
Mysql知识:索引
磁盘预读:通过经验,临近数据被读到的概率更大。因此这样按索引组织数据库也是更有效。
为什么要选择B+树作为索引的数据结构
哈希作为索引的数据结构(memory存储引擎使用这种)
只能处理等值查询,对于范围查询无能为力
要把数据丢到内存,占内存空间(哈希这种结构不适合磁盘存储)
二叉树或者红黑树存储
深度会非常深,查一次数据要发生非常多次io
B树存储
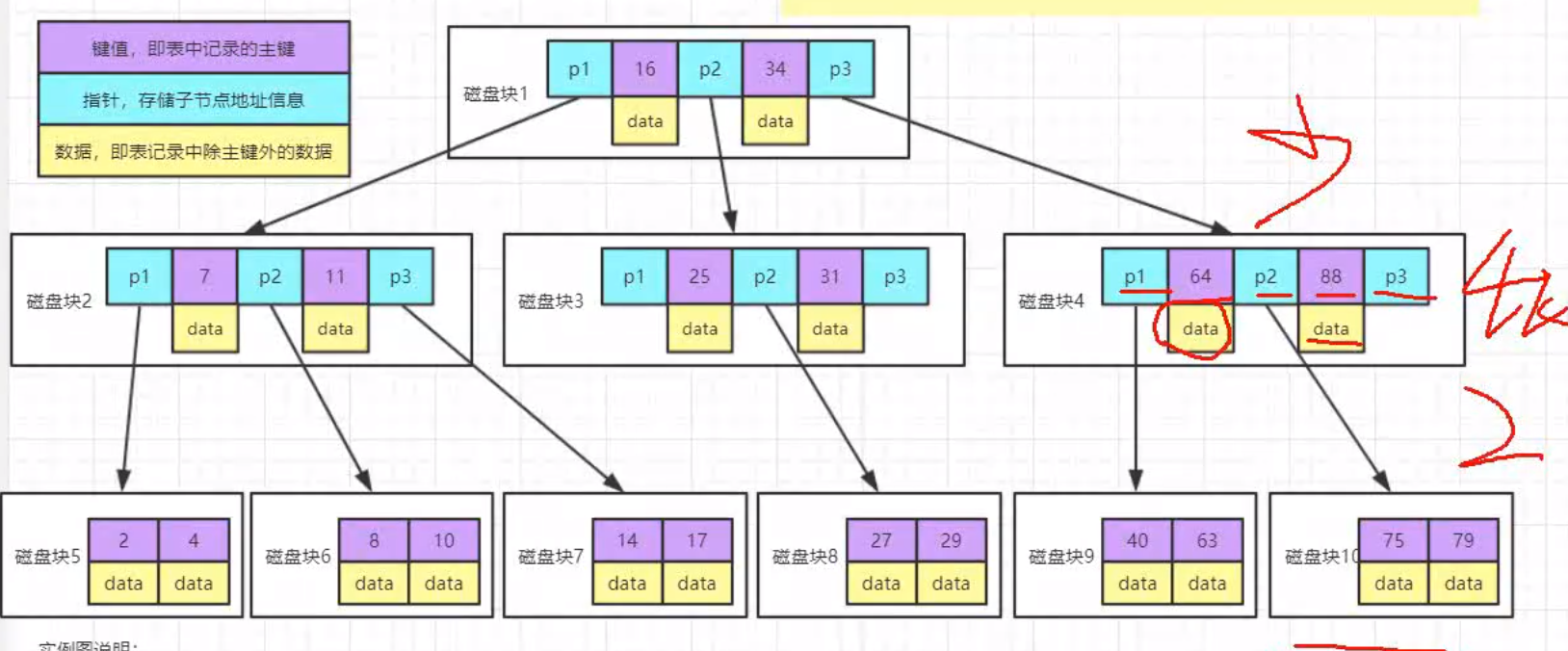
叶子节点和其他节点都存放数据
也是io过多
B+树存储

数据全部存放在叶子节点,非叶子节点只放指针
层数非常少,3层就可以百万级数据
Innodb---数据和索引放在一个文件
myisam---数据和索引分开放
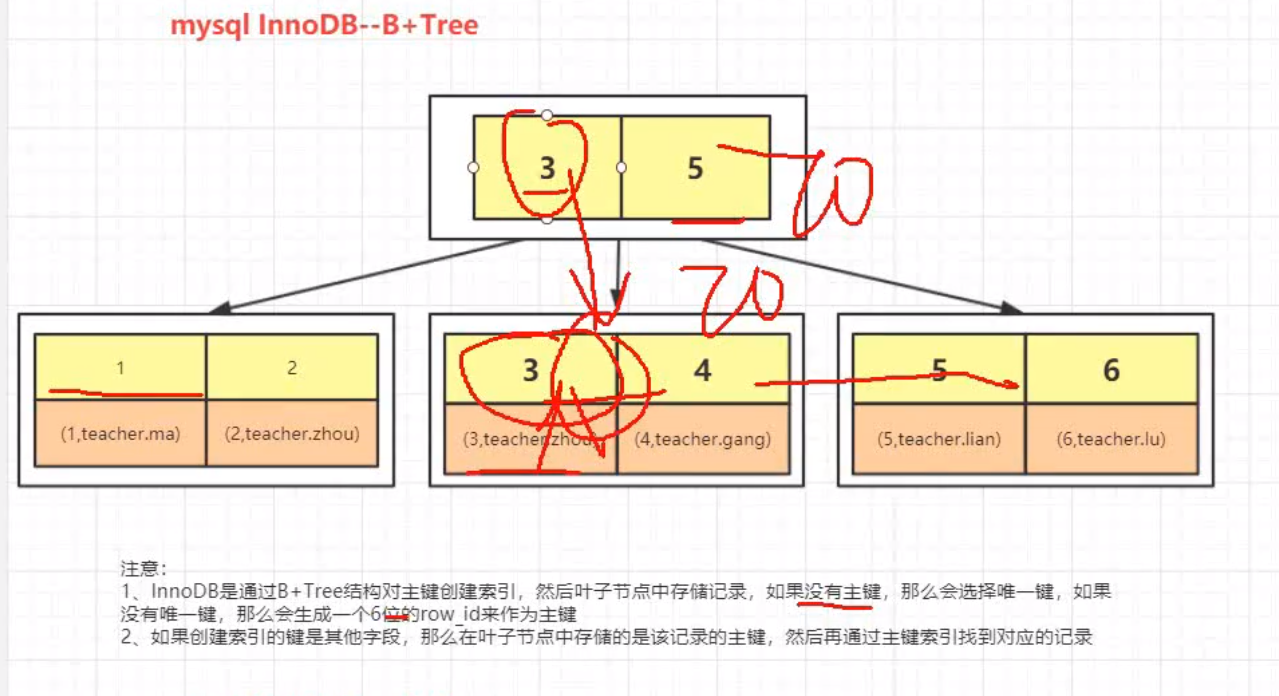
这是innodb的存储
- 如果没有主键,innodb会使用唯一键组织索引,如果没有唯一键,会使用隐藏的rowid作为主键
- 如果给其他字段建立索引,叶子节点最终储存的是该条记录的主键,再通过主键去找记录
几种索引分类

聚簇索引和非聚簇索引(也叫聚集):
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行
innodb使用了聚簇索引,myisam使用非聚簇索引
innodb中,在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找,非聚簇索引都是辅助索引
自然主键和代理主键:
代理主键-------和业务无关,比如id什么的,加上自增吧,方便维护索引
回表:
-查普通索引字段时,先去普通字段查早,查到主键后回到主键那张表内
覆盖索引:

直接查到了索引,不用回表了
查询列要被所建的索引覆盖
最左匹配:
建立组合索引 name,age

where age=10,不会使用这个组合索引(有点像like %ou)
由于mysql优化器,where age=10 and name='xx' 也会使用这个组合索引
顾名思义:最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
例如:b = 2 如果建立(a,b)顺序的索引,是匹配不到(a,b)索引的;但是如果查询条件是a = 1 and b = 2或者a=1(又或者是b = 2 and b = 1)就可以,因为优化器会自动调整a,b的顺序。再比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,因为c字段是一个范围查询,它之后的字段会停止匹配。
参考:https://www.cnblogs.com/lanqi/p/10282279.html
索引下推:
参考:https://zhuanlan.zhihu.com/p/121084592
SELECT * from user where name like '陈%' and age=20
联合索引(name,age)
没有索引下推时:会忽略age这个字段,直接通过name进行查询,在(name,age)这课树上查找到了两个结果,id分别为2,1,然后拿着取到的id值一次次的回表查询,因此这个过程需要回表两次
有索引下推:InnoDB并没有忽略age这个字段,而是在索引内部就判断了age是否等于20,对于不等于20的记录直接跳过,因此在(name,age)这棵索引树中只匹配到了一个记录,此时拿着这个id去主键索引树中回表查询全部数据,这个过程只需要回表一次。
一些技巧:
- 条件里不写表达式::where d=2+3
- 会不会某些字段建索引比不建索引还慢:有回表这个过程,可能io边多
- 前缀索引:字符串,不需要用完整的列做索引。假如字符串特别长 前7个字符做索引
- union all in都能用到索引:推荐用in
- 范围列能用到索引,但范围列后面的列无法用到索引了
- 强制类型转换会引起全表扫描
- 更新很频繁、区分度高的数据列不适合加索引
-
搞join的时候最好不要超过三张表
-
能用limit最好
-
单表索引最好不超过5个
-
组合索引不超过5个字段

 浙公网安备 33010602011771号
浙公网安备 33010602011771号