


第二次大作业数据采集
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。 输出信息:
| 序号 | 地区 | 日期 | 天气信息 | 温度 |
| 1 | 北京 | 7日(今天) | 晴间多云,北部山区有阵雨或雷阵雨转晴转多云 | 31℃/17℃ |
| 2 | 北京 | 8日(明天) | 多云转晴,北部地区有分散阵雨或雷阵雨转晴 | 34℃/20℃ |
| 3 | 北京 | 9日(后台) | 晴转多云 | 36℃/22℃ |
| 4 | 北京 | 10日(周六) | 阴转阵雨 | 30℃/19℃ |
| 5 | 北京 | 11日(周日) | 阵雨 | 27℃/18℃ |
| 6... |
url构建
经测试,各城市的url是通过其对应的标识码进行区分;
因此,可以通过标识码进行url的构建。
代码实现上,使用dict对城市和对应的标识码进行映射,通过输入城市名称实现请求:
cityCode = {
"北京": "101010100",
"上海": "101020100",
"广州": "101280101",
"深圳": "101280601"
}
if __name__ == '__main__':
cityName = "北京"
# 获取html
url = f'http://www.weather.com.cn/weather/{cityCode[cityName]}.shtml'
发送请求
这里使用的是requests库进行实现:
response = requests.get(url) response.encoding = "utf-8" html = response.text
构建soup对象并提取信息
对页面进行解析,发现该网页数据较为规整,目标数据均位于class = "t clearfix"的ul下的各个li中: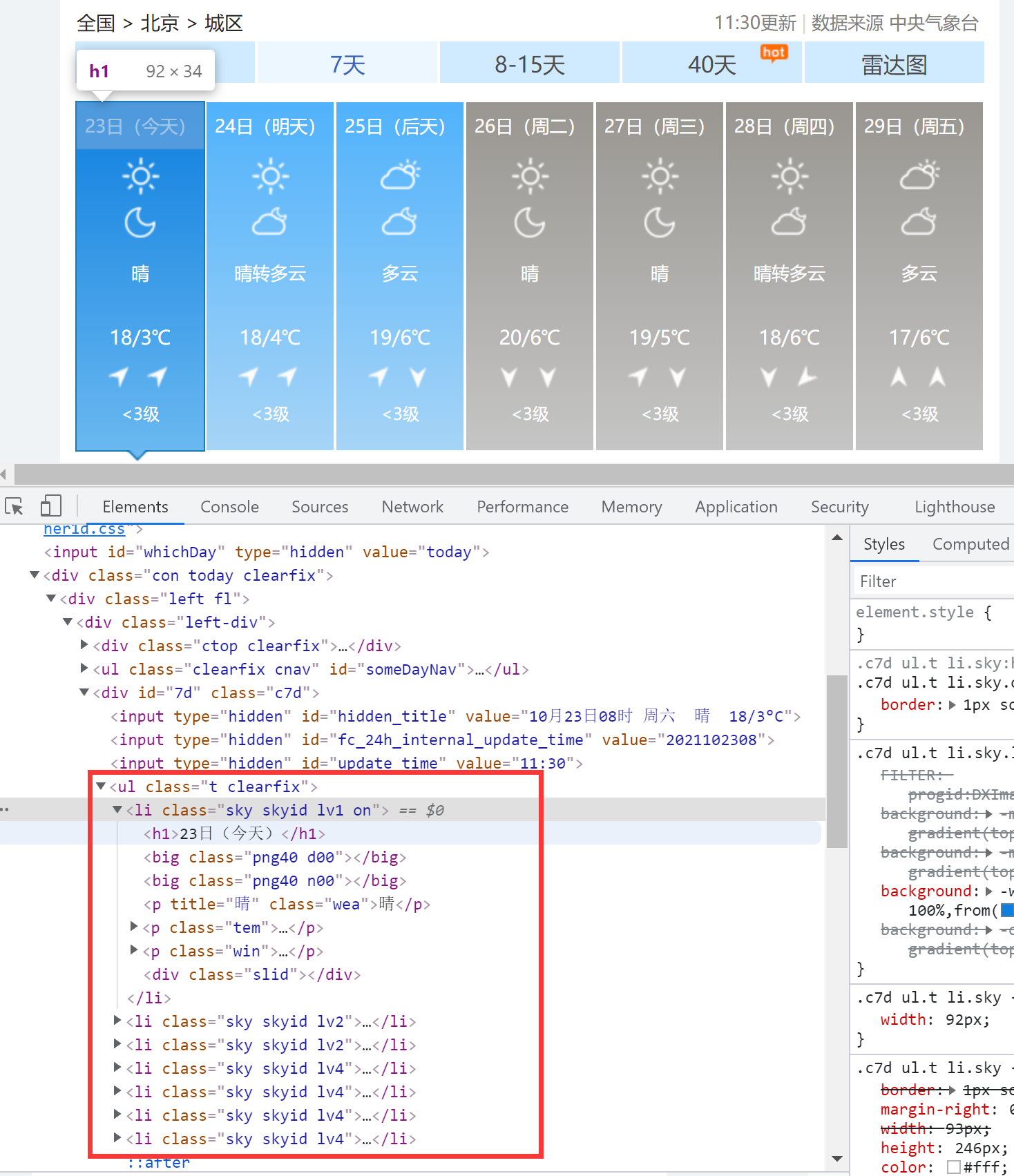
使用css进行选择ul,并遍历其中的li数据:
# 构建soup对象 soup = BeautifulSoup(html, "lxml")解析表格
ul = soup.find('ul', attrs={"class": "t clearfix"})
for li in ul.find_all('li'):
day = li.find('h1').text
msg = li.find_all('p')[0].text
temp = li.find_all('p')[1].text
temp = clear_data(temp)
print(cityName, day, msg, temp)
数据库保存
这里我使用pymysql构建了一个极简的mysql数据库连接类(CURD均未进行封装):
import pymysqlmysql连接极简封装
class DB:
host = '127.0.0.1'
port = 3306
user = 'root'
passwd = '******'def __init__(self): self.connection = pymysql.connect(host=self.host, port=self.port, user=self.user, passwd=self.passwd) self.driver = self.connection.cursor()
在爬虫开始前,应先连接数据库,并且创建数据表(内容包括城市,时间,天气信息,温度):
from mysql import DB创建数据库表单
db = DB()
db.driver.execute('use spider_test')
db.driver.execute('drop table if exists weather')
sql_create_table = """ CREATE TABLEweather(
idint(11) NOT NULL AUTO_INCREMENT,
cityvarchar(20) DEFAULT NULL,
udatevarchar(20) DEFAULT NULL,
msgvarchar(20) DEFAULT NULL,
tempvarchar(20) DEFAULT NULL,
PRIMARY KEY (id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
"""
db.driver.execute(sql_create_table)
最后,对每条数据进行插入操作(异常回滚已省略):
sql_insert = f'insert into weather(city, udate, msg, temp) values ("{cityName}", "{day}", "{msg}", "{temp}")'
db.driver.execute(sql_insert)
db.connection.commit()
运行结果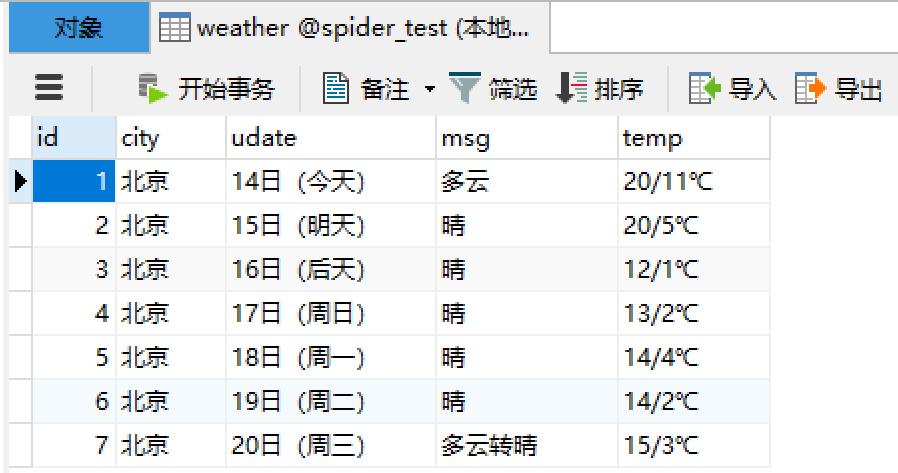
作业2
要求:用requests和自选提取信息方法定向爬取股票相关信息,并存储在数据库中。
抓包
由于该网页属于动态渲染网页,数据通过ajax进行动态渲染,因此需要进行抓包。
打开F12并刷新,获取浏览器发送的js请求。
如下进行解析:
1. 随便复制一个股票名称;
2. 启动搜索,粘贴复制的股票名称;
3. 搜索栏中出现一个(或多个 -> 随着时间会进行额外的数据刷新请求)含有该页所有股票代码信息的请求接口;
4. 右侧Response中可以预览到所有数据。
参数解析
上步中获取到的接口url如下:
http://67.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112407972169804676412_1634974778877&pn=1&pz=20&po=1&np=1&
可以看到,在url后,跟着很多get参数,可以对参数进行修改来完善爬虫。
因此我进行了一些尝试(请求经过验证,均与实际页面相匹配):
首先,最先看到的是pn和pz两个参数。
在后端编写接口中,一般都会使用page_num和page_size对应页码和分页大小,pn和pz则是这两个变量的缩写。
然后是cb=jQuery.......参数。
jQuery是基于js的一个框架,虽然对前端这块不太了解,但是一般情况,前后端分离项目需有一定的请求规范,而爬取到的接口细看是在Restful API的基础上添加一层jQuery函数封装。
可以大胆推测,该接口是专门对jQuery进行的适配,而用于控制这个适配可能性最高的参数就是cb参数(因为里面出现了jQuery)。
删除后,接口数据使用json格式进行返回(这后端接口不规范):
很直观的看出,data中的diff对应是一个list类型数据,启动包含的 f* 就是我们所需要数据。 接着是数据范围限定
经过人工比对,各字段和参数名对应表如下:
| 股票代码 | f12 |
| 名称 | f14 |
| 最新报价 | f2 |
| 涨跌幅 | f3 |
| 涨跌额 | f4 |
| 成交量 | f5 |
| 成交额 | f6 |
| 振幅 | f7 |
| 最高 | f15 |
| 最低 | f16 |
| 今开 | f17 |
| 昨收 | f18 |
最后是其他一些未知作用的参数,可能是后端进行埋点使用,逐个进行筛选,去掉不必要参数,最后,参数添加如下:
# 需要的参数,其他的参数就不需要请求了
needParams = ['f12', 'f14', 'f2', 'f3', 'f4', 'f5', 'f6', 'f7', 'f15', 'f16', 'f17', 'f18']
fields = ",".join(needParams) # 合并成fields参数
# 输入分页相关参数限定爬取数量和范围,fid为股票种类(f3为目的),fields限定返回参数
# 和爬取到的接口相比,去掉了cb=jQuery....参数,就可以直接返回json格式数据
url = f'http://60.push2.eastmoney.com/api/qt/clist/get' \
f'?pn={pageNum}' \
f'&pz={pageSize}' \
f'&po=1&np=1&fltt=2&invt=2' \
f'&fid={fid}&fs=m:1+s:2' \
f'&fields={fields}'
(po=1&np=1&fltt=2&invt=2作用未知,但是删除将导致请求未空)
数据库构建
db = DB()
db.driver.execute('use spider_test')
db.driver.execute('drop table if exists money')
sql_create_table = """ CREATE TABLE `money` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`code` varchar(64) DEFAULT NULL,
`name` varchar(64) DEFAULT NULL,
`zxbj` varchar(64) DEFAULT NULL,
`zdf` varchar(64) DEFAULT NULL,
`zde` varchar(64) DEFAULT NULL,
`cjl` varchar(64) DEFAULT NULL,
`cje` varchar(64) DEFAULT NULL,
`zf` varchar(64) DEFAULT NULL,
`high` varchar(64) DEFAULT NULL,
`low` varchar(64) DEFAULT NULL,
`jk` varchar(64) DEFAULT NULL,
`zs` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
"""
db.driver.execute(sql_create_table)

原则上,数据库字段名不应该出现中文字符,因此,数据库命名看着有些随意。
插入操作和作业一中大同小异,这里就不再展示了。
结果展示
当前只创建一张数据表进行实验,如有实际需求需要使用按时间对表进行划分,不能把所有时间段数据杂在一张表内(不然没有意义)。
另外,仅保存源数据信息,方便数据分析或可视化操作,数据转义(加%或加万、亿等)不应该在数据库中进行。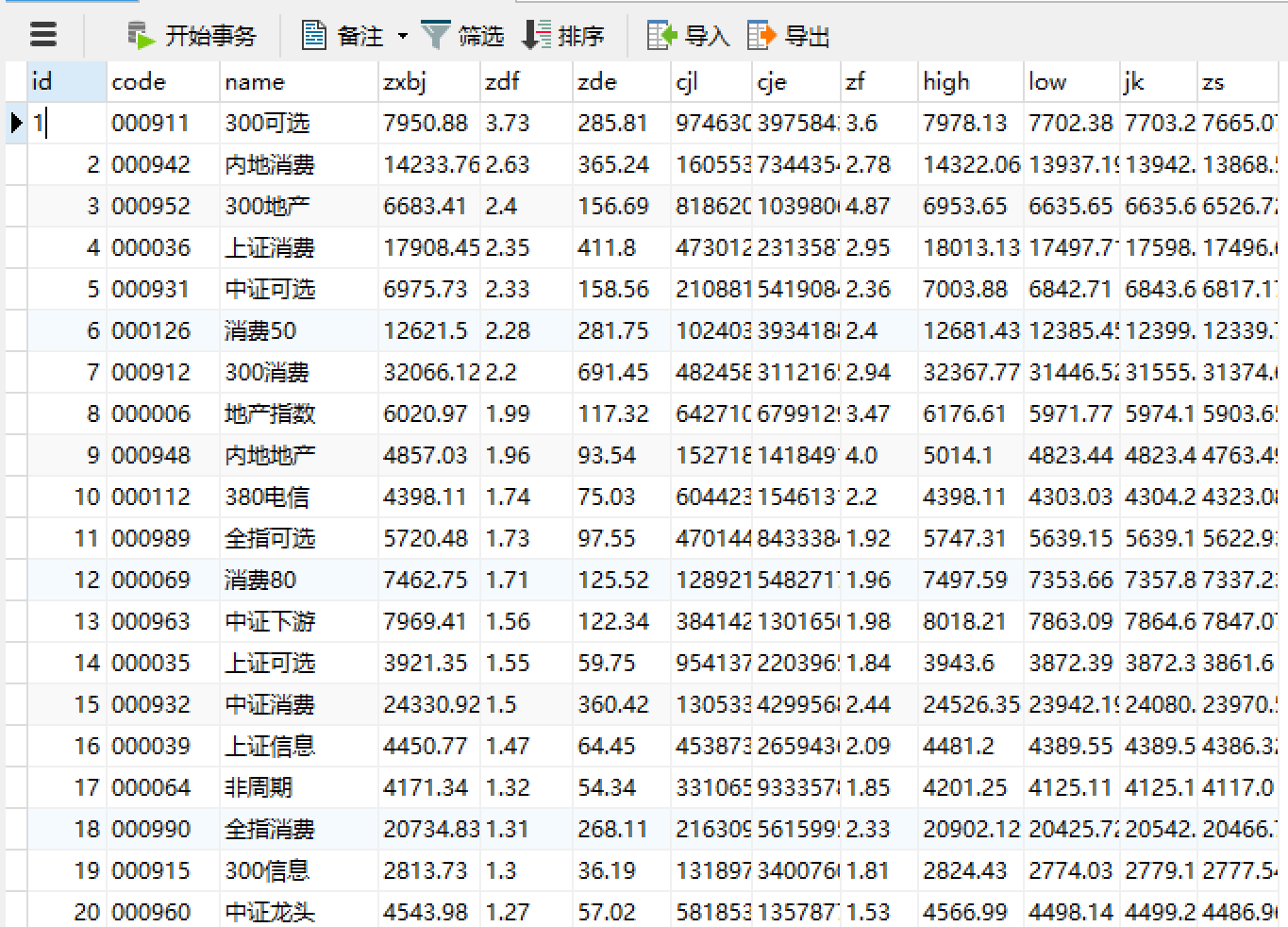
作业3
爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所
有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
输出信息:
| 排名 | 学校 | 总分 |
| 1 | 清华大学 | 969.2 |
抓包:
该网页的翻页实现比较特殊,是通过一次性返回所有数据,然后通过js函数进行动态实现。
和第二题的抓包一样,采用搜索的方式获取消息来源。
由于福州大学不在第一页,我们可以通过使用搜索"南方小清华""福州大学"进行搜索,很快就找到了数据来源于一个payload.js脚本: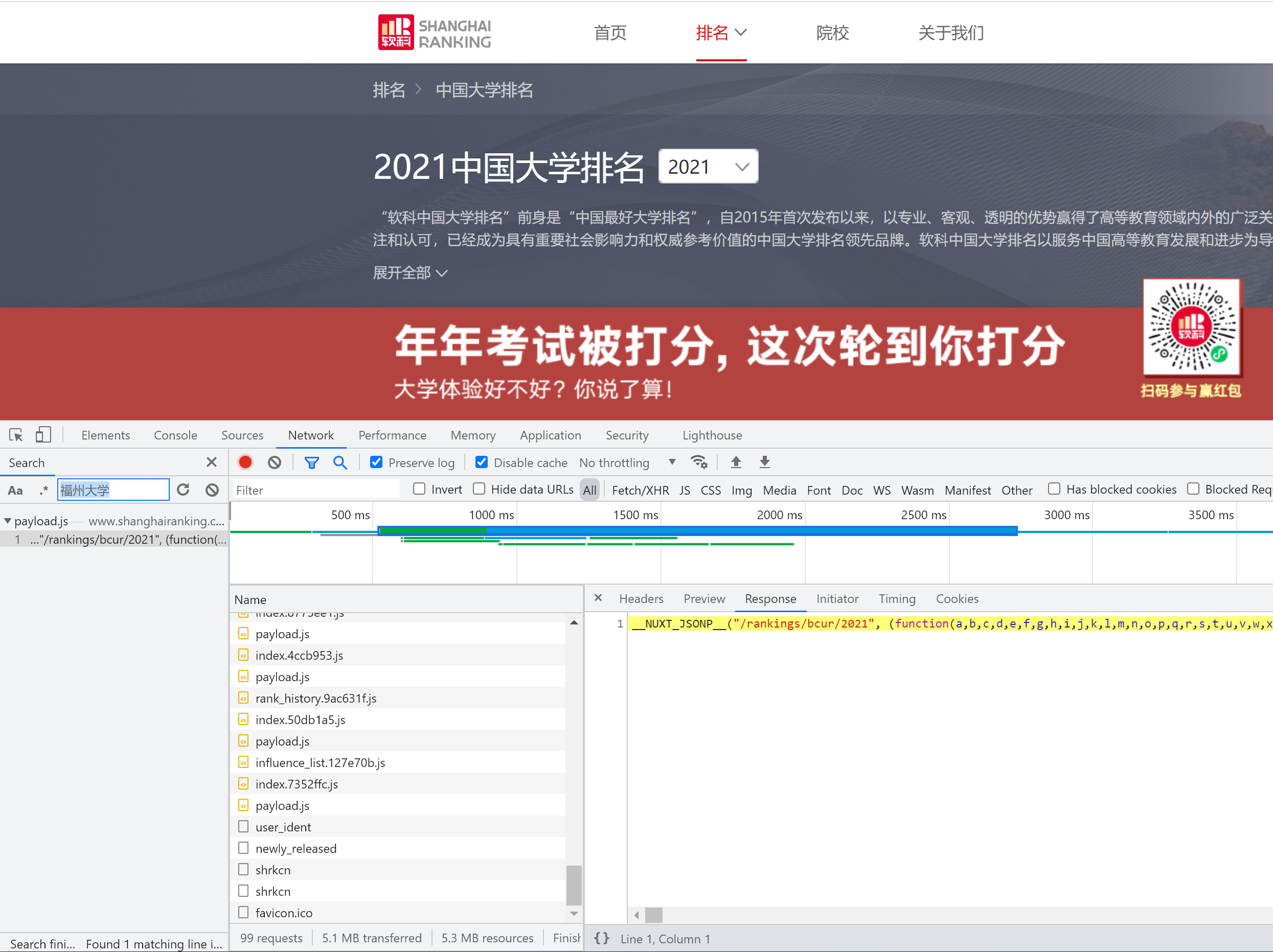
2. 解析网页
nameList = re.findall(r'univNameCn:"(.*?)"', html, re.S) scoreList = re.findall(r'score:(.*?),', html, re.S)
使用正则表达式,可以快速提取参数,但是发现相同分数下,排名会使用参数进行替代,如:
观察请求到的js脚本,发现其结构为一个函数,前方函数头存有参数名,结尾则存有参数值。
因此,只要获取参数名和参数值的对应表,对异常数据进行替代,就解决上述出现的问题。
参数提取:仍然使用正则表达式提取出参数名(keys)和参数值(values),并使用split(",")进行分割,并结合转换为dict类型:
keys = re.findall(r'function\((.*?\))', html)[0].split(',')
values = re.findall(r'\((.*?)\)', html)[-1]
params = dict(zip(keys, values))
然而,出现了元素对应错误的问题,打印keys和values长度,发现两者长度相差1,检查数据发现在一个字符串中,存在","对分割进行了干扰
这种情况,解决方法很多,我选择的是一个很“Python”的方法,使用eval函数进行解析:
1. 先将字符串进行处理,把一些类型换成Python的表达方式(如:true->True, null->None)等;
2. 将字符串用中括号"包起来";
3. 直接使用eval转为list形式
values = eval("[" +
values.replace("true", "True").replace("false", "False").replace("null", "None")
+ "]")
结果展示
编写一个简单的替换代码,实现参数替换: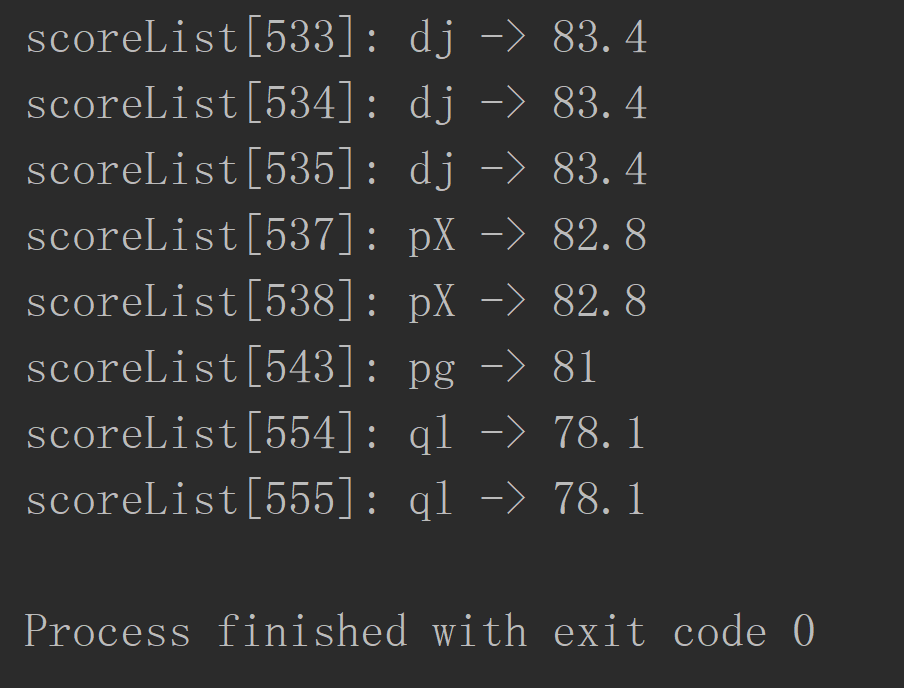
数据库构建上,和上面区别不大,但是要注意,排名rank存在重复,因此不能作为主键,需要另外使用id字段进行区分。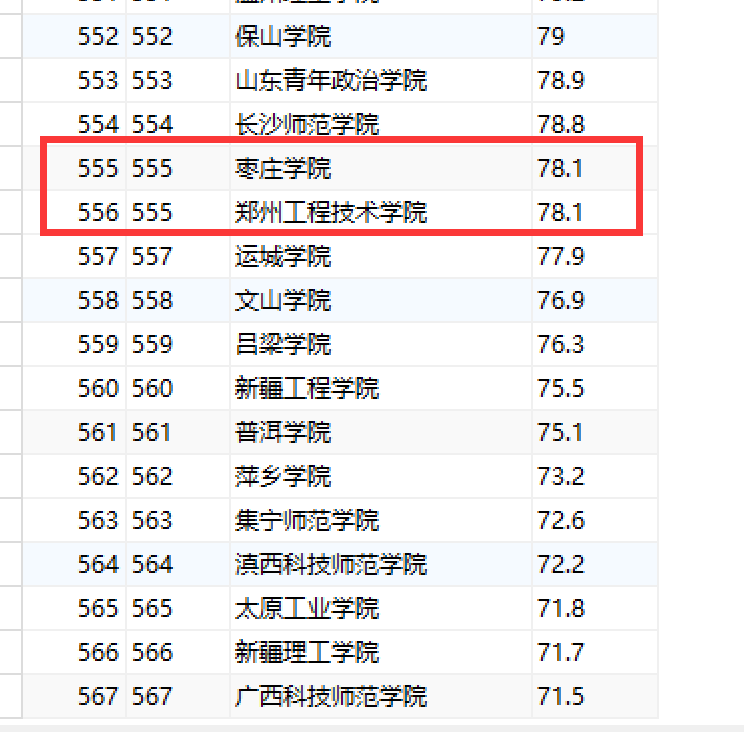
代码地址:https://gitee.com/mirrolied/spider_test

 浙公网安备 33010602011771号
浙公网安备 33010602011771号