

引言:为什么我们不再“从零开始”训练AI?
想象一下,你要教一个完全没接触过中文的人读懂法律条文。你会直接扔给他一本《刑法典》吗?大概率不会。更合理的做法是:先让他用中小学课本打好语言基础,认识几千个汉字,理解基本语法,然后再去攻读专业文献。
这,就是“预训练”(Pre-training)最核心的思想。
在AI领域,尤其是近几年爆火的大语言模型(如GPT、文心一言、通义千问)和视觉大模型,预训练已经成为构建智能系统的“标准流程” 。它让AI从一个“什么都不知道的婴儿”,变成一个“具备基础常识和通用能力的少年”,从而可以快速学会各种专业技能,比如写代码、分析财报、解读医学影像。
一个更贴近生活的比喻:预训练就像给模型提供了一个庞大的“互联网级别”的知识库。模型通过“阅读”海量文本或“观看”海量图片,自己总结出了世界的规律——语言的逻辑、图像的构成、事物间的关联。有了这个强大的基础,当我们想让它做一件具体的事(比如成为你的专属客服)时,只需要用少量数据“点拨”一下即可,效率极高。
那么,这个听起来很厉害的“预训练”,到底是怎么工作的?它和后续的“微调”是什么关系?更重要的是,作为一个开发者或爱好者,我们该如何利用这项技术,创造出属于自己的AI应用呢?这篇文章,我们将抛开复杂的数学公式,用最直观的方式带你一探究竟。
技术原理:三步拆解,看模型如何“自学成才”
预训练的技术核心可以归结为三个关键点:学什么、怎么学、学成什么样。我们一点一点来看。
1. 学什么?——海量无标注的通用数据
预训练的第一个特点是:它不挑食,但吃得特别多。
- NLP领域:模型“阅读”的是整个互联网的文本——维基百科、新闻网站、书籍、论坛帖子……可能高达数千亿甚至数万亿个词汇。
- CV领域:模型“观看”的是数亿张来自网络的无标签图片,如ImageNet、OpenImages等数据集。
关键点:这些数据没有人工标注(比如告诉你这张图是猫还是狗,这句话是正面还是负面情感)。模型需要从数据本身的结构中,去发现规律。这就好比让一个孩子通过大量观察现实世界,而不是背诵教科书定义,来学会“猫”的概念。
2. 怎么学?——“自监督学习”:给自己出题,自己解答
没有老师给答案,模型怎么学?答案是:模型自己给自己创造“练习题” 。这种方法叫“自监督学习”,是预训练的灵魂。
两大经典“出题”套路:
-
套路一:完形填空(掩码语言建模,MLM)
-
代表模型:BERT系列。
-
怎么玩:随机把一句话中的某些词“遮住”(变成
[MASK]),然后让模型根据上下文来猜被遮住的词是什么。 -
例子:原句是“今天天气很好,我们去公园
[MASK]风筝。”- 模型需要学习到“公园”和“风筝”的关联,以及“放”这个动作的搭配,从而预测出“放”。
-
效果:这种方式迫使模型深入理解每个词的双向上下文关系,学到的表征非常利于做理解类任务(如文本分类、情感分析)。
-
-
套路二:续写故事(自回归语言建模)
- 代表模型:GPT系列。
- 怎么玩:给定前面的词,让模型预测下一个最可能出现的词是什么。一个一个词地往下生成。
- 例子:输入“人工智能正在”,模型可能预测“改变”、“重塑”等词。
- 效果:这种方式训练出的模型拥有强大的文本生成能力,非常擅长创作、对话、续写。
视觉领域的玩法:
- 拼图游戏(图像掩码重建,如MAE) :把一张图片随机去掉很多小块,让模型根据剩余部分把缺失的部分“补画”出来。
- 找不同(对比学习,如SimCLR) :对同一张图片做两种不同的裁剪、变色等处理,让模型学会识别这两种处理来自同一张原图,从而学习到图片的本质特征。
3. 学成什么样?——一个富含“通用知识”的模型底座
经过以上海量数据和自监督任务的训练后,模型就变成了一个 “预训练模型” (也叫基座模型)。
- 它拥有了什么:对语言/图像通用模式、基础规律和世界知识的深刻理解。它知道“苹果”可以是一种水果也可以是一家公司,知道“猫”有胡须和尾巴,知道文章通常有开头、发展和结尾。
- 它还不是什么:它还不是一个能直接完成你具体任务的专家。因为它学得太通用了,并不知道你具体想让它做什么(比如用特定风格写邮件、分析你的业务数据)。
打个比方:预训练模型就像一个刚从综合性大学毕业的本科生,通识教育扎实,知识面广,学习能力强。但你要他直接去当心脏外科主刀医生或者处理复杂的跨国并购案,他还需要经过“专业培训”(即微调)。
实践步骤:从通用模型到专属模型的“精装修”之旅(微调)
拿到了强大的预训练模型底座,我们该如何让它为我们所用呢?答案是微调(Fine-tuning) 。如果把预训练比作“毛坯房”,微调就是根据你的个性化需求进行的“精装修”。
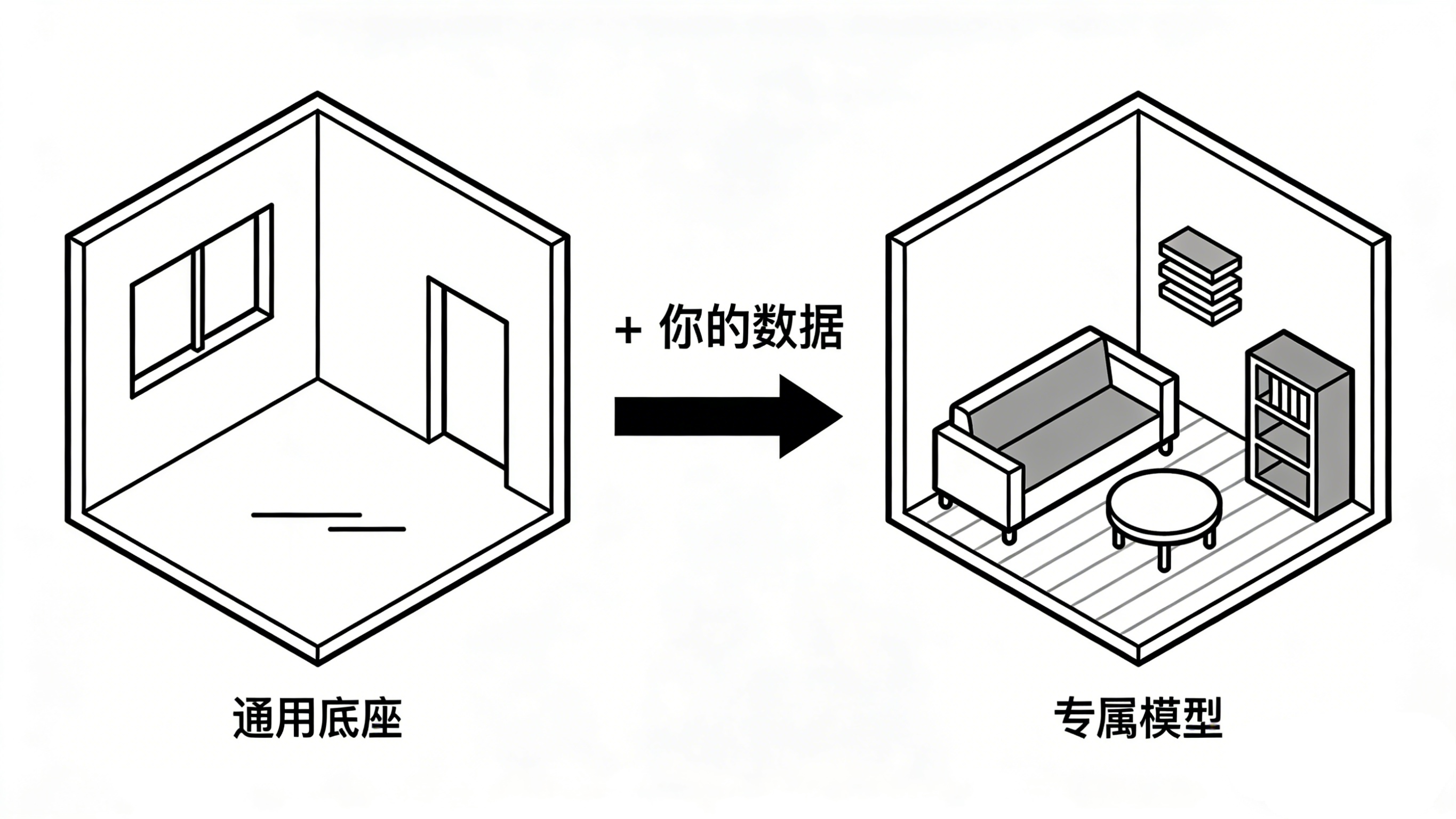
下面,我们以一个经典场景为例:你想让大模型学习你公司的产品文档和客服问答记录,成为一个专业的、风格独特的智能客服。
传统微调流程(涉及代码)
- 准备数据:收集和清洗你公司的客服对话记录、产品手册等,整理成
{“instruction”: “用户问题”, “output”: “标准回答”}这样的配对格式。 - 选择基座模型:根据你的算力和需求,选择一个开源预训练模型(如LLaMA、ChatGLM、Qwen等)。
- 搭建训练环境:配置Python、PyTorch/Transformers库,准备GPU服务器。这一步技术门槛不低,常有环境冲突、依赖问题。
- 编写训练脚本:使用LoRA、QLoRA等参数高效微调技术来减少显存消耗。你需要设置学习率、训练轮次、批次大小等大量超参数。
- 启动训练与监控:运行脚本,盯着日志和损失曲线,防止过拟合或训练崩溃。
- 测试与部署:训练完成后,用新的对话测试模型效果,并想办法将其部署成API或应用。
低门槛微调步骤(以平台化操作为例)
为了让概念更清晰,我们看看在理想的无代码平台上,微调是如何简化的:
-
数据准备与上传:在Web界面中,直接将整理好的客服问答Excel或JSON文件上传。平台通常会提供数据格式检查和简单的清洗工具。
-
选择“毛坯房” :在模型广场点选一个合适的开源基座模型(如“Llama-3-8B”或“Qwen-7B”)。
-
设计“装修方案” :
- 选择微调方法:点选“LoRA”等高效选项。
- 设定训练目标:通过勾选或简单描述,告诉系统你想提升“问答准确性”和“符合公司话术风格”。
-
一键启动“精装修” :点击“开始训练”。平台自动在云端分配算力,处理所有训练细节,你可以在仪表盘上实时看到训练进度和损失变化。
-
验收与试用:训练完成后,平台会自动提供一个测试聊天窗口。你可以直接输入问题,与刚诞生的“专属客服模型”对话,看看它的回答是否符合预期。
-
部署上线:如果效果满意,通过平台提供的“一键部署”功能,将模型发布为API接口,或打包下载,集成到你的客服系统中。
整个过程,你的核心工作就是准备高质量的数据和进行效果评估,将最大的技术门槛交给了平台。这极大地降低了个人开发者和中小企业使用大模型技术的门槛。
效果评估:如何判断你的微调是成功的?
模型训练完了,怎么知道它是不是真的变“专业”了?不能光靠感觉,这里有几个可操作的评估方法:
-
定性评估(人工评测) :
-
构造测试集:预留一部分未参与训练的真实客服问题。
-
设计评估维度:
- 准确性:回答的事实信息正确吗?
- 有用性:回答是否解决了用户的问题?
- 风格符合度:语气、用词、格式是否符合公司规范?(如是否总是以“感谢您的咨询”开头)
-
多人评分:让几名同事或领域专家对模型的回答进行打分(如1-5分),计算平均分。
-
-
定量评估(自动评测) :
-
困惑度:模型对你领域文本的预测不确定程度是否降低了?(数值越低越好)。但该指标有时与人类感受不完全一致。
-
任务特定指标:
- 对于分类任务:看准确率、F1值。
- 对于问答任务:可以用BLEU、ROUGE(衡量生成文本与标准答案的重合度)等指标,但需谨慎对待,它们更适合评测翻译或摘要。
-
对比测试:同一个问题,分别让微调前的基础模型和微调后的模型回答,直观对比效果提升。
-
-
实战检验(A/B测试) :
- 这是最硬核的评估。将微调后的模型小流量接入真实客服系统,与原有客服机器人或人工客服对比,关键指标是问题解决率、用户满意度、平均对话轮次。
核心建议:初期以人工定性评估为主,重点关注模型是否“胡说八道”(产生事实错误)以及风格是否符合要求。当模型基本稳定后,再结合定量指标进行优化。
总结与展望
预训练+微调的范式,已经彻底改变了AI开发的面貌。它就像为我们提供了一套强大的、可塑的“大脑模具”,而我们只需要注入自己的“专业知识与数据灵魂”。
-
总结来说:预训练让AI获得了通用智能和强大的学习基础,而微调则让这份通用智能定向进化为解决我们特定问题的专属能力。这套组合拳,极大地降低了AI技术的应用成本,让“每个行业、每个企业甚至每个人都拥有一个专属AI助手”成为可能。
-
展望未来,这个领域正朝着几个方向发展:
- 基座模型更小更强:如何在更小的参数量下保持甚至提升性能(如phi-3模型),让微调成本更低。
- 微调技术更高效精准:像LoRA、QLoRA这类技术会继续进化,让我们用极少的计算资源就能获得更好的效果。
- 自动化与平民化:工具和平台会越来越智能、易用。未来,微调一个大模型可能会像今天制作一个PPT一样,通过拖拽和配置就能完成。
在迈向AI平民化的道路上,LLaMA-Factory Online这类平台扮演着关键角色。它将大模型微调从实验室和顶级工程师的手中解放出来,变成一个可视化的、可交互的创作过程。无论你是想打造一个法律顾问、一个短视频脚本生成器,还是一个电商营销文案助手,你都可以从“喂”数据开始,亲自参与塑造AI的个性与能力。这不仅是技术的进步,更是一种创作方式的革新——每个人都能成为自己专属AI的“创造者”。感兴趣的朋友,不妨从这类平台开始,踏上你的大模型实践之旅。
希望这篇解读,能帮你拨开预训练与微调的技术迷雾,并鼓起勇气,动手创造出你的第一个专属AI模型。实践,永远是理解技术最好的方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号