

第九章 设计网络爬虫
网络爬虫介绍
基本算法
- 给定一组URL,下载对应的网页
- 从网页中提取URL
- 将新的URL添加到要下载的URL列表中,重复这三步
用途
- 搜索引擎索引
- 网络存档
- 网络挖掘
- 网络监测
优秀爬虫的特点
- 可扩展性:高效使用并行化
- 健壮性:能处理坏HTML、无响应服务器、崩溃、恶意链接等边缘情况
- 礼貌性:短时间内不对同一个网站发出太多请求
- 可扩展性:进行最小的更改即可支持新的内容类型
高级设计
总体流程
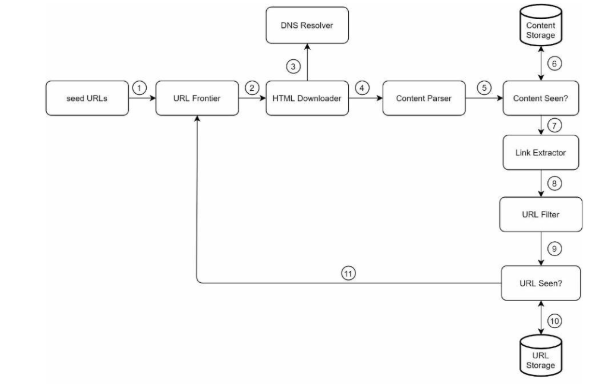
种子URL
种子URL是爬行爬取的起点,爬虫可以利用好的种子遍历尽可能多的链接。
- 基于地理位置分类,不同国家流行网站不同
- 根据主题选择
URL Frontier
爬取状态分为待下载状态和已下载状态,存储待下载状态的具有先进先出队列功能的组件称为URL Frontier。
HTML下载器
从互联网下载网页
DNS解析器
下载器在下载网页之前要调用DNS解析器将URL转换成相应的IP地址
内容解析器
下载网页后对内容进行解析验证,确保网页格式正确,避免浪费存储空间。将其作为一个单独的组件可以提高爬行服务器效率
内容查重器
有研究表明诸多网页是重复内容,内容查重器用于排除相同内容被多次存储的数据结构。使用逐个字符比较两个HTML文档速度慢且耗时,有效方法是直接比较两个网页哈希值。
内容存储
存储HTML内容的存储系统。
-
大部分内容存储在磁盘上,因为数据集过大,无法存储在内容中
-
流行内容保存在内存中,以减少延迟
URL提取器
从HTML页面中解析和提取链接
URL过滤器
排除某些内容类型、文件扩展名、错误链接和“黑名单”网站中的URL
URL查重器
用于跟踪在Frontier之前就已经访问过的URL的数据结构。有助于避免将相同的URL添加多次,这可能会增加服务器负载并且导致潜在的无限循环。常用技术为布隆过滤器和哈希表
URL存储
存储已访问的URL
构建组件和技术
广度优先搜索
作为网络爬虫的通用技术,通常使用先进先出队列实现。但是其存在问题:
- 大多数来自同一网页的URL会链接回同一主机,简单BFS会让爬虫的请求充满一个主机,这被认为是不礼貌的,甚至可能会被当作拒绝服务(DOS)攻击
- 标准的BFS没有考虑URL优先级,实际情况下需要根据页面排名、网络流量和更新频率来优先考虑URL
URL frontier组件是确保礼貌、URL优先级和新鲜度的重要组件。
礼貌
强行执行礼貌的思想是同一个主机中一次下载一页。同时在两个下载任务之间设置延迟。实际实现通过维护从网站主机名到下载线程的映射来实现,每个下载线程只下载对应的FIFO队列中的URL,并且将同一网站的URL维护在同一个队列中。
- FIFO队列:每个队列包含来自同一主机的URL
- 队列选择器:将每个工作线程映射到FIFO队列
优先级
“优先排序器”能够根据PageRank、网站流量、更新频率等来衡量URL有用性。
- 优先级排序器:URL输入并且计算对应的优先级
- 队列:每个队列对应分配的优先级,优先级高的队列被选中概率高
- 队列选择器:随机选择一个队列
最终形成管理优先级的前端队列和管理礼貌的后端队列
参考L. Page, S. Brin, R. Motwani, and T. Winograd, “The PageRank citationranking: Bringing order to the web,” Technical Report, StanfordUniversity,1998.
新鲜度
- 基于网页的更新历史进行重新抓取
- 优先处理重要页面的URL
前沿存储
URL数量过大,内存的存储不可持续不容易扩展,但是所有内容保存在磁盘会导致访问速度过慢。
采取混合方法,将大多数URL存储在大容量的磁盘上,同时在内存中维护缓冲区进行出队入队以减少磁盘读取和写入成本。将缓冲区中的数据定期写入磁盘。
HTML下载器
下载器会使用HTTP协议从互联网下载网页,同时也要遵循 Robots排除协议。
Robots.txt
Robots.txt又称为机器人排除协议,是网站与爬虫的通信标准,其指定了爬虫允许下载的页面,是爬虫在爬取网站前需要下载的文件。为了避免重复下载该文件,该文件会定期下载并保存到缓存中。
#从https://www.amazon.com/robots.txt 获取的robots.txt 文件中的一段
User-agent: Googlebot
Disallow: /creatorhub/*
Disallow:/rss/people/*/reviews
Disallow: /gp/pdp/rss/*/reviews
Disallow:/gp/cdp/member-reviews/
Disallow: /gp/aw/cr/
性能优化
- 分布式爬取:爬取任务根据URL空间划分被分布到多台服务器上,服务器运行多个线程进行爬取任务。
- 缓存DNS解析器:DNS解析任务受限于许多DNS接口的同步性质作为爬虫瓶颈,一个爬虫线程执行DNS请求的时候,其他线程将被堵塞,直到完成第一个请求。实现DNS缓存保存域名到IP地址的映射,并定期由cron作业更新是有效的速度优化技术
- 局部性:利用服务器相对于网站主机的地理优势获取速度提升,适用于绝大多数技术组件:爬虫服务器、缓存、队列、存储等
- 短超时:为避免web服务器响应缓慢或不响应带来的长时间等待,指定最大等待时间。未及时响应的页面将被爬虫跳过。
健壮性
- 一致性散列:下载器之间的负载均衡,和添加删除下载服务器
- 保存爬行状态和数据:防止故障导致的爬行中断,加载保存数据以快速重启服务
- 异常处理:必须要优雅处理各种异常,防止系统崩溃
- 数据验证:防止系统出错
可扩展性
这是每个系统都会发展的方向,本章系统的目标之一就是支持新的文件内容的灵活性
- 插入PNG下载器模块来下载PNG文件
- 插入网络监视器模块来监视网络中的版权和商标侵权
检测和避免问题
- 冗余内容:哈希 或 校验和
- 蜘蛛陷阱:蜘蛛陷阱是一个无限循环的网页。通过对URL设置最大长度和检测网站的网页数量可以避免部分陷阱,目前很难开发出自动算法来避免,更多依赖于用户手动
- 数据噪音:例如广告、代码片段、垃圾 URL 等内容没有价值,考虑将其排除在外
其余讨论点
- 服务器端渲染:许多网站使用像JavaScript、AJAX等脚本来动态生成链接。直接下载和解析网页会遗漏动态生成的链接。为解决这个问题,需要额外添加执行服务器端渲染(也称为动态渲染)这一步骤,再解析页面
- 过滤页面的精细化:添加类似于反垃圾邮件组件的过滤组件
- 数据库复制和分片:提高数据层的可用性、可扩展性和可靠性
- 横向扩展:保证大批量服务器执行下载任务的必要条件是服务器的无状态
- 可用性、一致性和可靠性:大型系统成功的核心
- 收集和分析数据
2025年7月19日补录昨日阅读文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号