


我在前面的文章(Android智能手机上的音频浅析)中说过Android手机上有一块专门用于音频处理的DSP,它的特点是频率低(一般几百MHZ)、内部memory小(通常不超过100k word)。要想让Audio DSP上放下更多的内容以及能流畅的运行,要有一些应对措施。今天就聊聊这些措施。
1,频率低的应对措施
由于DSP的频率低,要想软件能流畅的运行,就得把运行时的load降下来。主要的措施有两种,定点化和load优化。先看定点化。
DSP有定点DSP和浮点DSP之分。一般来说,定点DSP具有速度快,功耗低,价格便宜的特点;而浮点DSP则计算精确,动态范围大,速度快,易于编程,功耗大,价格高。音频处理用的DSP通常都是定点DSP。定点DSP,处理定点数据会相当快,但是处理浮点数据就会非常慢。那在定点DSP上涉及到浮点运算怎么办呢?解决方法是浮点运算定点化来节约处理时间,即用定点数表示浮点数。定点数中最高位表示符号位,符号位右边n位表示整数,剩下的表示小数。这种表示方法叫Q格式。
Q格式表示为:Qm.n,表示数据用m比特表示整数部分,n比特表示小数部分,共需要m+n+1位来表示这个数据,多余的一位用作符合位(不表示出来)。例如Q15表示小数部分有15位,一个short型数据,占2个字节,最高位是符号位,后面15位是小数位,表示的范围是:-1<X<0.9999695 。浮点数据转化为Q15,将数据乘以2^15;Q15数据转化为浮点数据,将数据除以2^15。例如假设数据存储空间为2个字节,0.333×2^15=10911=0x2A9F,0.333的所有运算就可以用0x2A9F表示,同理10911×2^(-15)=0.332977294921875,可以看出浮点数据通过Q格式转化后是有误差的。
再看看Q格式的加减乘除基本运算。加减法时须转换成相同的Q格式才能加减。不同Q格式的数据相乘,相当于Q值相加,要右移n位得到正确的值。不同Q格式的数据相除,相当于Q值相减,要左移n位得到正确的值。这里举一个乘的例子:两个小数相乘,0.333*0.414=0.137862
0.333*2^15=10911=0x2A9F,0.414*2^15=13565=0x34FD
short a = 0x2A9F;
short b = 0x34FD;
short c = a * b >> 15; // 两个Q15格式的数据相乘后为Q30格式数据,因此为了得到Q15的数据结果需要右移15位
这样c的结果是0x11A4=0001000110100100,这个数据同样是Q15格式的,它的小数点假设在第15位左边,即为0.001000110100100=0.1378173828125...和实际结果0.137862差距不大。或者0x11A4 / 2^15 = 0.1378173828125
其他的基本运算就不举例了,网上讲Q格式的有一些文章,感兴趣自己去看。
实际应用中,浮点运算大都时候都是既有整数部分,也有小数部分的。所以要选择一个适当的定标格式才能更好的处理运算。一般用如下两种方法:一是使用适中的定标,既可以表示一定的整数复位也可以表示小数复位,如对于2812的32位系统,使用Q15格式,可表示-65536.0~65535.999969482区间内的数据。二是全部采用小数,这样因为小数之间相乘永远是小数,永远不会溢出。取一个极限最大值(最好使用2的n次幂),转换成x/Max的小数(如果Max是取的2的 n次幂,就可以使用移位代替除法)。刚开始用Q格式时会很别扭,不习惯,用多了就慢慢习惯了。
为了降load,我们在软件开发过程中要做到以下两点:一是选择算法实现时一定要用定点实现。Audio DSP上会运行好多音频处理算法,比如各种codec,这些codec的制定者一般会提供两套reference code,一套定点实现的,一套浮点实现的,我们在选择时一定要选用定点实现的。对于应用在ARM上的音频处理算法,同样是推荐用定点实现的算法,虽然ARM频率高。在ARM上还是要优化算法把load降到尽量低。二是在我们自己的代码中如遇到要做浮点运算(比如算百分比),要用Q格式定点化去算,而不是直接用浮点数去运算。
再来看load优化。我在前面的文章(音频的编解码及其优化方法和经验)中load优化的一些通用方法,在DSP上也适用。不过由于DSP频率低,且DSP上运行的音频处理算法多,有些算法又比较耗load(比如AEC),要想让音频软件流畅的运行,复杂的算法都是要做汇编优化的。做这些不仅专业而且耗时,load优化没有最低只有更低。
2,memory低的应对措施
DSP的内部memory分两种,DTCM(Data Tightly Coupled Memory, 数据紧密耦合存储器)和PTCM(Program Tightly Coupled Memory, 程序紧密耦合存储器)。DTCM用于存data,PTCM用于存code。同时还有外部memory(DDR),它也可存data和code。data和code尽量放内部,因为这样速度快效率高,不到万不得已才将它们放在外部memory上。即使放在外部的也是一些低频访问的data和code,如初始化函数等。今天我们主要讲的是应对DTCM(data memory)小的措施。DTCM主要分以下几个区域:const区、data区、bss区、overlay区。const区顾名思义就是放一些常量的,data区是放已初始化的全局变量和静态变量,bss区是放未初始化的全局变量和静态变量,overlay区主要是根据场景的互斥做一些memory的复用,这是应对memory小的主要措施。我们先看overlay机制。
Overlay机制是指不会同时发生的场景下使用的memory可以复用,在音频上主要有两种情况。一是music使用的memory可以和voice使用的memory复用,因为音乐播放和打电话不可能同时发生。通常是音乐播放时来电话,音乐播放就暂停,把音乐播放的context以及还在buffer中未播放的数据拷贝到外部memory上,把music使用的memory让给voice用。打电话结束后再把放在外部memory上的音乐相关的context以及未播放的数据拷进内部memory原先的位置上,从而继续音乐的播放。二是各种codec使用的memory的复用,因为同时只有一种codec在使用。音乐的decoder有MP3、AAC,播放音乐时只可能有一种decoder在用。Voice的codec有AMR-NB、AMR-WB、EVS,打电话时只可能有一种codec在用。它与第一种的区别是不需要保存上下文。这样可以画出DTCM的分布图,如下图:
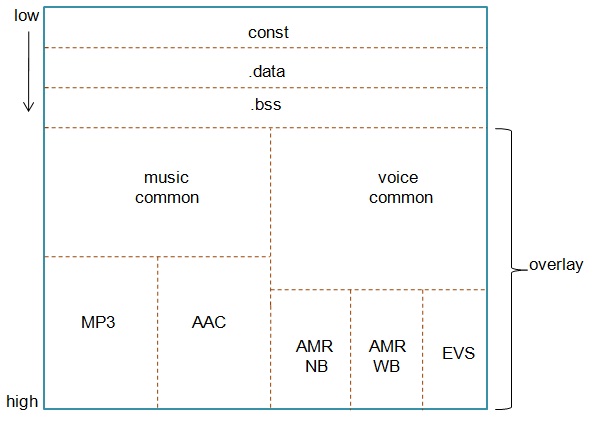
上图中memory地址是由低向高增长,分别是const区、data区、bss区、overlay区。在overlay区music和voice有相同的起始地址,在music中decoder MP3和AAC又有相同的起始地址,在voice中codec AMR-NB、AMR-WB和EVS又有相同的起始地址。
对于PTCM,同样可以用overlay机制。不过除非一些代码重写,一般很难省code size了。
除了overlay机制,其他的就要一点一点的抠来省memory了,主要有以下几点:
1) 定义数据类型时能用short的就不要用int
2)在overlay区域,buffer的大小都是指定的。指定时要正确算出大小值,不要指定大了,指定大了就浪费了。
3)在data区或者bss区的buffer要看是不是分大了,比如有的buffer分三块就够了,也就没必要分四块了,分四块一是浪费了buffer,二是有些场景下增加了时延。
4) DSP上每个thread/task的栈的大小都是指定的。为了省memory,栈的大小不可能很大,一般不超过1k word。这就要求写代码时不能有大的局部变量数组等,遇到时就要通过一些技巧解决。如一个要把双声道的数据从interleave变成non-interleave的函数,写成了如下实现,避免了大的局部变量数组。通常的做法是用一个大的局部变量数组先存右声道数据,最后再一起拷到指定位置上。
void interleave_to_noninterleave(int16_t *buf, int32_t frame_cnt)
{
int i,j;
short temp;
for(i = 1; i < frame_cnt; i++) {
temp = buf[2*i];
for(j = 0; j < i; j++)
buf[2*i - j] = buf[2*i - j -1];
buf[i] = temp;
}
}
5)代码编好后会生成一个各buffer起始地址和大小的文件。关注那些size较大的buffer,分析有没有减小的可能。
总体而言,DSP由于频率低和memory小的限制,在上面写代码比在ARM上要求高些,花的时间长些。长时间在ARM上写代码,转到DSP上会有些不习惯,有个适应过程。
为了更好的跟大家沟通,互帮互助,我建了一个讨论群。如您有兴趣,请搜weixin号 david_tym ,共同交流。谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号