第十三章 设计搜索完成系统
本章设计一个搜索自动补全系统,也称为“设计计前K个搜索次数最多的查询”
了解问题并建立设计范围
要求总结:
- 快速响应时间:Facebook自动补全的文章建议,当用户输入搜索查询时,需要在100毫秒内返回结果
- 相关:搜索结果应与搜索词相关
- 排序:结果必须要流行度或其他排名模型排序
- 可扩展:可以处理高流量
- 高可用性:当系统部分离线、速度减慢或遇到意外的网络错误时,系统应保持可用和可访问
提出高级设计
该系统可被拆分为两个服务:
- 数据收集服务:收集用户输入查询并将它们实时聚合
- 数据查询服务:给定搜索查询结果或前缀,返回5个最常搜索的术语
使用频率表实现查询字符串频率的收集和查询
深入探讨设计
主要探索以下方面的优化:
- Trie数据结构
- 数据收集服务
- 查询服务
- 扩展存储
- Trie操作
Trie数据结构
使用前缀树数据结构完成检索前5高频的搜索查询。该树状数据结构的特征是:
- 根节点表示空字符串
- 每个节点存储一个字符,共26类子节点
- 每个节点都代表一个单词或前缀字符串
在给出补全算法之前,先给出特定字符的解释: - p:前缀的长度
- n:前缀树所有节点的个数
- c:给定节点的孩子个数
查询前k个最频繁搜索查询的步骤是:
- 搜索到对应的前缀,O(p)
- 遍历该前缀节点对应的子树获取到所有有效孩子节点,有效孩子节点即代表了一个有效的查询字符串,O(c)
- 将所有孩子节点按照频率排序,获取前k个字符串,O(clogc)
该算法时间复杂度是上面每一步所花费的时间之和:O(p)+O(c)+O(clogc)
但是该算法在最坏情况下需要遍历整个树才能获取结果,以下是两种优化方法:
- 限制前缀的最大长度
- 在每个节点缓存前几个搜索查询
限制前缀的最大长度
用户很少在搜索框中输入一个长字符串进行搜索查询,因此将前缀查询的长度限制在小常数,对应的复杂度O(p)可以减小到O(1)
每个节点缓存前列查询结果
可以在每个节点缓存k个最频繁查询。这个设计需要大量的空间,对于需要快速响应时间的当前服务,这是值得的。对应的时间复杂度也减小为O(1)
由于每个步骤的时间复杂度都减少到了O(1),因此算法只需要O(1)来获取前k个查询。
数据搜集服务
数据搜集服务的底层基础大致相同,用于构建前缀树的数据通常来自分析或日志服务。
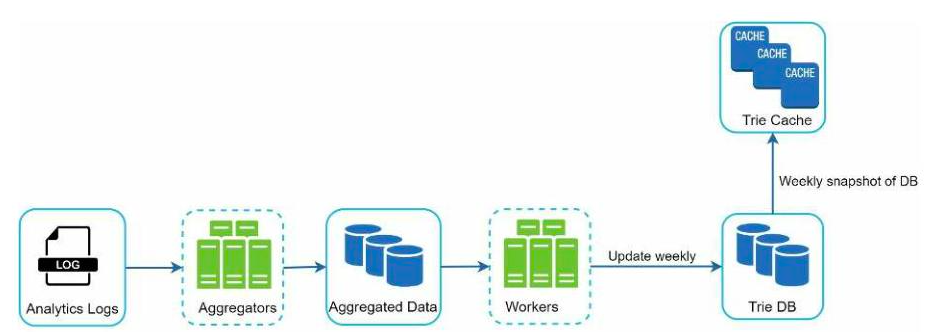
数据收集服务包括以下组件:
- 分析日志:存储有关搜索查询的原始数据,只读且没有索引
- 聚合器:进行分析日志的数据提取和格式转换
- 工人:定期执行异步任务的服务器,构建前缀树数据结构并且存储在Trie DB中
- Trie缓存:分布式缓存系统,将Trie存储在内存中实现快速读取,每周对数据库进行一次快照
- Trie DB:持久性存储数据,可以选择定期将Trie序列化后存储在数据库中。如MongoDB的文档存储就很适合序列化数据;也可以将每个前缀映射成键,数据映射成值存储在键值数据库中
查询服务
使用缓存优化后的流程如下:
- 查询请求被发送到负载均衡器
- 负载均衡器将请求路由到API服务器
- API服务器从Trie缓存获取数据并且为客户端构建补全建议
- 如果缓存未命中,也许其中缓存超内存或者离线了,就将数据补充到缓存中
针对快速响应进行优化:
- 使用AJAX请求:使用AJAX发送和接收响应不会刷新整个页面,适合web应用获取自动补全
- 使用浏览器缓存:对于许多应用,自动补全建议短时间不会发生变化,因此可以将其存储在浏览器缓存中使得后续结果可以从本地缓存中返回。Google搜索引擎就使用了类似的机制,例如Response headers里面的cache-conchrol字段。
- 数据采样:大型系统记录每个查询需要耗费大量处理和存储资源,可以数据采样为每N个请求记录1个
Trie操作
- Trie 是由工人使用聚合数据创建的,数据来源是AnalyticsLog/DB
- 更新 trie的频率为一周一次,可选择一旦创建了新的 trie,新的trie 将替换旧的 trie。在小规模下也可直接更新单个 trie 节点和它的父亲节点
- 在 Trie 缓存前面添加了一个过滤层,用于过滤仇恨、暴力、性暗示或危险的自动补全建议。也可用它根据不同过滤规则异步删除数据库中的结果。
- 为了扩大数据库存储规模,初步可以考虑根据第一个首字母进行分片存储,由于不同首字母开头字符数量不同,也可以引入一个分片映射管理器来使得分片均匀。
额外补充
- 多语言支持:在Trie节点中存储Unicode字符
- 不同国家的划分:构建不同的Trie,同时将其存储在CDN中
- 构建实时搜索自动补全功能:
- 分片减少工作数据集
- 改变排名模型,为最近搜索分配更多权重
- 数据可能以流的形式出现,数据是连续生成的,无法一次访问所有数据。流式处理需要一组不同的系统:Apache Hadoop MapReduce、Apache Spark Streaming、ApacheStorm、Apache Kafka等
2025年7月25日阅读文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号