基于requests模块的爬虫
1. requests模块:
该模块的作用:模拟浏览器发请求。
2. 使用requests模块爬取数据流程
1. 指定url
2. 发起http请求
3. 获取响应数据
4. 保存爬取到的数据
3. 环境安装:
pip install requests
4. 爬取程序:
爬取搜狗首页数据
import requests
url = 'https://***.***.com'
headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36' }
response = requests.get(url=url,headers=headers)
page_text = response.text #爬取的是响应包的源代码
print(page_text)
with open('./sogou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
print('爬取结束')
5. 代码优化
当我们要爬取的数据,需要通过url中的参数来提交时,我们要爬取的参数有很多,那么我们就可以将我们的参数放置在一个字典中。
import requests url = 'https://***.***.com' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36' } kw = input('enter a word:')
#param字典存储的是请求url的参数键值对:相当于?query=kw param = { 'query':kw } #对指定的url发起请求的url是携带参数的url,params就是请求的参数。
#这里的url就是 https://***.***.com?query=kw response = requests.get(url=url,params=param,headers=headers) page_text = response.text
fileName = kw+'.html' with open(fileName,'w',encoding='utf-8') as fp: fp.write(page_text) print('爬取结束')
6. 爬取局部文本数据:ajax刷新页面的爬取
前面都是直接将响应的页面全部保存了下来,有的需求就是只需要部分数据,这里用数据解析比较方便。
首先要找到对应的ajax的请求数据包,可以直接在浏览器的调试框中找到。并且可以看到这个请求的url,以及请求的方式,携带的参数。参数的类型,比如json等。
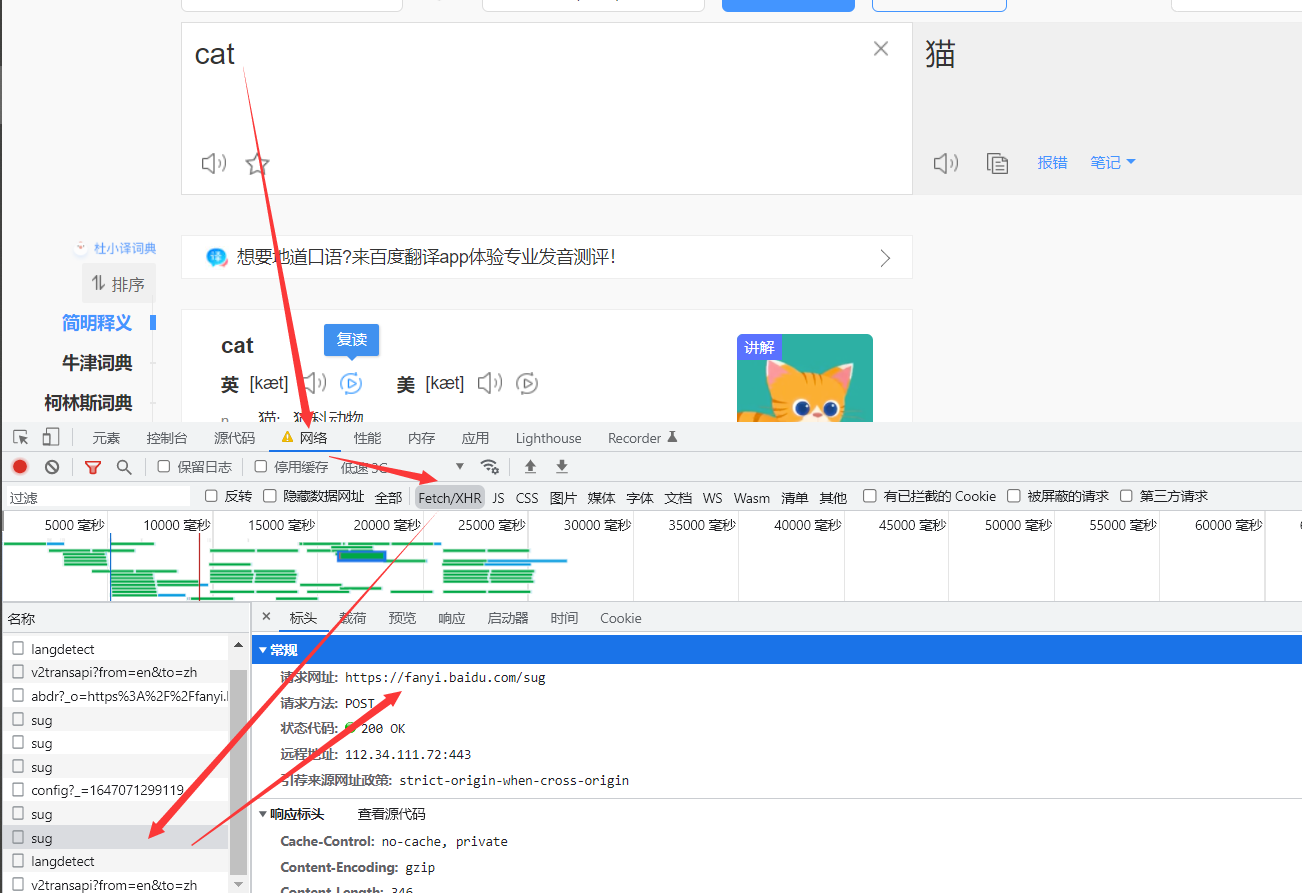
编写程序
import requests #这里导入json模块是为了后面保存爬取的数据时用。 import json post_url = 'https://fanyi.baidu.com/sug' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36' } word = input('enter a word:') #post请求参数处理,和get请求方式一样。 data = { 'kw':word } #post请求中,参数用data来表示,而get中是params。 response = requests.post(url=post_url,data=data,headers=headers) #json()对象拿到的是一个字典。如果响应的数据是json格式的,我们就可以这样提取。 dic_obj = response.json() print(dic_obj) fileName = word+'.json' fp = open(fileName,'w',encoding='utf-8') #ensure_ascii=False 这里是为了不让把中文用ascii编码。 json.dump(dic_obj,fp=fp,ensure_ascii=False) print('爬取结束')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号