

引言:为什么数据比算法更重要?
如果你在训练AI模型,可能会发现一个有趣的现象:有时候换一个更强大的算法,模型效果提升并不明显;但如果换上一批高质量的数据,效果却能突飞猛进。
这就好比教孩子学习——再好的老师(算法),如果教材(数据)乱七八糟、错误百出,学生也很难学到真本事。在AI领域,数据就是模型的“教材”,而数据集的质量,直接决定了这个模型能有多聪明、多可靠。
现在大模型这么火,很多人都在尝试微调自己的专属模型。但你是否遇到过这样的困惑:
- 精心准备了数据,训练出来的模型却答非所问?
- 明明数据量很大,效果还不如别人少量高质量数据?
- 不知道如何判断自己的数据到底“好不好”?
今天,我们就来彻底搞清楚:高质量数据集到底是什么,以及如何亲手打造它。无论你是想微调一个客服助手、创作帮手,还是行业专属AI,掌握数据质量的门道,都能让你的模型训练事半功倍。
一、数据集:AI的“智慧源泉”
1.1 数据集的本质
用最通俗的话说,数据集就是一堆有组织的数据的集合。就像你整理照片时建立的相册——不是把手机里所有照片乱糟糟堆在一起,而是按时间、地点、人物分类整理好。
国家标准里对数据集的定义是:“具有一定主题,可以标识并可以被计算机化处理的数据集合”。这里面有三个关键词:
- 有主题:你的数据要围绕一个明确目标(比如“法律咨询问答”“商品文案生成”)
- 可标识:每条数据都能被识别、定位
- 可计算机处理:必须是机器能读懂、能计算的格式
1.2 数据集的重要性
中国人民大学的钱明辉教授说得很到位:数据集已经从简单的“数据集合”,演变成了驱动AI系统构建、训练、部署、进化的基础性资源。
我们可以做个比喻:
- 算法像厨师的烹饪技法
- 算力像厨房的灶具火力
- 数据就像食材原料
米其林大厨用烂菜叶也做不出美味,普通厨娘用好食材也能做出可口的饭菜。AI也是如此——高质量数据是模型表现好的前提条件。
1.3 数据集的“好结构”长什么样?
好的数据集应该有清晰的表格结构(即使是文本数据,也有内在的结构逻辑)。比如一个客服问答数据集:
| 用户问题 | 标准回答 | 问题类型 | 难易程度 |
|---|---|---|---|
| “怎么退货?” | “登录账户-我的订单-申请退货…” | 操作流程 | 简单 |
| “商品破损怎么办?” | “请拍照上传,客服将在1小时内…” | 售后处理 | 中等 |
这样的结构让算法能清晰地看到“问题-答案”的对应关系,还能通过“类型”“难度”等字段做更精细的学习。
二、高质量数据集的“黄金标准”
2.1 从两个维度理解“高质量”
维度一:单个样本的“含金量”
高质量样本通常信息密度高、对模型提升帮助大。尤其是那些 “难例”样本——就是模型容易出错、但一旦学会就能大幅提升能力的例子。
比如教AI写诗:
- 简单样本:“写一首关于春天的诗”(AI已经会了)
- 难例样本:“用李商隐的含蓄风格写春天,但不能出现‘花’‘草’‘风’这些字”(这对AI是挑战,学会后能力会提升)
维度二:整体数据集的“均衡性”
这是很多初学者忽略的。高质量数据集不是一堆“好样本”的简单堆积,而要有科学的构成:
- 任务覆盖全面:如果你的模型要处理多种任务(问答、总结、创作),数据中都要有体现,且比例均衡
- 响应准确无误:事实错误率最好低于1%,逻辑要自洽
- 指令多样化:同一个问题,要有多种问法。用户不会总用教科书式的提问
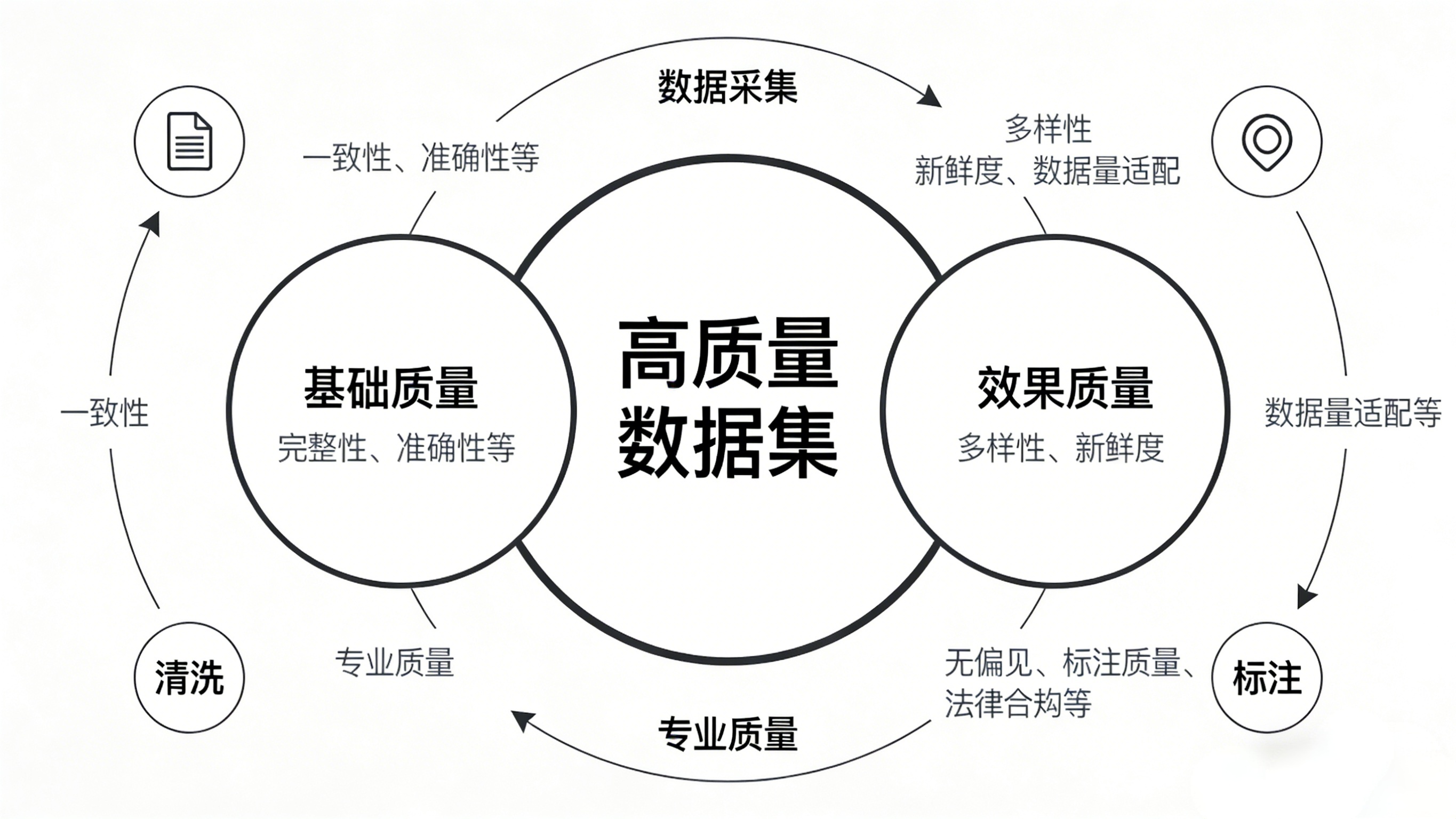
2.2 16条具体质量标准(帮你逐条自查)
根据深圳政务数据和百度文库的实践,我总结了16条可操作的质量标准:
基础六项(必须达标):
- 一致性:格式统一。日期都用“2024-01-01”,别混用“2024/1/1”“1月1日”
- 完整性:关键信息不缺失。100条数据里,重要字段空着的不超过2-3条
- 及时性:数据不过时。金融数据最好季度更新,科技资讯可能每月都要更新
- 准确性:没有“硬伤”。人名、日期、数字不能错,这是底线
- 有效性:符合业务规范。邮箱要有“@”,电话是11位
- 唯一性:不重复。完全一样的数据不要出现两次
进阶五项(影响效果):
7. 数据量适配:不是越多越好。简单任务可能几千条就够了,复杂任务需要几万到几十万
8. 新鲜度:时效性强的领域(新闻、股价),数据生命周期控制在3个月内
9. 多样性:覆盖各种场景。人脸数据要有不同肤色、光照;医疗数据要有常见病和罕见病
10. 可解释性:给数据加“备注”。这张图片是在什么设备、什么光线拍的?这段文本作者是什么背景?
11. 可得性:合法合规。爬虫数据要遵守robots协议,个人数据要脱敏
高级五项(专业要求):
12. 无偏见:主动平衡。招聘数据里男女简历通过率不应人为差异过大
13. 标注质量:关键任务三人标注+专家仲裁,错误率控制在5%以内
14. 版本管理:每次改动留记录。“数据集_V2_20240120_新增电商数据5000条”
15. 法律合规:特别重要!人脸数据要授权书,医疗数据要符合HIPAA(如果涉及国际)
16. 维护成本可控:建立自动化清洗流程,别每条数据都靠人工
一个生动的比喻:
好的数据集就像精心管理的花园——不是杂草丛生(低质数据),也不是只有一种花(缺乏多样性),而是各种植物(数据样本)科学搭配、定期修剪(清洗维护)、不断引入新品种(更新迭代)。
三、手把手教你构建高质量数据集
3.1 构建前的关键考虑
在开始采集数据之前,先想清楚这几点:
- 场景明确:你的模型到底要解决什么问题?是客服问答、文案生成,还是代码辅助?
- 数据来源:有哪些可信的来源?公开数据集、公司内部数据、人工构造数据如何搭配?
- 质量门槛:你能接受的最低质量标准是什么?准确率要99%还是95%?
- 安全合规:数据涉及隐私吗?需要脱敏吗?有版权问题吗?
特别提醒: 现在大模型训练有个趋势——数据量并非越多越好。很多团队发现,50万条数据里,真正有效的可能只有10-20万条。关键在于通过数据蒸馏技术筛选出最有价值的部分。
3.2 七步构建法(跟着做就行)
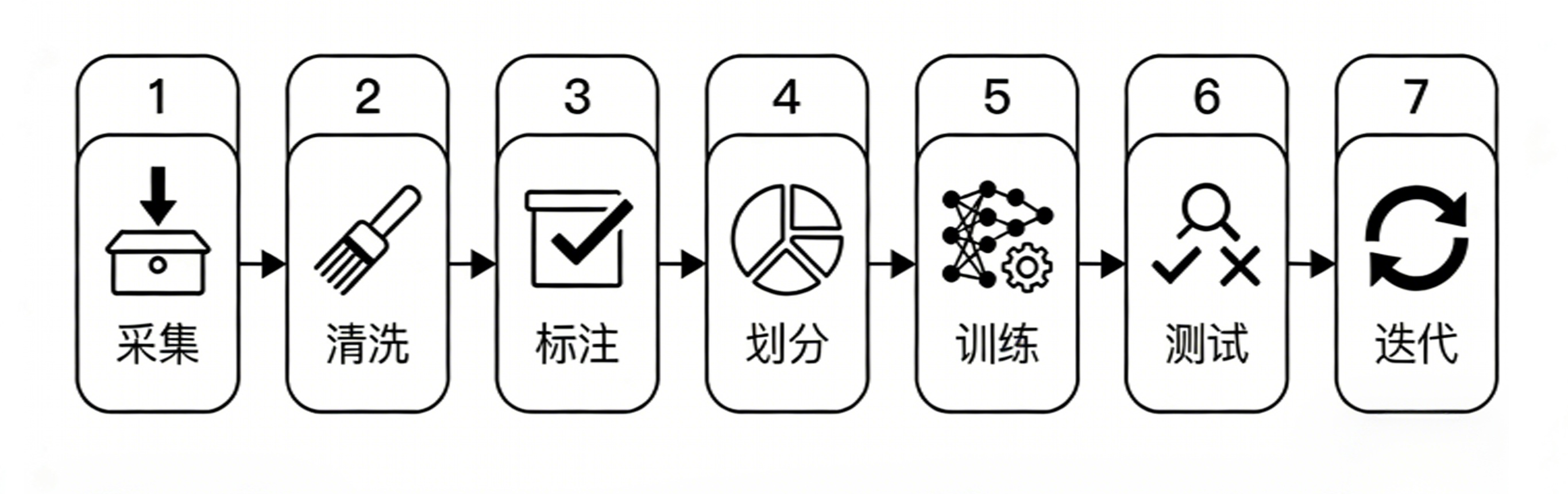
第一步:数据采集——找对“原材料”
-
从哪里找?
- 公开数据集(Hugging Face、Kaggle、国内开放平台)
- 业务系统日志(用户真实query)
- 人工构造(针对特定场景专门编写)
- 合成数据(用AI生成模拟数据)
-
采集技巧:
- 设定明确的采集范围,不要“什么都想要”
- 记录元数据:来源、采集时间、采集方式
- 初步去重:明显重复的当场剔除
第二步:数据清洗——给数据“洗澡”
这是最耗时但最关键的一步。清洗清单:
-
格式标准化:统一日期、数字、单位的格式
-
处理缺失值:
- 关键字段缺失→删除或标注“待补全”
- 非关键字段缺失→用合理值填充(并注明是填充的)
-
剔除异常值:血压300mmHg?明显错误,要复核
-
去重:完全重复的只留一条
-
编码统一:文本都用UTF-8,避免乱码
自动化工具推荐:可以写简单的Python脚本,或者用OpenRefine这类可视化工具。
第三步:数据标注——告诉AI“这是什么”
对于监督学习,标注质量决定天花板。
标注最佳实践:
- 制作标注手册:用20-30个典型样本,清晰说明标注规则
- 培训标注员:考核通过才能上岗
- 多人标注+仲裁:重要数据三人独立标注,分歧由专家决定
- 质量抽检:每2小时抽检,错误率超5%的重新培训
小技巧:标注时可以顺便标注“置信度”——这个标注我有多确定?这对后续训练有参考价值。
第四步:数据划分——科学分配“训练、验证、测试”
经典比例:70%训练集、15%验证集、15%测试集
划分原则:
- 随机打散:避免时间顺序或来源集中
- 分布一致:三个集合的样本类型比例要相似
- 测试集隔离:测试集在训练过程中完全不能接触
第五步:模型训练——开始“教学”
训练时要注意:
- 从小规模数据开始试跑,确认流程没问题
- 监控训练损失(loss),看是否正常下降
- 用验证集定期检查,防止过拟合
第六步:模型测试——看看“学得怎么样”
用测试集进行最终评估:
- 定量指标:准确率、F1值、BLEU分数(根据任务选择)
- 定性分析:人工看100个例子,评估回答是否自然、有用
- 边缘案例测试:故意给一些刁钻问题,看模型表现
第七步:迭代优化——持续改进
数据集不是一次性的。根据模型表现:
- 收集bad cases:模型哪里错了?补充相应数据
- 定期更新:业务变化了,数据也要更新
- 版本控制:每次更新都要记录,方便回溯
四、如何验证你的数据集真的“高质量”?
4.1 自动化检查清单
python
# 伪代码示例,你可以用类似逻辑检查
def check_dataset_quality(dataset):
issues = []
# 检查完整性
if missing_rate(dataset) > 0.05:
issues.append("缺失率过高")
# 检查一致性
if format_inconsistency(dataset):
issues.append("格式不一致")
# 检查多样性
if diversity_score(dataset) < threshold:
issues.append("多样性不足")
return issues
4.2 实战验证:训练一个基线模型
最直接的验证方法:用你的数据集训练一个简单模型(比如BERT-base),看它在验证集上的表现:
- 比随机猜测好多少?
- 比用公开数据集训练的效果如何?
- 训练过程稳定吗?(loss平滑下降)
4.3 人工抽样审查
随机抽取100-200条数据,请领域专家或目标用户评审:
- 数据准确吗?
- 标注正确吗?
- 覆盖典型场景了吗?
4.4 实际场景小规模测试
如果有条件,用实际业务流测试:
- 抽取一小批真实用户query
- 用你的数据集训练的模型处理
- 对比处理效果和人工处理的差距
五、总结与展望
5.1 核心要点回顾
- 高质量数据集是AI成功的基石——比算法和算力更基础
- 质量≠数量——1万条高质量数据可能比100万条垃圾数据更有用
- 构建是系统工程——从采集、清洗、标注到迭代,每个环节都要质量控制
- 验证必不可少——既要自动检查,也要人工评审和实际测试
5.2 未来趋势
- 合成数据崛起:用AI生成高质量训练数据,解决稀缺领域数据不足问题
- 自动标注进化:大模型辅助标注,提升效率和一致性
- 数据蒸馏普及:从海量数据中智能筛选最有价值的部分
- 一体化平台出现:像LLaMA-Factory Online这样的平台,正在把数据准备、模型微调、效果评估整合到一个流程里,大大降低了普通人使用大模型的门槛。你可以聚焦于业务和数据本身,而不必纠缠于技术细节。
5.3 给你的建议
如果你是初学者:
- 从小开始:先做1000条高质量数据,跑通全流程
- 重视清洗:花在清洗上的时间通常占50%以上
- 迭代思维:数据集是“活”的,要持续优化
- 善用工具:不要所有事情都手动做,选择合适的工具提升效率
最后的话:
构建高质量数据集,确实像养育孩子一样需要持续投入。但这份投入是值得的——当你的模型因为高质量数据而表现优异时,那种成就感是实实在在的。
现在大模型微调越来越普及,门槛也越来越低。关键不再是“能不能做”,而是“怎么做得更好”。而这一切的起点,就是一份精心准备的高质量数据集。
希望这篇指南能帮你避开一些坑,更顺利地打造出属于自己的优质数据集。如果你在实践过程中遇到具体问题,欢迎留言交流。下次我们会聊聊:如何用少量数据实现高质量的微调效果——这是很多中小团队最关心的话题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号