对于北京市租房信息数据采集分析
一、选题背景
在如今的时代,疯狂上涨的房价让年轻人买房愈发困难,因此租房成为年轻人更优先的选择,这次数据分析整合了大多数年轻人向往的首都北京的租房价格现状,让年轻人在选择时更得心应手。
二、大数据分析设计方案
1.通过用户数目极多的租房网站(本次选择信息来源网站为:58同城租房https://bj.58.com/zufang/)获取出租房屋的各种信息
三.数据分析步骤
1.获取出租房屋的数据(来源https://bj.58.com/zufang/)
#导入必要的库 # Data Manipulation import numpy as np import pandas as pd #Visualization import matplotlib. pyplot as plt import missingno import seaborn as sns from pandas.tools.plotting import scatter_matrix from mpl_toolkits.mplot3d import Axes3D #Feature selection and Encoding from sklearn. feature_selection import RFE,RFECV from sklearn.svm import SVR from sklearn.decomposition import PCA from sklearn. preprocessing import OneHotEncoder,LabelEncoder,label_binarize #Machine learning import sklearn. ensemble as ske from sklearn import datasets,model_selection,tree,preprocessing,metrics,linear_model from sklearn.svm import LinearSVC from sklearn. ensemble import RandomForestClassifier,GradientBoostingClassifier from sklearn. neighbors import KNeighborsClassifier from sklearn. naive bayes import GaussianNB import requests,json,csv for page in range(54): url='https://gongyu.58.com/guide/api_for_renting?displayLimitNum=15&basequery=room:j|cityId:1|areaId:1|cateId:8&cookie=e87rZl4Z2EYLG6ynBNNEAg==&pageNum={0}&_=1603797279731'.format(page) response=requests.get(url) response.encoding='utf-8' data=json.loads(response.text)['data'] data=data['position1']['list'][1:]+data['position2']['list'][1:]+data['position3']['list'][1:]+data['position4']['list'][1:] for i in data: name=i['title'].replace(' ','') layout = i['layout'] area = i['rentRoomArea'] infor=i['dispLocal'] money=i['price'] print(name) print(layout) print(area) print(infor) print(money) result = [name, layout, area, infor, money] with open('租房数据.csv', 'a+',newline='', encoding='gb18030') as f: f_csv = csv.writer(f) f_csv.writerow(result)
北京各区出租房屋的信息已经有了,为了能对北京目前的租房市场有更直观的认识,对数据进行分析并可视化展示
#分析各行政区房源数量及单价 import pandas as pd beijing_daname=['朝阳区', '丰台区', '海淀区', '大兴区', '通州区', '昌平区', '东城区', '西城区', '顺义区'] data=pd.read_csv('北京租房数据.csv',encoding='gbk') areas=list(set(list(data['行政区']))) area_sums={} for area in areas: area_sums[area]=list(data['行政区']).count(area) from pyecharts import options as opts from pyecharts.charts import Bar import random hotel_num=[area_sums[i] for i in beijing_daname] bar = ( Bar() .add_xaxis(beijing_daname) .add_yaxis("", hotel_num) .set_global_opts(title_opts=opts.TitleOpts(title="北京各区出租房屋数量")) .set_series_opts( label_opts=opts.LabelOpts(is_show=True), markline_opts=opts.MarkLineOpts( data=[ opts.MarkLineItem(type_="min", name="最小值"), opts.MarkLineItem(type_="max", name="最大值"), opts.MarkLineItem(type_="average", name="平均值"), ] ), ) ) bar.render_notebook()
得到的统计图如下

由此可见,北京市内朝阳区的房源数量最多,有1877套;顺义区的房源数量最少,只有272套;9个行政区,每个区平均房源数为611套。
#各行政区出租房屋单价
unit_price={} for i in list(data.groupby('行政区')): if i[0] in beijing_daname: unit_price[i[0]]=int(i[1]['价格'].sum()/i[1]['面积'].sum())*50 unit_price bar = ( Bar() .add_xaxis(list(unit_price.keys())) .add_yaxis("", [unit_price[i] for i in list(unit_price.keys())]) .set_global_opts(title_opts=opts.TitleOpts(title="北京市各行政区出租房屋单价(每平米单价*50平米为例)")) .set_series_opts( label_opts=opts.LabelOpts(is_show=True), markline_opts=opts.MarkLineOpts( data=[ opts.MarkLineItem(type_="min", name="最小值"), opts.MarkLineItem(type_="max", name="最大值"), opts.MarkLineItem(type_="average", name="平均值"), ] ), ) ) bar.render_notebook()
得出如下结果
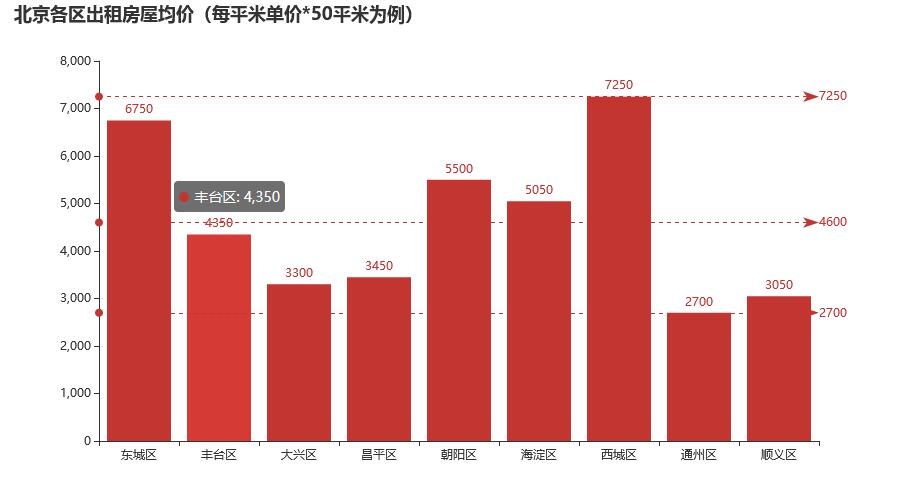
以租房面积为五十平方米为例:
北京市西城区的住房价格最高,为4350元/间;通州区的租房价格最低,为1620元/间,由此可见不同地域位置的价格差距很大。
#分析各户型占比及价格分布
#本次分析户型所列举的为['1室1厅1卫', '2室1厅1卫', '1室0厅1卫', '3室2厅2卫', '2室2厅1卫', '3室1厅1卫', '2室2厅2卫', '2室1厅2卫', '3室1厅2卫', '1室2厅2卫']十种户型
layouts=list(set(data['户型'])) layout=data.loc[:,'户型'].value_counts() from pyecharts import options as opts from pyecharts.charts import Pie print(list(layout.index)[:10]) values=[int(i) for i in list(layout.values)[:10]] pie = ( Pie() .add( "", [(i,j)for i,j in zip(list(layout.index)[:10],values)], radius=["30%", "75%"], center=["40%", "50%"], rosetype="radius", label_opts=opts.LabelOpts(is_show=False), ) .set_global_opts( title_opts=opts.TitleOpts(title="北京市各区出租房屋户型占比"), legend_opts=opts.LegendOpts(type_="scroll", pos_left="85%", orient="vertical"),) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c},{d}%")) ) pie.render_notebook()
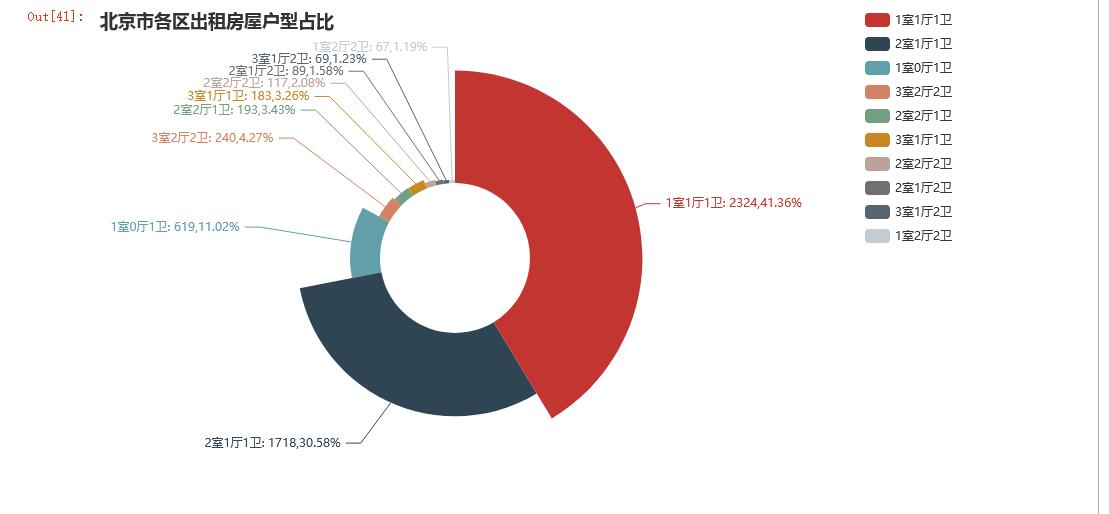
分析结果如下
![]()
本次统计数据分析可以看出,出租房屋的主流是1室1厅1卫,占比41.86%;,其次分别是是2室1厅1卫、1室0厅1卫,各占比30.58%和11.02%,因此可以看出,小户型在出租房屋中更占优势、更受租客的欢迎。
#分析北京市各区出租房屋户型占比以及价格
cut_n=list(range(0,12000,1000)) income=pd.cut(data["价格"],cut_n) price_cut=data['价格'].groupby(income).count() index=list(price_cut.index) index=[str(i) for i in list(price_cut.index)] values=[int(i) for i in list(price_cut.values)] pie = ( Pie() .add( "", [(i,j)for i,j in zip(index,values)], radius=["30%", "75%"], center=["40%", "50%"], rosetype="radius", label_opts=opts.LabelOpts(is_show=False), ) .set_global_opts( title_opts=opts.TitleOpts(title="北京市各区出租房屋户型占比"), legend_opts=opts.LegendOpts(type_="scroll", pos_left="85%", orient="vertical"),) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}, {d}%")) ) pie.render_notebook()
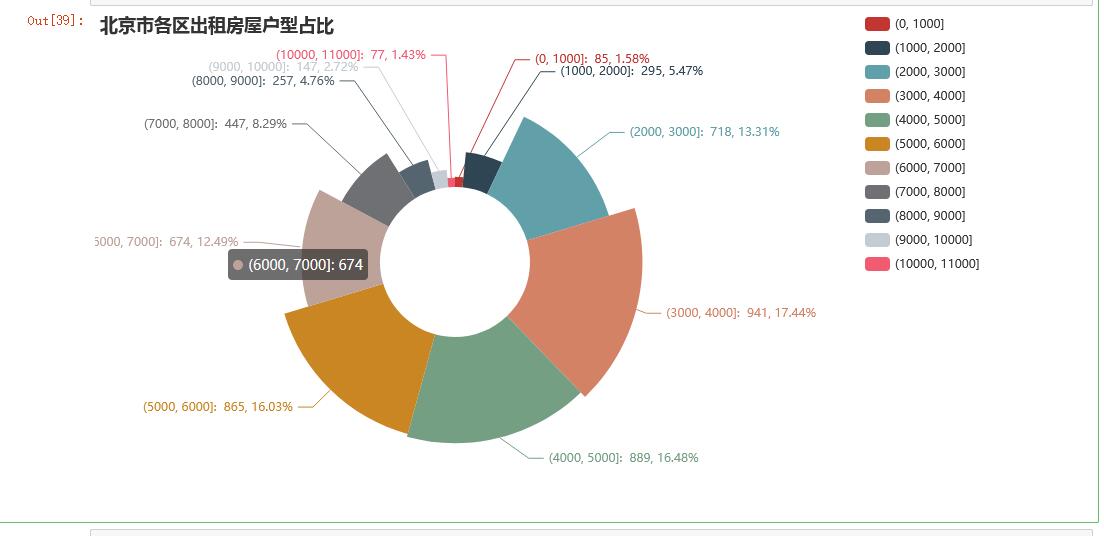
目前,大部分北京租客的租房价格在3000至6000元,占比50%左右,最便宜有1000元以下的,但位置相对较偏,且面积在20平以内;贵的有1万多的,这种一般面积在100平以上,位置在主城区,但选择此类房屋的租客极少,更多人还是选择了性价比更高的小户型。
#开始前导入必要的库
# Data Manipulation
import numpy as np import pandas as pd
#Visualization
import matplotlib. pyplot as plt import missingno import seaborn as sns from pandas.tools.plotting import scatter_matrix from mpl_toolkits.mplot3d import Axes3D
#Feature selection and Encoding
from sklearn. feature_selection import RFE,RFECV from sklearn.svm import SVR from sklearn.decomposition import PCA from sklearn. preprocessing import OneHotEncoder,LabelEncoder,label_binarize
#Machine learning import sklearn. ensemble as ske from sklearn import datasets,model_selection,tree,preprocessing,metrics,linear_model from sklearn.svm import LinearSVC from sklearn. ensemble import RandomForestClassifier,GradientBoostingClassifier from sklearn. neighbors import KNeighborsClassifier from sklearn. naive bayes import GaussianNB import requests,json,csv #分析网页,获取原始数据 #通过抓包,获取数据接口,通过pageNum参数控制页码,共有54页数据,返回json格式数据 for page in range(54): url='https://gongyu.58.com/guide/api_for_renting?displayLimitNum=15&basequery=room:j|cityId:1|areaId:1|cateId:8&cookie=e87rZl4Z2EYLG6ynBNNEAg==&pageNum={0}&_=1603797279731'.format(page) response=requests.get(url) response.encoding='utf-8' data=json.loads(response.text)['data'] data=data['position1']['list'][1:]+data['position2']['list'][1:]+data['position3']['list'][1:]+data['position4']['list'][1:] for i in data: name=i['title'].replace(' ','') layout = i['layout'] area = i['rentRoomArea'] infor=i['dispLocal'] money=i['price'] print(name) print(layout) print(area) print(infor) print(money) result = [name, layout, area, infor, money] #存入csv表格中准备后续使用 with open('租房数据.csv', 'a+',newline='', encoding='gb18030') as f: f_csv = csv.writer(f) f_csv.writerow(result) #分析各行政区房源数量及单价 import pandas as pd
beijing_daname=['朝阳区', '丰台区', '海淀区', '大兴区', '通州区', '昌平区', '东城区', '西城区', '顺义区'] data=pd.read_csv('北京租房数据.csv',encoding='gbk') areas=list(set(list(data['行政区']))) area_sums={}
for area in areas: area_sums[area]=list(data['行政区']).count(area)
from pyecharts import options as opts from pyecharts.charts import Bar import random
hotel_num=[area_sums[i] for i in beijing_daname]
bar = ( Bar() .add_xaxis(beijing_daname) .add_yaxis("", hotel_num) .set_global_opts(title_opts=opts.TitleOpts(title="北京各区出租房屋数量")) .set_series_opts( label_opts=opts.LabelOpts(is_show=True), markline_opts=opts.MarkLineOpts( data=[ opts.MarkLineItem(type_="min", name="最小值"), opts.MarkLineItem(type_="max", name="最大值"), opts.MarkLineItem(type_="average", name="平均值"), ] ), ) )
bar.render_notebook() #各行政区出租房屋单价 unit_price={}
for i in list(data.groupby('行政区')): if i[0] in beijing_daname: unit_price[i[0]]=int(i[1]['价格'].sum()/i[1]['面积'].sum())*50 unit_price
bar = ( Bar() .add_xaxis(list(unit_price.keys())) .add_yaxis("", [unit_price[i] for i in list(unit_price.keys())]) .set_global_opts(title_opts=opts.TitleOpts(title="北京各区出租房屋均价(每平米单价*50平米为例)")) .set_series_opts( label_opts=opts.LabelOpts(is_show=True), markline_opts=opts.MarkLineOpts( data=[ opts.MarkLineItem(type_="min", name="最小值"), opts.MarkLineItem(type_="max", name="最大值"), opts.MarkLineItem(type_="average", name="平均值"), ] ), ) )
bar.render_notebook() #分析各户型占比及价格分布 #本次分析户型所列举的为: #['1室1厅1卫', '2室1厅1卫', '1室0厅1卫', '3室2厅2卫', '2室2厅1卫', '3室1厅1卫', '2室2厅2卫', '2室1厅2卫', '3室1厅2卫', '1室2厅2卫']十种户型 layouts=list(set(data['户型'])) layout=data.loc[:,'户型'].value_counts()
from pyecharts import options as opts from pyecharts.charts import Pie print(list(layout.index)[:10])
values=[int(i) for i in list(layout.values)[:10]]
pie = ( Pie() .add( "", [(i,j)for i,j in zip(list(layout.index)[:10],values)], radius=["30%", "75%"], center=["40%", "50%"], rosetype="radius", label_opts=opts.LabelOpts(is_show=False), )
.set_global_opts( title_opts=opts.TitleOpts(title="北京市各区出租房屋户型占比"), legend_opts=opts.LegendOpts(type_="scroll", pos_left="85%", orient="vertical"),) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c},{d}%")) )
pie.render_notebook() #分析北京市各区出租房屋户型占比以及价格 cut_n=list(range(0,12000,1000))
income=pd.cut(data["价格"],cut_n) price_cut=data['价格'].groupby(income).count()
index=list(price_cut.index)
index=[str(i) for i in list(price_cut.index)]
values=[int(i) for i in list(price_cut.values)] pie = ( Pie() .add( "", [(i,j)for i,j in zip(index,values)], radius=["30%", "75%"], center=["40%", "50%"], rosetype="radius", label_opts=opts.LabelOpts(is_show=False), )
.set_global_opts( title_opts=opts.TitleOpts(title="北京市各区出租房屋户型占比"), legend_opts=opts.LegendOpts(type_="scroll", pos_left="85%", orient="vertical"),)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}, {d}%")) )
pie.render_notebook()
四、总结
经过对主题数据的分析与可视化,可以得出,北京市不仅有着高昂的房价,租房价格也非常高,当代年轻人肩上所担负的压力非常大。
数据的采集与分析可以让人对繁杂的数据有非常直观的感受,但是本次采集的数据还只是一小部分,总的来说信息数据采集范围不够广泛,样本不够全面,我还会继续加深学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号