
[论文笔记] Efficient Construction of Approximate Call Graphs for JavaScript IDE Services | Correlation Tracking for Points-To Analysis of JavaScript
Efficient Construction of Approximate Call Graphs for JavaScript IDE Services
Introduction
文章提出了 a field-based flow analysis for constructing call graphs。Java 基于 class-hierarchy 的方法并不适用于 JavaScript:JavaScript 是动态类型的,使用基于 prototype 的面向对象机制而且具备“一等函数”的函数式性质。Flow-analysis 比如 Andersen 指针分析则不够 scalable。这篇文章的主要贡献在于:
-
Field-based analysis:
e.f会在分析过程中被记录为一个f结点,忽略e,也就是说不能分析f是哪个对象的字段 -
Only tracks function objects:只关注 callgraph 的构建
-
Ignores dynamic property access:忽略动态字段的访问(即使这会使得分析是 unsound 的)
Analysis Formulation
Flow graph 的构建基于 AST。
Intraprocedural Flow
过程内的 flow graph 有下面几种结点:

\(\text{Exp}(\pi)\) 是 \(\pi\) 位置的表达式的值结点
\(\text{Var}(\pi)\) 是 \(\pi\) 位置定义的变量结点
\(\text{Prop}(f)\) 是名称为 f 的字段结点,代码中的实现如下:
function propVertex(nd) {
var p;
if(nd.type === 'Identifier')
p = nd.name;
else if(nd.type === 'Literal')
p = nd.value + "";
else
throw new Error("invalid property vertex");
return propVertices.get(p, { type: 'PropertyVertex',
name: p,
attr: { pp: function() { return 'Prop(' + p + ')'; } } });
}
Literal 是用来处理数组访问的标记,所有的数组访问会被处理成名称为 i 的 Property 结点。所有的 Property 结点被维护在 propVertices 下面。
\(\text{Fun}(\pi)\) 是 \(\pi\) 位置定义(包括函数表达式)的函数结点
定义一个函数 \(V\) 把位置为 \(\pi\) 的表达式 \(t^\pi\) 映射到 flow graph 上的结点:
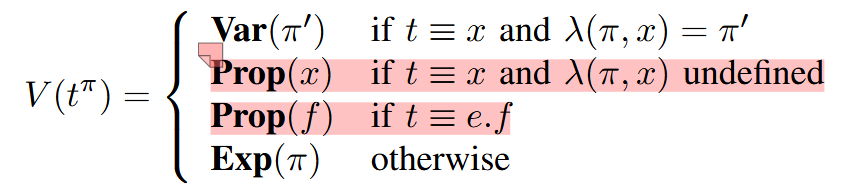
在代码中的实现对应函数 vertexFor:
/* Return the flow graph vertex corresponding to a given AST node. */
function vertexFor(nd) {
switch(nd.type) {
case 'Identifier':
// global variables use a property vertex, local variables a var vertex
var decl = nd.attr.scope.get(nd.name);
return decl && !decl.attr.scope.global ? varVertex(decl) : propVertex(nd);
case 'ThisExpression':
// 'this' is treated like a variable
var decl = nd.attr.scope.get('this');
return decl ? varVertex(decl) : exprVertex(nd);
case 'MemberExpression':
// ignore dynamic property accesses
if(!nd.computed)
return propVertex(nd.property);
// FALL THROUGH
default:
return exprVertex(nd);
}
}
再观察一下 varVertex 的实现可以发现代码把有些结点保存在 AST 上结点的属性下面(通过这种方式保证“唯一性”):
// variable vertices are cached at the variable declarations
function varVertex(nd) {
if(nd.type !== 'Identifier')
throw new Error("invalid variable vertex");
return nd.attr.var_vertex
|| (nd.attr.var_vertex = {
type: 'VarVertex',
node: 'nd',
attr: { pp: function() { return 'Var(' + nd.name + ', ' + astutil.ppPos(nd) + ')'; } }
});
}
Interprocedural Flow
为了处理过程间的流分析,添加下面几种结点和规则:


在具体实现中,还添加了 nativeVertex 来维护 JS 标准对象上的函数(比如 Array.indexOf),会有一条边从 nativeVertex 指向 PropVertex,同样地,只维护字段名称。
function addNativeFlowEdges(flow_graph) {
for(var native in nativeFlows) {
if(!nativeFlows.hasOwnProperty(native))
continue;
var target = nativeFlows[native];
flow_graph.addEdge(flowgraph.nativeVertex(native), flowgraph.propVertex({ type: 'Identifier',
name: target }));
}
return flow_graph;
}
nativeFlows = {
"Array": "Array",
"Array_isArray": "isArray",
"Array_prototype_some": "some",
"Array_prototype_indexOf": "indexOf",
"Array_prototype_lastIndexOf": "lastIndexOf"
}
文章使用了两种方法来具体地构造 callgraph:pessimistic 和 optimistic。在 pessimistic 方法中,只处理那些 one-shot calls 的函数对象的流动,比如:(function(...){...})(...)。之后,再按照上面提到过的 rules 处理过程内和过程间的流图。剩下的逃逸函数和逃逸调用点被使用 UNKNOWN 进行建模(连接到返回值或者参数)。算法描述如下:


optimistic 的方法要求 \((C, E, U)\) 从 \((\emptyset, \emptyset, \emptyset)\) 开始迭代,重复 pessimistic 的规则(不再只处理 one-shot call)直到达到不动点为止。
An Example


对于上面的代码,运行 pessimistic 的方法:

Evaluation
项目
在真实项目上运行了分析,框架有时是以压缩形式出现的,在实际运行中被替换成非压缩版本。使用 LOC,number of functions,number of calls 度量项目的大小。最后一行覆盖率是对项目插桩后动态调用图调用非框架函数的百分比,作者认为超过 60% 就算相当完整的。

Scalable
对于可扩展性,使用 UNIX 时间度量解析和分析的时间。Pessimistic 方法的效率最慢不到 9 秒,或许可以被使用到 IDE 中。

Precision
由于这里的方法是解决前人没有解决的问题,所以没办法使用别的静态分析方法当作一个 baseline,所以把结果和动态调用图进行比较。
设D为动态调用图中某个 callsite 对应的调用目标的集合,S为静态分析确定的目标集合,那么精确度(即所有目标中“真实”调用目标的百分比) = \(\frac{|D \cap S|}{|S|}\),召回率(即正确识别的真实目标的百分比) = \(\frac{|D \cap S|}{|D|}\)

不精确和精确度差异的来源:1. 两个对象的同名属性的函数;2. 回调函数
IDE
暂时不太关注

Summary and Threats to Validity
极端异常情况是对toString的调用,由于我们基于字段的方法,这些调用有超过100个被调用者。
大多数研究对象程序都使用了jQuery,只有两个程序使用了其他框架。
准确性测量是相对于不完整的动态调用图而言的,而不是相对于健全的静态调用图。因此,召回率应该被理解为一个上限(即,在更完整的调用图上,召回率可能会更低),而精确度是一个下限(即,精确度可能会更高)。鉴于将健全的调用图算法扩展到现实程序的困难性,动态调用图是我们目前可以用来比较的最佳数据。此外,动态调用图的相对较高的函数覆盖率表明它们能够代表整个程序。
Correlation Tracking for Points-To Analysis of JavaScript
Introduction
由于 JS 的动态特性,no field-sensitive 的方法会造成很大的不精确性,但是 field-sensitive 的方法会带来极大的时间开销,同时也无法很好的处理动态字段访问的问题(访问的字段必须在运行时计算出来),比如对于下面这个例子:

但是,注意到在一个读-写对中,读和写有时会操作不同对象上的同名字段,称为 an obvious correlation,比如 x[p] = y[p](或者说 t = x[p]; y[p] = t;)。这篇文章提出的方法就是捕获这些在相同属性上操作的读-写对,然后对于变量 p 的所有可能的取值分别的进行约束图的构建(基于 Andersen)。在 WALA 上作为一个扩展实现了这个方法。这篇文章的方法不关注 eval 或者其他的动态生成的代码,因此同样是 unsound 的。
Field-Sensitive Points-To Analysis for JavaScript
一个 Field-sensitive 的 Andersen 指针分析如下:


前面几条规则和 Java 中的指针分析类似。v = x.nextProp() 被用来建模 JS 中的 for-in 结构,JS 代码经常使用 for-in 来遍历对象中的每个属性:
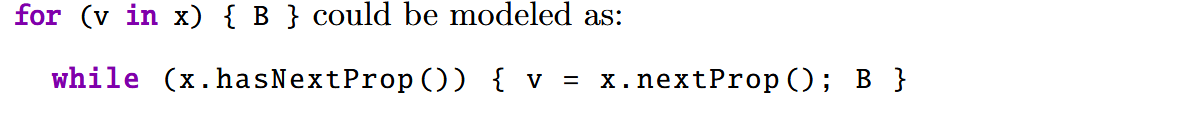
Andersen 指针分析可以被看作是约束图上的一个传递闭包(DTC)的求解问题,最差时间复杂度是 \(O(n^3)\),又因为 JS 允许向对象上动态的增减属性,因此对象上的属性的数量不能被简单的建模成常数级别,所以 \(O(n^4)\)(太粗略了,暂时还不太理解为什么可以被看作一个 DTC 的求解,可以参考 SAS 2009 的一篇文章:https://manu.sridharan.net/files/sas2009.pdf)
对于上面的指针分析,容易出现不精确的结果,比如对于下面这个代码:

按上面的规则,下面的推理是成立的:

原因来自于 prop 本质是在运行时被动态计算得到的,andersen 一方面没有动态分析,另一方面没有识别出 t = src[prop]; dest[prop] = t; 是对同名属性进行读写,不可能出现这种“交叉”的情况(能不能理解成 andersen 没有准确的捕捉所有的约束?)
Correlation Tracking
Example
Correlation tracking 主要分为两个步骤:1. 从 JS 程序中识别上面形式的读写对;2. 把对于读写对的操作提取成一个匿名函数,prop 作为函数形参,使用上下文敏感技术实现前面提到的“对于变量 p 的所有可能的取值分别的进行约束图的构建”。

Implementing Correlation Tracking
定义 read \(r\) 具备形式 o[p],write \(w\) 具备形式 o'[p'] = e,如果 p 和 p' 具备相同的取值,那么认为 \(r\) 和 \(w\) 是 correlated 的。在具体实现中,“具备相同的取值”被定义为 p 和 p' 指向同一个局部变量 \(p\),并且 \(p\) 没有在 \(r\) 和 \(w\) 之间被重复定义。有时 \(r\) 和 \(p\) 会被传入某个函数调用,我们做假设:所有的函数调用都会对对象上的字段做写操作,那么 write \(w\) 也可以认为具备形式 fun(r, p, ...)
Function Extraction
一旦我们识别出属性名 \(p\) 上的一次读取 \(r\) 和一次写入 \(w\) 之间的关联,就把包含这两个访问的代码片段提取到一个新函数中,并把 \(p\) 作为该函数的形参。如果不同关联对所对应的抽取区域相互重叠,就将它们合并并提取为一个函数,该函数接收所有这些相关属性名作为参数。某些代码结构需要特殊处理。
Context Sensitivity
若函数 \(f\) 在某个动态属性访问中使用形参 \(p\) 作为属性名,则对 \(f\) 进行上下文敏感分析,并为 \(p\) 的每一个具体取值创建一个独立上下文。该策略可视作 field-sensitive 的变体,只是把区分上下文的基准从 this 换成了属性名参数。
Evaluation
算法的实现基于 WALA。而且仍然存在不健全性:1. with;2. eval Function;3. 隐式类型转换;4. 标准库和 DOM 的模型不完整
在多个流行框架上评估了方法,对每个框架各收集了 6 个小型基准应用。多数框架大量使用反射(call apply),为了评估反射的影响,额外分别运行一次“建模 call/apply”和一次“不建模 call/apply”的分析,得到
Baseline−:WALA 标准分析,不支持call/applyBaseline+:WALA 标准分析,支持call/applyCorrelations−:启用相关性追踪,不支持call/applyCorrelations+:启用相关性追踪,支持call/apply



实验结果明确显示,相关性追踪显著提升了面向一系列 JavaScript 框架的字段敏感指向分析的可扩展性与精度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号