
ubuntu系统中ceph 部署流程-上篇
ceph
ceph简介:
Ceph 是一个开源的分布式存储系统, 同时支持对象存储、块设备、文件系统
Ceph 提供对象存储/块设备/文件存储类型。
ceph 的设计思想:
Ceph 的设计旨在实现以下目标:
- 每一组件皆可扩展
- 无单点故障
- 基于软件(而非专用设备)并且开源(无供应商锁定)
- 在现有的廉价硬件上运行
- 尽可能自动管理,减少用户干预
ceph 集群的组成部分:
Monitor(ceph-mon) ceph 监视器:
在一个主机上运行的一个守护进程,用于维护集群状态映射(maintains maps of thecluster state),比如 ceph 集群中有多少存储池、每个存储池有多少 PG 以及存储池和 PG的映射关系等, monitor map, manager map, the OSD map, the MDS map, and the CRUSH map,这些映射是 Ceph 守护程序相互协调所需的关键群集状态,此外监视器还负责管理守护程序和客户端之间的身份验证(认证使用 cephX 协议)。通常至少需要三个监视器才能实现冗余和高可用性。
Managers(ceph-mgr)的功能:
在一个主机上运行的一个守护进程,Ceph Manager 守护程序(ceph-mgr)负责跟踪运行时指标和 Ceph 集群的当前状态,包括存储利用率,当前性能指标和系统负载。CephManager 守护程序还托管基于 python 的模块来管理和公开 Ceph 集群信息,包括基于 Web的 Ceph 仪表板和 REST API。高可用性通常至少需要两个管理器。
Ceph OSDs( 对象存储守护程序 ceph-osd) :
提供存储数据,操作系统上的一个磁盘就是一个 OSD 守护程序,OSD 用于处理 ceph集群数据复制,恢复,重新平衡,并通过检查其他 Ceph OSD 守护程序的心跳来向 Ceph监视器和管理器提供一些监视信息。通常至少需要 3 个 Ceph OSD 才能实现冗余和高可用性。
MDS(ceph 元数据服务器 ceph-mds):
代表 ceph 文件系统(NFS/CIFS)存储元数据,(即 Ceph 块设备和 Ceph 对象存储不使用MDS)
Ceph 的管理节点:
1.ceph 的常用管理接口是一组命令行工具程序,例如 rados、ceph、rbd 等命令,ceph 管理员可以从某个特定的 ceph-mon 节点执行管理操作
2.推荐使用部署专用的管理节点对 ceph 进行配置管理、升级与后期维护,方便后期权限管理,管理节点的权限只对管理人员开放,可以避免一些不必要的误操作的发生。
ceph 逻辑组织架构:
Pool:存储池、分区,存储池的大小取决于底层的存储空间。
PG(placement group):一个 pool 内部可以有多个 PG 存在,pool 和 PG 都是抽象的逻辑概念,一个 pool 中有多少个 PG 可以通过公式计算。
OSD(Object Storage Daemon,对象存储设备):每一块磁盘都是一个 osd,一个主机由一个或多个 osd 组成.
ceph 集群部署好之后,要先创建存储池才能向 ceph 写入数据,文件在向 ceph 保存之前要先进行一致性 hash 计算,计算后会把文件保存在某个对应的 PG 的,此文件一定属于某个
pool 的一个 PG,在通过 PG 保存在 OSD 上。数据对象在写到主 OSD 之后再同步对从 OSD 以实现数据的高可用。
ceph 存储文件
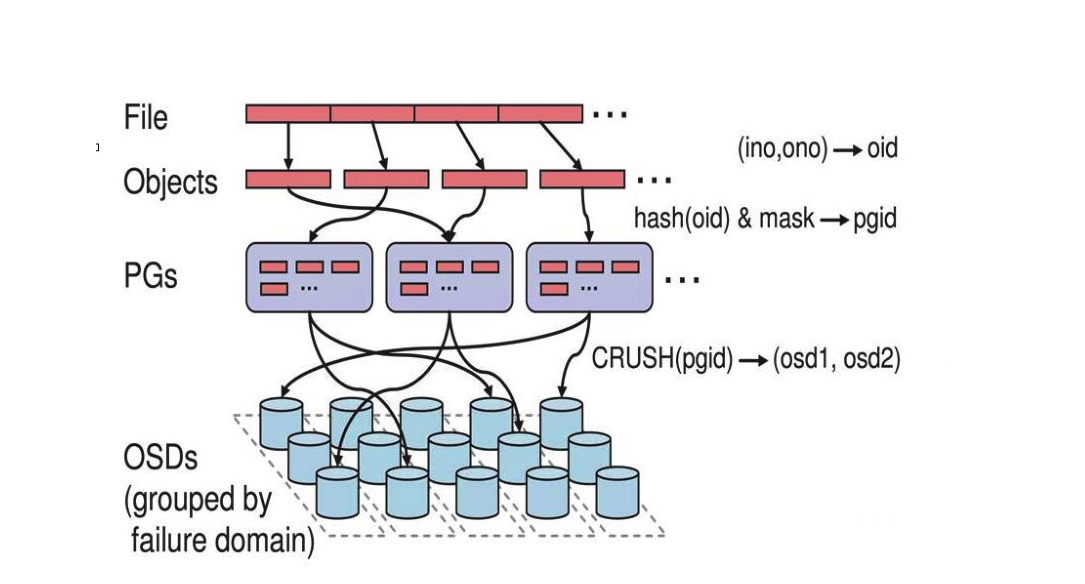
第一步: 计算文件到对象的映射:
计算文件到对象的映射,假如 file 为客户端要读写的文件,得到 oid(object id) = ino + ono
ino:inode number (INO),File 的元数据序列号,File 的唯一 id。
ono:object number (ONO),File 切分产生的某个 object 的序号,默认以 4M 切分一个块大
小。
第二步:通过 hash 算法计算出文件对应的 pool 中的 PG:
通过一致性 HASH 计算 Object 到 PG, Object -> PG 映射 hash(oid) & mask-> pgid
第三步: 通过 CRUSH 把对象映射到 PG 中的 OSD
通过 CRUSH 算法计算 PG 到 OSD,PG -> OSD 映射:[CRUSH(pgid)->(osd1,osd2,osd3)]
第四步:PG 中的主 OSD 将对象写入到硬盘
第五步: 主 OSD 将数据同步给备份 OSD,并等待备份 OSD 返回确认
第六步: 主 OSD 将写入完成返回给客户端
准备环境
服务器要求
最小基本的硬件配置:(线下和实验环境中使用)
- mon监视服务: 4核cpu 4g内存 硬盘100g 2块网卡
- mgr守护进程服务: 4核cpu 4g内存 硬盘100g 2块网卡
- osd存储服务:4核cpu 8g内存 硬盘100g, 每台osd存储机器外加不低于3块SATA硬盘各100g (主要看需求) 2块网卡
推荐硬件配置:(建议使用物理机器来部署)
- mon监视服务: 16核cpu 16g内存 硬盘200g 2块万兆网卡 (可以使用虚拟机部署)
- mgr守护进程服务: 16核cpu 16g内存 硬盘200g 2块万兆网卡 (假如使用定向存储 资源分配就要翻倍 32核cpu,32g内存)
- osd存储服务:32核cpu 32g 内存 硬盘使用ssd 2块万兆网卡 (ssd容量和多少块 看个人需求来设定 没有准确数量但是每天台osd 不低于三块)
服务器最好可以访问外网,会有yum 安装包需求
软件环境:
| 软件 | 版本 |
| 操作系统 | Ubuntu 18.04.5 LTS |
| ceph | Paciflc |
服务器整体规划
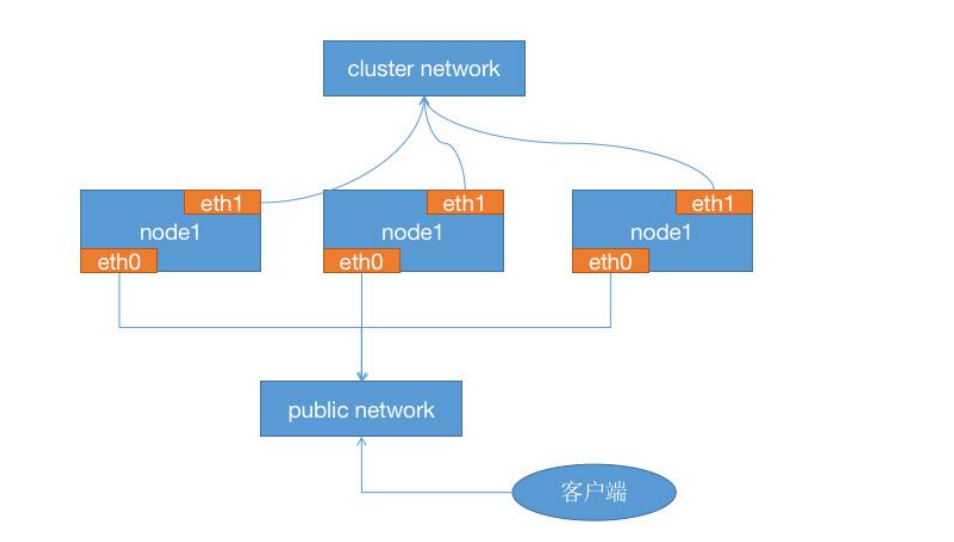
1、四台服务器作为ceph集群OSD存储服务器,每台服务器支持两个网络,public网络针对于客户端访问,cluster网络 用于集群管理及数据同步,每台三块或以上的磁盘
| 角色 | public网络 | cluster网络 |
| ceph-osd-node1 | 192.168.0.186 | 10.20.3.26 |
| ceph-osd-node2 | 192.168.0.187 | 10.20.3.27 |
| ceph-osd-node3 | 192.168.0.188 | 10.20.3.28 |
| ceph-osd-node4 | 192.168.0.189 | 10.20.3.29 |
| 各个存储服务器磁盘划分 | ||
| /dev/sdb /dev/sdc /dev/sdd #100G | ||
2、三台服务器作为ceph集群Mon监视服务器,每台服务器可以和ceph集群的cluster网络通信
| 角色 | public网络 | cluster网络 |
| ceph-mon-node1 | 192.168.0.183 | 10.20.3.23 |
| ceph-mon-node2 | 192.168.0.184 | 10.20.3.24 |
| ceph-mon-node3 | 192.168.0.185 | 10.20.3.25 |
3、两个ceph-mgr管理服务器,可以和ceph集群的cluster网络通信。
| 角色 | public网络 | cluster网络 |
| ceph-mgr-node1 | 192.168.0.181 | 10.20.3.21 |
| ceph-mgr-node2 | 192.168.0.182 | 10.20.3.22 |
4、一个服务器用于部署 ceph 集群即安装 Ceph-deploy,也可以和 ceph-mgr 等复用
| 角色 | public网络 | cluster网络 |
| ceph-deploy | 192.168.0.180 | 10.20.3.20 |
5、创建一个普通用户,能够通过 sudo 执行特权命令,配置主机名解析,ceph 集群部署过程中需要对各主机配置不通的主机名,另外如果是 centos 系统则需要关闭各服务器的防火墙和 selinux
操作系统环境准备
1、时间同步
sudo apt-get update
sudo apt-get install ntpdate
sudo ntpdate ntp1.aliyun.com
sudo systemctl status systemd-timesyncd.service \\查看ntpdate 是否启动中
sudo ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime 同步时区
加入计划任务时间每隔五分钟同步一次 (切换到root下执行)
echo "*/5 * * * * /usr/sbin/ntpdate time1.aliyun.com &> /dev/null && hwclock -w &> /dev/null" >> /var/spool/cron/crontabs/root
2、关闭防火墙
~$ sudo ufw status \\查看当前防火墙状态;inactive状态是防火墙关闭状态 active是开启状态。
Status: inactive
3、配置 hosts 解析 (所有ceph机器都要相互指定)
cat /etc/hosts
192.168.0.180 ceph-deploy
192.168.0.181 ceph-mgr-node1
192.168.0.182 ceph-mgr-node2
192.168.0.183 ceph-mon-node1
192.168.0.184 ceph-mon-node2
192.168.0.185 ceph-mon-node3
192.168.0.186 ceph-osd-node1
192.168.0.187 ceph-osd-node2
192.168.0.188 ceph-osd-node3
192.168.0.189 ceph-osd-node4
ceph集群部署方式:
ceph-ansible:https://github.com/ceph/ceph-ansible #python
ceph-salt:https://github.com/ceph/ceph-salt #python
ceph-container:https://github.com/ceph/ceph-container #shell
ceph-chef:https://github.com/ceph/ceph-chef #Ruby
cephadm: https://docs.ceph.com/en/latest/cephadm/ #ceph 官方在 ceph 15 版本加入的
ceph 部署工具
ceph-deploy:https://github.com/ceph/ceph-deploy #python
是一个 ceph 官方维护的基于 ceph-deploy 命令行部署 ceph 集群的工具,基于 ssh 执行可
以 sudo 权限的 shell 命令以及一些 python 脚本 实现 ceph 集群的部署和管理维护。
Ceph-deploy 只用于部署和管理 ceph 集群,客户端需要访问 ceph,需要部署客户端工具。
https://mirrors.tuna.tsinghua.edu.cn/ceph/ #使用清华大学镜像源
仓库准备
各个节点配置ceph yum 仓库
导入key文件(deploy,mgr,mon,osd,客户端 机器上都要导入)
sudo wget -q -O- 'https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add -
配置yum 文件
sudo echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >> /etc/apt/sources.list
更新
apt update
创建 ceph 用户
推荐使用指定的普通用户部署和运行 ceph 集群,普通用户只要能以非交互方式执行 sudo
命令执行一些特权命令即可,新版的 ceph-deploy 可以指定包含 root 的在内只要可以执行
sudo 命令的用户,不过仍然推荐使用普通用户,比如 ceph、cephuser、cephadmin 这样
的用户去管理 ceph 集群。
在包含 ceph-deploy 节点的存储节点、mon 节点和 mgr 节点等创建 ceph 用户。
各服务器创建lmttrade用户
groupadd -r -g 2025 lmttrade && useradd -r -m -s /bin/bash -u 2025 -g 2025 lmttrade && echo lmttrade:123456 | chpasswd
各服务器允许 lmttrade 用户以 sudo 执行特权命令:
cat /etc/sudoers
lmttrade ALL=(ALL) NOPASSWD: ALL
或者
echo "lmttrade ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
配置免秘钥登录:
在ceph-deploy 节点配置允许以非交互的方式登录到各 ceph node/mon/mgr 节点,即在
ceph-deploy 节点生成秘钥对,然后分发公钥到各被管理节点:
这里我们在 deploy 节点这台机器上面来操作 创建秘钥 (这里以 lmttrade 普通用户下操作)
coinceres@ceph-deploy:~$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/coinceres/.ssh/id_rsa):
Created directory '/home/coinceres/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/coinceres/.ssh/id_rsa.
Your public key has been saved in /home/coinceres/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:bNZ8LrlI68g4bGuKce4GISUf59p/S2Ta4gguxv80gus coinceres@ceph-deploy
The key's randomart image is:
+---[RSA 2048]----+
| |
|. o . |
| + + |
|o . . . o |
|.. o S o . |
|. o . B + |
|oooo +o + o . |
|.Oo.B=o=.o o |
|+E*==++o=.. |
+----[SHA256]-----+
ceph@ceph-deploy:~$ ssh-copy-id -i .ssh/id_rsa.pub lmttrade@192.168.0.180
ceph@ceph-deploy:~$ ssh-copy-id -i .ssh/id_rsa.pub lmttrade@192.168.0.181
ceph@ceph-deploy:~$ ssh-copy-id -i .ssh/id_rsa.pub lmttrade@192.168.0.182
ceph@ceph-deploy:~$ ssh-copy-id -i .ssh/id_rsa.pub lmttrade@192.168.0.183
ceph@ceph-deploy:~$ ssh-copy-id -i .ssh/id_rsa.pub lmttrade@192.168.0.184
ceph@ceph-deploy:~$ ssh-copy-id -i .ssh/id_rsa.pub lmttrade@192.168.0.185
ceph@ceph-deploy:~$ ssh-copy-id -i .ssh/id_rsa.pub lmttrade@192.168.0.186
ceph@ceph-deploy:~$ ssh-copy-id -i .ssh/id_rsa.pub lmttrade@192.168.0.187
ceph@ceph-deploy:~$ ssh-copy-id -i .ssh/id_rsa.pub lmttrade@192.168.0.188
ceph@ceph-deploy:~$ ssh-copy-id -i .ssh/id_rsa.pub lmttrade@192.168.0.189
安装 ceph 部署工具:
在 ceph 部署服务器安装部署工具 ceph-deploy 我们在主机名为ceph-deploy 这台 机器上操作
安装ceph-deploy 包
coinceres@ceph-deploy:~$ sudo apt install ceph-deploy
初始化 mon 节点:
在ceph-deploy管理节点初始化mon节点
coinceres@ceph-deploy:~$ mkdir ceph-cluster
coinceres@ceph-deploy:~$ cd ceph-cluster/
coinceres@ceph-deploy:~/ceph-cluster$
初始化 mon 节点过程如下:
Ubuntu 各服务器需要单独安装 Python2:
apt install python2.7 -y
ln -sv /usr/bin/python2.7 /usr/bin/python2
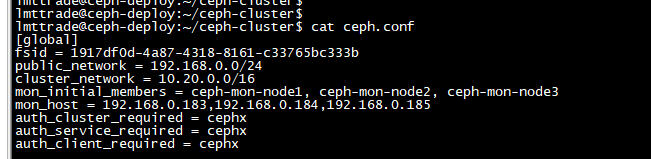
[ceph@ceph-deploy ceph-cluster]$ ceph-deploy new --cluster-network 10.20.0.0/16 --public-network 192.168.0.0/24 ceph-mon-node1 ceph-mon-node2 ceph-mon-node3
配置 mon 节点并生成及同步秘钥
单独在3台mon节点上安装ceph-mon
root@ceph-mon-node1:~# apt install ceph-mon -y
root@ceph-mon-node2:~# apt install ceph-mon -y
root@ceph-mon-node3:~# apt install ceph-mon -y
在deploy 初始化mon 节点
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-deploy mon create-initial
分发 admin 秘钥:
在ceph-deploy 节点把配置文件和admin 密钥拷贝至 Ceph集群需要执行ceph 管理命令的
节点,从而不需要后期通过 ceph 命令对 ceph 集群进行管理配置的时候每次都需要指定
ceph-mon 节点地址和 ceph.client.admin.keyring 文件,另外各 ceph-mon 节点也需要同步
ceph 的集群配置文件与认证文件。
如果在 ceph-deploy 节点管理集群:
安装ceph-common 命令
root@ceph-deploy:~# apt install ceph-common -y
root@ceph-osd-node1:~# apt install ceph-common -y
root@ceph-osd-node2:~# apt install ceph-common -y
root@ceph-osd-node3:~# apt install ceph-common -y
root@ceph-osd-node4:~# apt install ceph-common -y
推送到 admin 秘钥到 deploy 和 osd 节点
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-deploy admin ceph-deploy ceph-osd-node1 ceph-osd-node2 ceph-osd-node3 ceph-osd-node4
ceph 节点验证秘钥:
root@ceph-osd-node1:~# ll /etc/ceph/
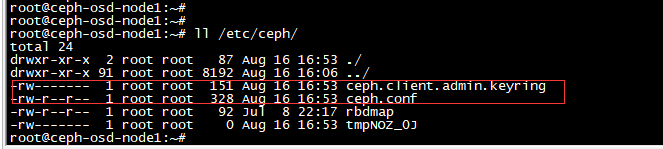
ceph.client.admin.keyring 这个文件存在就行
以上方法可以到另外三台osd 节点查看
认证文件的属主和属组为了安全考虑,默认设置为了 root 用户和 root 组,如果需要 ceph
用户也能执行 ceph 命令,那么就需要对 ceph 用户进行授权,(这里是在 lmttrade用户下操作 所有用户只能改成lmttrade)
lmttrade@ceph-deploy:~/ceph-cluster$ sudo setfacl -m u:lmttrade:rw /etc/ceph/ceph.client.admin.keyring
root@ceph-osd-node1:~# setfacl -m u:lmttrade:rw /etc/ceph/ceph.client.admin.keyring
root@ceph-osd-node2:~# setfacl -m u:lmttrade:rw /etc/ceph/ceph.client.admin.keyring
root@ceph-osd-node3:~# setfacl -m u:lmttrade:rw /etc/ceph/ceph.client.admin.keyring
root@ceph-osd-node4:~# setfacl -m u:lmttrade:rw /etc/ceph/ceph.client.admin.keyring
lmttrade@ceph-deploy:~/ceph-cluster$ ceph -s
cluster:
id: 1917df0d-4a87-4318-8161-c33765bc333b
health: HEALTH_WARN
mons are allowing insecure global_id reclaim
services:
mon: 3 daemons, quorum ceph-mon-node1,ceph-mon-node2,ceph-mon-node3 (age 113m)
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
部署 ceph-mgr 节点
root@ceph-mgr-node1:~# apt install ceph-mgr -y
root@ceph-mgr-node2:~# apt install ceph-mgr -y
创建mgr节点 在deploy节点 上操作
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-deploy mgr create ceph-mgr-node1 ceph-mgr-node2
验证
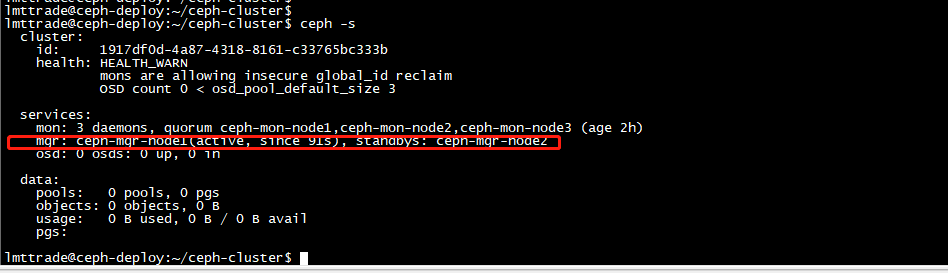
测试 ceph 命令
lmttrade@ceph-deploy:~/ceph-cluster$ ceph -s
cluster:
id: 1917df0d-4a87-4318-8161-c33765bc333b
health: HEALTH_WARN
mons are allowing insecure global_id reclaim \\报错解决方法: ceph config set mon auth_allow_insecure_global_id_reclaim false
OSD count 0 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum ceph-mon-node1,ceph-mon-node2,ceph-mon-node3 (age 2h)
mgr: ceph-mgr-node1(active, since 36m), standbys: ceph-mgr-node2
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
添加OSD
1、初始化osd node 节点 在deploy 节点上执行
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-deploy install --no-adjust-repos --nogpgcheck ceph-osd-node1 ceph-osd-node2 ceph-osd-node3 ceph-osd-node4
准备 OSD 节点
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific ceph-osd-node1 ceph-osd-node2 ceph-osd-node3 ceph-osd-node4
列出 ceph osd-node 节点磁盘:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-deploy disk list ceph-osd-node1 ceph-osd-node2 ceph-osd-node3 ceph-osd-node4
擦除osd-node节点 添加的数据磁盘
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-osd-node1 /dev/sdb /dev/sdc /dev/sdd
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-osd-node2 /dev/sdb /dev/sdc /dev/sdd
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-osd-node3 /dev/sdb /dev/sdc /dev/sdd
lmttrade@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-osd-node4 /dev/sdc /dev/sdb /dev/sdd
添加 OSD :
数据分类保存方式:
- Data:即 ceph 保存的对象数据
- Block: rocks DB 数据即元数据
- block-wal:数据库的 wal 日志

添加主机磁盘osd
osd的id从0开始使用
ceph-deploy osd create ceph-osd-node1 --data /dev/sdb
ceph-deploy osd create ceph-osd-node1 --data /dev/sdc
ceph-deploy osd create ceph-osd-node1 --data /dev/sdd
ceph-deploy osd create ceph-osd-node2 --data /dev/sdb
ceph-deploy osd create ceph-osd-node2 --data /dev/sdc
ceph-deploy osd create ceph-osd-node2 --data /dev/sdd
ceph-deploy osd create ceph-osd-node3 --data /dev/sdb
ceph-deploy osd create ceph-osd-node3 --data /dev/sdc
ceph-deploy osd create ceph-osd-node3 --data /dev/sdd
ceph-deploy osd create ceph-osd-node4 --data /dev/sdc
ceph-deploy osd create ceph-osd-node4 --data /dev/sdb
ceph-deploy osd create ceph-osd-node4 --data /dev/sdd
lmttrade@ceph-deploy:~/ceph-cluster$ ceph -s
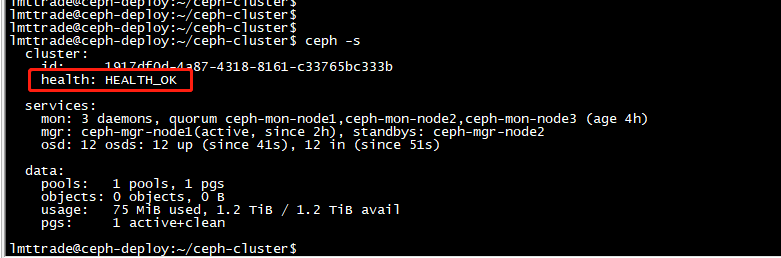

以上是部署完成
测试上传与下载数据:
存取数据时,客户端必须首先连接至 RADOS 集群上某存储池,然后根据对象名称由相关的CRUSH 规则完成数据对象寻址。于是,为了测试集群的数据存取功能,这里首先创建一个
用于测试的存储池 mypool,并设定其 PG 数量为 32 个。
创建pool:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph osd pool create mypool 32 32
pool 'mypool' created
查看pool
lmttrade@ceph-deploy:~/ceph-cluster$ ceph osd pool ls
device_health_metrics
mypool
验证 PG 与 PGP 组合:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph pg ls-by-pool mypool | awk '{print $1,$2,$15}'
PG OBJECTS ACTING
2.0 0 [3,6,0]p3
2.1 0 [9,0,6]p9
2.2 0 [5,1,10]p5
2.3 0 [11,5,8]p11
2.4 0 [1,7,9]p1
2.5 0 [8,0,4]p8
2.6 0 [1,6,10]p1
2.7 0 [3,10,2]p3
2.8 0 [9,7,0]p9
2.9 0 [1,4,9]p1
2.a 0 [6,1,9]p6
2.b 0 [8,5,10]p8
2.c 0 [6,0,5]p6
2.d 0 [6,10,2]p6
2.e 0 [2,8,9]p2
2.f 0 [8,9,4]p8
2.10 0 [10,7,0]p10
2.11 0 [9,3,1]p9
2.12 0 [7,1,3]p7
2.13 0 [9,4,2]p9
2.14 0 [3,7,11]p3
2.15 0 [9,1,8]p9
2.16 0 [5,7,11]p5
2.17 0 [5,6,2]p5
2.18 0 [9,4,6]p9
2.19 0 [0,4,7]p0
2.1a 0 [3,8,2]p3
2.1b 0 [6,5,11]p6
2.1c 0 [8,4,1]p8
2.1d 0 [10,6,3]p10
2.1e 0 [2,7,9]p2
2.1f 0 [0,3,8]p0
当前的 ceph 环境还没还没有部署使用块存储和文件系统使用 ceph,也没有使用对象存储 的客户端,但是 ceph 的 rados 命令可以实现访问 ceph 对象存储的功能:
上传文件:
把 syslog 文件上传到 mypool 并指定对象 id 为 msg1
lmttrade@ceph-deploy:~/ceph-cluster$ sudo rados put msg1 /var/log/syslog --pool=mypool
列出存储池里有哪些数据
lmttrade@ceph-deploy:~/ceph-cluster$ rados ls --pool=mypool
msg1
查看文件信息:
ceph osd map 命令可以获取到存储池中数据对象的具体位置信息:
lmttrade@ceph-deploy:~/ceph-cluster$ ceph osd map mypool msg1
osdmap e70 pool 'mypool' (2) object 'msg1' -> pg 2.c833d430 (2.10) -> up ([10,7,0], p10) acting ([10,7,0], p10)
下载文件:
把存储池里 对象id 为msg1 文件下载到opt下命名为my.txt
lmttrade@ceph-deploy:~/ceph-cluster$ sudo rados get msg1 --pool=mypool /opt/my.txt
验证下载文件:
lmttrade@ceph-deploy:~/ceph-cluster$ head /opt/my.txt

修改文件:
这里我们使用passwd文件做代替来验证
上传
lmttrade@ceph-deploy:~/ceph-cluster$ sudo rados put msg1 /etc/passwd --pool=mypool \\这里是把新文件覆盖旧文件
下载
lmttrade@ceph-deploy:~/ceph-cluster$ sudo rados get msg1 --pool=mypool /opt/2.txt \\下载验证是否是新文件
验证
lmttrade@ceph-deploy:~/ceph-cluster$ head /opt/2.txt
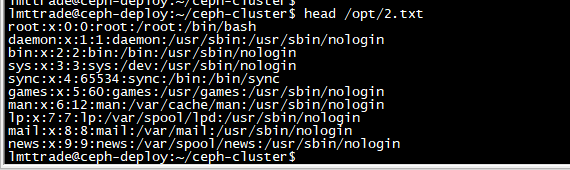
查看结果是新文件说明 修改成功
删除文件:
lmttrade@ceph-deploy:~/ceph-cluster$ sudo rados rm msg1 --pool=mypool \\删除mypool存储池 里的id 为msg1 的文件
lmttrade@ceph-deploy:~/ceph-cluster$ rados ls --pool=mypool \\查看id 为msg1 的文件 不在了 说明删除成功
------------恢复内容结束------------
------------恢复内容结束------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号