arch
arch
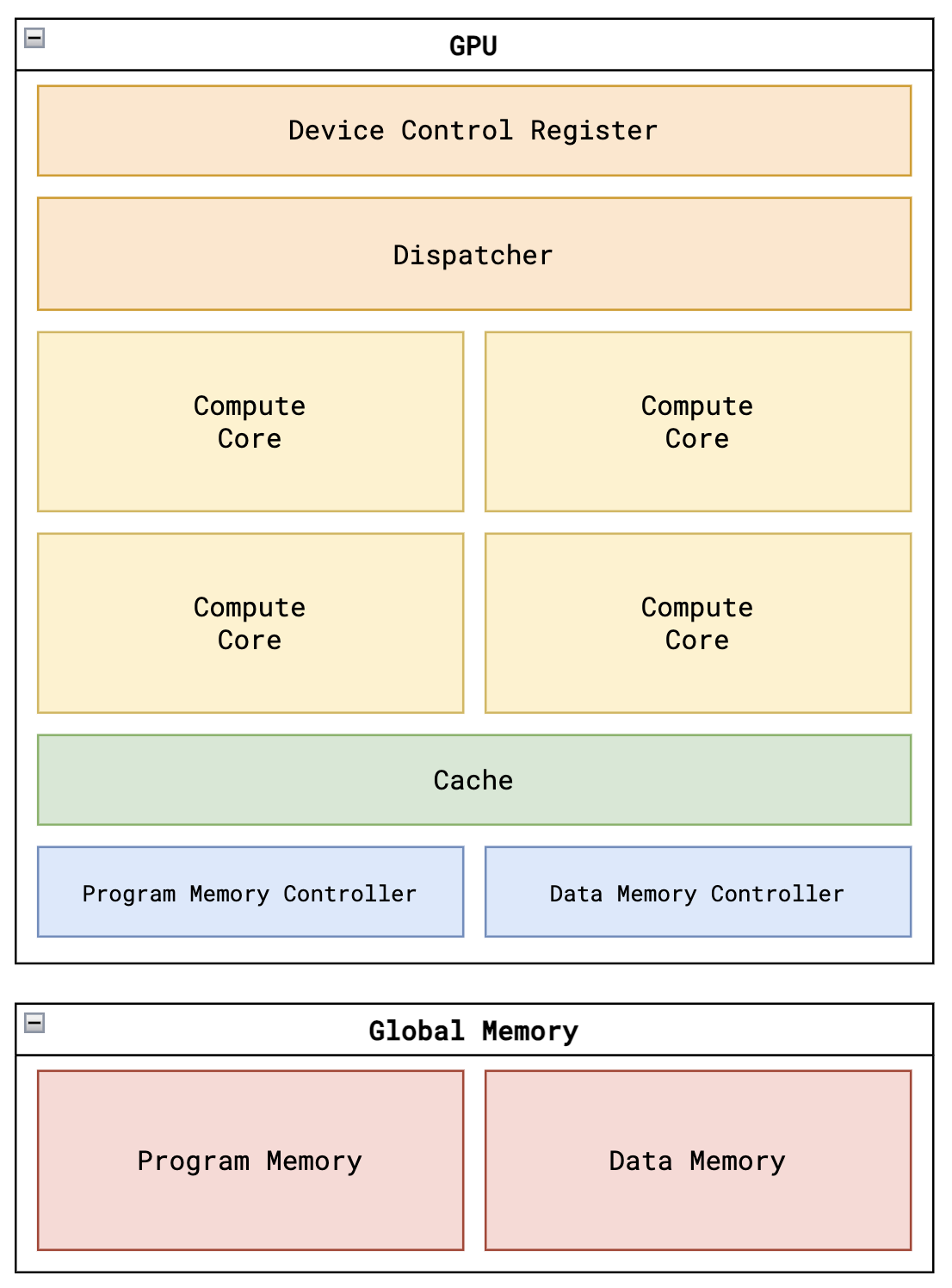
- Device Control Register : 用来接收外部的设置,打开多少个threads来跑当前的kernel。
- Dispatcher : 当一个kernel开始执行时,调度器会来确定会有多少个线程组来执行这个kernel。每个线程组叫block。每个线程组会被assign到一个可用的计算核,并根据该线程组应使能的线程数来enable 核内的线程。当启动某个计算核开始计算时,调度器会向该计算核传递所需的block id以及enable的线程数。当所有block被分配到相应的计算核并开始计算,调度器会不断轮询每个计算核是否完成了当前kernel的计算。当所有计算核或者block完成了计算。调度器会向GPU外部发送done的信号,表示当前kernel已经被执行完毕。
- Compute Core : 它是GPU最重要的计算单元。每个计算核一次只能支持一个线程组的运行。每个计算核会包含多个thread,当前代码实现了4个thread。每个thread会有自己独立的ALU(计算逻辑单元)、LSU(加载存储单元)、PC(代码指针)、Registers(寄存器)。
- Program Memory Controller : 它是读取外部代码内存内容的控制器。它支持多个channel访问外部代码内存和多个consumer。当前代码只支持了1个通道的外部代码访问以及2个consumer。代码地址线为8,代码数据位宽为16。根据某个consumer即计算核读取代码的请求(包含访问地址),该控制器会向外部代码内存发出内存读取的控制信号(包含内存地址以及读使能信号)。当外部内存准备好数据,它会向控制器发出数据ready的信号。接着控制器会把外部内存读取的内容转发给相应的consumer,等待consumer去读取。当consumer读取了内容,控制器会复位相应的控制信号,并处理下一个consumer的请求。
- Data Memory Controller : 它是读写外部数据内存内容的控制器。它支持多个channel访问外部数据内存和多个consumer。当前代码只支持了4个通道的外部数据访问以及8个consumer。根据某个consumer即计算核读取数据的请求(包含访问地址),该控制器会向外部数据内存发出内存读取的控制信号(包含内存地址以及读使能信号)。当外部内存准备好数据,它会向控制器发出数据ready的信号。接着控制器会把外部内存读取的内容转发给相应的consumer,等待consumer去读取。当consumer读取了内容,控制器会复位相应的控制信号,并处理下一个consumer的请求。控制器处理写数据的请求和上述读取过程类似。
Compute Core
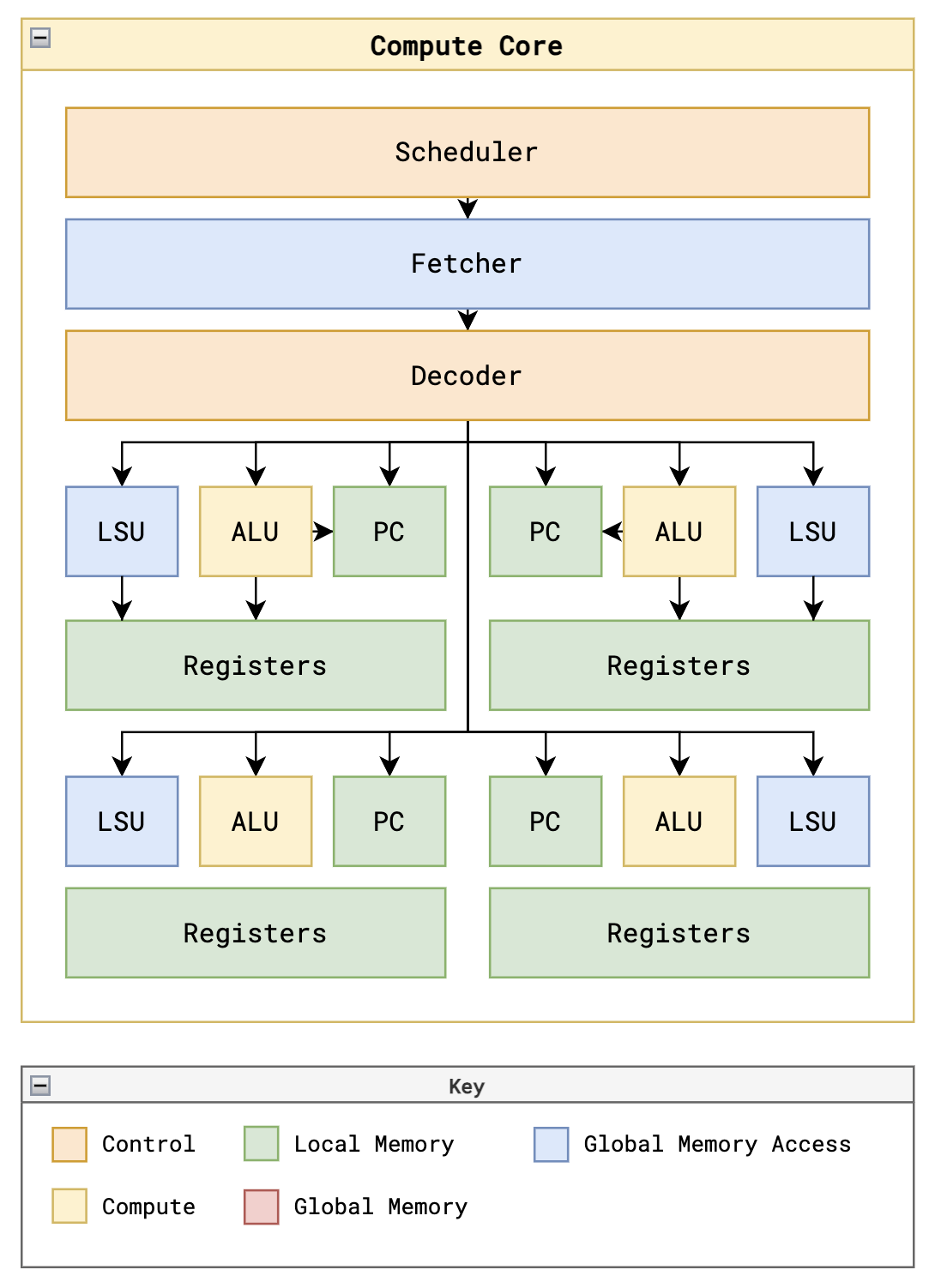
- Scheduler : 它管理着计算核内所有子线程的运行即一个线程组的运行。它通过管理计算核的状态来控制在不同状态下执行不同的任务。见下图,可以了解计算核不同的执行状态以及迁移的Flow。
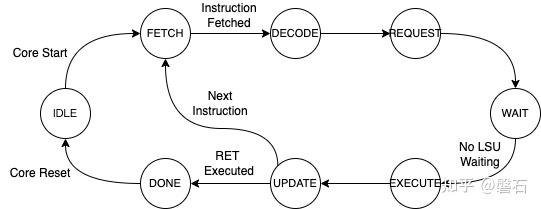
接下来详细解释下计算核的不同执行状态:
IDLE - 当计算核被复位后,会首先来到这个起始状态。它会一直保持,直到计算核的开始信号被使能。
FETCH - 当计算核的开始信号使能以后,计算核进入代码取指状态。在该状态下,代码取指单元会根据当前代码指针的值向GPU的代码内存控制器发出代码读取请求。接下来代码取指单元会等待代码内存控制器返回读取的内容。当要读取的指令获得以后,代码取指单元会通知计算核进DECODE状态。
DECODE - 计算核进入该状态,会停留一个cycle,然后下一个cycle会自动进入REQUEST状态。与此同时,代码解码器会在该状态下解析读取的指令并根据指令的含义向子线程的各执行单元发出相应的控制信号。
REQUEST - 计算核进入该状态后会停留一个cycle,然后下一个cycle会自动进入WAIT状态。在该状态下,每个子线程的LSU(加载存储单元)会根据代码解码器发出的控制信号判断当前指令是否需要对外部数据内存进行读写。如果是,它作为一个Consumer会向GPU的数据内存控制器发出读写外部数据内存的请求。
REQUEST - 计算核进入该状态后会停留一个cycle,然后下一个cycle会自动进入WAIT状态。在该状态下,每个子线程的LSU(加载存储单元)会根据代码解码器发出的控制信号判断当前指令是否需要对外部数据内存进行读写。如果是,它作为一个Consumer会向GPU的数据内存控制器发出读写外部数据内存的请求。
WAIT - 计算核进入该状态后会轮询每个子线程LSU的状态。如果某个子线程的LSU还在等待GPU数据内存控制器返回的结果,那么计算核会继续停留在WAIT状态并轮询每个子线程LSU的状态。当所有线程的LSU都得到了GPU数据内存控制器的响应,这时计算核才会进入EXECUTE状态。
EXECUTE - 计算核进入该状态后会停留一个cycle,然后下一个cycle会自动进入UPDATE状态。在该状态下,子线程的ALU会根据代码解码器发出的控制信号执行相应的计算,PC会更新下一条指令的地址。
UPDATE - 在该状态下,子线程会把ALU计算的结果或者LSU外部读取的数据或者指令的立即数存储到对应的寄存器。与此同时,计算核会判断当前指令是否是return指令。如果是,发出Done信号给GPU,表示该计算核已经执行完当前kernel;然后进入DONE状态。如果不是,计算核会把下一条指令地址设置成当前指令地址,计算核重新进入FETCH状态。
DONE - 计算核执行完当前kernel会一直保持在DONE状态直到该计算核被reset,然后再重新来到IDLE状态。
-
Fetcher : 它负责从外部代码内存读取当前指令。具体地,当计算核进入FETCH状态,代码取指单元会根据当前指令的地址向GPU的代码内存控制器发出代码读取请求。它会一直等待,直到GPU的代码内存控制器返回读取的内容。然后它会把读取的指令内容发给计算核用于指令解析,并等待下一次代码取指的窗口。
-
Decoder :它负责解析当前的指令并给子线程的各执行单元发出相应的控制信号。
-
子线程 :它由多个执行部件和寄存器组成,可以独立执行一个kernel。
ALU(计算逻辑单元):当计算核进入EXECUTE状态,它会根据代码解析器发出的控制信号执行对应的算数运算。它会处理ADD,SUB,MUL和DIV的算术指令。对于CMP指令,它会比较两个寄存器值的差别,把结果传送给PC单元并存储到它的NZP寄存器。
LSU(加载存储单元):当计算核进入REQUEST状态,它会根据代码解析器发出的控制信号判断当前指令是否是LDR指令还是STR指令。如果是LDR指令,它会根据LDR指令解析的读取地址向GPU数据内存控制器发出读外部数据内存的请求。如果是STR指令,它会根据STR指令解析的写数据和地址向GPU数据内存控制器发出写外部数据内存的请求。然后它会一直等待,直到GPU数据内存控制器返回结果。
PC(代码指针):它用来确定子线程下一条指令的地址。当当前指令是BRnzp指令,它会查看NZP寄存器的值也就是之前CMP指令的结果。如果满足给定的条件,它就会跳转到代码的其它行;如果不满足,那么下一条指令就是当前指令的下一条指令。
Registers(寄存器):每个子线程都有独立的一套寄存器,总共有16个寄存器。最后面3个寄存器预留用来存储block id,当前block需要的线程数,thread id。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号