Python基础-day15-内置函数

======================================

======================================
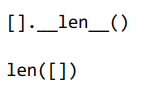
======================================

======================================

======================================

======================================

======================================

======================================

======================================
 、
、
======================================

======================================

======================================

hash(dict) # 错误,字典不可哈希,字典为可变数据类型
hash(set) # 错误,集合不可哈希,集合为可变数据类型
hash(list) # 报错,列表不可哈希,列表为可变数据类型
hash(str) # 正确,字符串可哈希,字符串为不可变数据类型
hash(int) # 正确,整数可哈希,整数为不可变数据类型
hash(tuple) # 正确,元祖可哈希,元祖为不可变数据类型
hash(bool) # 正确,布尔可哈希,布尔为不可变数据类型
======================================

默认的打印方式:
print(1, 2)
打印结果:
D:\tutorial\venv\Scripts\python.exe D:/tutorial/test1.py
1 2
Process finished with exit code 0
print(1, 2, sep='......', end='++++++')
打印结果:
D:\tutorial\venv\Scripts\python.exe D:/tutorial/test1.py
1......2++++++
Process finished with exit code 0
如果要打印到文件中,需要打开一个文件,获取文件标识符,然后将标识符传给print函数。
print(1, 2, file=f)
此时内容就输入到了文件中。
print(1, 2, flush=True)
因为print打印的内容会存放在内存中,某些时刻不会立即显示到屏幕或文件中,设置flush=True让内存中的内容立即刷新到屏幕和文件中。
【经测试,无效,文件中根本没有实时刷新,程序结束才刷新】
======================================
进度条
import time import sys for i in range(1, 101): progress = '-' * i + '>' sys.stdout.write('\r' + (progress + ' ' + str(i) + '%')) time.sleep(1) sys.stdout.flush()
======================================

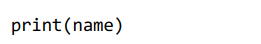
def func(par): print(par) return par ret = eval("func(a)", {"a": 1, "func": func}) print(ret)
打印:
1
1
def func(par): print(par) return par ret = exec("func(a)", {"a": 1, "func": func}) print(ret)
打印:
1
None(因为exec没有返回值)
def func(par): print(par) return par code_string = "func(1)" code = compile(code_string, 'test.log', 'eval') # test.log用于存放错误日志信息 ret = eval(code) print(ret)
打印:
1
1
def func(par): print(par) return par code_string = "func(1)" code = compile(code_string, 'test.log', 'exec') ret = exec(code) print(ret)
打印:
1
None
code_string = "name = input('请输入你的名字: ')" code = compile(code_string, 'test.log', 'single') # 如果是交互式地字符串语句,需要以single模式编译 eval(code)
或
exec(code) print(name)
======================================

======================================

======================================

======================================

print(round(3.14159, 2)) print(round(3.14159, 3)) print(round(4.14159, 4))
3.14
3.142
4.1416
print(sum([1, 2, 3], 10)) print(sum((1, 2, 3), 10)) print(sum({1, 2, 3}, 10))
16
16
16
print(min(1, 2, 3)) print(min(1, 2, 3, -1)) print(min(1, 2, 3, -1, key=abs)) # 最后的key可以指定其他排序算法,abs代表绝对值 print(min([1, 2, 3]))
li = []
print(min(li, default=0)) # 当可迭代对象li为空时,返回默认值0
# min接收两种参数,一种是可迭代参数,另一种就是2个或多个数。
print(max(1, 2, 3)) print(max(1, 2, 3, -1)) print(max(1, 2, 3, -1, key=abs)) print(max([1, 2, 3])) li = [] print(max(li, default=0))
======================================

======================================

这个地方稍微注意一下,一个是li.reverse(),一个是reversed(li)。

li = [1, 2, 3, 4, 5] li.reverse() print(li) li2 = [6, 7, 8, 9, 10] li3 = reversed(li2) print(li3)
[5, 4, 3, 2, 1]
<list_reverseiterator object at 0x03840930>
======================================

======================================

print(format('test')) print(format('test', '>20')) print(format('test111', '>20')) print(format('test111111', '>20'))
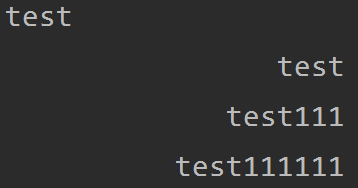
在个format在显示字符串的时候,做格式化操作比较方便,对齐显示。
======================================
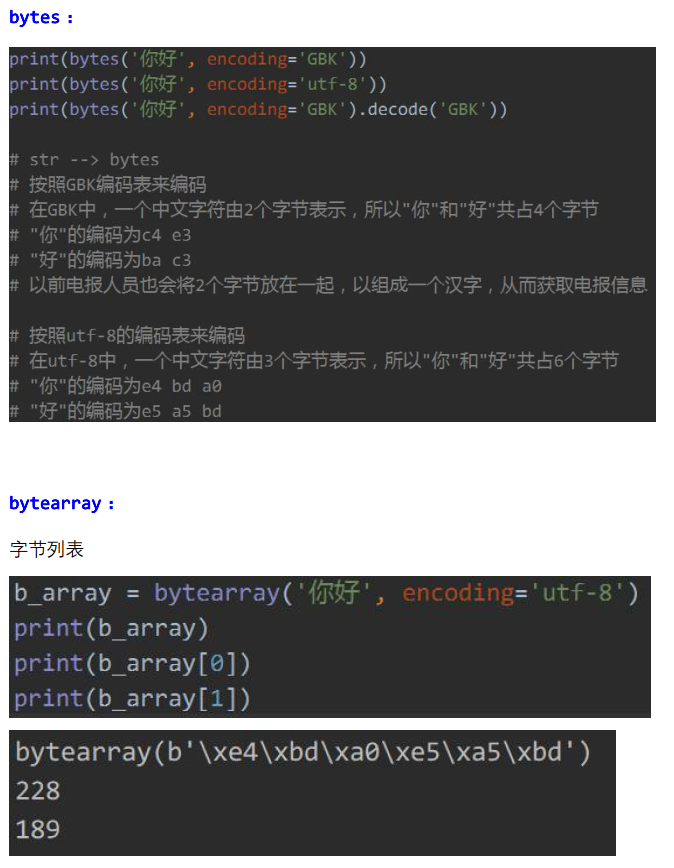
print(bytes('你好', encoding='GBK')) print(bytes('你好', encoding='utf-8')) print(bytes('你好', encoding='GBK').decode('GBK'))
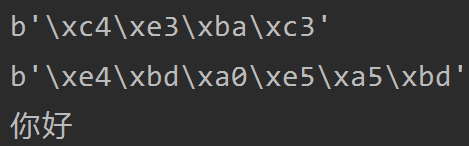
在网络传输中,就需要经常将字符串数据按照指定编码方式转换成对应的bytes数据类型,然后通过网络发送给其他位置。
所以要经常使用encode和decode。
b_array = bytearray('你好', encoding='utf-8') print(b_array) print(b_array[0]) print(b_array[1]) print(hex(228)) print(hex(189))
bytearray(b'\xe4\xbd\xa0\xe5\xa5\xbd')
228
189
0xe4
0xbd
说明在字节列表中,分别保存了十六进制的十进制数据,比如十六进制0xe4对应的十进制为228,十六进制0xbd对应的十进制为189。
所谓字节列表,好比将4个字节或6个字节放在字节列表中。
======================================
字符转unicode码
unicode码转字符

切记:只能转单个字符,不要转字符串。
在使用chr()时,里面的数字范围为:0 到 0x10ffff。
======================================

======================================

print(all([1, 2, 3])) print(all([1, '', 0])) print(all([[], 1, 2])) print(all([]))
True
False
False
True
print(any([1, 2, 3])) print(any([1, '', 0])) print(any([[], 1, 2])) print(any([]))
True
True
True
False
======================================
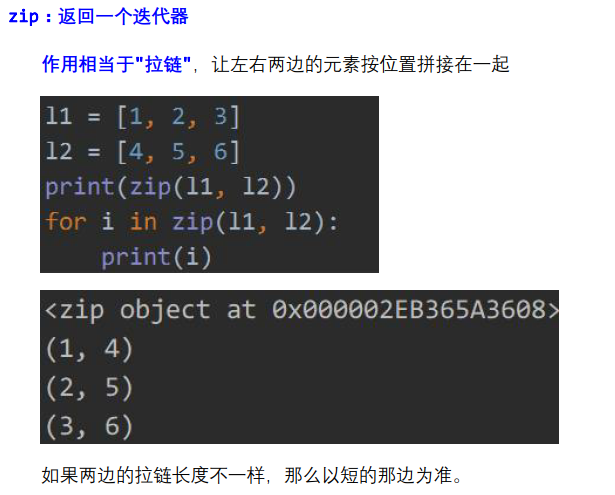

l1 = [1, 2, 3, 8, 9] l2 = [4, 5, 6, 7] zip_object = zip(l1, l2) print(zip_object, type(zip_object)) print(hasattr(zip_object, '__iter__')) print(hasattr(zip_object, '__next__')) # print(zip_object.__next__()) # print(zip_object.__next__()) # print(zip_object.__next__()) # print(zip_object.__next__()) for i in zip_object: print(i)
<zip object at 0x037053F0> <class 'zip'>
True
True
(1, 4)
(2, 5)
(3, 6)
(8, 7)
dic1 = {'name': 'yang', 'age': 20}
dic2 = {'name': 'wang', 'age': 20}
zip_obj = zip(dic1, dic2)
for i in zip_obj:
print(i)
('name', 'name')
('age', 'age')
只是key跟key进行连接。
l1 = [1, 2, 3] l2 = [4, 5, 6] l3 = [7, 8, 9] zip_object = zip(l1, l2, l3) print(zip_object, type(zip_object)) print(hasattr(zip_object, '__iter__')) print(hasattr(zip_object, '__next__')) for i in zip_object: print(i)
<zip object at 0x02C75418> <class 'zip'>
True
True
(1, 4, 7)
(2, 5, 8)
(3, 6, 9)
======================================
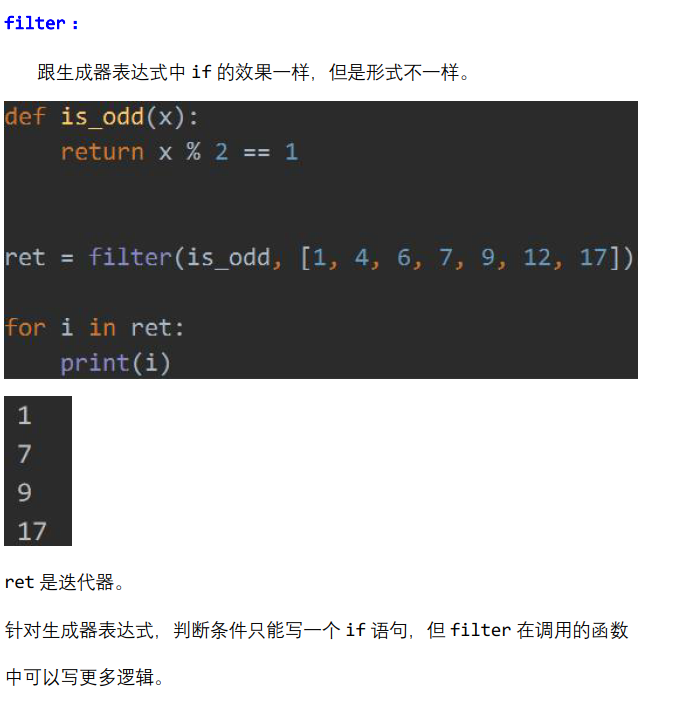

在生成器表达式中,if条件在后面,只有满足条件地数据才会记录到生成器对象中。
而这里的filter中,if的角色被过滤器中的漏斗替代了,所谓的漏斗就是一个函数,它来分辨牛鬼蛇神。是人,就保留,是鬼,就丢弃。
======================================
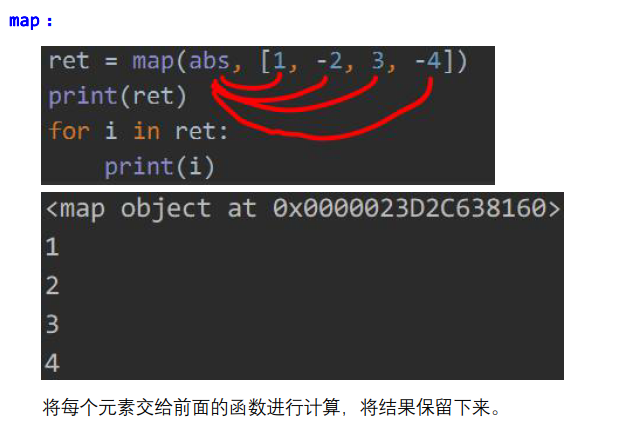
这个跟前面的filter有所不同,filter是将满足条件的数据保留下来,而map是将计算出来的结果保留下来。
def count_num(x): return len(x) ret = map(count_num, [(1, 2, 3), (4, 5), (6, 7)]) for i in ret: print(i)
3
2
2
map的参数:第一个是函数,第二个是可迭代对象。
======================================
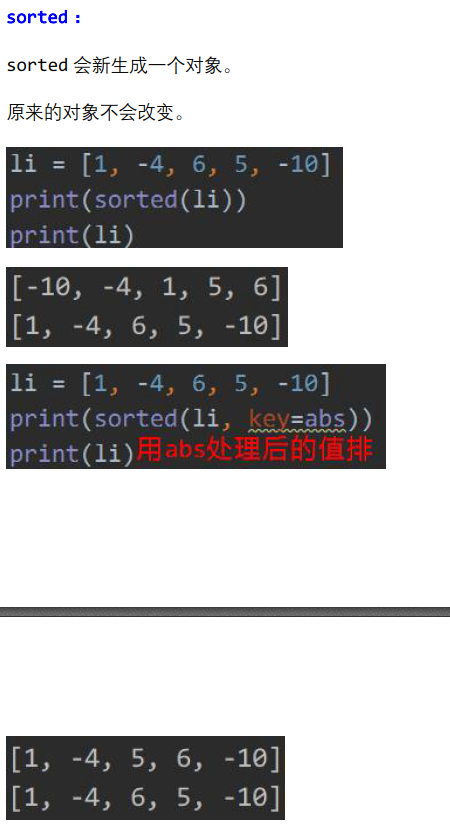
li1 = [1, -4, 6, 5, -10] li2 = sorted(li1) # 第一个参数 可迭代对象 # 第二个参数 排序方式(函数) # 第三个参数 反向 print(li1) print(li2)
打印:
[1, -4, 6, 5, -10]
[-10, -4, 1, 5, 6] # sorted默认按数值的大小进行排序
li1 = [1, -4, 6, 5, -10] li2 = sorted(li1, key=abs) print("排序前: ", li1) print("排序后: ", li2)
打印:
排序前: [1, -4, 6, 5, -10]
排序后: [1, -4, 5, 6, -10]
先将所有数据用abs处理后,用它们的结果进行排序,但实际返回的是它们的本尊。
li1 = [1, -4, 6, 5, -10] li2 = sorted(li1, key=abs, reverse=True) print("排序前: ", li1) print("排序后: ", li2)
打印:
排序前: [1, -4, 6, 5, -10]
排序后: [-10, 6, 5, -4, 1]
添加reverse参数后,就进行反向排序。
======================================

注意,上图中有一个错误,我写错了。如果有多个参数,就用逗号分开,而不是多个函数用逗号分开。
lambda arg1, arg2, ....., argn:expression
这就是匿名函数最全的表达式。
匿名函数不需要return来返回值,表达式本身结果就是返回值。
lambda返回的值,结合map,filter,reduce使用:
li = map(lambda n: n * n, [1, 2, 3, 4]) for i in li: print(i)
打印:
1
4
9
16
filter(lambda x:x%3==0,[1,2,3,4,5,6]) [3, 6]
无参匿名函数:
t = lambda : True # 分号前无任何参数 print(t()) # 等价于 def func(): return True
打印:
True
s = "this is\na\ttest" # 建此字符串按照正常情形输出 print(s) # 打印 'this is\na\ttest' print(s.split()) # split函数默认分割:空格,换行符,TAB #打印 ['this', 'is', 'a', 'test'] print(' '.join(s.split())) # 用join函数转一个列表为字符串 'this is a test' 等价于 (lambda s:' '.join(s.split()))("this is\na\ttest")
首先前面的lambda s:' '.join(s.split())是一个函数对象,它作为一个整体,其实表示的就是一个内存地址。
在内存地址后添加()就是调用这个函数。在()中添加参数就是传递参数给左边的函数对象。
匿名函数接收到参数后,就开始计算。
带参数的匿名函数:
lambda x: x**3 # 一个参数 lambda x,y,z: x+y+z # 多个参数 lambda x,y=3: x*y # 允许参数存在默认值
a = lambda *z: z # *z返回的是一个元祖 a('Testing1','Testing2') ('Testing1', 'Testing2')
注意:之类的*z好比*args,z相当于是一个空元祖,所有的位置参数会被放置到该元祖中。
故最后的z就是我们传递进去的2个参数。
c = lambda **arg: arg # arg返回的是一个字典 c() {}
同理,**arg相当于是**kwargs。kwargs是一个空字典,所有的关键字参数会被放置到该字典中。
lambda本身作为返回值被返回:
def increment(n): return lambda x: x+n f = increment(4) f(2) # 打印 6
和列表结合,和字典结合,和Tkinter结合,和map结合
有了基础,就能建高楼大厦,成不成,试一下即可。
lambda和sorted联合使用
# 按death名单里面,按年龄来排序 # 匿名函数的值返回给key,进行排序 death = [('James', 32), ('Alies', 20), ('Wendy', 25)] sorted(death, key=lambda age: age[1]) # 按照第二个元素,索引为1排序
[('Alies', 20), ('Wendy', 25), ('James', 32)]
首先看key,它的作用是决定按照什么来排序。看匿名函数的逻辑,它是获取年龄。
最终获取的是32, 20, 25,然后进行排序,20, 25, 32,最终的结果就是上面的结果。
a = [1,2,3,4] b = [5,6,7,8] map(lambda x,y:x+y, a,b) # 在a, b序列中各取一个值,然后进行计算,如果有多个序列,以最短的那个为准 [6, 8, 10, 12]
======================================
python2 中是reduce
python3 中是functools.reduce
from functools import reduce print(reduce(lambda x, y: x + y, [1, 2, 3, 4])) # 打印10 print(reduce(lambda x, y: x + y, [1, 2, 3, 4], 20)) # 打印30 print(reduce(lambda x, y: x + y, [], 20)) # 打印20(特别注意,如果序列为空,必须要传初始值,否则报错)
reduce的函数全称是:
reduce(function, sequence, initial)
最后的inital可传可不传。
reduce的作用就是计算sequence中的所有值的和。从前往后取,每次取两个值,直到所有值都被加起来。
======================================

======================================

======================================

import sys sys.setrecursionlimit(1500) # 修改递归调用深度 def recursion(n): # 定义递归函数 print(n) # 打印n recursion(n+1) # 在函数的运行种调用递归 recursion(1) # 调用函数 # n = 1 print(1) recursion(2) # n = 2 print(2) recursion(3) # n = 3 print(3) recursion(4) # ...
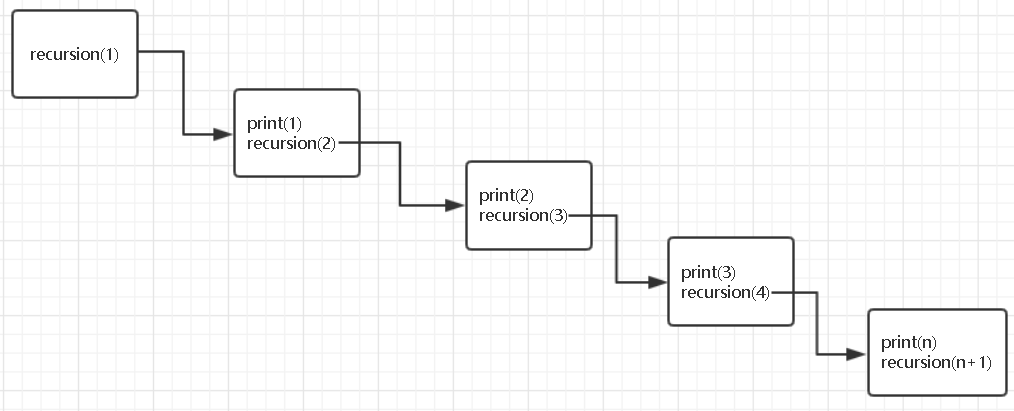
修改递归调用深度:
import sys sys.setrecursionlimit(1500) # 修改递归调用深度
======================================


======================================


 浙公网安备 33010602011771号
浙公网安备 33010602011771号