
JVM 学习笔记(五)
前言:
前面的文件介绍了JVM的内存模型以及各个区域存放了那些内容,本编文章将介绍JVM中的垃圾回收Garbage Collector,和大家一起探讨一下。
如何确定一个对象是垃圾:
这里介绍两种方法:
-
引用计数法
-
可达性分析
垃圾回收算法:
-
标记-清除(Mark-Sweep)
-
标记
找出内存中需要回收的对象,并且把它们标记出来。此时堆中所有的对象都会被扫描一遍,从而才能确定需要回收的对象,比较耗时。
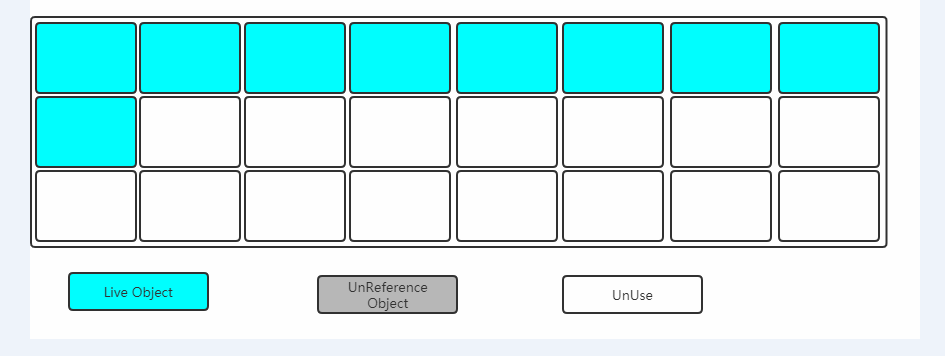
如图:绿色的区域表示当前存活的对象,灰色表示垃圾对象,白色表示没有用到的内存碎片。

2. 清除
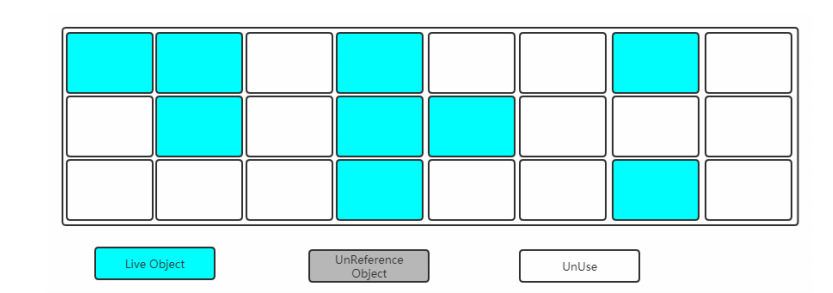
有以下缺点:
-
复制(Copying)
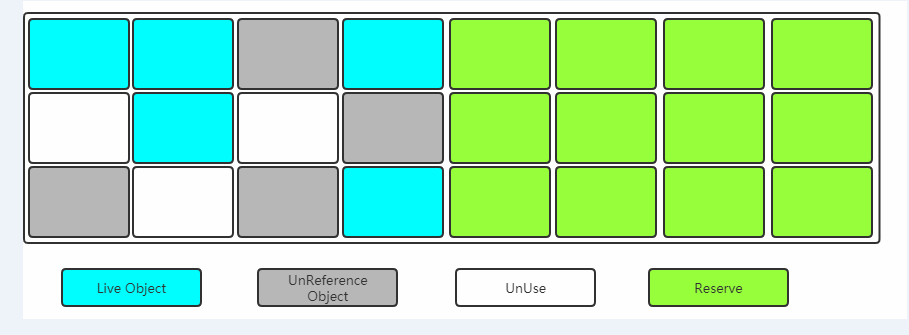
当其中一块内存使用完了,就将还存活的对象复制到另外一块上面,然后把已经使用过的内存空间一次清除掉。
下图的清理过后的内存模型:
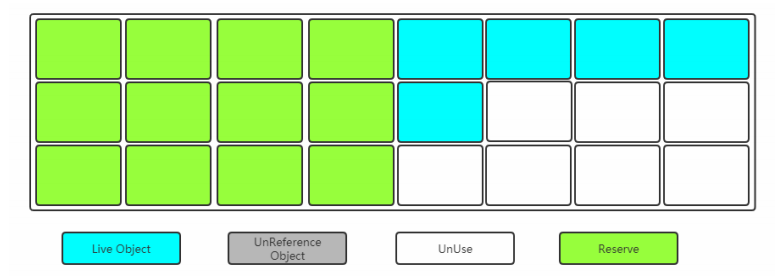
缺点:
因为这种方法保留的两个大小一样的内存区域,而同一时刻只会用到其中的一个,所以该方法内存的空间利用率比较低。
-
标记-整理(Mark-Compact)
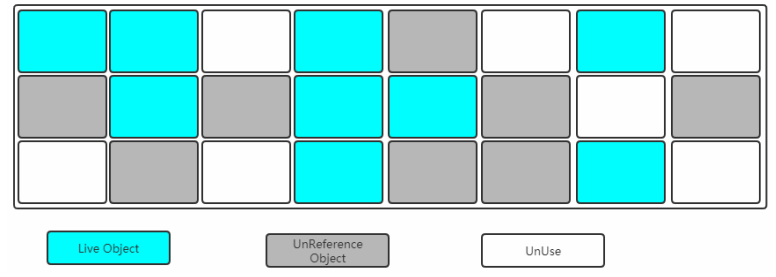
下图是整理阶段,该阶段会将被标记的区域清除,并把存活的对象往一端移动,这样内存区域就会连续化,不会有空间碎片。
分代收集算法:
垃圾收集器的介绍:
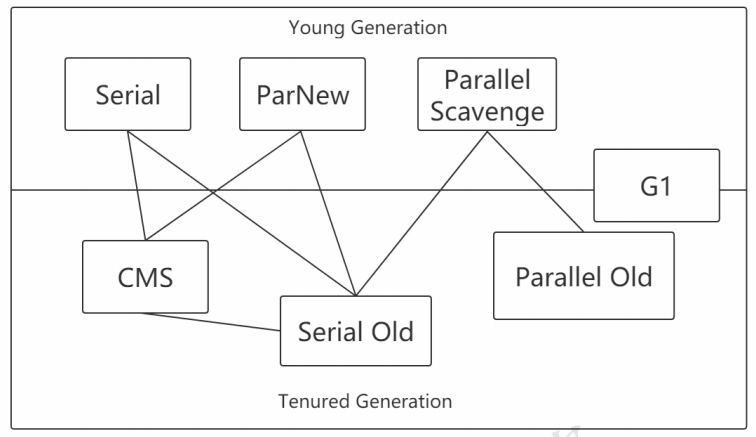
下面来介绍这几种垃圾收集器:
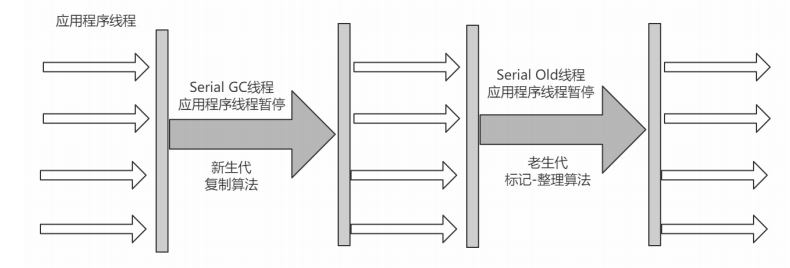
1.Serial收集器
优点:简单高效,拥有很高的单线程收集效率
缺点:收集过程需要暂停所有线程
算法:复制算法
适用范围:新生代
应用:Client模式下的默认新生代收集器
下图是该模式下的应用线程状态图:

2. ParNew收集器
简单理解为是Serial收集器的多线程版本。
简单总结一下该收集器:
优点:在多CPU时,比Serial效率高。
缺点:收集过程暂停所有应用程序线程,单CPU时比Serial效率差。
算法:复制算法
适用范围:新生代
应用:运行在Server模式下的虚拟机中首选的新生代收集器
3. Parallel Scavenge收集器
这里解释一下什么是吞吐量:
4. Serial Old收集器
下图是该模式下的应用线程状态图:
5. Parallel Old收集器
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和"标记-整理算法"进行垃圾回收。
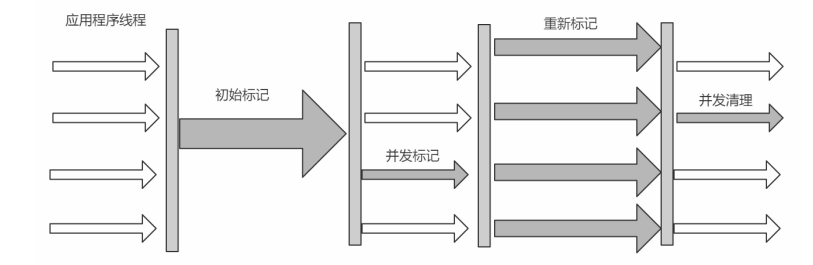
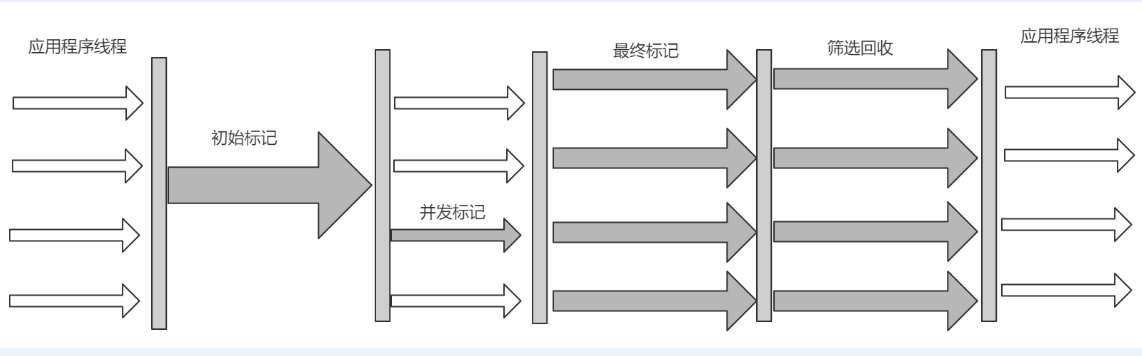
6. CMS收集器
7. G1收集器
G1 (Garbage-First)是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征. 在Oracle JDK 7 update 4 及以上版本中得到完全支持, 专为以下应用程序设计:
- 可以像CMS收集器一样,GC操作与应用的线程一起并发执行
- 紧凑的空闲内存区间且没有很长的GC停顿时间.
- 需要可预测的GC暂停耗时.
- 不想牺牲太多吞吐量性能.
- 启动后不需要请求更大的Java堆.
G1的长期目标是取代CMS(Concurrent Mark-Sweep Collector, 并发标记-清除). 因为特性的不同使G1成为比CMS更好的解决方案. 一个区别是,G1是一款压缩型的收集器.G1通过有效的压缩完全避免了对细微空闲内存空间的分配,不用依赖于regions,这不仅大大简化了收集器,而且还消除了潜在的内存碎片问题。除压缩以外,G1的垃圾收集停顿也比CMS容易估计,也允许用户自定义所希望的停顿参数(pause targets)
归纳总结一下G1收集器的特点:
1.并行与并发
2.分代收集(仍然保留了分代的概念)
3.空间整合(整体上属于“标记-整理”算法,不会导致空间碎片)
4.可预测的停顿(比CMS更先进的地方在于能让使用者明确指定一个长度为M毫秒的时间片段内,消耗在垃圾收集 上的时间不得超过N毫秒)。
初始标记(Initial Marking) 标记一下GC Roots能够关联的对象,并且修改TAMS的值,需要暂 停用户线程
并发标记(Concurrent Marking) 从GC Roots进行可达性分析,找出存活的对象,与用户线程并发 执行
最终标记(Final Marking) 修正在并发标记阶段因为用户程序的并发执行导致变动的数据,需 暂停用户线程
筛选回收(Live Data Counting and Evacuation) 对各个Region的回收价值和成本进行排序,根据 用户所期望的GC停顿时间制定回收计划
垃圾收集器分类:
串行收集器->Serial和Serial Old
并行收集器[吞吐量优先]->Parallel Scanvenge、Parallel Old
并发收集器[停顿时间优先]->CMS、G1
理解吞吐量和停顿时间:
如何选择合适的垃圾收集器:
首先我们了解一下官网是如何建议的:

简单翻译一下就是:
1.优先调整堆的大小让服务器自己来选择
2.如果内存小于100M,使用串行收集器
3.如果是单核,并且没有停顿时间要求,使用串行或JVM自己选
4.如果允许停顿时间超过1秒,选择并行或JVM自己选
5.如果响应时间最重要,并且不能超过1秒,使用并发收集器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号