
Understanding the linux kernel Chapter5 Kernel Synchronization
How the kernel Services Requests
Kernel Preemption
As I understand, Kernel Preemption is the invocation of the schedule()
the main characteristic of a preemptive kernel is that a process running in Kernel Mode can be replaced by another process while in the middle of a kernel function.
The main motivation for making a kernel preemptive is to reduce the dispatch latency of the User Mode processes, that is, the delay between the time they become runnable and the time they actually begin running.
kernel can be preempted only when it is executing an exception handler (in particular a system call,or just exited from interrupt handler?) and the kernel preemption has not been explicitly disabled.
macros handle preempt_count
preempt_count()
preempt_disable()
preempt_enable_no_resched()
//Decreases by one the value of the preemption counter, and invokes **preempt_schedule()** if the TIF_NEED_RESCHED flag in the thread_info descriptor is set
premmpt_enable()
//Similar to preempt_disable(), but also returns the number of the local CPU
get_cpu()
//Same as premmpt_enable() and preempt_enable_no_resched()
put_cpu()
put_cpuh_no_resched()
kernel preemption may happen either when a kernel control path (usually, an interrupt handler) is terminated, or when an exception handler reenables kernel preemption by means of preempt_enable().kernel preemption may also happen when deferrable functions are enabled.
When Synchronization Is Not Necessary
constraints
- All interrupt handlers acknowledge the interrupt on the PIC and also disable the IRQ line. Further occurrences of the same interrupt cannot occur until the handler terminates.
- Interrupt handlers, softirqs, and tasklets are both nonpreemptable and nonblocking.
- A kernel control path performing interrupt handling cannot be interrupted excepted by another interrupt irqs.
- Softirqs and tasklets cannot be interleaved on a given CPU and The same tasklet cannot be executed simultaneously on several CPUs.
the simplifications benified from constraints
- Interrupt handlers and tasklets need not to be coded as reentrant functions.
- Per-CPU variables accessed by softirqs and tasklets only do not require synchronization.
- A data structure accessed by only one kind of tasklet(or interrupt handler) does not require synchronization.
Sychronization Primitves
per-cpu variables
The simplest and most efficient synchronization technique consists of declaring kernel variables as per-CPU variables(execute like in the uniprocessor). that the per-CPU variables can be used only in particular cases—basically, when it makes sense to logically split the data across the CPUs of the system.
The elements of the per-CPU array are aligned in main memory and falls on different cache line, so concurrent accesses to the per-CPU array do not result in cache line snooping and invalidation.
per-CPU variables are prone to race conditions caused by kernel preemption, so a kernel control path should access a per-CPU variable with kernel preemption disabled(e.g. one exception handler get the address of the local cpu-var and an interrupt hanppend and preempt kernel and scheduled the handler to another cpu after it terminated).
macros ops on per-cpu var
DEFINE_PER_CPU(type, name) \\ Statically allocates a per-CPU array called name of type data structures
per_cpu(name, cpu) \\ Selects the element for CPU cpu of the per-CPU array name
_ _get_cpu_var(name) \\ Selects the local CPU’s element of the per-CPU array name
get_cpu_var(name) \\ Disables kernel preemption, then selects the local CPU’s element of the per-CPU array name
put_cpu_var(name) \\ Enables kernel preemption (name is not used)
alloc_percpu(type) \\ Dynamically allocates a per-CPU array of type data structures and returns its address
free_percpu(pointer) \\ Releases a dynamically allocated per-CPU array at address pointer
per_cpu_ptr(pointer, cpu) \\ Returns the address of the element for CPU cpu of the per-CPU array at address pointer
Atomic operations
When you write C code, you cannot guarantee that the compiler will use an atomic instruction for an operation like a=a+1 or even for a++.
classification
Assembly language instructions that make zero or one aligned memory access are atomic.(an unaligned memory access is not atomic)
Read-modify-write assembly language instructions in uniprocessor.
Read-modify-write assembly language instructions whose opcode is prefixed by the lock byte (0xf0) are atomic even on a multiprocessor system. When the control unit detects the prefix, it “locks” the memory bus until the instruction is finished.
Optimization and Memory Barriers
Things would quickly become hairy if an instruction placed after a synchronization primitive is executed before the synchronization primitive itself(caused by optimization). Therefore, all synchronization primitives act as optimization and memory barriers.
optimization barrier
An optimization barrier primitive ensures that the assembly language instructions corresponding to C statements placed before the primitive are not mixed by the compiler with assembly language instructions corresponding to C statements placed after the primitive.
Notice that the optimization barrier does not ensure that the executions of the assembly language instructions are not mixed by the CPU—this is a job for a memory barrier.
the real understanding of the optimization barriers needs the basic knowledge of CPU-excution optimization(pending now).
/* Optimization barrier */
#ifndef barrier
/* The "volatile" is due to gcc bugs */
# define barrier() __asm__ __volatile__("": : :"memory")
#endif
The memory keyword forces the compiler to assume that all memory locations in RAM have been changed by the assembly language instruction; therefore, the compiler cannot optimize the code by using the values of memory locations stored in CPU registers before the asm instruction. Notice that the optimization barrier does not ensure that the executions of the assembly language instructions are not mixed by the CPU this is a job for a memory barrier.
memory barrier
A memory barrier primitive ensures that the operations placed before the primitive are finished before starting the operations placed after the primitive. Thus, a memory barrier is like a firewall that cannot be passed by an assembly language instruction.
the "serializing" instructions act as memory barries
- All instructions that operate on I/O ports.
- All instructions prefixed by the lock byte.
- All instructions that write into control registers, system registers, or debug registers (for instance, cli and sti).
- The lfence, sfence, and mfence assembly language instructions, which have been introduced in the Pentium 4 microprocessor to efficiently implement read memory barriers, write memory barriers, and read-write memory barriers, respectively.
- A few special assembly language instructions; among them, the iret instruction that terminates an interrupt or exception handler
Memory barriers primitives in Linux
These memory barriers primitives act also as optimization barriers, because we must make sure the compiler does not move the assembly language instructions around the barrier.
mb() //Memory barrier for MP and UP
rmb() //Read memory barrier for MP and UP
wmb() //Write memory barrier for MP and UP
//use in multiprocessor
smp_mb() //Memory barrier for MP only
smp_rmb() //Read memory barrier for MP only
smp_wmb() //Write memory barrier for MP only
The implementations of the memory barrier primitives depend on the architecture of the system.
Spin Locks
As a general rule, kernel preemption is disabled in every critical region protected by spin locks. In the case of a uniprocessor system, the locks themselves are useless, and the spin lock primitives just disable or enable the kernel preemption. Please notice that kernel preemption is still enabled during the busy wait phase, thus a process waiting for a spin lock to be released could be replaced by a higher priority process.
spinlock_t
- slock
Encodes the spin lock state: the value 1 corresponds to the unlocked state, while every negative value and 0 denote the locked state.
- break_lock
Flag signaling that a process is busy waiting for the lock (present only if the kernel supports both SMP and kernel preemption)
spin_lock_init() //Set the spin lock to 1 (unlocked)
spin_lock() //Cycle until spin lock becomes 1 (unlocked), then set it to 0 (locked)
spin_unlock() //Set the spin lock to 1 (unlocked)
spin_unlock_wait() //Wait until the spin lock becomes 1 (unlocked)
spin_is_locked() //Return 0 if the spin lock is set to 1 (unlocked); 1 otherwise
spin_trylock() //Set the spin lock to 0 (locked), and return 1 if the previous value of the lock was 1; 0 otherwise
The spin_lock macro with kernel preemption
- Invokes preempt_disable() to disable kernel preemption.
- Invokes the _raw_spin_trylock() function.
_raw_spin_trylock
//do ops same as below
movb $0, %al
xchgb %al, slp->slock
xchgb(test-and-set)
The xchg assembly language instruction exchanges atomically the content of the 8-bit %al register (storing zero) with the content of the memory location pointed to by slp->slock. The function then returns the value 1 if the old value stored in the spin lock (in %al after the xchg instruction) was positive, the value 0 otherwise.
-
If the old value of the spin lock was positive, the macro terminates: the kernel control path has acquired the spin lock.
-
invoke preempt_enable and busy wait
-
If the break_lock field is equal to zero, sets it to one. By checking this field, the process owning the lock and running on another CPU can learn whether there are other processes waiting for the lock. If a process holds a spin lock for a long time, it may decide to release it prematurely to allow another process waiting for the same spin lock to progress(how?when?).
-
cpu_relax()(busy wait)
The spin_lock maco without kernel preemption
spin_lock
//equaivalen ops as below
1: lock; decb slp->slock//(atomic op)&(memory barrier) with lock prefix
jns 3f //(the f suffix denotes the fact that the label is a “forward” one; it appears in a later line of the program
2: pause
cmpb $0,slp->slock
jle 2b
jmp 1b
3:
Then execution restarts from label 1, since it is unsafe to proceed without checking whether another processor has grabbed the lock.
The spin_unlock macro
- movb $1, slp->slock
- invoke preempt_enable()
Notice that the lock byte is not used because write-only accesses in memory are always atomically executed by the current 80×86 microprocessors.
Read/Write Spin Locks(no sequence)
rwlock_t
- A 24-bit counter denoting the number of kernel control paths currently reading the protected data structure. The two’s complement value of this counter is stored in bits 0–23 of the field.
- An unlock flag that is set when no kernel control path is reading or writing, and clear otherwise. This unlock flag is stored in bit 24 of the field.
Geting and releasing a lock for reading
preempt_disable() -- _raw_read_trylock() -- preempt_enable()
_raw_read_trylock
int _raw_read_trylock(rwlock_t *lock)
{
atomic_t *count = (atomic_t *)lock->lock;
atomic_dec(count);
if (atomic_read(count) >= 0)
return 1;
atomic_inc(count);
return 0;
}
The lock field—the read/write lock counter—is accessed by means of atomic operations. Notice, however, that the whole function does not act atomically on the counter.for instance, the counter might change after having tested its value with the if statement and before returning 1. Nevertheless, the function works properly: in fact, the function returns 1 only if the counter was not zero or negative before the decrement, because the counter is equal to 0x01000000 for no owner, 0x00ffffff for one reader, and 0x00000000 for one writer.
the reason why this function do not need to be atomic is that the acquire of the reader lock don't care about the sequence. when the numbers of the readers exceed 0x00ffffff, than only 0x00ffffff readers get the lock and other return 0 and incr count, so the non-atomic of the incr and comparation of the value count is don't matter.
Getting and releasing a lock for writing
preempt_disable() -- _raw_write_trylock() -- preempt_enable()
_raw_write_trylock
int _raw_write_trylock(rwlock_t *lock)
{
atomic_t *count = (atomic_t *)lock->lock;
if (atomic_sub_and_test(0x01000000, count))
return 1;
atomic_add(0x01000000, count);
return 0;
}
The _raw_write_trylock() function subtracts 0x01000000 from the read/write spin lock value, thus clearing the unlock flag (bit 24). If the subtraction operation yields zero (no readers), the lock is acquired and the function returns 1; otherwise, the function atomically adds 0x01000000 to the spin lock value to undo the subtraction operation.
Seqlocks
Seqlocks introduced in Linux 2.6 are similar to read/write spin locks, except that they give a much higher priority to writers.
strategy
Each seqlock is a seqlock_t structure consisting of two fields: a lock field of type spinlock_t and an integer sequence field. This second field plays the role of a sequence counter. Each reader must read this sequence counter twice, before and after reading the data, and check whether the two values coincide.
writer of the seqlocks
disable preempt automatically(because it acquire spin lock)
Writers acquire and release a seqlock by invoking write_seqlock() and write_sequnlock(). The first function acquires the spin lock in the seqlock_t data structure, then increases the sequence counter by one; the second function increases the sequence counter once more, then releases the spin lock. This ensures that when the writer is in the middle of writing, the counter is odd, and that when no writer is altering data, the counter is even.
reader of the seqlocks
don't need disable preempt because it don't acquire spin lock
reader
unsigned int seq;
do {
seq = read_seqbegin(&seqlock);
/* ... CRITICAL REGION ... */
} while (read_seqretry(&seqlock, seq));
read_seqbegin() returns the current sequence number of the seqlock; read_seqretry() returns 1 if either the value of the seq local variable is odd (a writer was updating the data structure when the read_seqbegin() function has been invoked),or if the value of seq does not match the current value of the seqlock’s sequence counter (a writer started working while the reader was still executing the code in the critical region)
drawback of the seqlock
1.restrict to the data it protected
- The data structure to be protected does not include pointers that are modified by the writers and dereferenced by the readers (otherwise, a writer could change the pointer under the nose of the readers)(why?when?)
- The code in the critical regions of the readers does not have side effects (otherwise, multiple reads would have different effects from a single read)
2.the critical regions of the readers should be short and writers should seldom acquire the seqlock, otherwise repeated read accesses would cause a severe overhead.
Read-Copy update(RCU)
main conception: Reader, Updater, Reclaimer
Read-copy update (RCU) is yet another synchronization technique designed to protect data structures that are mostly accessed for reading by several CPUs.
advantage
RCU is lock-free, that is, it uses no lock or counter shared by all CPUs; this is a great advantage over read/write spin locks and seqlocks, which have a high overhead due to cache line-snooping and invalidation.
restriction
- Only data structures that are dynamically allocated and referenced by means of pointers can be protected by RCU.
- No kernel control path can sleep inside a critical region protected by RCU.
Reader:rcu_read_lock()
:easy work just diasable preempt
When a kernel control path wants to read an RCU-protected data structure, it executes the rcu_read_lock() macro, which is equivalent to preempt_disable(). Next, the reader dereferences the pointer to the data structure and starts reading it. As stated above, the reader cannot sleep until it finishes reading the data structure; the end of the critical region is marked by the rcu_read_unlock() macro, which is equivalent to preempt_enable().
Updater: rcu_assign_pointer()
when a writer wants to update the data structure, it dereferences the pointer and makes a copy of the whole data structure.Next, the writer modifies the copy. Once finished, the writer changes the pointer to the data structure so as to make it point to the updated copy(atomically).
a memory barrier is required to ensure that the updated pointer is seen by the other CPUs only after the data structure has been modified. Such a memory barrier is implicitly introduced if a spin lock is coupled with RCU to forbid the concurrent execution of writers.
Reclaimer: call_rcu()
go through a quiescent state(means finish rcu_read_unlock())
- The CPU performs a process switch (see restriction 2 earlier).
- The CPU starts executing in User Mode.
- The CPU executes the idle loop
The call_rcu() function is invoked by the writer to get rid of the old copy of the data structure. It receives as its parameters the address of an rcu_head descriptor (usually embedded inside the data structure to be freed) and the address of a callback function to be invoked when all CPUs have gone through a quiescent state.
The call_rcu() function stores in the rcu_head descriptor the address of the callback and its parameter, then inserts the descriptor in a** per-CPU list of callbacks**. Periodically, once every tick the kernel checks whether the local CPU has gone through a quiescent state. When all CPUs have gone through a quiescent state, a local tasklet—whose descriptor is stored in the rcu_tasklet per-CPU variable—executes all callbacks in the list.
Semaphores(Kernel Semaphores)
Essentially, Semaphores implement a locking primitive that allows waiters to sleep until the desired resource becomes free.
whenever a kernel control path tries to acquire a busy resource protected by a kernel semaphore, the corresponding
process is suspended. It becomes runnable again when the resource is released. Therefore, kernel semaphores can be acquired only by functions that are allowed to sleep; interrupt handlers and deferrable functions cannot use them.
struct semaphore
fields
1.count
Stores an atomic_t value. value 1: free to acquire; value 0: has been accessed and no process waiting for this; negative value:one more pro wait for this;
could also be initialized with an arbitrary positive value n.In this case, at most n processes are allowed to
concurrently access the resource.
2.wait
Stores the address of a wait queue list that includes all sleeping processes that are currently waiting for the resource. Of course, if count is greater than or equal to 0, the wait queue is empty.
3.sleepers
Stores a flag that indicates whether some processes are sleeping on the semaphore.
macro
#define DEFINE_SEMAPHORE(name) \
struct semaphore name = __SEMAPHORE_INITIALIZER(name, 1)
sema_init(struct semaphore *sem, int val)
down(struct semaphore *sem) //sleep UNINTERRUPTABLE
down_interruptible(struct semaphore *sem) //sleep interruptable
down_killable (struct semaphore *sem) //sleep killable
down_trylock(struct semaphore *sem)
down_timeout(struct semaphore *sem, long jiffies) //specified time-out jiffies
up(struct semaphore *sem) //release
Getting and releasing semaphores
release: up()
The up() function increases the count field of the *sem semaphore, and then it checks whether its value is greater than 0(automically). If count is less than 0, the _ _up() function is invoked so that sleeping process is woken up.
getting: down()
The down() function decreases the count field of the *sem semaphore, and then checks whether its value is negative(automically). If count is greater than or equal to 0, the current process acquires the resource and the execution continues normally. Otherwise, count is negative, and the current process must be suspended. The contents of some registers are saved on the stack, and then _ _down() is invoked.
__down()
the _ _down() function changes the state of the current process from TASK_RUNNING to TASK_UNINTERRUPTIBLE, and it puts the process in the semaphore wait queue.
Usually, wait queue functions get and release the wait queue spin lock as necessary when inserting and deleting an element. The _ _down() function, however, uses the wait queue spin lock also to protect the other fields of the semaphore data structure, so that no process running on another CPU is able to read or modify them.
Only exception handlers, and particularly system call service routines, can use the down() function. Interrupt handlers or deferrable functions must not invoke down( ), because this function suspends the process when the semaphore is busy.
version of down()
- down_trylock( ) : not sleep when resources busy
- down_interruptible( ) : allow interrupted and return -EINTR
Read/Write Semaphores
rw_semaphore
Read/write semaphores are similar to the read/write spin locks described earlier in the section “Read/Write Spin Locks,” except that waiting processes are suspended instead of spinning until the semaphore becomes open again.
Completions
struct completion {
unsigned int done;
wait_queue_head_t wait;
};
//up
complete()
//get
wait_for_completion()
The real difference between completions and semaphores is how the spin lock included in the wait queue is used. In completions, the spin lock is used to ensure that complete() and wait_for_completion() cannot execute concurrently. In semaphores, the spin lock is used to avoid letting concurrent down() mess up the semaphore data structure.
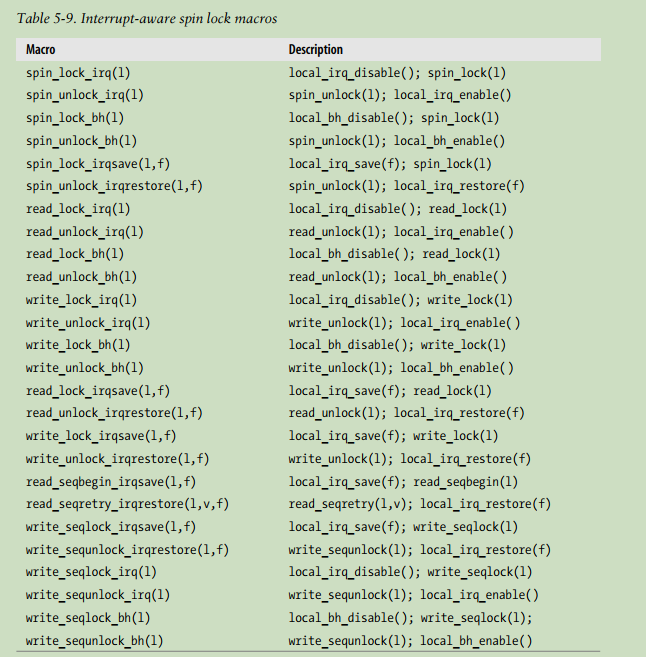
Local Interrupt Disabling
Interrupt disabling is one of the key mechanisms used to ensure that a sequence of kernel statements is treated as a critical section. It allows a kernel control path to continue executing even when hardware devices issue IRQ signals, thus providing an effective way to protect data structures that are also accessed by interrupt handlers.
ops
//by set IF flag in eflags
local_irq_disable( )
local_irq_enable()
irq_disabled()
local_irq_save()
local_irq_restore()
//by set APIC
disable_irq(irq_num)//ignore the interrupt asked in 'irq_num' line
Disabling and Enabling Deferrable Functions
1.disable interrupts on that CPU
With no interrupt handler can be activated, softirq actions cannot be started asynchronously.
2.set preempt_count
Local deferrable functions can be enabled or disabled on the local CPU by acting on the softirq counter stored in the
preempt_count field of the current’s thread_info descriptor because of that the do_softirq() function never executes the softirqs if the softirq counter is positive.
Moreover, tasklets are implemented on top of softirqs, so setting this counter to a positive value disables the execution of all deferrable functions on a given CPU, not just softirqs.
local_bh_disable\local_bh_enable
local_bh_enable would check the value of the hardirq counter and the softirq counter and invoke do_softirq() if it needed to ensure the timely execution of deferable task. In addition, it alse check the value of the flag 'TIF_NEED_RESCHED' and invokes the preempt_schedule() if its value is 1.
Synchronizing Accesses to Kernel Data Structures
A rule: always keep the concurrency level as high as possible in the system.
the concureency level
base on two main factors:
- The number of I/O devices that operate concurrently.
- The number of CPUs that do productive work.
To maximize I/O throughput, interrupts should be disabled for very short periods of time.
To use CPUs efficiently, synchronization primitives based on spin locks should be avoided whenever possible. When a CPU is executing a tight instruction loop waiting for the spin lock to open, it is wasting precious machine cycles. Even worse, spin locks have negative effects on the overall performance because of their impact on the hardware caches.
Choosing Among Spin Locks, Semaphores, and Interrupt Disabling
Remember that whenever a kernel control path acquires a spin lock (as well as a read/write lock, a seqlock, or a RCU “read lock”), disables the local interrupts, or disables the local softirqs, kernel preemption is automatically disabled.
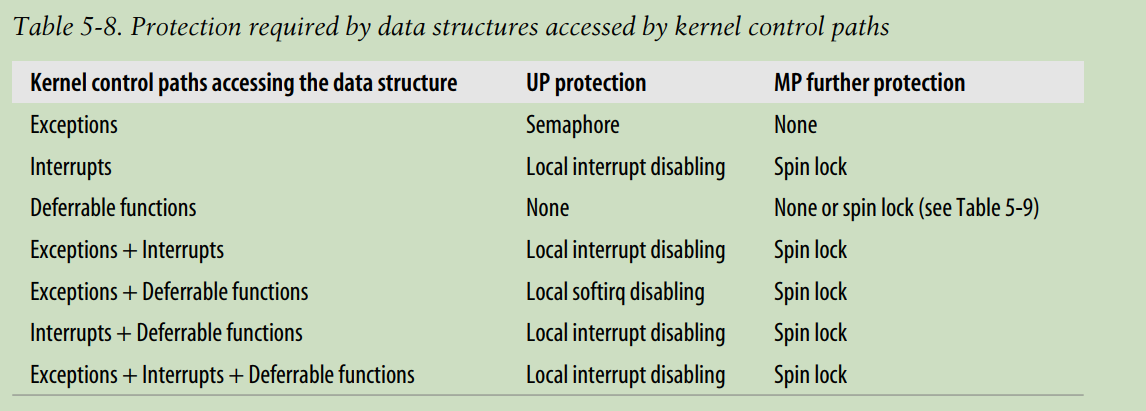
Protecting a data structure accessed by exceptions
Race conditions are avoided through semaphores, because these primitives allow the process to sleep until the resource becomes available(in process context).
Kernel preemption does not create problems either. If a process that owns a semaphore is preempted, a new process running on the same CPU could try to get the semaphore.
Protecting a data structure accessed by interrupts
each interrupt handler is serialized with respect to itself—that is, it cannot execute more than once concurrently(disable itself automatically).
The Linux kernel uses several macros that couple the enabling and disabling of local interrupts with spin lock handling. In uniprocessor systems, these macros just enable or disable local interrupts and kernel preemption.
Protecting a data structure accessed by deferrable functions
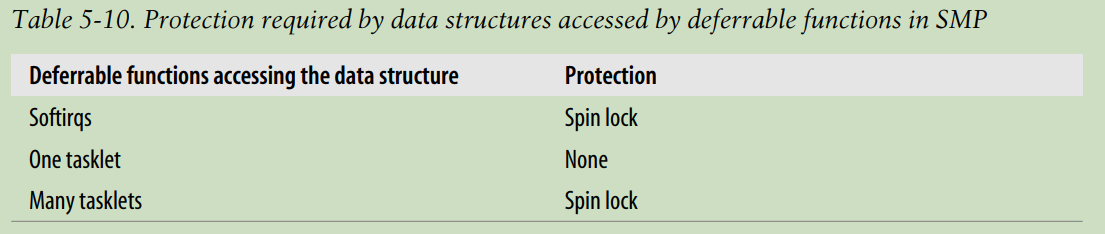
A data structure accessed by a softirq must always be protected, usually by means of a spin lock, because the same softirq may run concurrently on two or more CPUs. Conversely, a data structure accessed by just one kind of tasklet need not be protected, because tasklets of the same kind cannot run concurrently. However, if the data structure is accessed by several kinds of tasklets, then it must be protected.
Protecting a data structure accessed by exceptions and interrupts
Sometimes it might be preferable to replace the spin lock with a semaphore. Because interrupt handlers cannot be suspended, they must acquire the semaphore using a tight loop and the down_trylock() function; for them, the semaphore acts essentially as a spin lock. System call service routines, on the other hand, may suspend the calling processes when the semaphore is busy. For most system calls, this is the expected behavior. In this case, semaphores are preferable to spin locks, because they lead to a higher degree of concurrency of the system.
Protecting a data structure accessed by exceptions and deferrable functions
in uniprocessor systems, disable interrupt(only interrupts can invoke softirqs) or just disable softirqs with macro local_bh_disable() with enabling the interrupt.
in multiprocessor systems, a spin lock is always required to forbid concurrent accesses to the data structure on several CPUs.
Protecting a data structure accessed by exceptions, interrupts, and deferrable functions
spin lock
Examples of Race Condition Prevention
Reference Counters
The Big Kernel Lock
p223
ponits : preempt_schedule_irq() invoke a process switch with holding big_kernel_lock(by temporarily set the locak_depth to -1 before schedule)
Memory Descriptor Read/Write Semaphore
Slab Cache List Semaphore
Inode Semophores

 浙公网安备 33010602011771号
浙公网安备 33010602011771号