

第十一章 设计新闻推送系统
本章节的目标是设计一个信息流推送系统。以社交媒体为例,信息流也就是主页中不断更新的故事列表,里面包含了文字、照片、视频等多种信息。
理解并确定设计范围
- 手机应用和网络应用
- 功能:在新闻信息流页面发布帖子并看到朋友帖子
- 按时间倒序排序
- 一个用户5000个朋友
- 流量为1000万DAU
- 内容包括文字、图片和视频
提出高级设计
设计可分为两个流程:
- 信息流发布:用户发布帖子,对应的数据被写入缓存和数据库。一个帖子被填充到他朋友的信息流中。
- 构建信息流:简化为按逆时间顺序聚合朋友的帖子来构建
新闻信息流API
API是服务端与客户端通信的主要方式,本小节只讨论该系统中最重要的两个API:
# 新闻信息流发布API
POST/v1/me/feed
参数:• content:内容是帖子的文本。• auth_token:用于验证 API 请求。
# 新闻信息流检索API
GET/v1/me/feed
参数:• auth_token:它用于验证API请求。

整体流程设计
- 用户:可在浏览器或终端上查看信息流;可通过API发布帖子
- 负载均衡器:分发负载给web服务器
- Web服务器:将负载重定向到不同的中间服务
- Post服务:将帖子保存在缓存和数据库中
- Fanout服务:将新的内容推送到朋友的信息流中。信息流存储在缓存中用于快速读取
- 通知服务:提醒朋友存在新内容并发送推送通知
深入高级设计
信息流发布设计
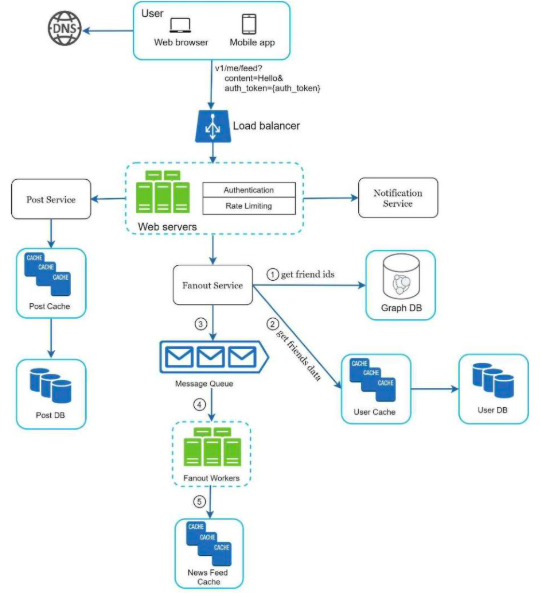
重点讨论流程中的Web服务器和Fanout服务
Web服务器
除了与客户通信外,该组件还执行身份验证和速率限制。只有使用有效auth_token登登录的用户才能发布帖子。该系统还限制用户在一定时间内发布的帖子数量以防止垃圾邮件和滥发内容。
Fanout服务
该服务是向所有朋友发送帖子的过程。可分为推送模型和拉取模型。
推送模型
新闻信息流在写入时进行预计算,新帖在发布后立即发送到朋友的缓存中
优点:
- 信息流实时生成,可以立即推送给朋友
- 由于信息流在写入时预计算过,获取信息流的速度很快
缺点: - 如果user朋友过多,获取朋友列表并为他们生成信息流会很缓慢和耗时,即热键问题
- 为不活跃用户生成预先计算的信息流会浪费资源
拉取模型
新闻信息流在读取时生成,即当用户加载他自己的主页时,会拉取最近的帖子。
优点:
- 对于不活跃用户,拉取模型能节约资源
- 数据没有被推送到朋友那,不存在热键问题
缺点: - 获取新闻信息流很慢
混合模式
混合方法获取两种方法优点并避开缺点
- 由于快速获取新闻信息流很重要,对于大部分用户使用推送模型
- 对于有很多朋友关注的用户,让关注者按需拉取内容,以避免系统过载
推送服务流程

- 从图数据库中获取朋友ID
- 将朋友信息加载进user缓存。系统根据用户设置筛选。
- 将朋友列表和帖子ID发送到消息队列
- 发布工作者从消息队列中取出数据并以<post_ID, user_ID>的形式存储在类似于哈希表的缓存中,由于用户翻阅成千上万条帖子的概率很小,所以脱靶几率很小
- 将对应的数据存储在信息流缓存中
信息流拉取流程
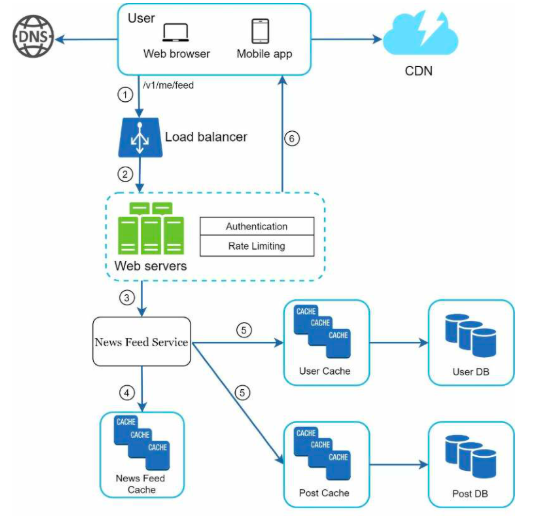
假定包括图片、视频等媒体内容存储在CDN上用于快速读取。客户端获取信息流的流程如下:
- 用户发送请求以检索自己的信息流,类似于
/v1/me/feed - 负载均衡器将请求分配给Web服务器
- Web服务器调用信息流服务来检索信息流
- 信息流服务从信息流缓存中获取帖子ID列表
- 信息流服务从用户缓存和帖子缓存中检索完整的用户和帖子对象以构建完全填充的信息流
- 完全填充的信息流以JSON格式返回给客户端进行渲染
缓存结构
- 新闻源:存储新闻源ID
- 内容:存储每个帖子内容,热门内容存在热点缓存中
- 社交图谱:用户关系数据
- 动作:是否喜欢帖子、回复帖子或对帖子的其他操作的信息
- 计数器:喜欢、回复、关注者、被关注者等的计数器
扩展设计
数据库相关
- 垂直扩展/水平扩展
- SQL/NoSQL
- 主从复制
- 读副本
- 一致性模型
- 数据库分片
链接相关
- 保持Web层无状态
- 尽可能缓存数据
- 支持多个数据中心
使用消息队列将组件解耦
监控关键指标
2025年7月21日阅读文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号