allow rw' osd 'allow rwx pool=cephfs-data'
added key for client.yanyan
#验证账户
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get client.yanyan
[client.yanyan]
key = AQCfqSVhv83RLRAA8xYkF+1VTcGmpuVOPC9eaQ==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rwx pool=cephfs-data"
exported keyring for client.yanyan
#创建用 keyring 文件
lmttrade@ceph-deploy:~/ceph-cluster$ ceph auth get client.yanyan -o ceph.client.yanyan.keyring
exported keyring for client.yanyan
#创建 key 文件:
ceph auth print-key client.yanyan > yanyan.key
deploy 节点 拷贝配置文件到centos客户端上去
lmttrade@ceph-deploy:~/ceph-cluster$ scp ceph.conf ceph.client.yanyan.keyring yanyan.key root@192.168.0.240:/etc/ceph/
在客户端上验证 yanyan 这个用户是否可用
[root@ansible-node0 ~]# ceph --user yanyan -s
cluster:
id: 1917df0d-4a87-4318-8161-c33765bc333b
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-mon-node1,ceph-mon-node2,ceph-mon-node3 (age 2h)
mgr: ceph-mgr-node1(active, since 8d), standbys: ceph-mgr-node2
mds: 1/1 daemons up
osd: 12 osds: 9 up (since 2h), 9 in (since 2h)
data:
volumes: 1/1 healthy
pools: 5 pools, 161 pgs
objects: 192 objects, 614 MiB
usage: 4.4 GiB used, 896 GiB / 900 GiB avail
pgs: 161 active+clean
内核空间挂载 ceph-fs:
客户端挂载有两种方式,一是内核空间一是用户空间,内核空间挂载需要内核支持 ceph 模块,用户空间挂载需要安装 ceph-fuse
客户端通过 key 文件挂载:
[root@ansible-node0 ~]# mount -t ceph 192.168.0.181:6789,192.168.0.184:6789,192.168.0.185:6789:/ /data/mysql -o name=yanyan,secretfile=/etc/ceph/yanyan.key

开机启动自动挂载
192.168.0.181:6789 192.168.0.184:6789 192.168.0.185:6789: / /data/mysql ceph defaults,name=yanyan,secretfile=/etc/ceph/yanyan.key,_netdev 0 0

ceph mds 高可用:
Ceph mds(etadata service)作为 ceph 的访问入口,需要实现高性能及数据备份,假设启动 4个 MDS 进程,设置 2 个 Rank。这时候有 2 个 MDS 进程会分配给两个 Rank,还剩下 2 个 MDS进程分别作为另外个的备份。
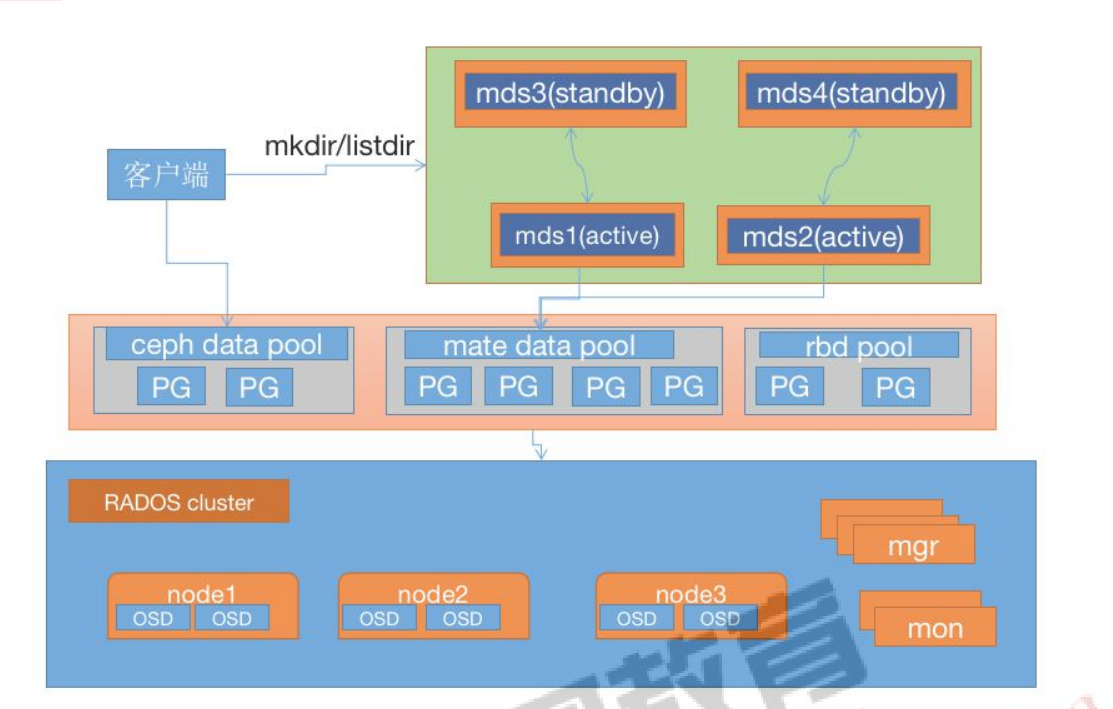
设置每个 Rank 的备份 MDS,也就是如果此 Rank 当前的 MDS 出现问题马上切换到另个 MDS。设置备份的方法有很多,常用选项如下。
mds_standby_replay:值为 true 或 false,true 表示开启 replay 模式,这种模式下主 MDS 内的数量将实时与从 MDS 同步,如果主宕机,从可以快速的切换。如果为 false 只有宕机的时候才去同步数据,这样会有一段时间的中断。
mds_standby_for_name:设置当前 MDS 进程只用于备份于指定名称的 MDS。
mds_standby_for_rank:设置当前 MDS 进程只用于备份于哪个 Rank,通常为 Rank 编号。另外在存在之个 CephFS 文件系统中,还可以使用 mds_standby_for_fscid 参数来为指定不同的文件系统。
mds_standby_for_fscid:指定 CephFS 文件系统 ID,需要联合 mds_standby_for_rank 生效,如果设置 mds_standby_for_rank,那么就是用于指定文件系统的指定 Rank,如果没有设置,就是指定文件系统的所有 Rank。
当前 mds 服务器状态
deploy 节点
lmttrade@ceph-deploy:~/ceph-cluster$ ceph mds stat
mycephfs:1 {0=ceph-mgr-node1=up:active}
安装mds
root@ceph-mon-node2:~# apt install ceph-mds=16.2.5-1bionic
root@ceph-mon-node3:~# apt install ceph-mds=16.2.5-1bionic
添加MDS服务器
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-deploy mds create ceph-mon-node2
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-deploy mds create ceph-mon-node3
查看一主

状态查看
mttrade@ceph-deploy:~/ceph-cluster$ ceph fs status
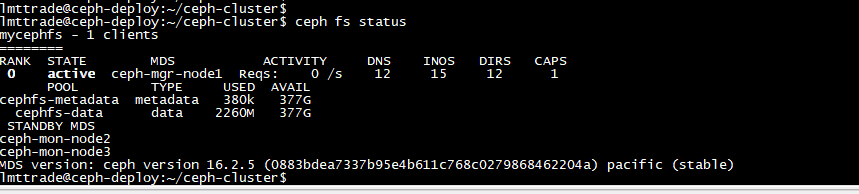
验证 mds 服务器当前状态:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph mds stat
mycephfs:1 {0=ceph-mgr-node1=up:active} 2 up:standby

 浙公网安备 33010602011771号
浙公网安备 33010602011771号