原创不如山寨——原型模式详解
现实世界中山寨这种行为往往意味着假冒伪劣,备受批判。但是在软件开发中,山寨却又不少可取之处。首先其“成分”和“质量”和原创不相上下;其次相比原创一个东西的时间开销,山寨一个出来总归是省时省力的,毕竟对于计算机,克隆一个对象要比创建一个对象性能好得多(拷贝对象不会执行构造方法)。如果在开发中我们需要一个类的多个实例,这些实例只在某些属性细节上不同,相比直接new出它们的时间开销,从一个实例原型拷贝出其他的实例或许是更可取的方法。而原型模式,或者说克隆模式就能够帮我们做到这点。
2. 原型模式详解
2.1 原型模式定义
用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
2.2 原型模式类结构
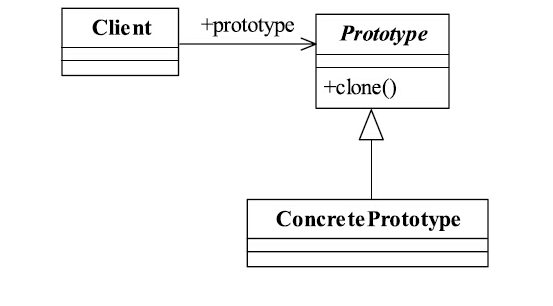
原型模式中的主要角色是Prototype类,含有clone方法供客户端调用,从而创建它的拷贝对象。类结构简单清晰。
2.3 原型模式的代码实现
- 首先创建原型类,其实现了Cloneable接口,并重写自Object继承的clone方法。
public class Prototype implements Cloneable {
@Override
protected Prototype clone() throws CloneNotSupportedException {
return(Prototype)super.clone();
}
}
- 测试
public class TestCase {
public static void main(String[] args) throws CloneNotSupportedException {
Prototype pObj = new Prototype();
Prototype cObj = pObj.clone();
System.out.println(pObj);
System.out.println(cObj);
}
}
首先创建了一个原型类的实例,其次调用该实例的clone方法获得了该实例的拷贝,分别打印出两个对象的哈希值
- 结果

3. 关于对象拷贝的深拷贝和浅拷贝问题
3.1 什么是深拷贝和浅拷贝
- 浅拷贝
上面我们通过实现标记接口Clone使得该对象具有创建一个和自己一摸一样的拷贝对象的能力,然而这种拷贝是浅拷贝,与之相对的是深拷贝。关于浅拷贝和深拷贝,可以见下图
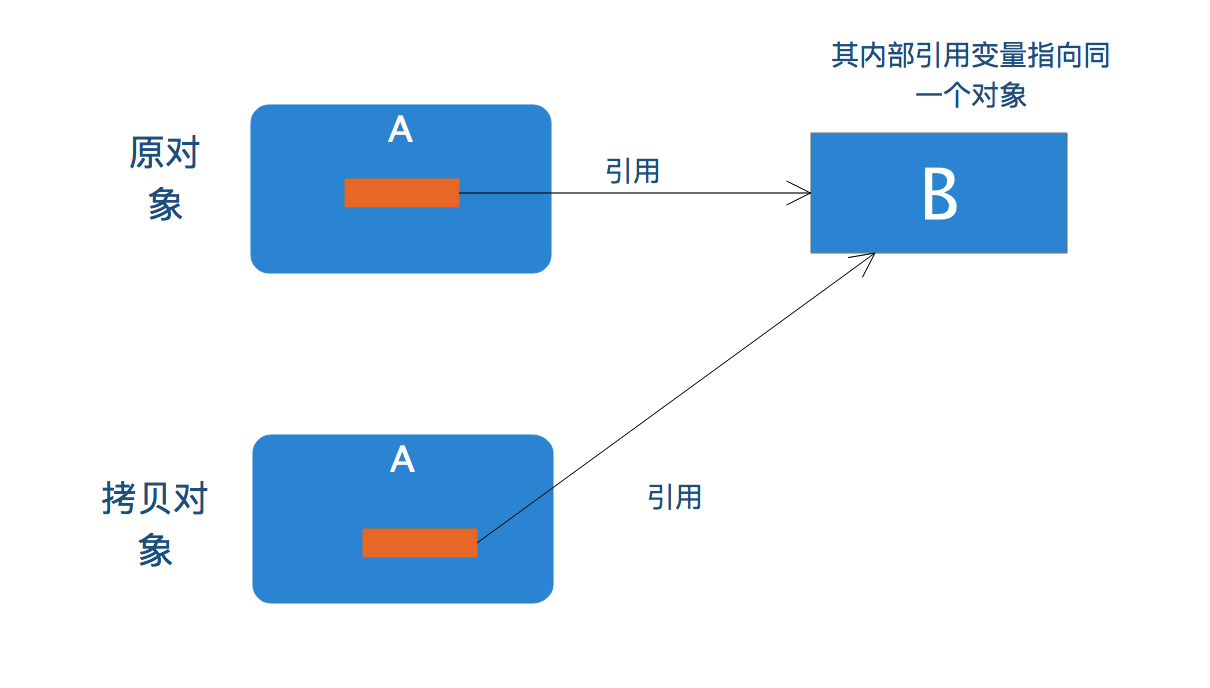
当原对象内部有一个非基本类型的引用变量时,浅拷贝意味着拷贝对象内部该变量和原对象内部的引用变量指向同一个对象,通俗的说,它只对外部对象进行拷贝,对内部引用变量指向的对象不进行真实拷贝,只是指向该对象而已。
- 深拷贝
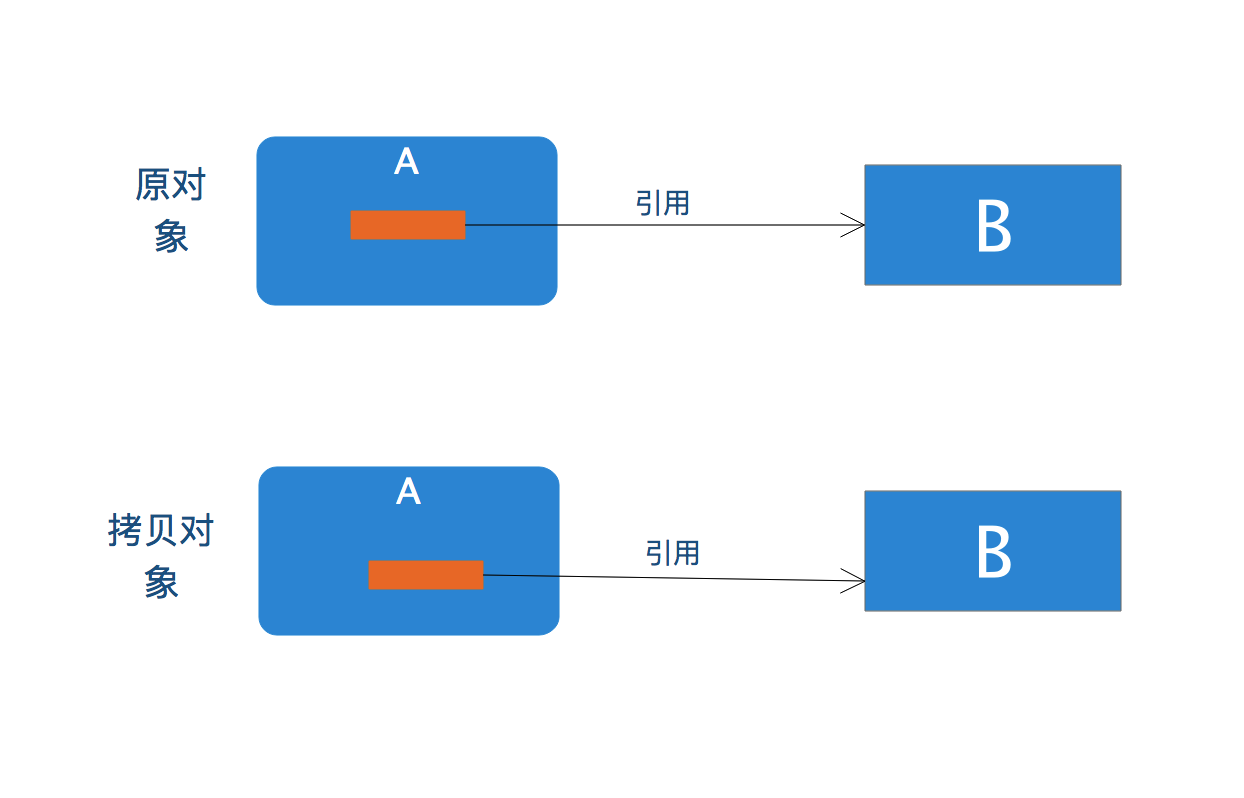
深拷贝,除了拷贝外部对象外,其引用变量指向的对象也要拷贝,同时如果该对象还有引用变量,其指向的对象同样需要拷贝,一直递归进行指导拷贝完成。可以看出,深拷贝是深度的拷贝。如果对象间的组合关系十分复杂的话,深度拷贝过程就类似于树的遍历了。
3.2 Java的Clone接口实现的是浅拷贝
对此,我们可以验证如下,首先修改原型类,添加一个引用变量obj指向Object对象。
public class Prototype implements Cloneable {
public Object obj=new Object();
@Override
protected Prototype clone() throws CloneNotSupportedException {
return(Prototype)super.clone();
}
}
测试比较原型对象和拷贝对象的obj变量是否指向同一Object对象
public class TestCase {
public static void main(String[] args) throws CloneNotSupportedException {
Prototype pObj = new Prototype();
Prototype cObj = pObj.clone();
System.out.println(pObj.obj.equals(cObj.obj));
}
}
运行结果如下

3.3 使用序列化和反序列化实现深拷贝
实现深拷贝的方式很多,比如递归实现浅拷贝,或者工作中可以使用开源类库来做。下面介绍一种使用对象序列化和反序列化实现深拷贝的方式。原型类必须实现另一个标记接口Serializable,且其内部引用变量指向的对象也必须实现该序列化接口,由于Object没有实现该接口,所以会报出NotSerializableException异常。下面给出关键的序列化和反序列化代码,就不修改原型类进行测试了。
import java.io.*;
public class TestCase {
public static void main(String[] args) throws CloneNotSupportedException, IOException, ClassNotFoundException {
Prototype pObj = new Prototype();
//序列化
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(pObj);
byte[] bytes = bos.toByteArray();
//反序列化
ByteArrayInputStream bis = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(bis);
Prototype cObj = (Prototype) ois.readObject();
System.out.println(pObj.obj.equals(cObj.obj));
}
}
4. 总结
原型模式通过对象拷贝的方式获得类的多个实例。在很多情况下这样能获得更好的性能。原型模式通常和其他模式结合使用,比如Spring框架中通过和工厂模式结合使得我们可以获得相同Bean的多个实例,这样帮我们我们屏蔽了创建新实例的复杂细节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号