每日总结
今日完成了大型数据库的作业。使用spark书写程序。
首先是在idea中书写代码:
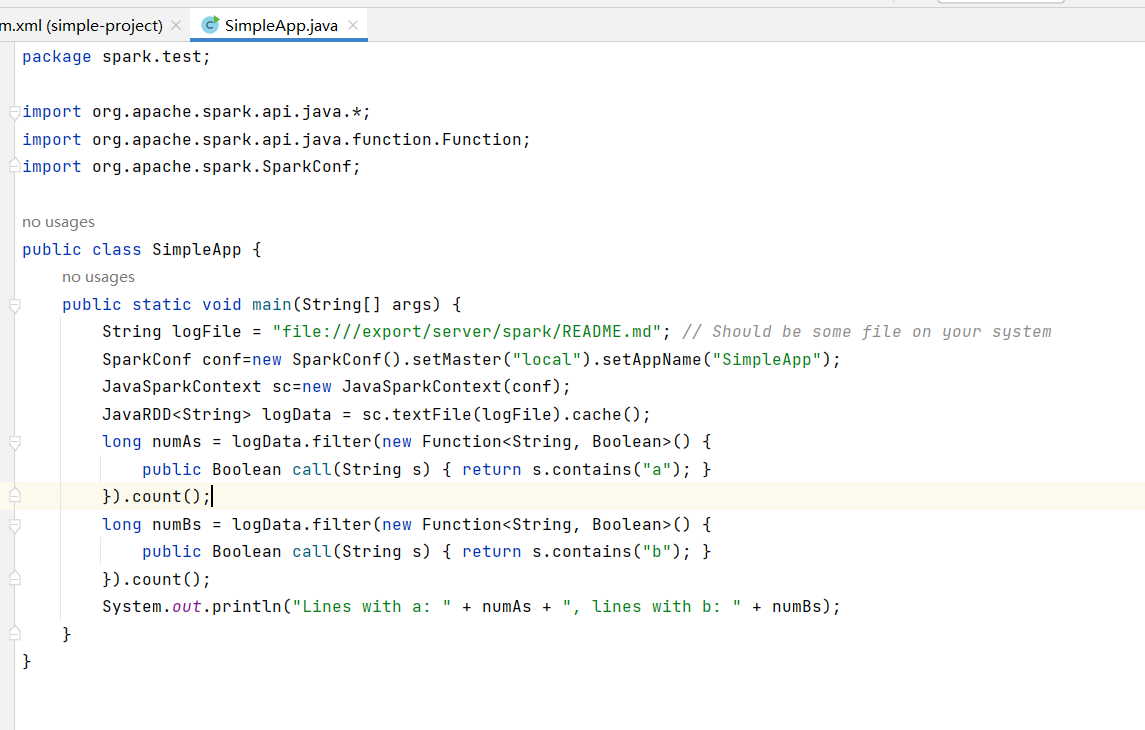
SimpleApp.java文件
package spark.test; import org.apache.spark.api.java.*; import org.apache.spark.api.java.function.Function; import org.apache.spark.SparkConf; public class SimpleApp { public static void main(String[] args) { String logFile = "file:///export/server/spark/README.md"; // Should be some file on your system SparkConf conf=new SparkConf().setMaster("local").setAppName("SimpleApp"); JavaSparkContext sc=new JavaSparkContext(conf); JavaRDD<String> logData = sc.textFile(logFile).cache(); long numAs = logData.filter(new Function<String, Boolean>() { public Boolean call(String s) { return s.contains("a"); } }).count(); long numBs = logData.filter(new Function<String, Boolean>() { public Boolean call(String s) { return s.contains("b"); } }).count(); System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs); } }
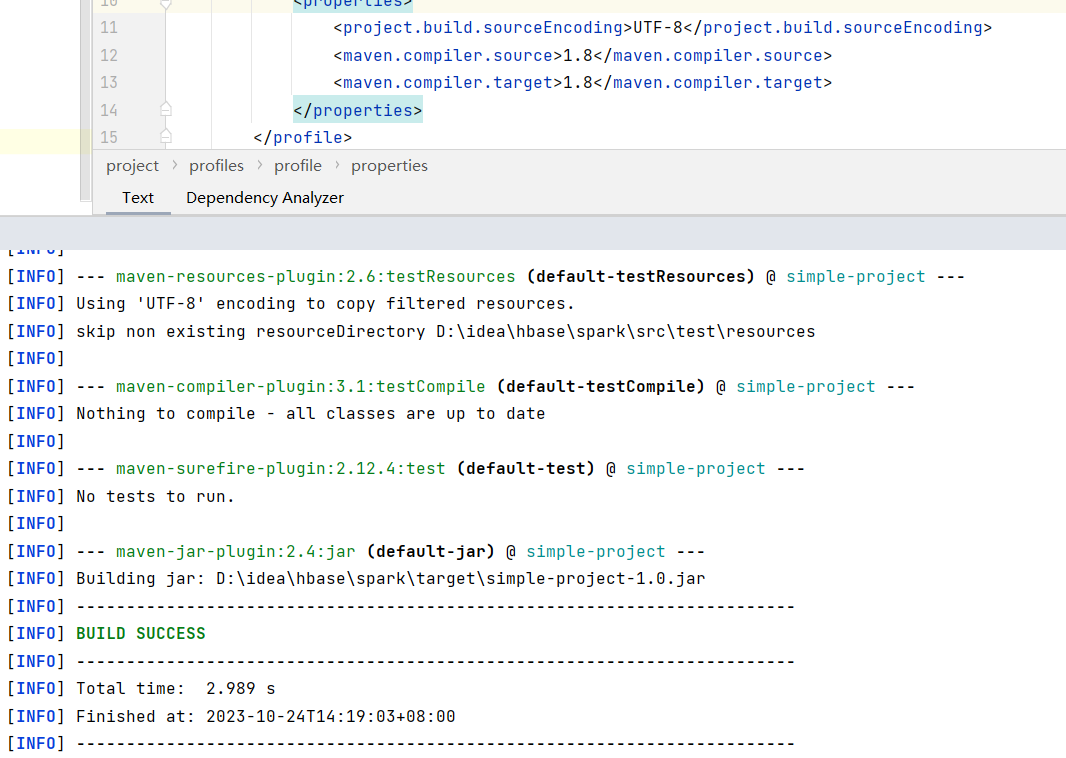
pom.xml文件:
<project>
<profiles>
<profile>
<id>jdk-1.8</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.8</jdk>
</activation>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
</profile>
</profiles>
<groupId>cn.edu.xmu</groupId>
<artifactId>simple-project</artifactId>
<modelVersion>4.0.0</modelVersion>
<name>Simple Project</name>
<packaging>jar</packaging>
<version>1.0</version>
<repositories>
<repository>
<id>jboss</id>
<name>JBoss Repository</name>
<url>http://repository.jboss.com/maven2/</url>
</repository>
</repositories>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.4.0</version>
</dependency>
</dependencies>
</project>
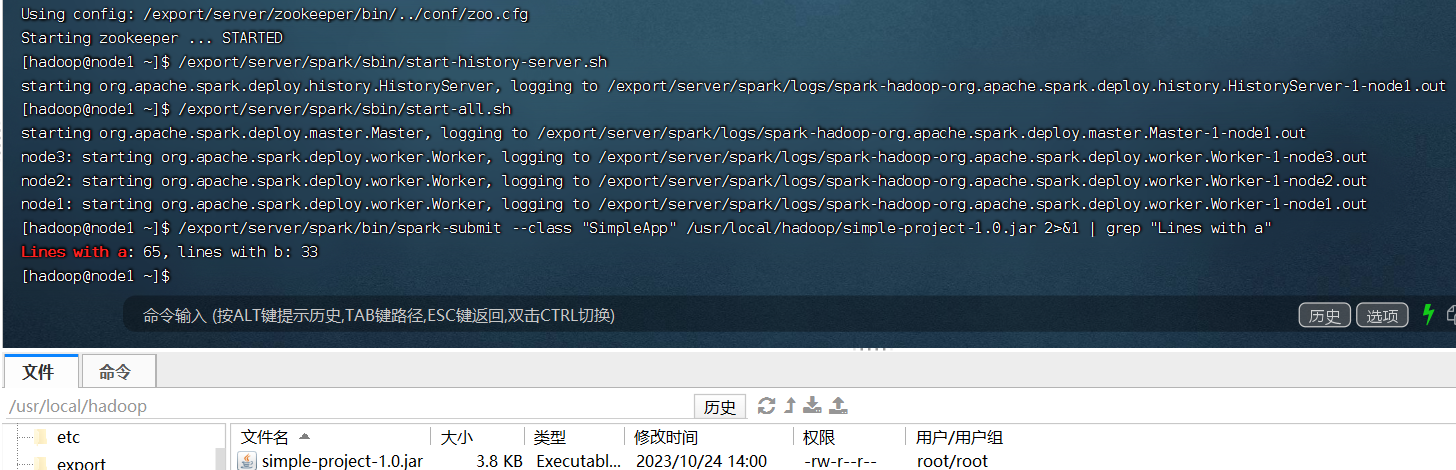
之后打包,提交到spark上运行得出结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号