
Understanding the linux kernel Chapter3 Processes
Process Descriptor
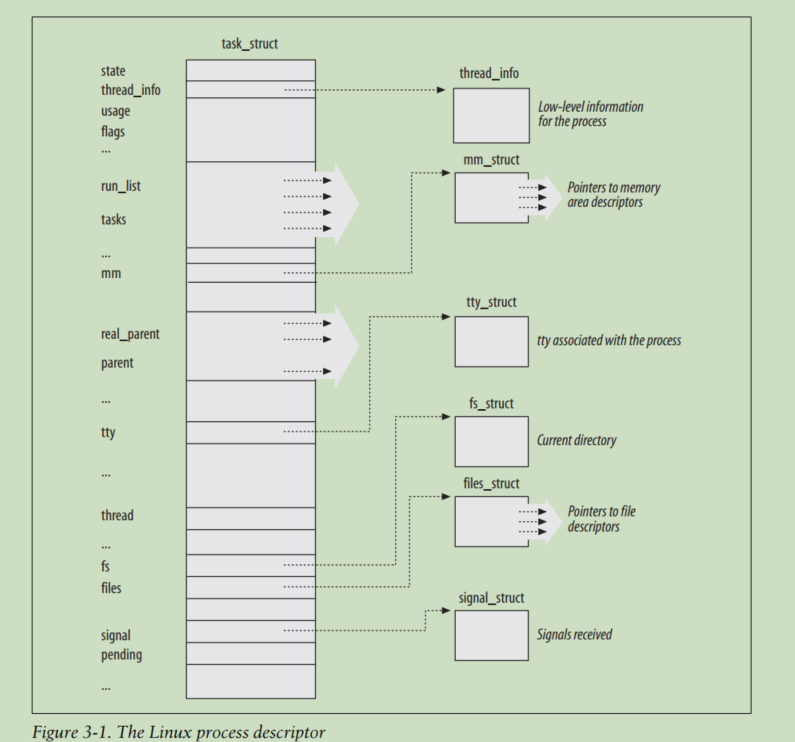
How Processes Are Organized
the process in state:
-
TASK_RUNNING
organized in runqueue list group -
TASK_STROPPED\EXIT_ZOMBIE\EXIT_DEAD
There is no need to group processes in any of these three states, because stopped, zombie, and dead processes are accessed only via PID or via linked lists of the child processes for a particular parent
-
TASK_INTERRUPTIBLE\TASK_UNINTERRUPTIBLE
managed in wait queuesBy the way, it is rather uncommon that a wait queue includes both exclusive and nonexclusive processes.
the macro represent task state has expanded to more subdivided flags(base on v6.7), defined in <linux/include/sched.h>
new flags
/*
* Task state bitmask. NOTE! These bits are also
* encoded in fs/proc/array.c: get_task_state().
*
* We have two separate sets of flags: task->__state
* is about runnability, while task->exit_state are
* about the task exiting. Confusing, but this way
* modifying one set can't modify the other one by
* mistake.
*/
/* Used in tsk->__state: */
#define TASK_RUNNING 0x00000000
#define TASK_INTERRUPTIBLE 0x00000001
#define TASK_UNINTERRUPTIBLE 0x00000002
#define __TASK_STOPPED 0x00000004
#define __TASK_TRACED 0x00000008
/* Used in tsk->exit_state: */
#define EXIT_DEAD 0x00000010
#define EXIT_ZOMBIE 0x00000020
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/* Used in tsk->__state again: */
#define TASK_PARKED 0x00000040
#define TASK_DEAD 0x00000080
#define TASK_WAKEKILL 0x00000100
#define TASK_WAKING 0x00000200
#define TASK_NOLOAD 0x00000400
#define TASK_NEW 0x00000800
#define TASK_RTLOCK_WAIT 0x00001000
#define TASK_FREEZABLE 0x00002000
#define __TASK_FREEZABLE_UNSAFE (0x00004000 * IS_ENABLED(CONFIG_LOCKDEP))
#define TASK_FROZEN 0x00008000
#define TASK_STATE_MAX 0x00010000
//see more flag in linux kernel source
... ...
Process Resource Limits
stored in the current->signal->rlim field
struct rlimit
struct rlimit {
unsigned long rlim_cur;//currently max value of the corresponding resource
unsigned long rlim_max;//max value of the rlim_cur
};
Whenever a user logs into the system, the kernel creates a process owned by the superuser, which can invoke setrlimit( ) to decrease the rlim_max and rlim_cur fields for a resource. The same process later executes a login shell and becomes owned by the user. Each new process created by the user inherits the content of the rlim array from its parent, and therefore the user cannot override the limits enforced by the administrator.
manage process for scheduler
The trick used to achieve the scheduler speedup consists of splitting the runqueue in many lists of runnable processes, one list per process priority. Each task_struct descriptor includes a run_list field of type list_head. If the process priority is equal to k (a value ranging between 0 and 139), the run_list field links the process descriptor into the list of runnable processes having priority k. Furthermore, on a multiprocessor system, each CPU has its own runqueue, that is, its own set of lists of processes. This is a classic example of making a data structures more complex to improve performance: to make scheduler operations more efficient, the runqueue list has been split into 140 different lists!
the kernel must preserve a lot of data for every runqueue in the system; however, the main data structures of a runqueue are the lists of process descriptors belonging to the runqueue; all these lists are implemented by a single prio_array_t data structure.
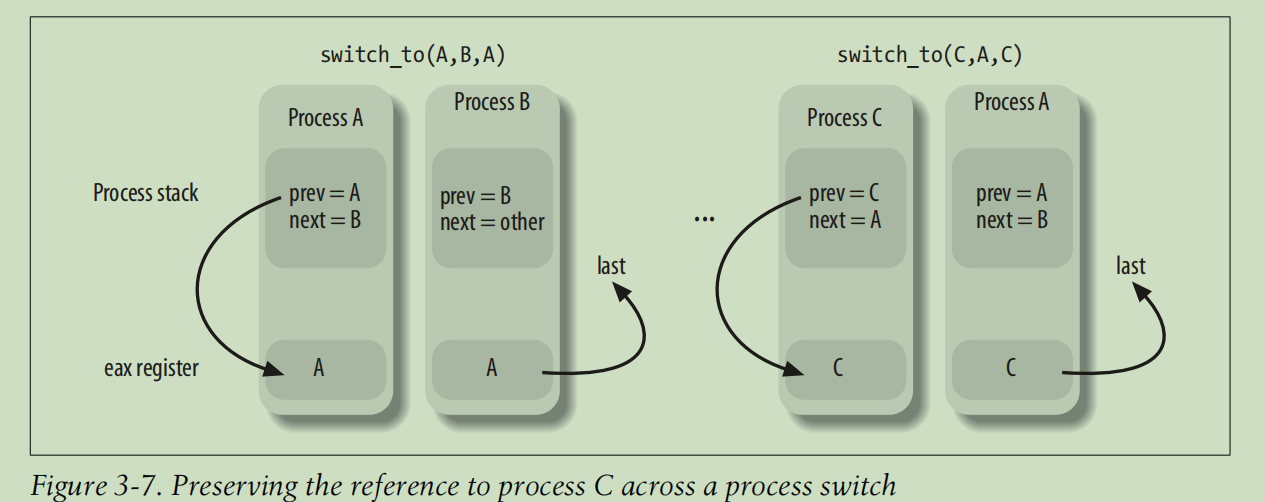
Process Switch
Hardware Context
The set of data that must be loaded into the registers before the process resumes its execution on the CPU is called the hardware context.
The contents of all registers used by a process in User Mode have already been saved on the Kernel Mode stack before performing process switching.
Task State Segment
In Linux, a part of the hardware context of a process is stored in the process descriptor, while the remaining part is saved in the Kernel Mode stack.
was ued by hardware context switches to store hardware context. the linux set up this segment for two main reaseon:
- When an 80×86 CPU switches from User Mode to Kernel Mode, it fetches the address of the Kernel Mode stack from the TSS.
- When a User Mode process attempts to access an I/O port by means of an in or out instruction, the CPU may need to access an I/O Permission Bitmap stored in the TSS to verify whether the process is allowed to address the port.
The thread field
each process descriptor includes a field called thread of type thread_struct, in which the kernel saves the hardware context.
Performing the Process Switch
The switch_to macro
Switching the Kernel Mode stack and the hardware context.
#define switch_to(prev, next, last) \
do { \
((last) = __switch_to((prev), (next))); \ //see below "the function __switch_to()"
} while (0)
The last parameter of the switch_to macro is an output parameter that specifies a memory location in which the macro writes the descriptor address of process C(who switced to A), thus last always reference the process who was the last running process before rerrunning prev.
The __switch_to() function
The _ _switch_to( ) function does the bulk of the process switch started by the switch_to( ) macro.
_ _switch_to(struct task_struct *prev_p,
struct task_struct *next_p)
_ _attribute_ _(regparm(3));
the detail excuting of the switch_to() see
If next_p was never suspended before because it is being executed for the first time, the function finds the starting address of the ret_from_fork( ) function
Saving and Loading the FPU,MMX,and XMM Registers
coprocessor:
A coprocessor is a computer processor used to supplement the functions of the primary processor (the CPU). Operations performed by the coprocessor may be floating-point arithmetic, graphics, signal processing, string processing, cryptography or I/O interfacing with peripheral devices.
FPU: the arithmetic floating-point unit
ESCAPE instruction(use FPU,MMX and XMM registers)
floating-point arithmetic functions are performed with ESCAPE instructions.These instructions act on the set of floating-point registers included in the CPU.
so, if the process use them, the contents of them should be saved when process switched.
MMX instructions
a set of assembly language instructions are used to speed up the excuting of multimedia applications, introduced in later Pentium models, using the float-point registers of the FPU.
there are some support provided by the hardware to maintain those registers
TS (Task_Switching) flag( just like the lazy mechanism of COW, iomap)
When a context switch occurs from A to B, the kernel sets the TS flag and saves the floating-point registers into the TSS of process A. If the new process B does not use the mathematical coprocessor, the kernel won’t need to restore the contents of the floating-point registers. But as soon as B tries to execute an ESCAPE or MMX instruction, the CPU raises a “Device not available” exception, and the corresponding handler loads the floating-point registers with the values saved in the TSS of process B.
Saving and Loading the FPU registers
save:
save contents of register to thread.i387 and set flag TS_USEDFPU and The TS flag of cr0.
load:
raise a "Device not available" exception because the TS flag is set, and the handler reload the contents of FPU register from thread.i387
Using the FPU,MMX,and SSE/SSE2 units in Kernel Mode
flow
- Before using the coprocessor, the kernel must invoke kernel_fpu_begin(), which essentially calls save_init_fpu() to save the contents of the registers if the User Mode process used the FPU (TS_USEDFPU flag), and then resets the TS flag of the cr0 register.
- After using the coprocessor, the kernel must invoke kernel_fpu_end(), which sets the TS flag of the cr0 register.
- Later, when the User Mode process executes a coprocessor instruction, the math_state_restore() function will restore the contents of the registers, just as in process switch handling.
Creating Process
main call chain: clone ---> do_fork(kernel_clone in newst kernl(v6.7)) ---> copy_process()
the return address of the forked thread(the thread.esp filed stored in the thread kernel stack) point to ret_from_fork()
clone \ sys_clone
int clone(int (*fn)(void *), void *child_stack,
int flags, void *arg, ...
/* pid_t *ptid, void *newtls, pid_t *ctid */ );
flags: The low byte specifies the signal number to be sent to the parent process when the child terminates; the SIGCHLD signal is generally
selected. The remaining three bytes encode a group of clone flags.
The sys_clone() service routine that implements the clone() system call does not have the fn and arg parameters. In fact, the wrapper function saves the pointer fn into the child’s stack position corresponding to the return address of the wrapper function itself;
fork
The traditional fork( ) system call is implemented by Linux as a clone( ) system call whose flags parameter specifies both a SIGCHLD signal and all the clone flags cleared, and whose child_stack parameter is the current parent stack pointer. Therefore, the parent and child temporarily share the same User Mode stack. But thanks to the Copy On Write mechanism, they usually get separate copies of the User Mode stack as soon as one tries to change the stack.
/* Fork a new task - this creates a new program thread.
* This is called indirectly via a small wrapper
*/
asmlinkage int sys_fork(struct pt_regs *regs)
{
return do_fork(SIGCHLD, regs->ARM_sp, regs, 0, NULL, NULL);//see blow "the do_fork() function"
}
vfork
The vfork( ) system call creates a process that shares the memory address space of its parent. To prevent the parent from overwriting data needed by the child, the parent’s execution is blocked until the child exits or executes a new program.
asmlinkage int sys_vfork(struct pt_regs *regs)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, regs->ARM_sp, regs, 0, NULL, NULL);
}
the do_fork() function
long do_fork(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size, int __user *parent_tidptr,
int __user *child_tidptr);
//in latest version of kernel(v6.7), the do_fork has changed to kernel_clone defined in /kernel/fork.c
pid_t kernel_clone(struct kernel_clone_args *args)
Kernel Threads
kernel_thread()
create kernel threads through do_fork(flags|CLONE_VM|CLONE_UNTRACED, 0, pregs, 0, NULL, NULL)
CLONE_VM: don't need access user address
CLONE_UNTRACED: don't allowed ptrace kernel processes
Destroying Processes
Process Termination
syscall: _exit() exit_group() --> do_exit()
The do_group_exit() function
The do_group_exit() function kills all processes belonging to the thread group of current. It receives as a parameter the process termination code, which is either a value specified in the exit_group() system call (normal termination) or an error code supplied by the kernel (abnormal termination).
send SIGKILL to all task in the current thread group, and call do_exit().
The do_exit() function
the way the thread exit:
in summary, if the thread is traced, it send signal to its parent and set state to EXIT_ZOMBIE, treated like a process(thread group leader). And if the process is a thread and not traced, it released remaining resources and set state to EXIT_DEAD.
Process Removal
release_task() is used to reclaime the remaining resources of the zombie child-process, which could be invoked in two ways:one is cause by parent who cares about the exiting code of ch-pro and calls wait(), the other is the parent don't care about the exit code and do_exit would call release_task() in which case resources are reclaimed by the scheduler(e.g. untraced threads).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号