CUDA编程模型 -- 统一编址

下面看一下GPU内存管理方式的演进。下面看一下GPU内存管理方式的演进。
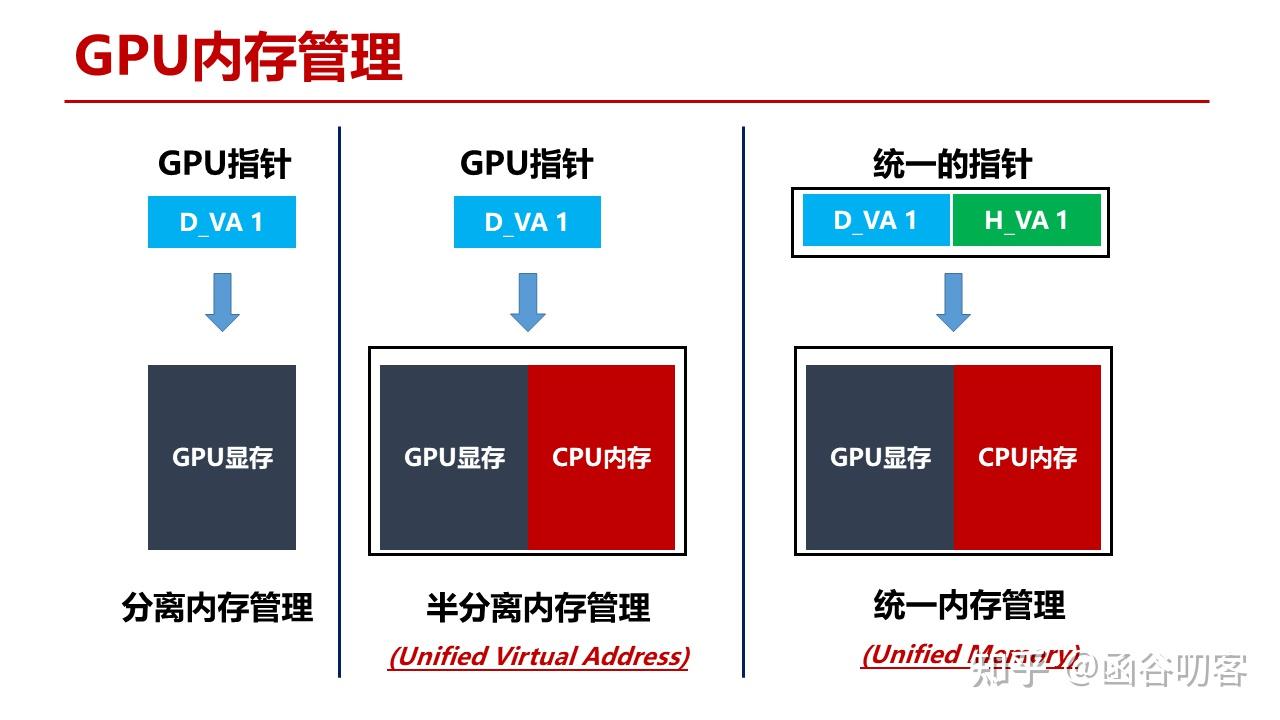
从用户编程的角度而言,在使用存储资源时看到的就是CPU指针和GPU指针。对CPU内存 + GPU内存的使用经历了三个阶段:
- 第一个阶段是分离内存管理,GPU上运行的kernel代码不能直接访问CPU内存,在Kernel代码执行之前和执行之后都需要进行显式的拷贝操作;
- 第二个阶段是半分离内存管理,Kernel代码能够直接用指针寻址到整个系统中的内存资源;
- 第三个阶段是统一内存管理,CPU还是GPU上的代码都可以使用指针直接访问到系统中的任意内存资源。
接下来我们分别来详细介绍一下三种不同内存管理方式的区别以及部分实现细节。
- 分离内存管理
- Page-locked Memory
- Mapped/Zero Copy Memory
- 半分离内存管理
- Unified Virtual Address(UVA)
- 统一内存管理
- Unified Memory(UM)
1. 分离内存管理
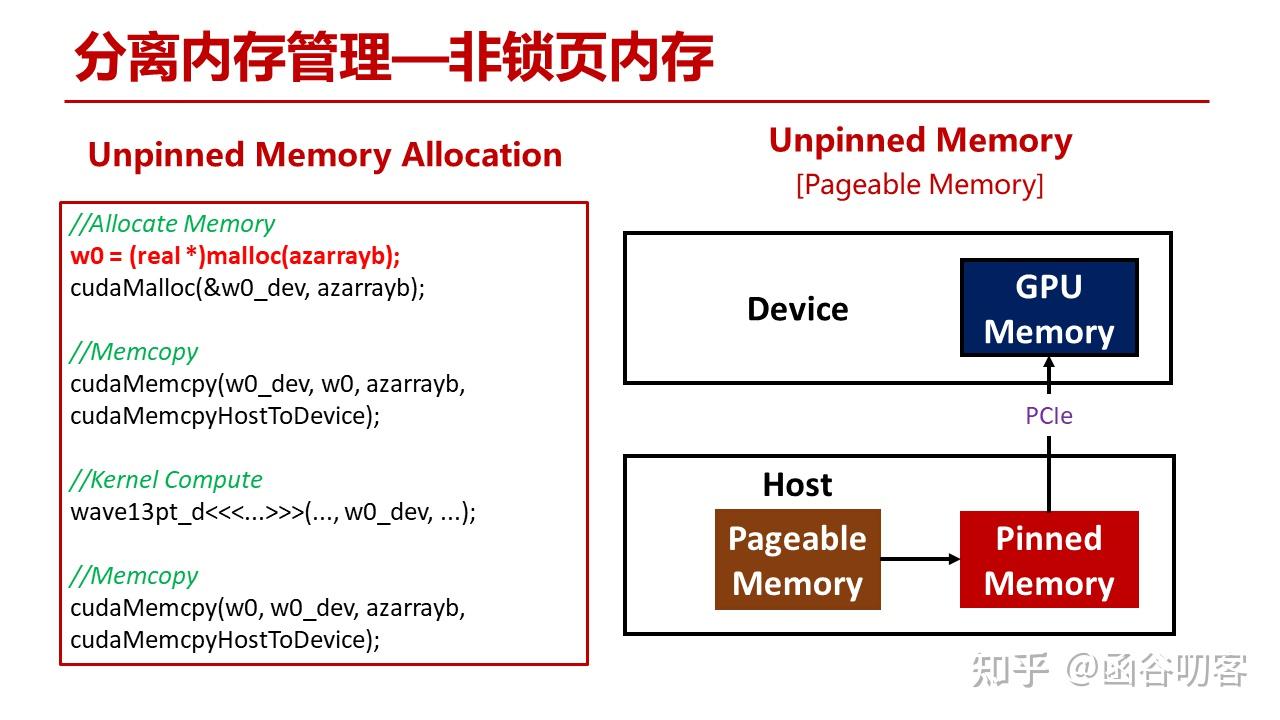
在最原始的方式下,从主机内存拷贝到GPU显存,首先操作系统会分配一块用于数据中转的临时锁页内存,然后将用户缓冲区中的数据拷贝到锁页内存中,在通过PCIe DMA拷贝到GPU显存中。
- 锁页内存(Pinned Memory)
- 内存区域:锁页内存通常分配在物理内存中,且是固定不变的。操作系统不会将这部分内存换出到磁盘,因此始终保持在物理内存中。
- 分配方式:在许多编程模型(如 CUDA)中,分配锁页内存时,使用特定的 API(如 cudaMallocHost)来确保分配的内存块不会被换出。
- 非锁页内存(Pageable Memory)
- 内存区域:非锁页内存可以位于任何可用的虚拟内存区域,操作系统可以在需要时将其换出到磁盘。这意味着这部分内存可能会被动态管理。
- 分配方式:通常使用标准的内存分配函数(如 malloc 或 new)来分配,可随时被操作系统处理。
对于分离内存管理,其又可以分为两种,即锁页内存和零拷贝内存。
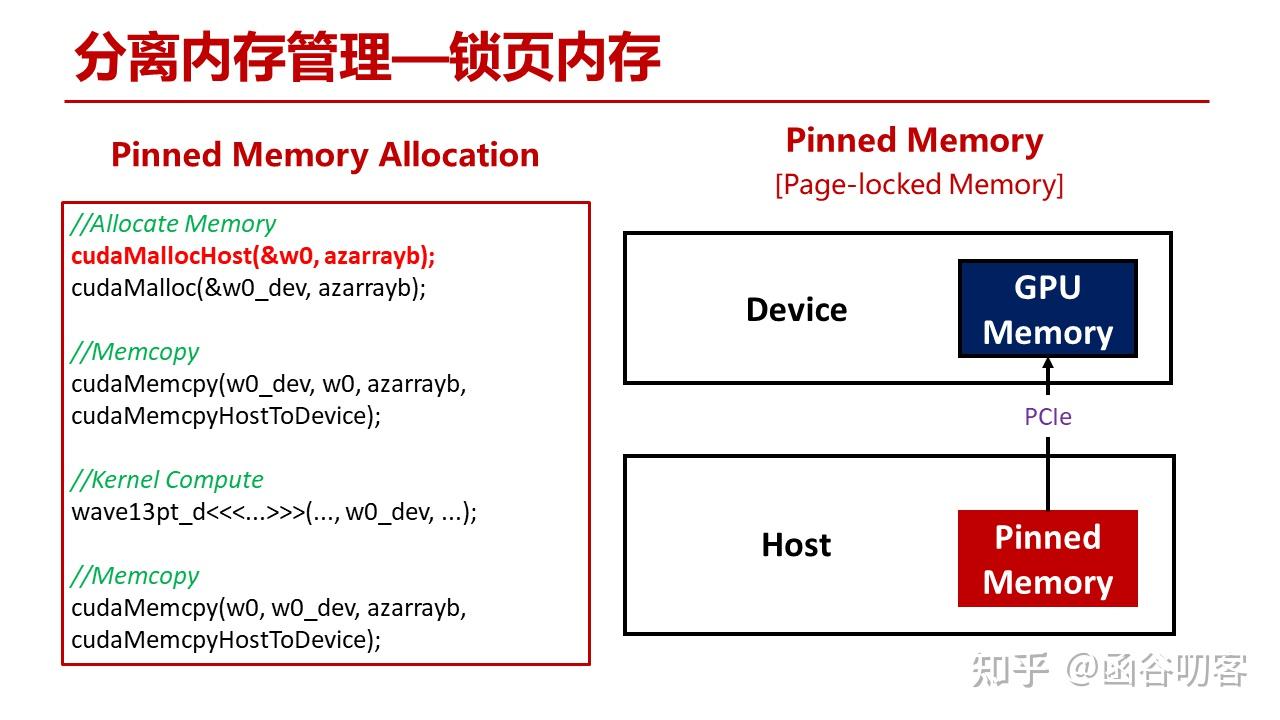
1.1 锁页内存
对于锁页内存,首先分配内存的API发生了变化,而且分配的区域将直接成为锁页内存区域,在向GPU显存进行拷贝时只需要进行一次PCIe DMA操作即可。
无论是传统的非锁页内存还是锁页内存,刚才看到GPU需使用CPU的数据是需要通过 CudaMemcpy 进行显式拷贝操作的,这种方式适合大批量的数据传递。
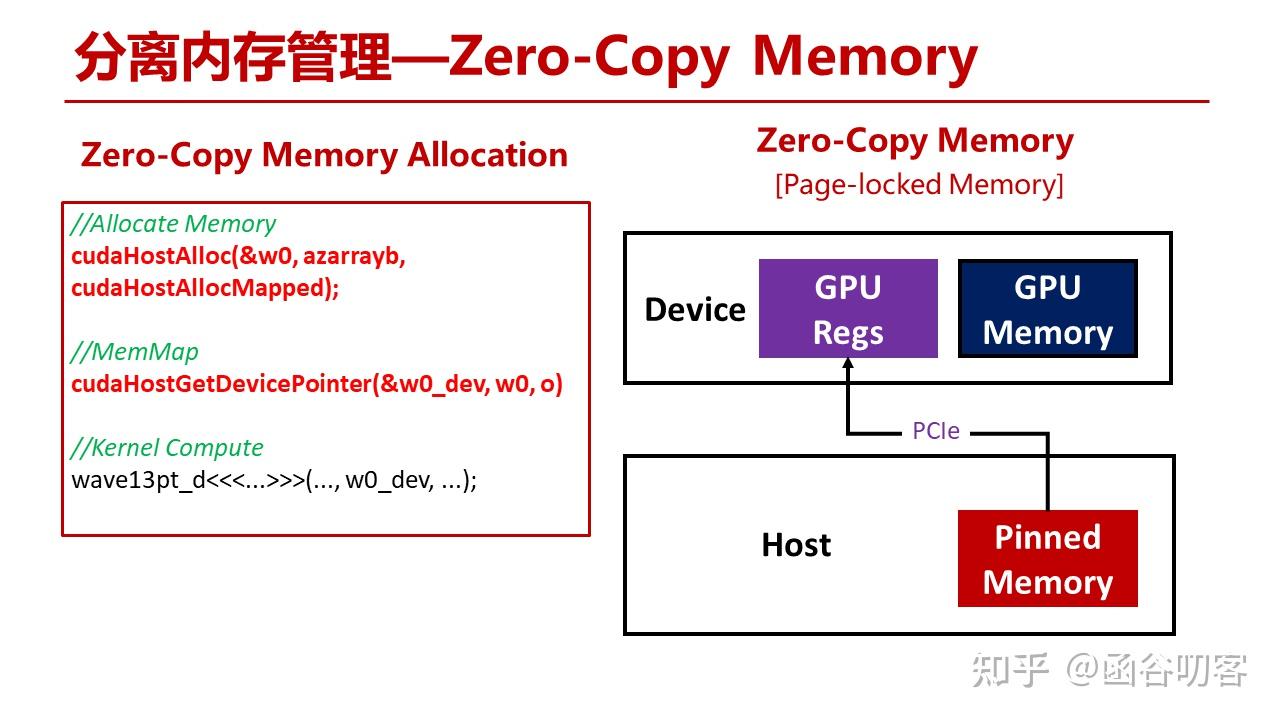
1.2 零拷贝内存
如果只是想更新某个标志位,可以使用零拷贝内存。所谓零拷贝,就是GPU寄存器堆直接与主机内存交互。从代码里可以看到,将主机内存指针进行映射后,Kernel就可以直接使用指针来访问主机内存了,读取的数据会直接写入寄存器中。
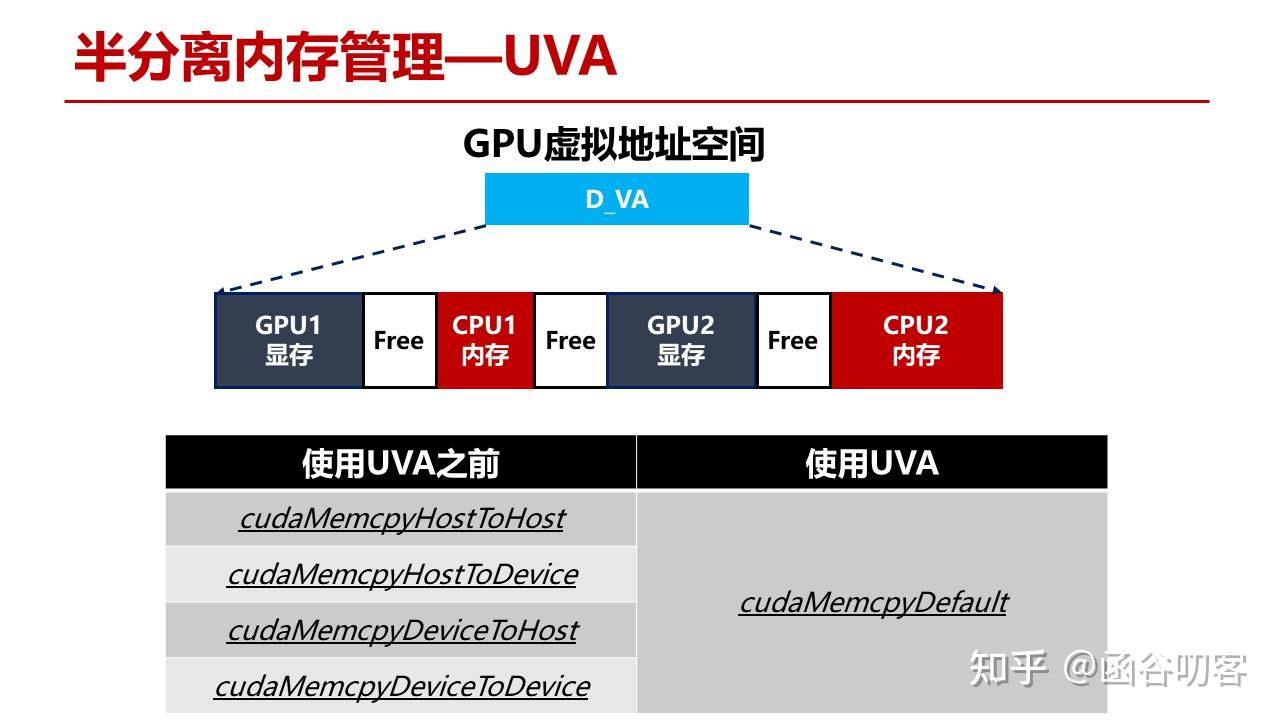
在分离内存管理的基础上,Nvidia推出了半分分离内存管理,也就是统一虚拟地址空间。
2. 半分离内存管理
对于半分离内存管理,实际上也是语法糖,将原有的四个方向的拷贝函数和成了一个,用户调用统一的拷贝函数,由Cuda Runtime来判定数据源和目标所在的物理地址。
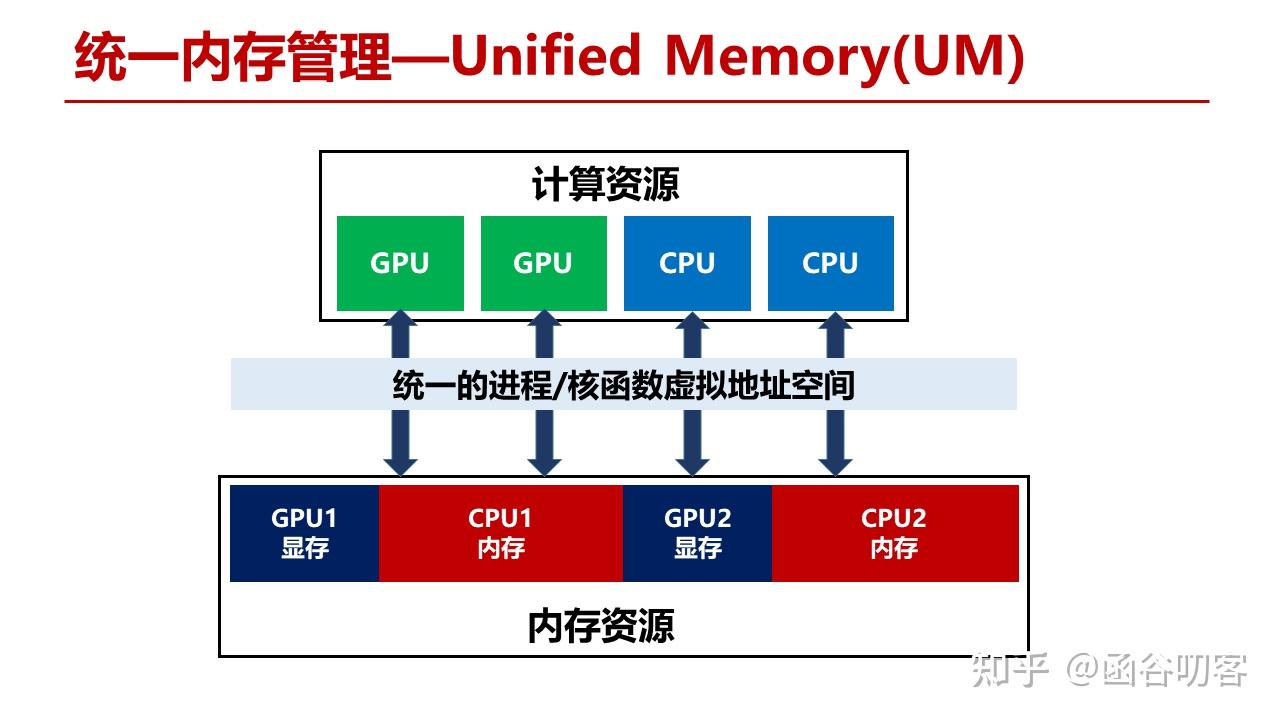
在UVA之后,Nvidia又创造性地提出了Unified Memory统一内存管理机制。
3. 统一内存管理
Unified Memory在Unified Virtual Address的基础上更进一步,将系统内的所有内存资源都整合到相同的虚拟地址空间中。不管是CPU还是GPU代码,不用再区分其指针指向的空间,这给用户编程提供了极大的便利性。
case
我们看两个例子,代码功能是在CPU上分配一段数据,CPU进行运算,将结果拷贝到GPU上运算,GPU运算结束再拷贝到CPU中,CPU再继续运算。如果使用Unified Memory,在分配完数据后,不需要进行显式数据拷贝,直接调用相关函数对其进行处理即可,在GPU处理完后需要执行一次同步。

上面例子的优势还不明显,我们再看下一个例子。这是一个深拷贝操作,CPU分配一个二维数组,显式拷贝时,要对二维数组进行逐行拷贝。但使用Unified Memory,Kernel就可以直接对数据进行操作。到这里我们看到了UM作为语法糖发挥的一些作用,看起来与UVA好像区别不大,都是GPU虚拟地址直接访问主机内存空间。但对于UVA,GPU访问主存是直接将数据搬到寄存器里的,不经过其显存,这也就意味着每次访问都至少要经过一次PCIe操作。UM在底层硬件实现上机制完全不同。

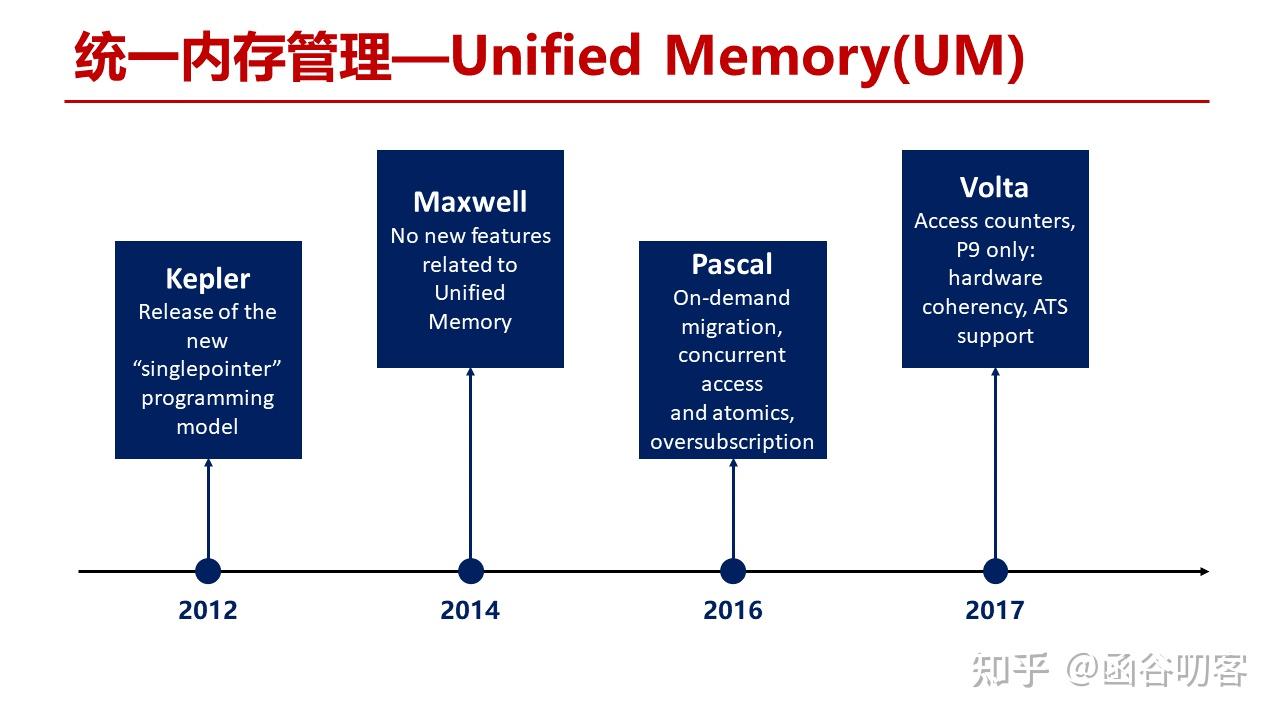
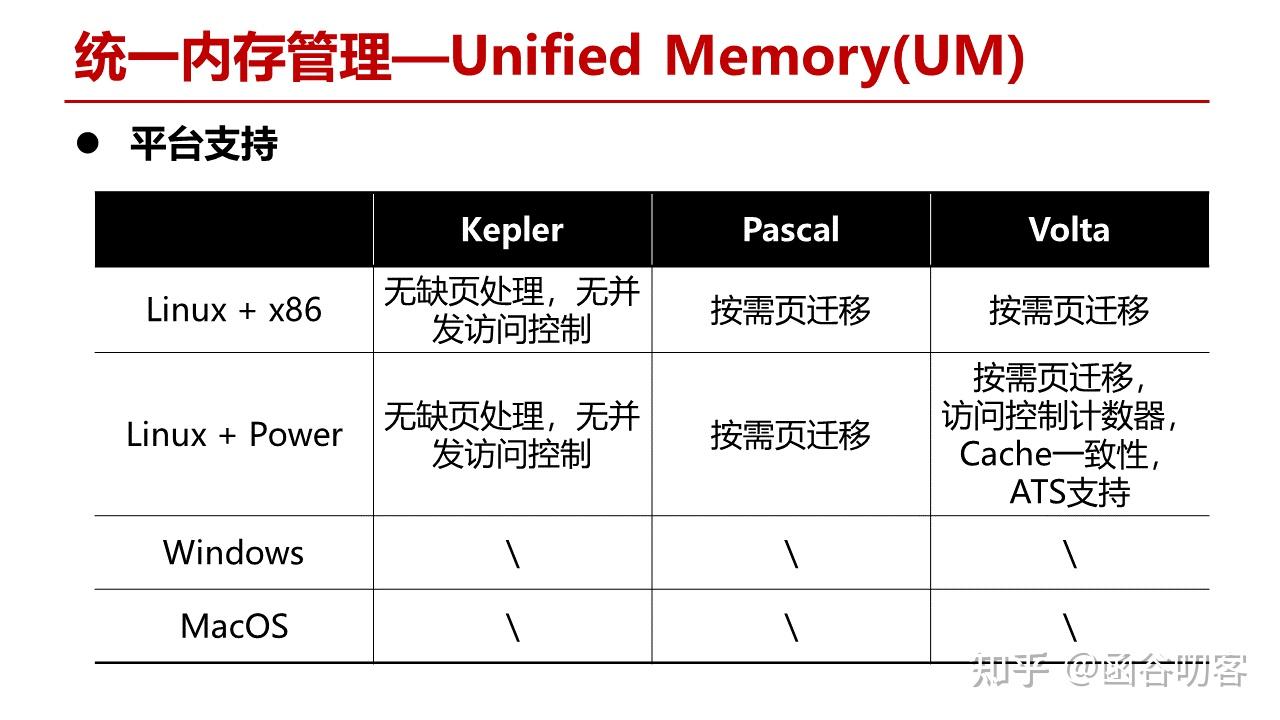
实际上,直到Pascal架构才算真正有了对UM的硬件上的支持。在Pascal架构之前,Kepler和Maxwell仅仅还是沿用了前面讲的CPU数据搬移到GPU寄存器中,只是在CUDA Runtime中提供了对地址的判断。而在Pascal架构上,实现了对物理内存页的按需迁移,GPU和CPU的并发访问,内存超额配置等,以及在Volta架构上又进一步实现了访问计数器,GPU和CPU的Cache一致性等新特性。
我们首先来看在Pascal架构之前UM的硬件工作方式。这段代码首先分配GPU显存,这时GPU的MMU会分配一段物理内存,然后构造页表项。
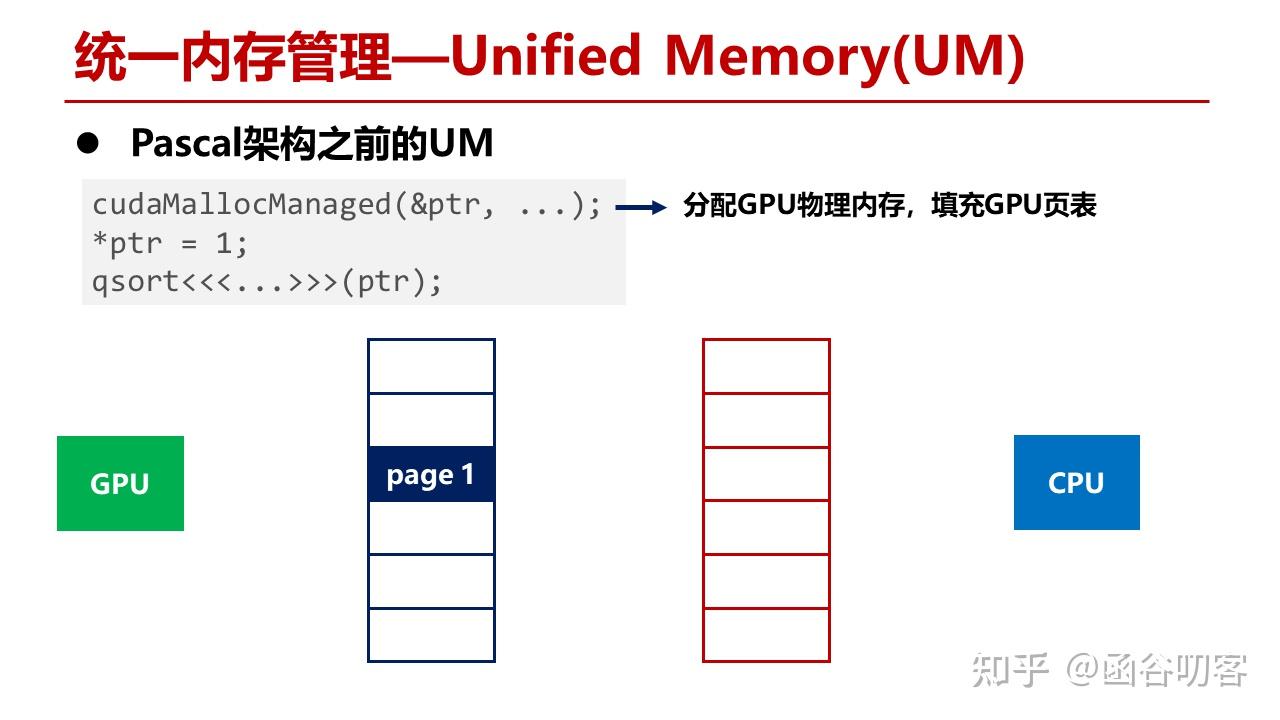
当CPU指针访问这段显存时,发生缺页异常,进行物理页迁移,将GPU的物理页迁移到CPU内存中,此时GPU的页表会进行释放。
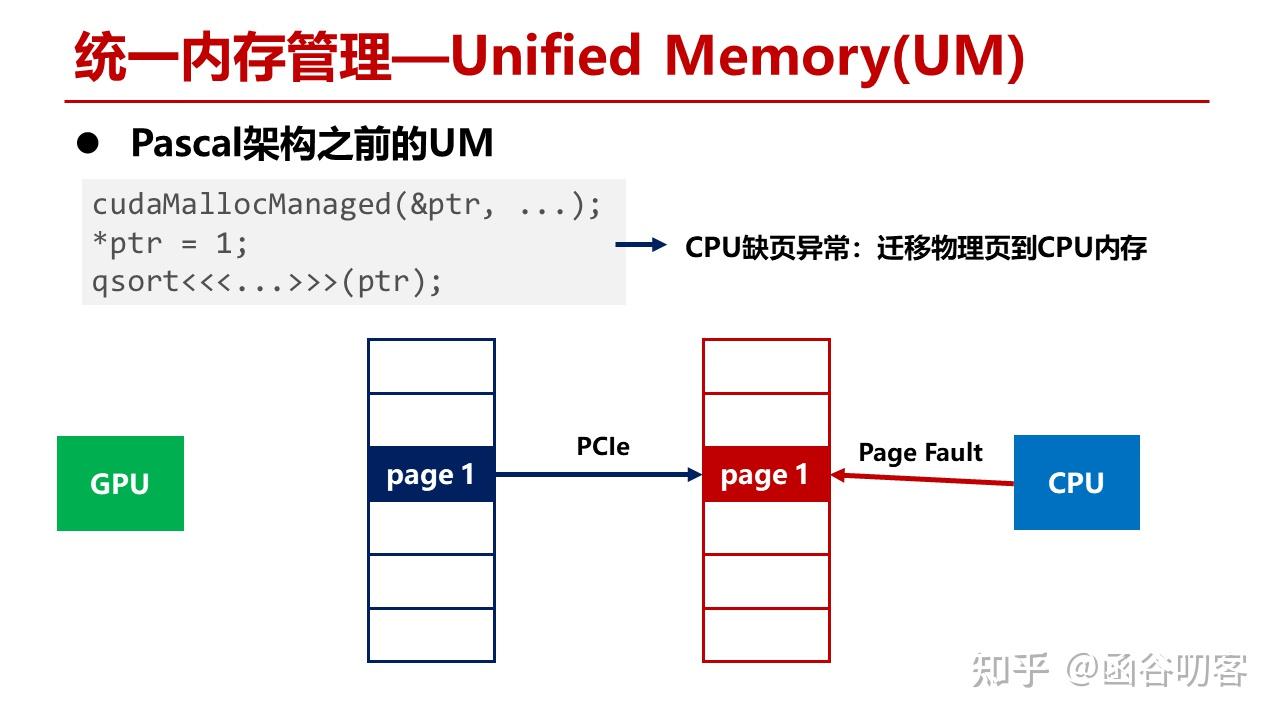
而当Kernel使用该地址时,会再次构造GPU页表项,将CPU内存页迁移到GPU上。
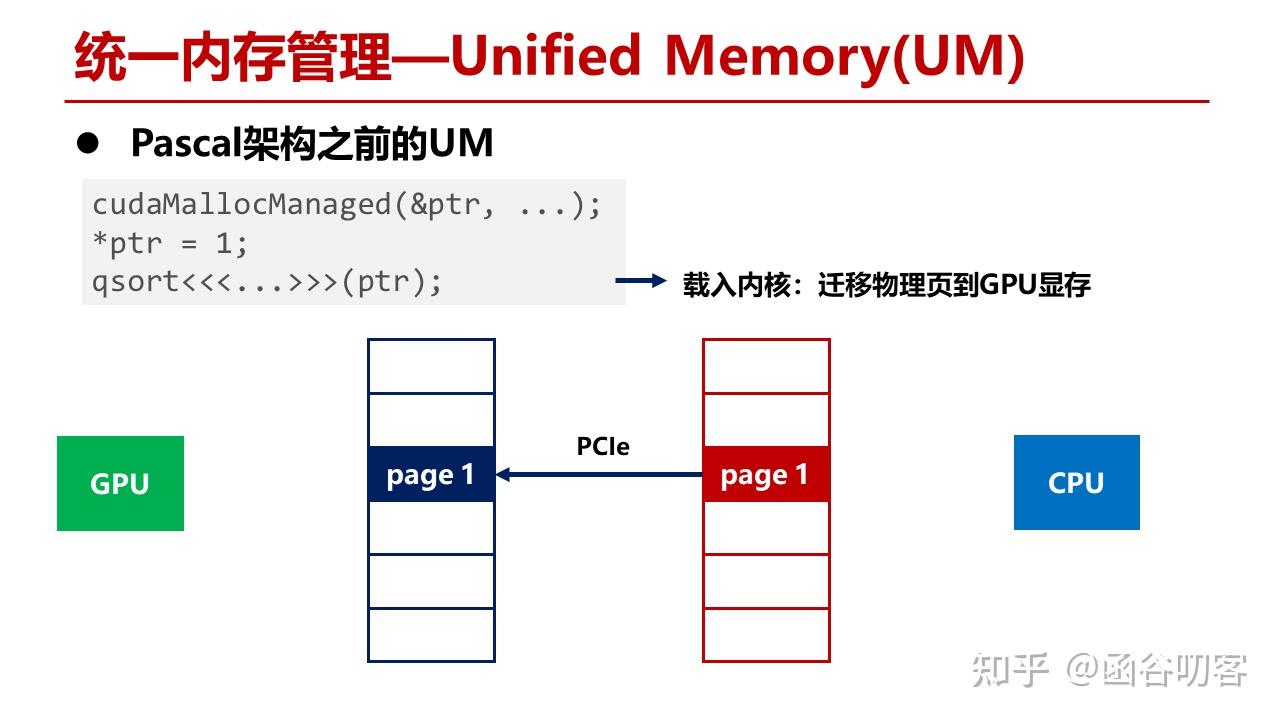
在这种方式下,UM不能支持内存超额配置,也就是申请的内存数量不能超过GPU显存总量。同时也不支持按需页迁移,例如当GPU显存已经塞满时,如果要访问CPU内存,数据会直接进入GPU寄存器,而不会对显存进行置换,如果频繁访问CPU内存就会带来较大的开销。

在Pascal之后的架构对GPU缺页异常提供了支持,在分配GPU内存时,只是分配了一个页表项,没有进行实际的显存分配。
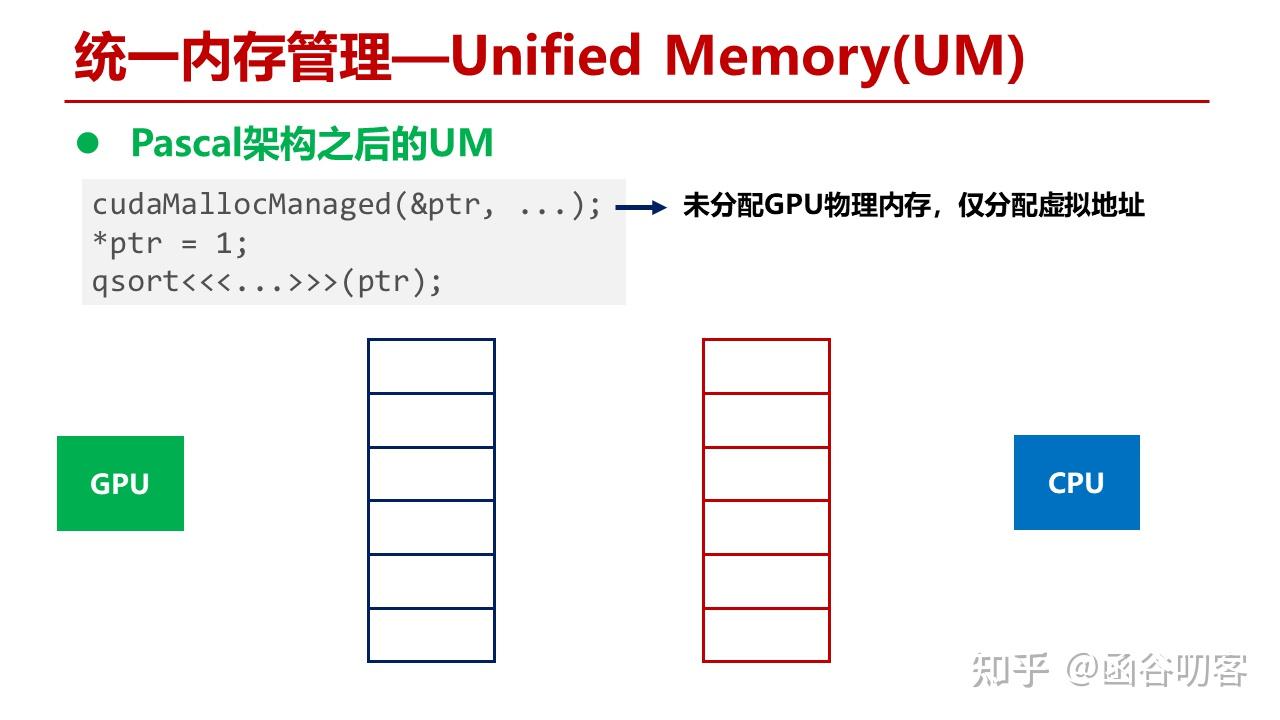
当CPU代码访问内存时,发生缺页异常,分配CPU物理内存页,创建CPU页表项。
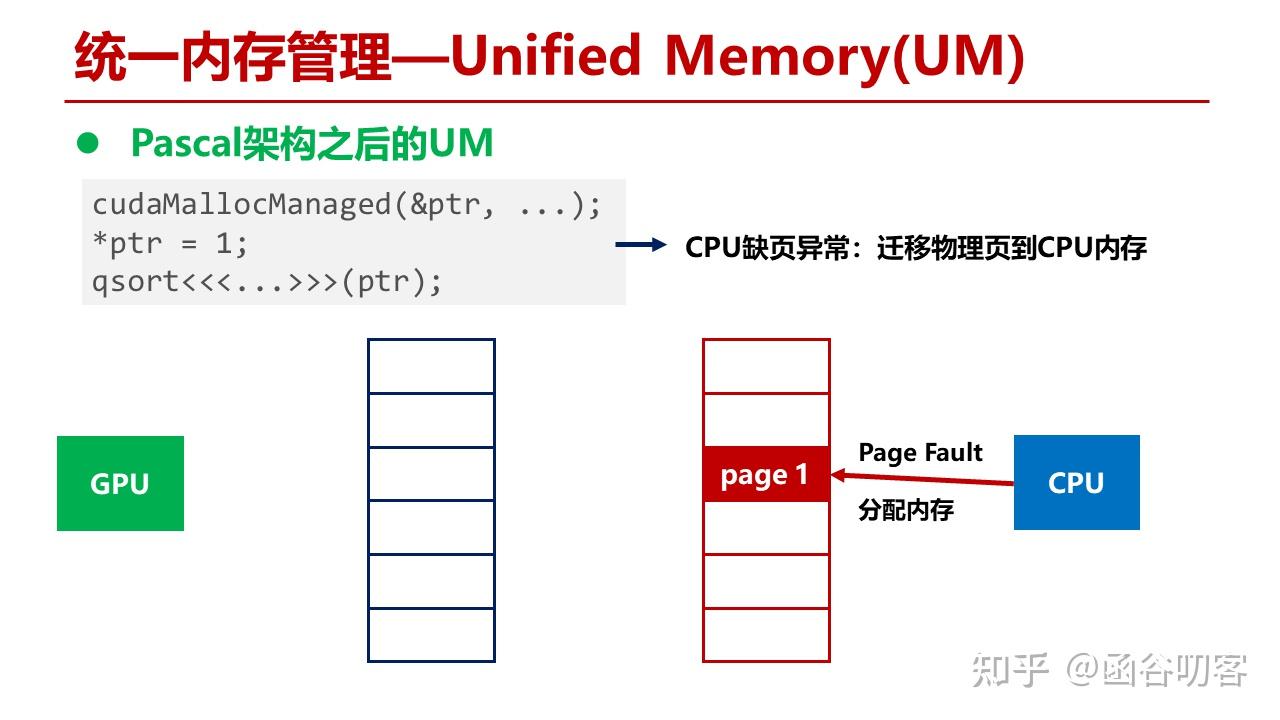
当GPU代码访问时,发生GPU缺页异常,CPU内存页通过PCIe被迁移到GPU显存中。
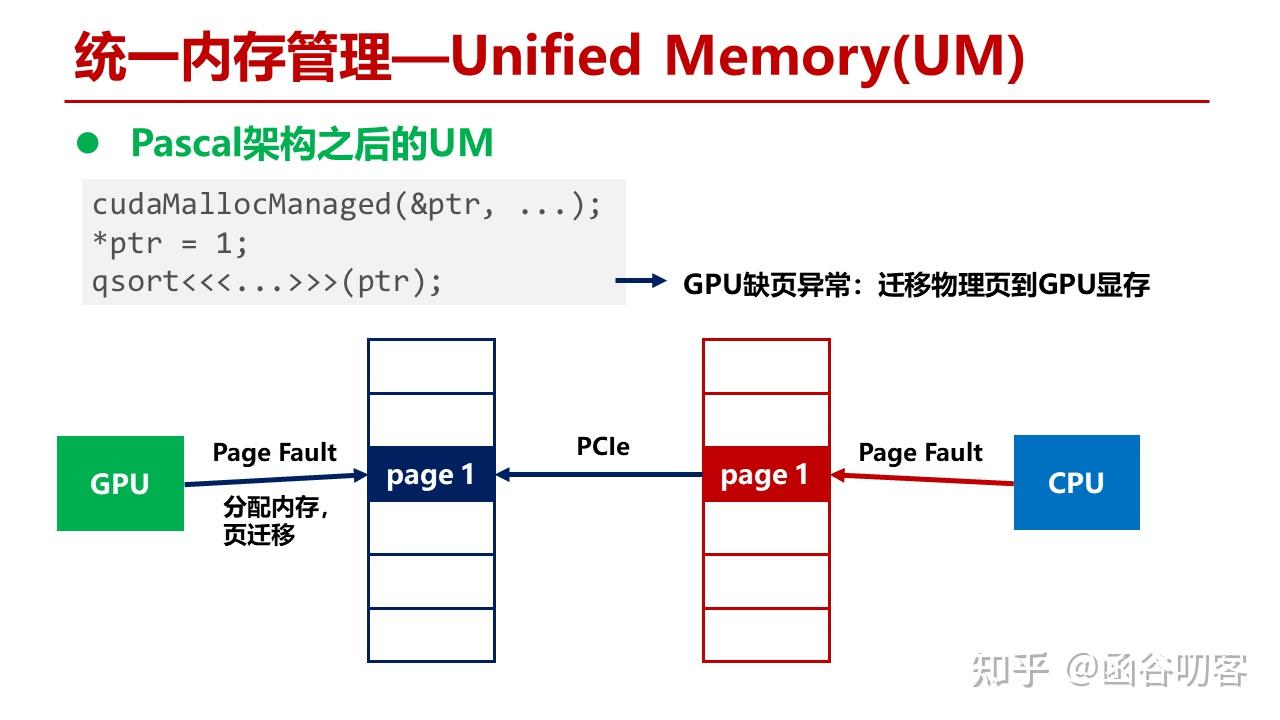
接下来我们看Pascal架构是怎么支持内存超额配置和按需页迁移的。在当前状态下,对于GPU和CPU虚拟地址空间,Page 1到Page 4指向了GPU显存,Page 5指向了CPU内存。当GPU访问Page 5时,发现GPU页表为空,出现缺页异常。
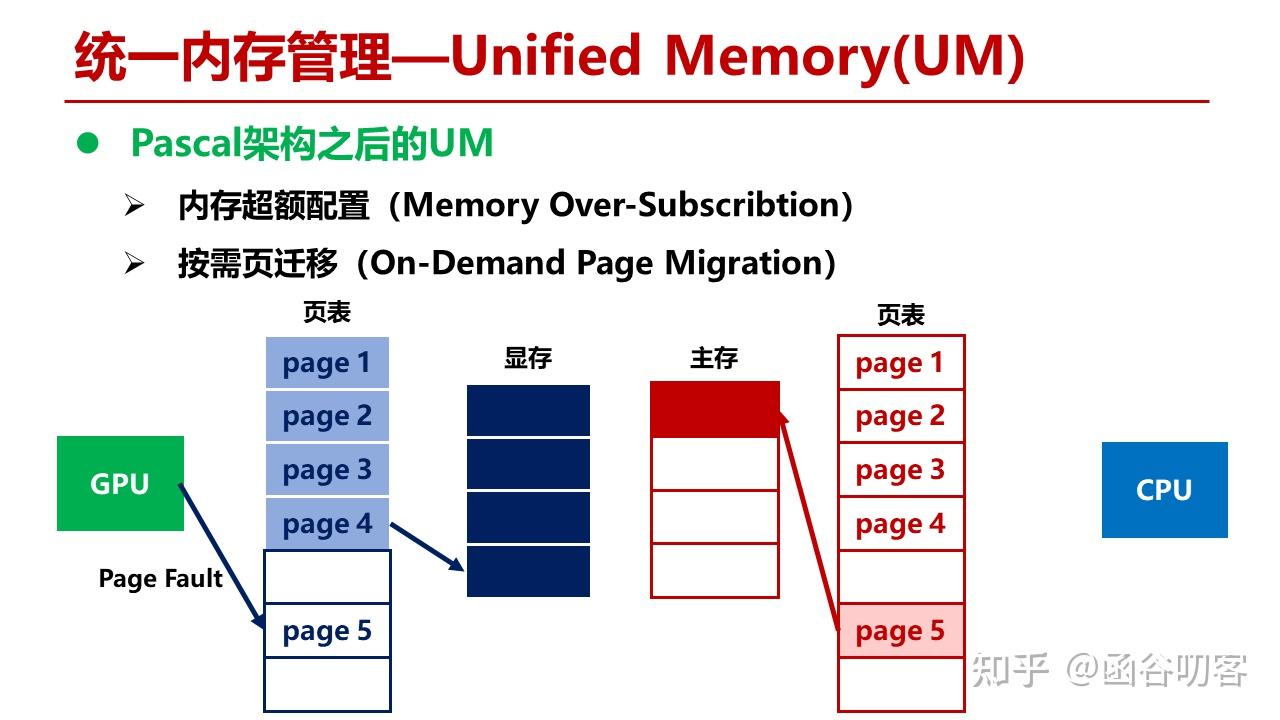
此时,GPU的MMU会在显存中选择一个物理页面迁移到CPU主存中,这里是Page 4,然后在CPU页表中建立Page 4到物理页面的映射。
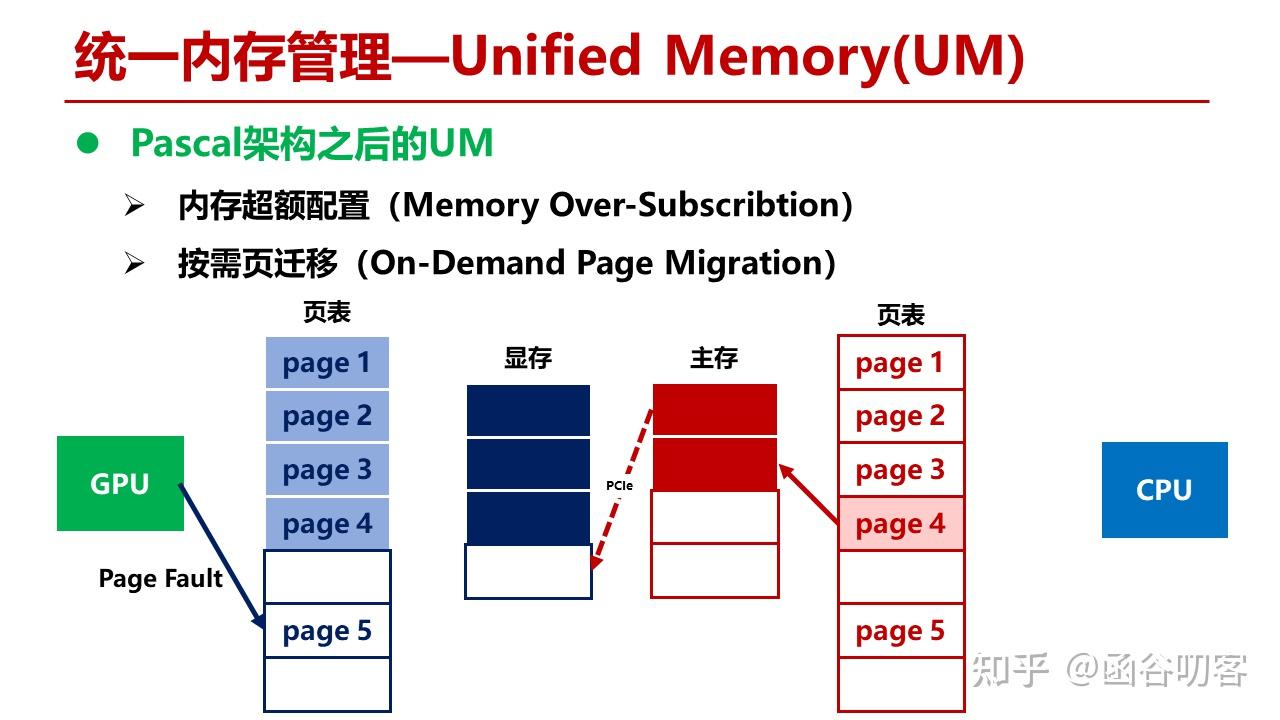
完成整个缺页异常的处理流程。
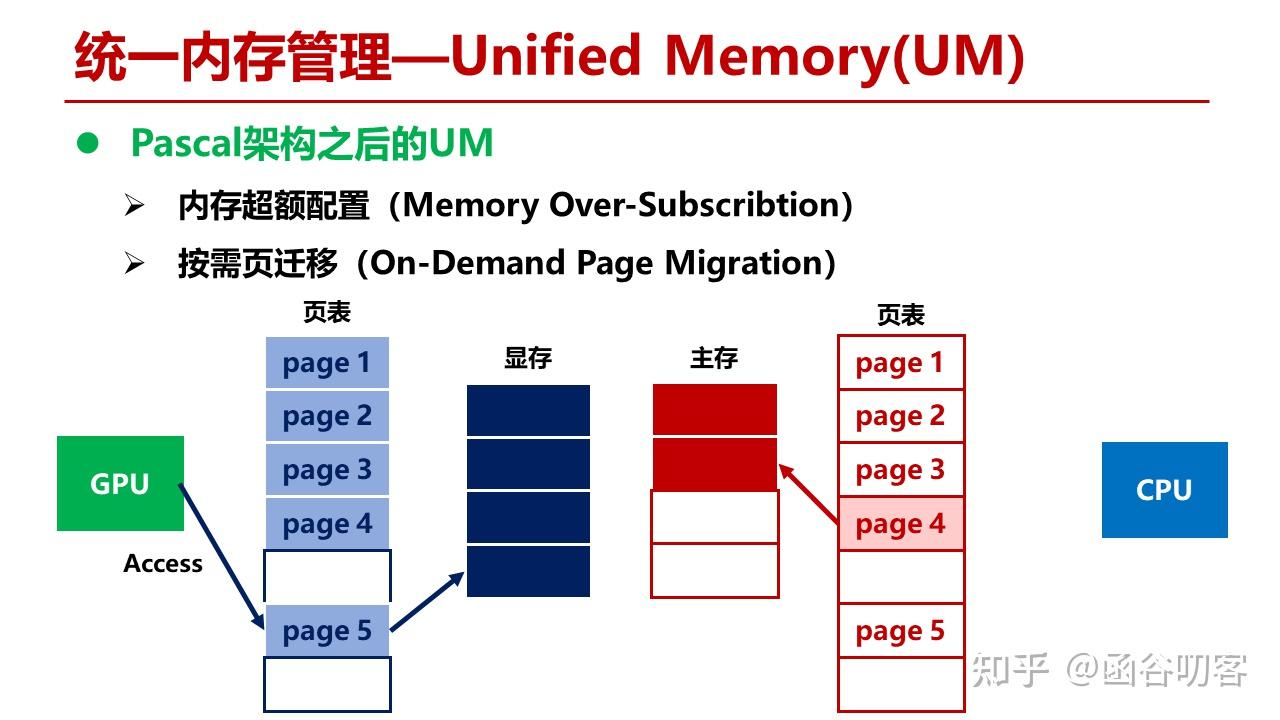
上述示例只是给出了基本的按需页迁移的过程。UM还涉及到很多相关问题,比如Cache一致性问题,CPU和GPU对同一个数据的多次并发读写,导致页面来回迁移的问题等,以及冷热页面的替换算法问题等。Power系列对UM特性的支持更完备,一个主要原因是其支持GPU和Power 9直接通过NVLink进行互连,后面在Summit和SummitDev的评测中我们可以看到这种架构。需要注意的是,UM本质上还是一种语法糖,这些特性的支持也只是为了尽可能提升语法糖的性能。由于这部分内容本身不是今天讨论的重点,所以点到为止。更详细的性能测评数据可以看相关参考文献。
接下来是本文讨论的重点内容,GPUDirect技术的介绍。首先我会介绍GPUDirect技术是如何演进的,然后我会重点讨论GPUDirect技术的实现细节,最后给出GPUDirect技术的详细评测结果。这部分内容主要参考了[7-9]。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号