
面向对象第一次作业总结与反思
面向对象第一单元作业个人总结与反思
架构设计与代码分析
由于在参阅了一些同学的博客之后,感觉将一整张图片贴上来会影响视觉观感,因此本文尽量缩小了贴上来的图片大小。同理,表格部分只引入了缺陷较大的几项。
第一次作业
架构分析
由于题目比较简单,我并没有去刻意的设计架构。但是自从第一次作业开始,我就确定了我的优化思路:在读入输出时进行优化,而不是读入后优化。
我的设计包括四个类:多项式类、项类、因子类和主类。主类得到字符串后调用多项式类的静态工厂方法进行解析,再调用静态求导方法得到求导后的表达式类的实例,最后进行输出。由于设计比较简单,此处略去类图。
我通过循环匹配项的正则表达式来对整个表达式进行解析,在通过正则表达式对提取出来的项进行进一步拆解,最后得到表达式类的示例。
这个架构埋下了两个隐患:
- 没有可扩展性。没有对各个类进行抽象,增加任何功能都需要大量改动代码,完全没有体现出面向对象的优势,违反了开闭原则;
- 难以进一步优化。由于我尽全力在输入输出部分进行优化,这导致了我的架构无法进行之后两次作业较为精细的优化;
复杂度分析
| 方法名 | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Term.toString | 10 | 8 | 7 | 8 |
| Polynomial.toString | 4 | 4 | 4 | 4 |
| 平均 | 2.05 | 1.82 | 2.18 | 2.50 |
本次作业的复杂度主要出问题在我的两个toString方法上。由于在输出时进行了大量优化(去0、去加减号)等,导致这两个方法中的分支数上涨。而实际上之后我也一直没能将这一部分进行重构,也并没有一个更优雅的方式来解决这个问题。
第二次作业
架构分析
在完成这次作业前我参加了OO的第一次研讨会,其中一次有关设计模式的报告令我感触颇深。在听完这次研讨会之后,我随即开始对我代码中的两个部分进行重构(实际上是几乎完全重构):
- 将输入方式改为递归下降。因为之前听过其他人推荐这种方式,在简单了解了其思想后我在不了解形式化表达语法的前提下写出了一个递归下降的解析器。
- 更改我的现有架构到工厂模式+组合模式。这次作业之后我的架构如下(省略了主类与工厂类);
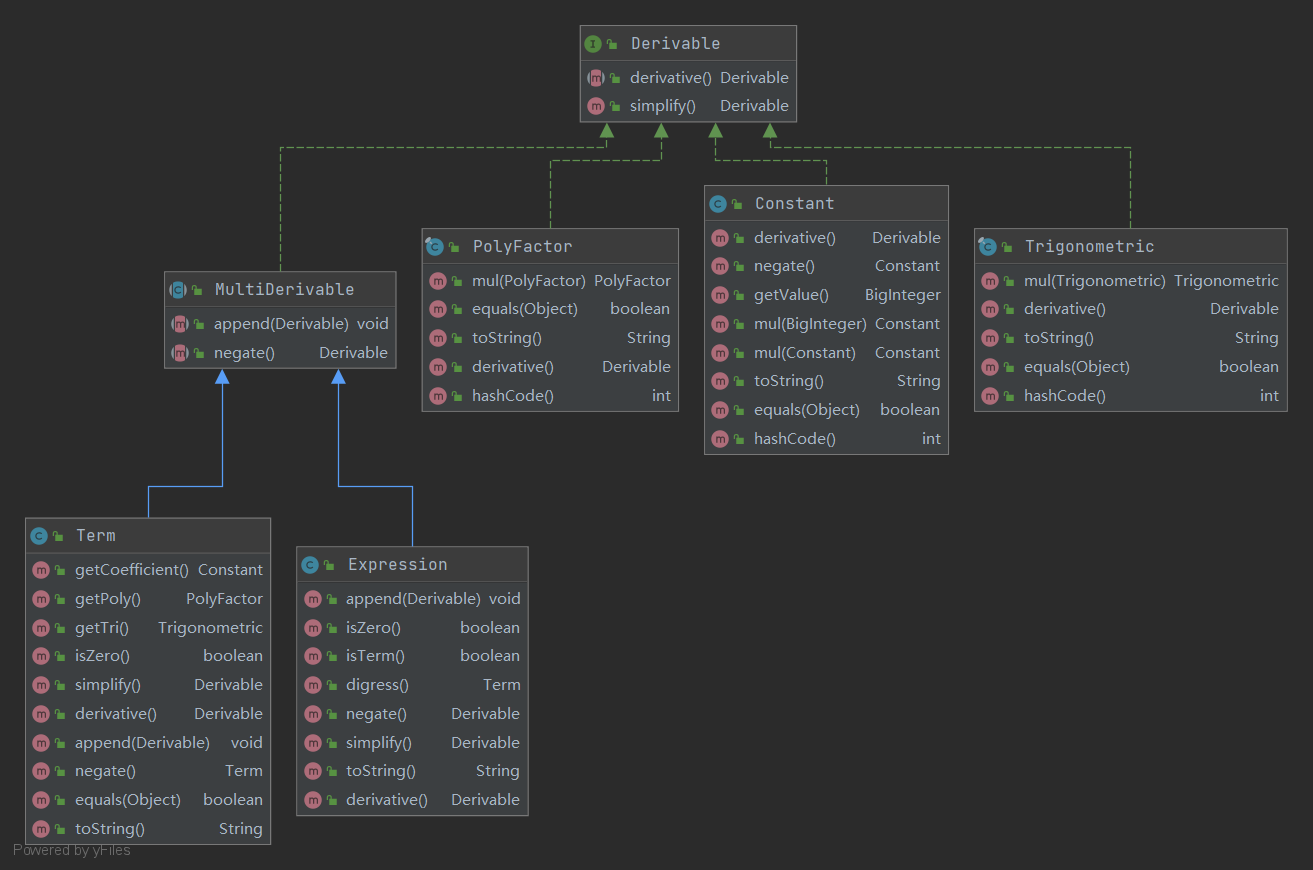
可以看到我已经将各个基础类成功解耦合,并对可导函数抽象出了求导和化简两个方法。在MultiDerivable中我统一使用了ArrayList保存子元素;但由于抽象类使用的不熟练、节省强制类型转换的码量以及后续修改List为Map的可能性,我并没有将其抽象为一个可导函数的ArrayList放到MultiDerivable类中。类之间的继承关系基本上照搬了组合模式的模板。
这样的架构使得我可以轻松完成添加、求导等工作,并且在新增代码量极少的情况下完成了第三次作业;但由于我过分强调在输入、输出的过程中优化表达式,导致了项与表达式两个类之间的强耦合,甚至循环依赖,破坏了继承关系;此外,将各项系数提出来成为单独一个因子也使得我很难应用Map进行化简——因为我的架构中各个类型理论上是平权的。
此外,由于在读入过程中进行了化简,我的部分类中存在着Cyclic-Dependent Modularization的代码问题。(就是在append过程中不断调用自己)
复杂度分析
| 方法名 | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Term.toString | 14 | 2 | 9 | 10 |
| Expression.toString | 8 | 4 | 6 | 7 |
| PolyFactor.toString | 4 | 4 | 1 | 4 |
| Term.append | 16 | 6 | 9 | 9 |
| 平均 | 1.98 | 1.57 | 2.08 | 2.42 |
可以看到,主要的问题仍然在输入、输出函数上,这是因为我在输入输出函数上完成了我的全部简化过程。其中几个ev(G)值较大的函数也在嗅探中被认定为是过于复杂的函数。我应该考虑将各个优化过程拆开执行,或者提供更多的优化方法,并专门新建一个类来处理优化事务,来降低圈复杂度。
第三次作业
架构分析
由于第二次作业设计的架构相对较为成熟,此次作业的架构与上次基本没有区别;唯一区别便是由于三角函数内部的表达式因子在输出时必须要输出括号,而一般表达式在输出时会将最外层的括号优化掉,因此我新建了一个WrappedExpression类继承了Expression类作为三角函数的内嵌表达式因子,并重写了输出函数来保证结果的正确性。
在这一次作业中我试图进行化简,但由于我使用了ArrayList进行存储,化简变得有些困难。我将ArrayList替换成了Map并且写了一百行左右的优化,但因为没有时间完成调试且复杂度太高而最终放弃了同类项的合并。
复杂度分析
| 方法名 | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Expression.toString | 8 | 4 | 6 | 7 |
| PolyFactor.toString | 4 | 4 | 3 | 4 |
| Term.append | 17 | 6 | 9 | 9 |
| Term.equals | 10 | 6 | 5 | 7 |
| Term.register | 6 | 4 | 4 | 4 |
| Term.simplify | 7 | 4 | 4 | 4 |
| Term.toString | 14 | 2 | 9 | 10 |
| eatTrigonmetric | 9 | 6 | 3 | 7 |
| 平均 | 2.00 | 1.70 | 2.03 | 2.40 |
除去复杂度仍然很高的输入输出函数之外,我的化简部分由于情形过于复杂也被指出复杂度较高。此外,我的递归下降部分代码由于添加了大量throw语句用于判断WF,因此也被指出复杂度稍高。
在代码嗅探方面上,我的问题和上一次基本一致。
Bug分析
在自测阶段我在我个人的代码中发现了一定数量的Bug,而这些Bug通常都来自我的输入输出部分(在化简过程中去掉了不应该去掉的项等),在“比较面向对象”的代码段中几乎没有bug。而由于我的输入输出部分的圈复杂度是最高的,因此也印证了复杂度越高越容易产生bug这一结论。除此之外,还遇到过一个由于未使用不可变对象而产生的bug,不过我已经意识到了这一点,因而并未给我造成太大的麻烦。
在公测阶段,除了第二次作业我没能按时完成导致强测、互测崩盘以外,其他的阶段我都没有被hack到。
发现Bug策略与自动评测机的搭建
由于发现手动debug以及找出其他人的bug较为耗时,我使用python写了一台半自动评测机对自己以及别人的程序进行debug:
首先使用题目中所给的文法随机生成表达式,使用目标程序以及sympy同时求导,最后取点计算是否相等。
此外,我也会手动输入一些特殊的评测样例,并令自动评测机将这些样例一同进行测试。
我在自动评测机中加入了爆栈攻击,括号嵌套攻击等常见便捷样例;但由于我过分依赖自动评测机,导致其他同学的部分较为明显的bug我并没能发现,这是需要反省的。
我发现别人的bug包括无法解析+++1这种式子,依赖正则表达式解析而被重复语句爆栈,在应该输出0的地方输出空串,优化后项的正负错误,无法对不含x的表达式进行正常求导等。
心得体会
- 永远不要骄傲自大。我曾经以为自己写过小型的java工程,了解面向对象了就能写出高质量的代码了,就可以轻松OO了;事实证明,我对架构一无所知,设计模式一个都不会,甚至连第二次作业都没来得及完成。傲慢是永远的敌人,只有不断学习才能进步。
- 设计模式中的思想很有用。如果有时间的话,也同样推荐其他同学阅读一些有关OO编程思想的书籍,例如《设计模式之禅》等。至少应该了解一些如面向接口编程以及六大原则之类的思想。
- 最好在第一次作业时就确立好一个可信的架构来支持你的后两次作业。
- 自动评测机很重要,这次体验很好,下次还写(
- 不建议像我一样在周日下午的五点钟临时决定为了提升代码运行效率将指数从BigInteger类换成long然后去吃了一小时的饭。请先把中测过了再优化。
- java不需要向C一样锱铢必较的去抠效率。更何况数据范围很小;可以选择用完就扔的不变类以及禁忌的O(n^4)暴力(只要保证不触发GC stop-the-world就行 大概)
碎碎念:要不是因为某设计模式的分享我说不定就不会写不完第二次作业了…………

