


第三次大作业数据采集
作业1 要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位) 输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件夹中,并给出截图。 思路: 爬取一个网站的所有图片,需要两个提取操作: 1. 提取所有子url(获取所有a标签) 2. 提取所有图片(获取所有img标签)
soup = BeautifulSoup(html, "lxml")
urls = set(tuple([url.get('href') for url in soup.find_all('a')]))
imgs = set(tuple([img.get('src') for img in soup.find_all('img')]))
# 转为set是方便进行差集运算
操作为搜索并保存所有图片,然后依次进入到下一个子url进行遍历。
页面遍历去重
不妨先假设子url与父url为树形结构,即各url节点之间无环或回路: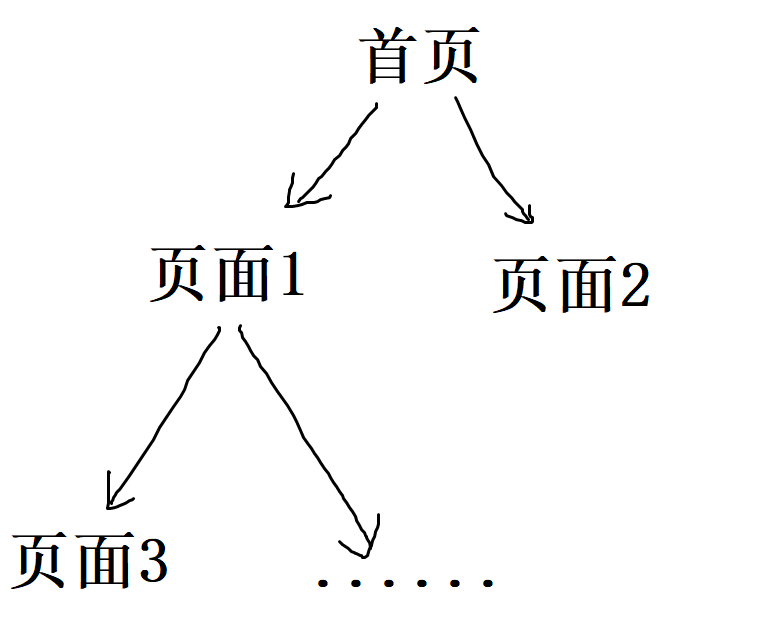
通过遍历(如:dfs),就可以将树上url上所有的图片都找出来。
然而,实际情况是,网站url组成的图中存在较多的环与回路(比如所有页面都指向首页)
为了解决重复爬取同一页面,可以选择采用set类型全局变量进行存储已经过的路径。
在获取到子url时,与已经过的路径取差集,即可去重。
over_urls = set()
def dfs(target_url: str):
# 模拟dfs进行遍历
"""
图片提取代码
"""
# 取差集
target_urls = urls.difference(over_urls)
# 遍历
[dfs(url) for url in target_urls]
复制代码
将遍历进行修改可以是遍历url实现并发:
# 并发遍历
import threading
threads = [threading.Thread(target=dfs, args=(url, 20)) for url in target_urls]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
在图片方面,也存在图片在不同页面的复用情况,同上采用set类型全局变量,对已下载的图片路径进行存储,防止重复下载。
target_imgs = imgs.difference(over_imgs)
for i, img in enumerate(target_imgs):
if i >= limit:
break
save_img(img)
保存图片
def save_img(img_url):
print(f"正在保存:{img_url}")
# 普通下载
# download(img_url)
# 并发下载
import threading
t = threading.Thread(target=download, args=[img_url])
t.start()
def download(img_url):
try:
resp = requests.get(img_url)
except:
return
with open(f'./images/{img_url.split("/")[-1].split("?")[0]}', 'wb') as f:
f.write(resp.content)
运行结果
由于并发量拉满了,因此输出有些怪异。
(这里的并发量是比较恐怖的,基本上同时爬取了全站可达的url,还要网站没封IP,后续需要添加最大并发数进行限制爬取)
还有一个小细节:在并发下或是错误捕获中,exit()和sys.exit()都不能实现python程序的退出(会被识别成线程错误进行错误捕获),需要使用os._exit()才能成功退出程序。
作业2
使用scrapy框架复现作业1
设置scrapy
# 关闭爬虫协议验证
ROBOTSTXT_OBEY = False
# 设置默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# 设置下载路径
IMAGES_STORE = "./images"
# 启动pipeline
import os
IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'images')
ITEM_PIPELINES = {
'session_2.pipelines.Session2Pipeline': 300,
}
# 启动下载器
DOWNLOADER_MIDDLEWARES = { 'session_2.middlewares.Session2DownloaderMiddleware': 543, }
构建入口文件
# run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl weath -s LOG_ENABLED=True".split())
下载图片
在爬虫函数中,返回一个Item,将图片url递交给pipeline。
# weath.py yield Session2Item(url=img)
重构pipeline,使其继承图片下载类ImagesPipeline。
# pipelines from scrapy import Request from scrapy.pipelines.images import ImagesPipelineclass Session2Pipeline(ImagesPipeline):
# 继承ImagesPipeline
def get_media_requests(self, item, info):
print(item['url'])
yield Request(item['url'])复制代码
图片保存路径由上面设置的IMAGES_STORE决定(图片会放在这个路径下的full目录中)。
* 为方便统计图片下载数量,放弃使用了图片列表,而是采用单张图片的方式作为传递,并发量会略有下降。
-> 改进: 将剩余需要下载数量与当前页码做减法,剩余下载量不足则取差相反数个数进行传参。
作业3
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在imgs路径下。
候选网站: https://movie.douban.com/top250
输出信息:
| 序号 | 电影名称 | 导演 | 演员 | 简介 | 评分 | 封面 |
| 1 | 肖申克的救赎 | 弗兰克·德拉邦特 | 蒂姆·罗宾斯 | 希望让人自由 | 9.7 | ./imgs/xsk.jpg |
| 2 |
对页码进行的Xpath解析如下:
html = response.body.decode('utf-8')
selector = scrapy.Selector(text=html)
movies = selector.xpath("//li/div[@class='item']")
for movie in movies:
item = Session3Item()
item['name'] = movie.xpath(".//span[@class='title']/text()").extract_first()
item['director'] = movie.xpath(".//div[@class='bd']/p/text()").extract_first().split(':')[1][:-2]
item['actor'] = movie.xpath(".//div[@class='bd']/p/text()").extract_first().split(':')[-1]
item['introduction'] = movie.xpath(".//span[@class='inq']/text()").extract_first()
item['score'] = movie.xpath(".//span[@property='v:average']/text()").extract_first()
item['url'] = movie.xpath(".//img/@src").extract_first()
yield item
翻页操作使用url跳转实现:
self.page_num += 1
if self.page_num > 10:
return
yield scrapy.Request(url=self.url.format(self.page_size*(self.page_num-1)), callback=self.parse)
由于豆瓣分页大小为40,因此爬10页就能爬完,当页码大于十页时,退出页码遍历。
Item
item需要包括电影名称、导演、作者、介绍、图片以及链接信息:
class Session3Item(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
director = scrapy.Field()
actor = scrapy.Field()
introduction = scrapy.Field()
score = scrapy.Field()
image = scrapy.Field()
url = scrapy.Field()
Pipelines
由于数据库上传和图片下载的pipeline继承自不同的pipeline(其实就图片下载有个继承),因此在创建上,二者存在冲突。
因此使用两个pipeline分别进行数据库和下载操作:
数据库pipeline:
这里还有一个需要注意的地方,数据库的连接和创建表操作不能放在执行函数中,否则多次运行会导致数据丢失或报错。
from scrapy.pipelines.images import ImagesPipeline from scrapy import Requestclass Session3Pipeline:
from mysql import DB
from settings import DB_CONFIG
db = DB(DB_CONFIG['host'], DB_CONFIG['port'], DB_CONFIG['user'], DB_CONFIG['passwd'])def __init__(self): self.db.driver.execute('use spider') self.db.driver.execute('drop table if exists movies') sql_create_table = """一堆建表的sql语句""" self.db.driver.execute(sql_create_table) def process_item(self, item, spider): sql_insert = f'''insert into movies(...) values (...)''' self.db.driver.execute(sql_insert) self.db.connection.commit() return item
下载pipeline:
通过item_completed可以在下载完成后,通过os模块实现重命名
class DownloadImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
print("正在保存:", item['url'])
yield Request(item['url'])
def item_completed(self, results, item, info):
# 重命名
path = [x["path"] for ok, x in results if ok]
# os模块重命名
os.rename(IMAGES_STORE + "\\" + path[0], IMAGES_STORE + "\\" + str(item['name']) + '.jpg')
最后进行setting.py配置即可:
# 数据库设置
DB_CONFIG = {
'host': '127.0.0.1',
'port': 3306,
'user': 'spider',
'passwd': 'spider',
}
# 取消爬虫验证
ROBOTSTXT_OBEY = False
# 默认请求头
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:92.0) Gecko/20100101 Firefox/92.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# 启动pipelines
import os
IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'imgs')
ITEM_PIPELINES = {
'session_3.pipelines.Session3Pipeline': 300,
'session_3.pipelines.DownloadImagePipeline': 300,
}
由于需要添加到数据库,因此在setting.py中多了数据库配置信息,另外注意同时启动两个pipelines。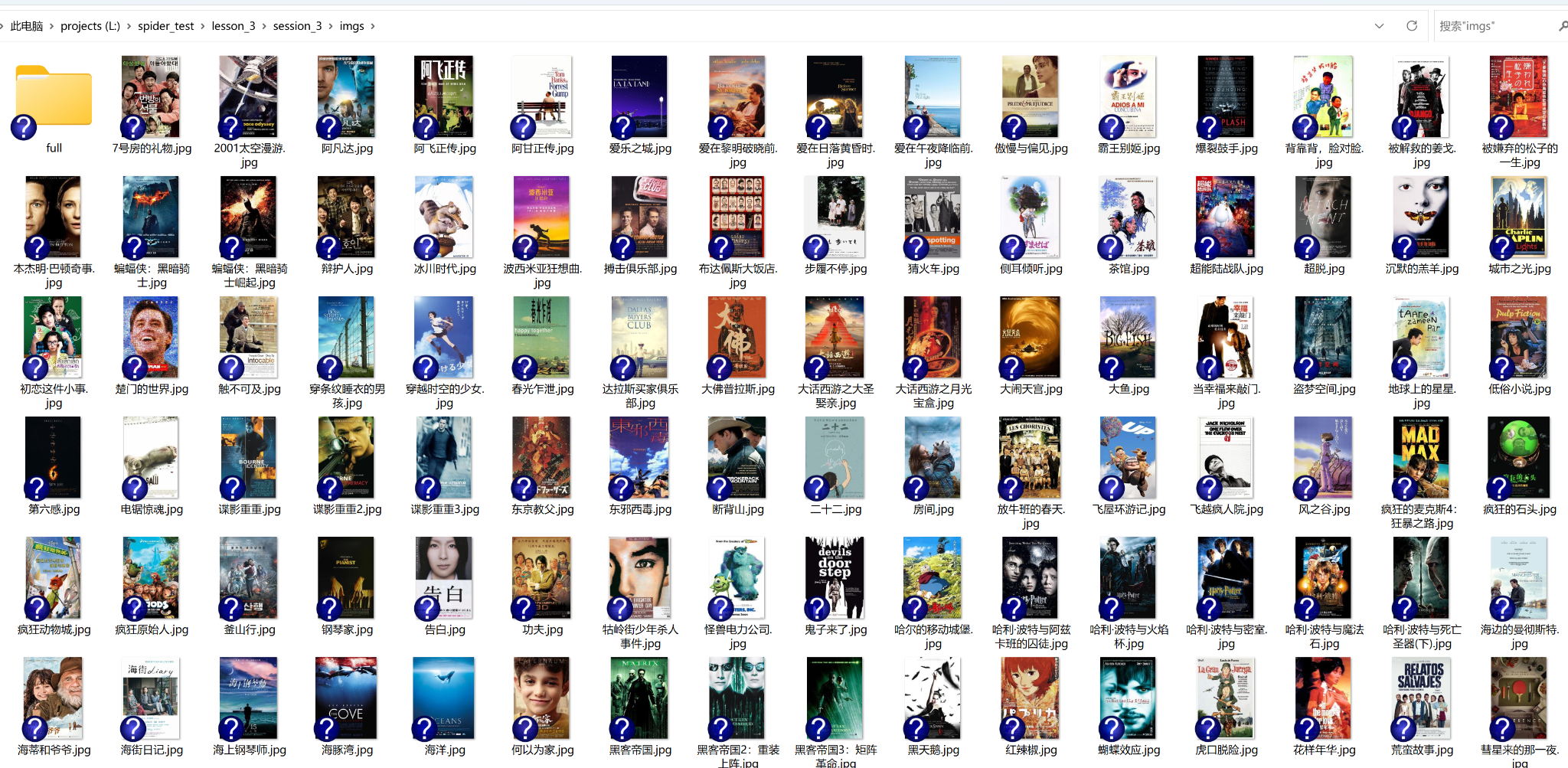


 浙公网安备 33010602011771号
浙公网安备 33010602011771号