

24级数应二班课堂作业3
2024090106陈嘉怡音频的播放
2024010077 马京兴 在python中打开页面图片并提取颜色RGB数
import tkinter as tk
from tkinter.colorchooser import askcolor
root = tk.Tk()
root.config(bg='red')
rgb = askcolor(color=root.cget('bg'))[0]
if rgb:
print(f"页面颜色的 RGB 值: {tuple(int(x) for x in rgb)}")
root.mainloop()
2024010059李若楠 扫描文件夹中的文件
import os
file_list = [f for f in os.listdir('.') if os.path.isfile(f)] # 扫描当前文件夹,筛选出文件并加入列表
print(file_list) # 输出文件名列表

2024030259 储妙 文本中提取公司信息
text = "这是一段包含公司信息的文字,公司名称:ABC有限公司,公司地址:上海市浦东新区世纪大道100号,公司邮箱:abc@example.com,公司电话号码:13992975581"
# 定义正则表达式
company_name_pattern = r"公司名称:([^,。]+)"
company_address_pattern = r"公司地址:([^,。]+)"
company_email_pattern = r"公司邮箱:([\w.-]+@[\w.-]+\.\w+)"
company_phone_pattern = r"公司电话号码:(1[3-9]\d{9}|0\d{2,3}-\d{7,8})"
# 提取公司名称
company_name_match = re.search(company_name_pattern, text)
company_name = company_name_match.group(1).strip() if company_name_match else ""
# 提取公司地址
company_address_match = re.search(company_address_pattern, text)
company_address = company_address_match.group(1).strip() if company_address_match else ""
# 提取公司邮箱
company_email_match = re.search(company_email_pattern, text)
company_email = company_email_match.group(1).strip() if company_email_match else ""
# 提取公司电话号码
company_phone_match = re.search(company_phone_pattern, text)
company_phone = company_phone_match.group(1).strip() if company_phone_match else ""
# 将提取的信息存储在字典中
result = {
"公司名称": company_name,
"公司地址": company_address,
"公司邮箱": company_email,
"公司电话号码": company_phone
}
print(result)

2024010048 景勇强 群聊中聊天发言排行
from collections import defaultdict
def count_messages(chat_records):
"""
统计群聊中每个成员的发言次数
参数:
chat_records: 聊天记录列表,每条记录格式为 (发言人, 发言内容)
返回:
一个字典,键是发言人,值是发言次数
"""
# 使用defaultdict来初始化计数器,默认值为0
count_dict = defaultdict(int)
for speaker, _ in chat_records:
count_dict[speaker] += 1
return count_dict
def sort_speakers(count_dict):
"""
对发言人按发言次数进行排序
参数:
count_dict: 统计好的发言次数字典
返回:
按发言次数降序排列的(发言人, 次数)元组列表
"""
# 使用sorted函数排序,key指定按次数排序,reverse=True表示降序
return sorted(count_dict.items(), key=lambda x: x[1], reverse=True)
def print_ranking(sorted_list, top_n=10):
"""
打印发言排行榜
参数:
sorted_list: 排序后的(发言人, 次数)列表
top_n: 显示前多少名,默认为10
"""
print("=== 群聊发言次数排行榜 ===")
for rank, (speaker, count) in enumerate(sorted_list[:top_n], 1):
print(f"第{rank}名: {speaker} - 发言{count}次")
# 示例用法
if __name__ == "__main__":
# 模拟聊天记录数据 - 格式: (发言人, 发言内容)
sample_chat = [
("张三", "大家好!"),
("李四", "今天天气不错"),
("王五", "有人打游戏吗?"),
("张三", "我来了"),
("赵六", "晚上聚餐吧"),
("李四", "我同意"),
("张三", "去哪里吃?"),
("王五", "我知道一家不错的餐厅"),
("张三", "发个位置"),
("李四", "我也要"),
("钱七", "新人报到"),
("张三", "欢迎新人"),
]
# 统计发言次数
counts = count_messages(sample_chat)
# 排序
ranked = sort_speakers(counts)
# 打印排行榜
print_ranking(ranked)
2024010072刘芝池输出学生列表成绩列表
# 学生列表
students = ["张三", "李四", "王五", "赵六"]
# 成绩列表,每个元素是一个包含学生姓名和成绩的列表
scores = [["张三", 88], ["李四", 92], ["孙七", 77], ["赵六", 85]]
# 筛选成绩列表中在学生列表里有人名的记录
new_scores = [score for score in scores if score[0] in students]
# 打印处理后的成绩列表
print(new_scores)
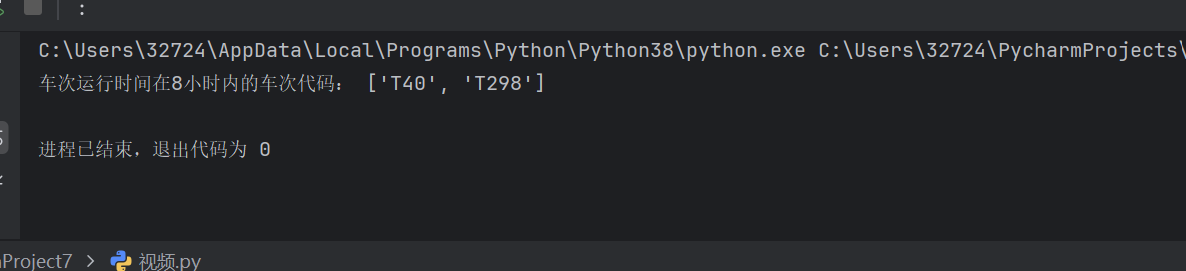
2024010045 计旭升 统计车次运行时间在8小时内
from datetime import datetime
trains = {
"T40": ("长春-北京", "00:12", "12:20"),
"T298": ("长春-北京", "00:06", "10:50"),
"Z158": ("长春-北京", "12:48", "21:06"),
"Z216": ("长春-北京", "00:55", "08:18")
}
result = []
for train_num, info in trains.items():
start_time = datetime.strptime(info[1], '%H:%M')
end_time = datetime.strptime(info[2], '%H:%M')
duration = (end_time - start_time).total_seconds() // 3600
if duration > 8:
result.append(train_num)
print("车次运行时间在8小时内的车次代码:", result)
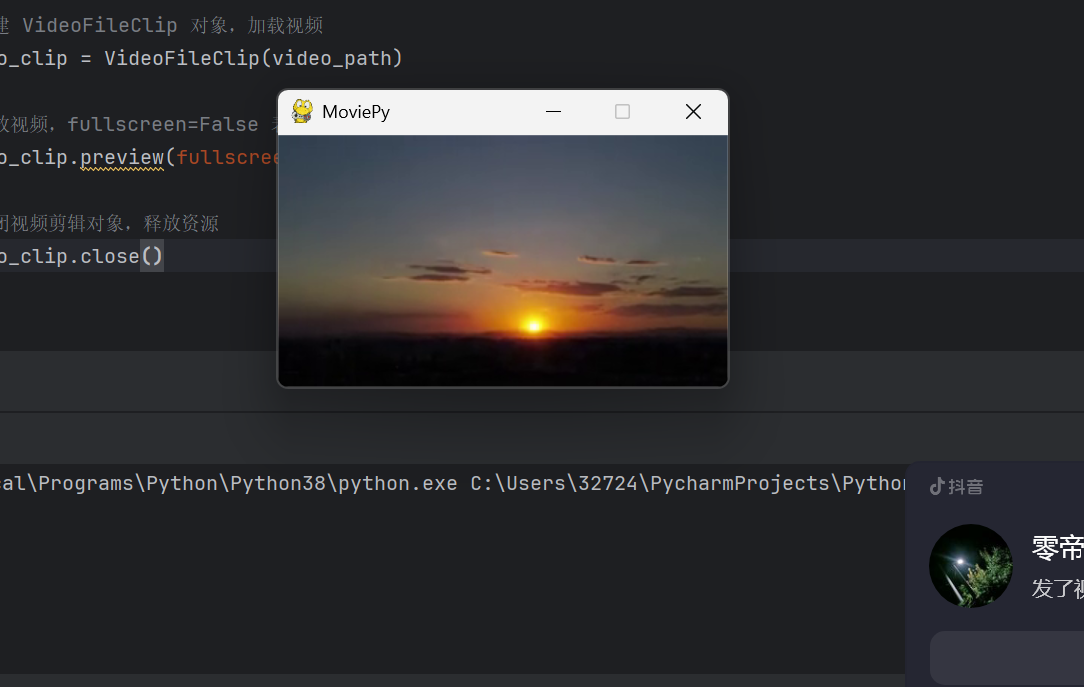
2024010061 李升 用第三方库生成视频窗口并播放
from moviepy.editor import VideoFileClip
# 替换为你实际的视频文件路径
video_path = "ABC.mp4"
# 创建 VideoFileClip 对象,加载视频
video_clip = VideoFileClip(video_path)
# 播放视频,fullscreen=False 表示不以全屏模式播放
video_clip.preview(fullscreen=False)
# 关闭视频剪辑对象,释放资源
video_clip.close()
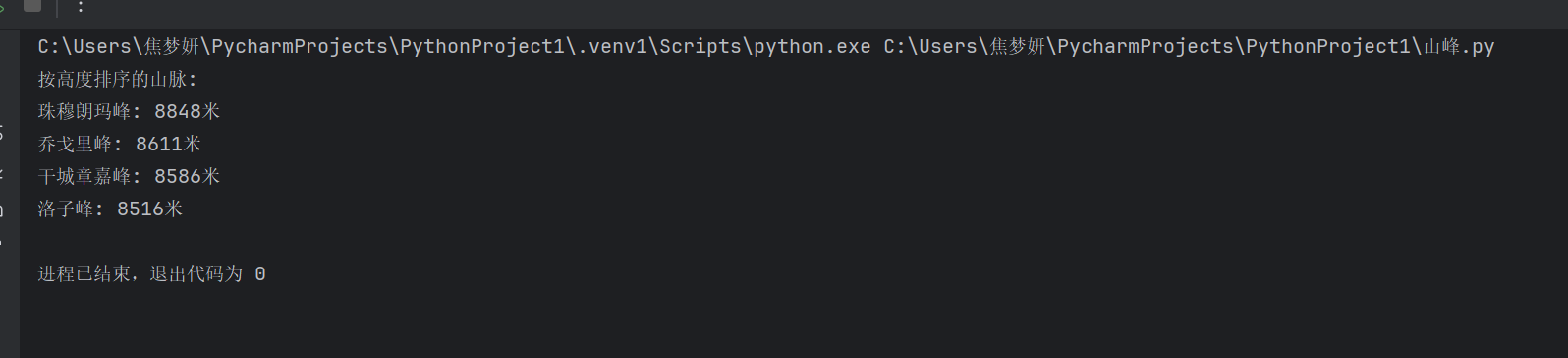
2024010046焦梦妍 将数据插入到合适的位置
# 已有的山脉数据(名称和高度)
mountains = [('珠穆朗玛峰', 8848), ('乔戈里峰', 8611), ('干城章嘉峰', 8586)]
# 新要插入的山脉
new_mountain = ('洛子峰', 8516)
# 找到插入位置
for i in range(len(mountains)):
if new_mountain[1] > mountains[i][1]: # 比较高度
mountains.insert(i, new_mountain) # 插入到合适位置
break
else:
mountains.append(new_mountain) # 如果最小,加到最后
# 打印结果
print("按高度排序的山脉:")
for name, height in mountains:
print(f"{name}: {height}米")
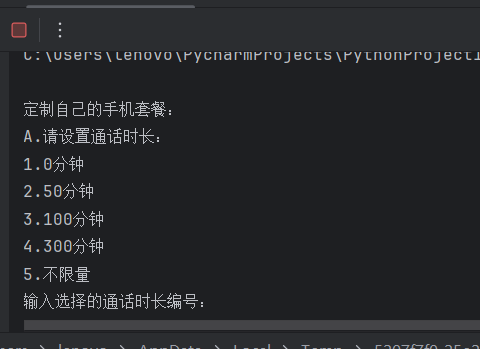
2024010047 金佳仪 统计套餐个数
from collections import Counter
call = ["0分钟", "50分钟", "100分钟", "300分钟", "不限量"]
liu = ["0M", "500M", "1G", "5G", "不限量"]
message = ["0条", "50条", "100条"]
all_combinations = []
for _ in range(3): # 假设有3个用户进行选择
print("\n定制自己的手机套餐:")
print("A.请设置通话时长:")
for i, j in enumerate(call):
print(f"{i + 1}.{j}")
A = int(input("输入选择的通话时长编号:"))
print("B.请设置流量包:")
for i, j in enumerate(liu):
print(f"{i + 1}.{j}")
B = int(input("输入选择的流量包编号:"))
print("C.请设置短信条数:")
for i, j in enumerate(message):
print(f"{i + 1}.{j}")
C = int(input("输入选择的短信条数编号:"))
combination = f"通话:{call[A - 1]}, 流量:{liu[B - 1]}, 短信:{message[C - 1]}"
all_combinations.append(combination)
print(f"\n您的手机套餐定制成功:免费通话时长为{call[A - 1]}/月,流量为{liu[B - 1]}/月,短信条数{message[C - 1]}/月")
package_counts = Counter(all_combinations)
print("\n套餐统计结果:")
for combo, count in package_counts.items():
print(f"{combo}: {count}次")
李楠 2024010057 输入城市,按城市人口排序
from operator import itemgetter#导入itemgetter函数,用于后续排序
# 创建一个空字典来存储城市和人口信息
cities = {}
while True:
# 输入城市名
city = input("请输入城市名(输入 'q' 退出):")
if city == 'q':
break
# 输入城市人口
population = int(input(f"请输入 {city} 的人口数量:"))
#将城市名和人口信息存入字典cities
cities[city] = {'population': population}
# 使用sorted函数按照人口数量对城市进行降序排序
sorted_cities = sorted(cities.items(), key=lambda x: itemgetter('population')(x[1]), reverse=True)
# 输出排序后的结果
for city, info in sorted_cities:
print(f'{city}: {info["population"]}')

2024010050 康佳莹 股票涨势
data = [
("中体产业", 8.31, 2.59),
("乐普生物 - B", 4.160, - 1.65),
("上证指数", 3356.17, 0.23),
("中概股", 600.19, 0.63),
("普路通", 7.07, - 0.42),
("晨曦航空", 9.83, - 1.90)]
def find_rising_stocks(data):
result = []
for item in data:
name, _, change = item
if change > 0:
result.append(name)
if len(result) >= 10:
break
return result
rising_stocks = find_rising_stocks(data)
print("前一天涨且今天还涨的股票:", rising_stocks)

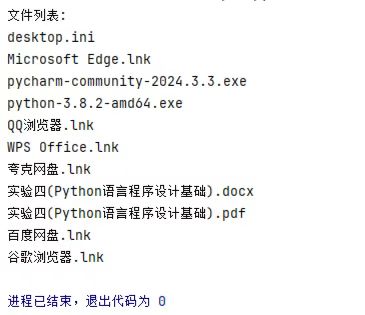
2024010064 刘纯怡 扫描桌面打印文件名称
import os
def list_files_in_directory(directory):
items = os.listdir(directory)
files = [item for item in items if os.path.isfile(os.path.join(directory, item))]
return files
directory_path = 'C:/Users/Administrator/Desktop/'
file_list = list_files_in_directory(directory_path)
print("文件列表:")
for file in file_list:
print(file)
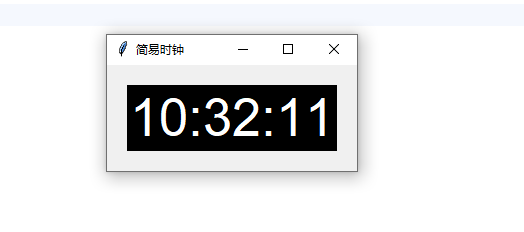
2024010065 刘欢幸 简易时钟
import tkinter as tk
import time
root = tk.Tk()
root.title("简易时钟")
time_label = tk.Label(root, font=('Arial', 40), bg='black', fg='white')
time_label.pack(padx=20, pady=20)
def update_time():
current_time = time.strftime('%H:%M:%S')
time_label.config(text=current_time)
root.after(1000, update_time)
update_time()
root.mainloop()
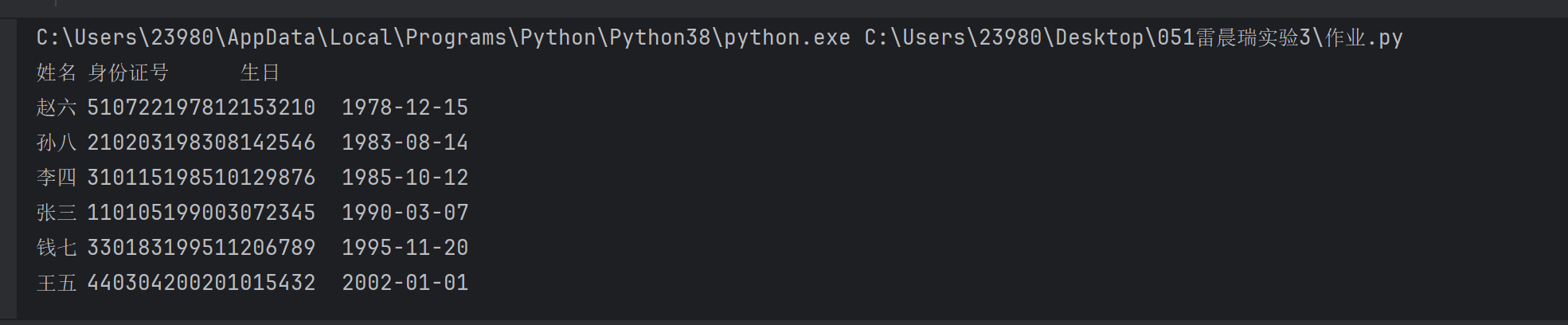
2024010051 雷晨瑞 将生日进行排序
group1 = [
["张三", "110105199003072345"],
["李四", "310115198510129876"],
["王五", "440304200201015432"]
]
group2 = [
["赵六", "510722197812153210"],
["钱七", "330183199511206789"],
["孙八", "210203198308142546"]
]
all_people = group1 + group2
all_people.sort(key=lambda p: p[1][6:14])
print("姓名\t身份证号\t\t生日")
for person in all_people:
name, id_card = person
birthday = id_card[6:14]
print(f"{name}\t{id_card}\t{birthday[:4]}-{birthday[4:6]}-{birthday[6:8]}")
2024010054 李嘉靖 找出属于哪一级别
# 定义层级结构字典 (名称: 层级)
hierarchy = {
"安康学院": 1,
"数统学院": 2,
"教育学院": 2,
"数学与应用数学专业": 3,
"统计专业": 3,
"学前教育专业": 3,
"小学教育专业": 3
}
def check_level():
# 获取用户输入并去除首尾空格
user_input = input("请输入学院/专业名称:").strip()
# 查找层级
level = hierarchy.get(user_input, None)
if level:
print(f"「{user_input}」属于第{level}级")
else:
print(f"「{user_input}」不在定义的三级结构中")
# 测试示例
if __name__ == "__main__":
check_level()

2024010055 李金俞 排序距离长短
# 定义各点之间的距离
distances = {
('A', 'B'): 6,
('B', 'C'): 4,
('B', 'D'): 8,
('C', 'D'): 5,
('A', 'C'): 3
}
# 找出从A到D的所有可能路线并计算距离
def find_all_routes():
routes = []
# 路线1: A -> B -> D
route1 = ['A', 'B', 'D']
distance1 = distances[('A', 'B')] + distances[('B', 'D')]
routes.append((route1, distance1))
# 路线2: A -> C -> D
route2 = ['A', 'C', 'D']
distance2 = distances[('A', 'C')] + distances[('C', 'D')]
routes.append((route2, distance2))
# 路线3: A -> B -> C -> D
route3 = ['A', 'B', 'C', 'D']
distance3 = distances[('A', 'B')] + distances[('B', 'C')] + distances[('C', 'D')]
routes.append((route3, distance3))
return routes
# 找出所有路线并按距离排序
all_routes = find_all_routes()
sorted_routes = sorted(all_routes, key=lambda x: x[1])
# 输出结果
for route, distance in sorted_routes:
route_str = ' -> '.join(route)
print(f"路线: {route_str}, 距离: {distance}")

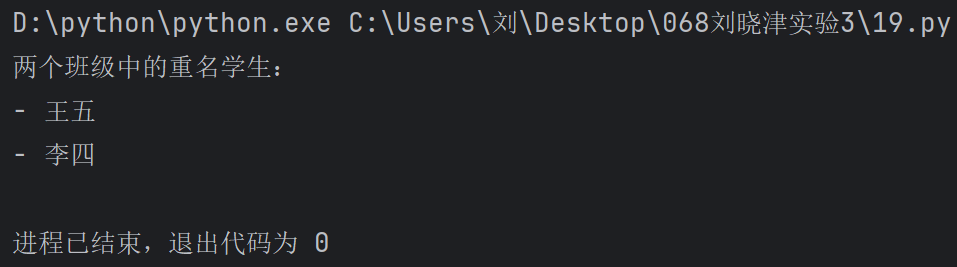
2024010068 刘晓津 找出重复的名字
# 班级名单(可替换为实际数据)
class1 = ["张三", "李四", "王五", "赵六", "周七"]
class2 = ["李四", "陈八", "王五", "吴九", "郑十"]
# 转换为集合并查找交集
common_names = set(class1) & set(class2)
# 输出结果
print("两个班级中的重名学生:")
for name in common_names:
print(f"- {name}")
2024010086孙景涵 分支和循环代码分类
code=""""
for i in range(10):
if i > 5:
print(i)
while True:
x = 10
if x == 10:
break
elif x > 10:
pass
else:
print
"""
loop_count = 0
branch_count = 0
lines = code.splitlines()
for line in lines:
line = line.strip()
if line.startswith(("for ", "while ")):
loop_count += 1
elif line.startswith(("if ", "elif ", "else")):
branch_count += 1
print(f"循环代码个数: {loop_count}")
print(f"分支代码个数: {branch_count}")

2024010075鲁美宏绘制五角星
import turtle
# 创建画笔对象
star = turtle.Turtle()
# 绘制五角星
for _ in range(5):
star.forward(100)
star.right(144)
# 隐藏画笔
star.hideturtle()
# 保持图形窗口显示
turtle.done()
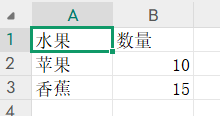
2024010076马凤凤访问Excel表格
from openpyxl import Workbook, load_workbook
# 创建Excel并写入数据
wb = Workbook()
ws = wb.active
ws['A1'] = '水果'
ws['B1'] = '数量'
ws['A2'] = '苹果'
ws['B2'] = 10
ws['A3'] = '香蕉'
ws['B3'] = 15
wb.save('simple_example.xlsx')
# 读取Excel数据
wb_read = load_workbook('simple_example.xlsx')
ws_read = wb_read.active
list = []
for row in ws_read.iter_rows(values_only=True):
list.append(row)
#print(list)
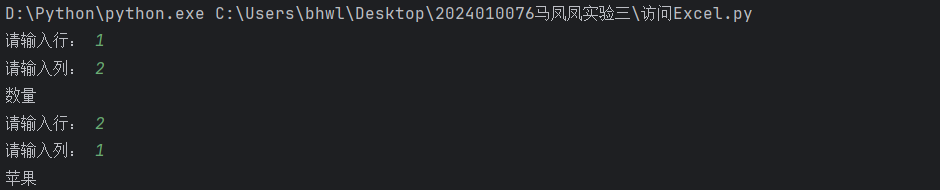
while(True):
hang = input("请输入行: ")
lie = input("请输入列: ")
print(list[int(hang)-1][int(lie)-1])
2024010081 孟佳茵 播放一个视频
import cv2
video_path = ('E:\WeChat_20250419215856.mp4')
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
cv2.imshow('Video Player', frame)
# 每帧显示25毫秒,按下 'q' 键退出
if cv2.waitKey(25) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
2024010080 毛蕊婷 马鞍面
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 创建网格数据
x = np.linspace(-5, 5, 100)
y = np.linspace(-5, 5, 100)
X, Y = np.meshgrid(x, y)
# 定义马鞍面函数
Z = X ** 2 - Y ** 2
# 创建图形和3D轴对象
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# 绘制马鞍面
ax.plot_surface(X, Y, Z, cmap='viridis')
# 设置坐标轴标签
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
# 显示图形
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号