吴恩达第2课第2周随笔
2-2-1:mini-batch初步
mini-batch,将巨大的数据集的样本,不再做一个向量里做运算了,而是分割成T个小样本的合集。
特点:一次只处理m/T个样本,执行深度学习过程
优点:当遍历完整个数据集时,执行了T次梯度下降,加快了学习过程。
并不再是人为的去规定遍历多少次数据集了,而是根据条件去选择合适时机终止(如损失函数或者达到一定的值,用while语句确定)
一代(one epoch),遍历一次训练集数据
T的选取:T一般是区间64-512的2的次方值,
T=m时,称为随机梯度下降法
2-2-2:指数加权平均
首先转换一下关系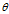 是真实数据值
是真实数据值 
然后是一些数据关系,当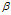 =0.9时,相当于10天的指数加权平均值
=0.9时,相当于10天的指数加权平均值
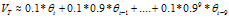
这10天能占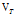 的2/3左右(1-1/e)的总量,虽然说应该需要加到
的2/3左右(1-1/e)的总量,虽然说应该需要加到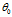 才对,但10天之后的所有量的加权平均占比不到1/3(1/e),忽略了
才对,但10天之后的所有量的加权平均占比不到1/3(1/e),忽略了
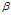 越大,
越大, 越准确
越准确
另外一个特点是使用指数加权平均时会使数据右移,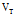 是前
是前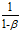 项的指数加权平均值,所以训练数据前
项的指数加权平均值,所以训练数据前 是没有的,造成数据右移,由于使用的事加权平均值会使得图形更加平滑
是没有的,造成数据右移,由于使用的事加权平均值会使得图形更加平滑
偏差修正应用的必要性:指数加权平均初始值会很低
使用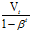 代替
代替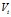 你会发现,如果随着t的增加,两者会越来越相等,只是在初期时,才会比较不同,这样有利于消除前期
你会发现,如果随着t的增加,两者会越来越相等,只是在初期时,才会比较不同,这样有利于消除前期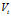 很小的影响。不过也有认为前期影响并不重要,看重整体,那直接使用
很小的影响。不过也有认为前期影响并不重要,看重整体,那直接使用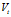 也没关系
也没关系
2-2-3:momentum梯度下降
方法:在求解梯度时,对梯度使用了加权平均算法
让下降的时候,更直接的偏向最小值(指数加权平均几个梯度后,更加的有利于只想最小值)

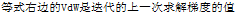
对于batch就是上一次迭代,对于mini-batch就是上一T的计算值
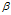 通常取0.9,加权平均10项,很好的避开开头值小的现象
通常取0.9,加权平均10项,很好的避开开头值小的现象
2-2-4 RMSProp
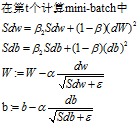
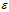 只是确保Sdw不会出现0的情况,所以给它加上一个极小值1e-8
只是确保Sdw不会出现0的情况,所以给它加上一个极小值1e-8
论除以 的影响;
的影响;
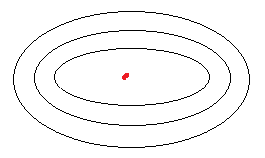
假设W是横轴方向,b是纵轴方向,椭圆线是等值线
在纵轴方向值是不是改变的特别快,即梯度特别大,db大,除以 它,即减少b方向的影响。
它,即减少b方向的影响。
在横轴方向,同理,db比较小,除以一个小值,会增加W方向的影响
概括起来,就是让W,b尽量趋向于同等,即将椭圆的等值线趋向于同心圆的等值线,利于任意初始点寻找最佳梯度方向
使用RMSProp时,还可以顺便扩大学习率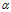 ,加快学习速度
,加快学习速度
2-2-5结合使用(Adam)

上面Adam算法的过程,结合了momentum和RMSProp,
更新参数时,梯度分子采用momentum,分母使用RMSProp,注意其超参数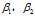 的不同
的不同
默认值设定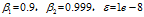 ,所以实际调参时,还是调
,所以实际调参时,还是调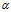
2-2-6 学习率的衰减
即在初始时,设置一个较大的学习率,然后随着迭代次数的增加,学习率减小,以便更有利的收敛在最优点
有很多种方式降低学习率,甚至是手动设置也行(不过此方法只适用于你的模型很小时)
eg1: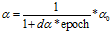 ,epoch是代,遍历数据集次数
,epoch是代,遍历数据集次数
2-2-7 局部最优点及鞍点
局部最优点一般是会在神经网络结构简单的情况下出现,当W很复杂时,对于J不可能每个方向都是上升的,但是会在局部平缓地区梯度下降很慢,不过Adam,这些算法,能指数加权平均几个梯度,有利于跨过这个平缓地区

 浙公网安备 33010602011771号
浙公网安备 33010602011771号